Разработка системы умный дом. Вариант. Технологии с каждым годом развиваются все стремительнее и стремительнее
 Скачать 477.57 Kb. Скачать 477.57 Kb.
|

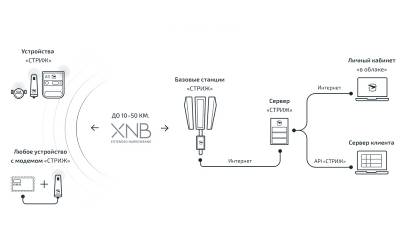 Сейчас компания «стриж» ориентирована на работу в России и странах СНГ и покрывает все города-миллионики и примыкающие к ним территории. Для того, чтобы охват сети был увеличен вместе с производительностью базовых станций, используются алгоритмы параллельной обработки радиочастотного спектра. Bluetooth. Кто не знает про Bluetooth? Bluetooth – это спецификация беспроводных сетей. Она обеспечивает передачу информации между персональными компьютерами, ноутбуками, планшетами, смартфонами, принтерами и другими устройствами на беспроводной бесплатной доступной радиочастоте для ближней связи. Устройства могут обмениваться информацией только при условии, что они не находятся дальше 100 метров друг от друга, при этом нет никаких значимых преград или помех, которые могут прервать связь в любой момент передачи данных. Принцип работы Bluetooth заключается в использовании радиоволн и связь корректно осуществляется в ISM-диапазоне, который используется во множестве повседневных устройствах [32]. Рисунок 14. Топология сети Bluetooth 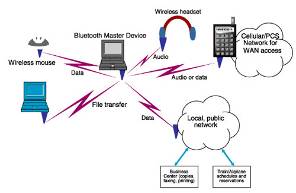 При передачи цифровой информации используются разные виды кодирования, при которых аудиосигнал обычно не повторяется, а данные передаются повторно, если пакет был утерян. Также протокол использует соединение «point-to-point» и «point-to-multipoint» [33]. Thread. Thread – это технология ячеистых сетей передачи данных. В своей значительной части Thread основан на 6LoWPAN, но основным отличием и одновременно преимуществом перед последним является наиболее упрощенный процесс разработки и улучшения взаимодействия с пользователем. Топология сети обеспечивает соединение «устройство-устройство» и «устройство-облако». Данный протокол поддерживает адресацию IPv6 и предоставляет каждому узлу в сети IP-адрес [34]. Основным преимуществом Thread является надежная защита информации на шифровании AES и при этом низкое электропотребление. Действует такая технология на расстоянии до 30 метров и может обеспечивать одновременно до 300 устройств, что является удобным для использования в больших компаниях. Скорость передачи данных также довольно высокая – около 250 кбит/сек, а частота 2,4 ГГц. Рисунок 15. Топология сети Thread 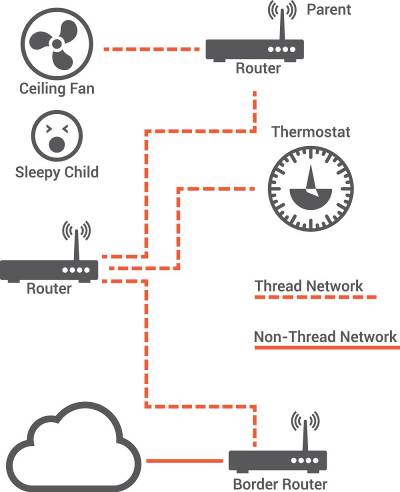 Также к преимуществам стоит отнести простую установку при помощи любого ПК, планшета или смартфона. Так как данная технология разрабатывалась специально для системы «умный дом», то для установки Thread достаточно просто сканировать QR код и авторизоваться [35]. 6. Сравнение протоколов передачи данных В данном разделе приведён сравнительный анализ рассматриваемых протоколов передачи информации для сетей IoT. Представленные в данной таблице протоколы, на данный момент, являются одними из основных протоколов передачи данных в системах интернета вещей. В таблице приведены основные параметры протоколов, необходимы для принятия решения. Данное сравнение проходит по следующим параметрам: транспорт, назначение и особенности. Таблица 1. Сравнение протоколов передачи данных
Из сравнения видно, что одним из самых подходящих протоколов для передачи данных является MQTT. Он отлично подходит для работы с большим количеством элементов в сети и большим количеством запросов [36]. 7. Сравнение стандартов сетей передачи данных В данном разделе приведён сравнительный анализ рассматриваемых технологий передачи информации для сетей IoT. В данной исследовании представлены одни из самых перспективных и интересных для интернета вещей стандарты передачи информации. В приведённой таблице отражены основные параметры необходимые для принятия решения по выбору сетевого протокола. Данное сравнение проходит по следующим параметрам: дальность действия, скорость передачи, частотный диапазон и потребление энергии, а также, стандарт связи, поддержка IP и топология [37]. Таблица 2. Сравнение технологий передачи данных
Из проведённого исследования видно, что для реализации данной системы отлично подходят два стандарта связи: LoRa и Стриж. Они способны передавать небольшие сообщения на большие расстояния что позволит сократить стоимость подключения новых клиентов. А также, данные стандарты не требовательны к размерам аккумуляторной батареи, что позволит использовать минимальное количество энергии на отправку сообщений [38] [39] [40]. 8. Модель системы В рамках данной работы разрабатывается модель системы оплаты в сфере ЖКХ. Ниже приведено описание схемы с указанием необходимых деталей для разработки конечного продукта. Модель. Рисунок 16. Структурная схема системы сбора информации и оплаты 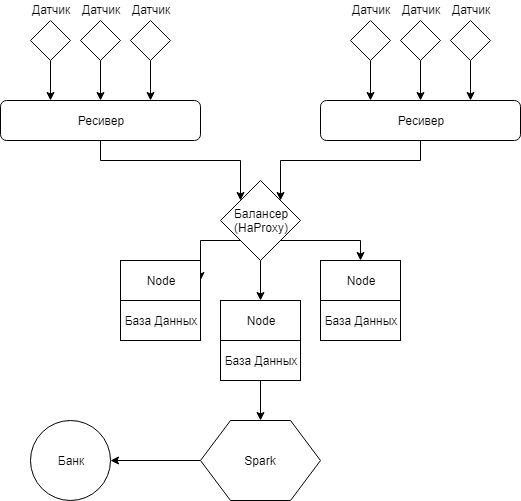 Предлагаемая модель состоит из пять частей основных частей: Сбор данных – отвечает за получение информации на датчиках Балансировка – отвечает за распределение нагрузки внутри имеющейся архитектуры Обработка – отвечает за обработку поступающих запросов от пользователей и работу с данными от датчиков. Агрегация – отвечает за сохранение и анализированные данных пользователей и информации с датчиков Клиентская часть – отвечает за коммуникацию системы с пользователями Сбор и балансировка. Рисунок 17. Схема сбора данных и балансировки нагрузки 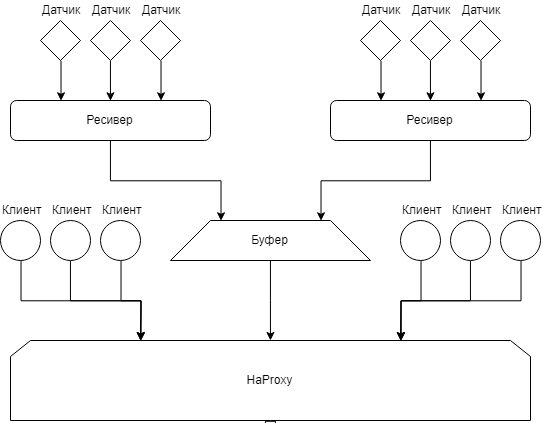 Датчики На данный момент существует огромное количество видов датчиков разных ценовых категорий, производства различных производителей. Можно выбрать новые датчики или добавить специальные надстройки на уже имеющиеся. Они поддерживают большое количество разнообразных стандартов передачи данных и можно подобрать необходимый датчик под любую схему и ценовую категорию. На данный момент жизненный цикл датчиков состоит из производства, доставки и установки, выработки ресурса батареи и замены на новый датчик. Сегодня, такие датчики могут работать автономно в течение более 5 лет [41]. Рисунок 18. Схема счетчика воды 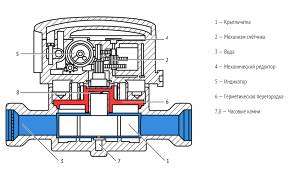 Датчики состоят из магнита и герконового датчика, которые закреплены на двигающейся части устройства. Принцип действия заключается в том, что при каждом перемещении магнита возле датчика, создаётся импульс, соответствующий конкретному расходу воды. Приёмный модуль записывает такой сигнал и конвертирует его в удобный для транспортировки и считывания вид. Далее данные передают эту информацию по каналам связи на наружное устройство или в интернет. На рисунке указан механический датчик с шестернями. Для того, чтобы сделать его электрическим необходимо заменить вычислительный блок на электрический и добавить магнит. Сейчас к таким датчикам можно добавить дополнительный блок, который будет отвечать за перекрытие воды. Такая возможность поможет оперативно отключать воду неплательщикам. Ресиверы. Необходимы для аккумулирования данных с датчиков. Собирает данные с датчиков и находится в постоянной активности. Нужен для обработки запросов от отдельных датчиков и отправки на балансер. Состоит из самого ресивера и базы данных, в которой поддерживается тройная рандомизированная репликация. Для каждого датчика доступен не только локальный ресивер, но и другие ресиверы. Это позволяет сохранить работоспособность системы в критических случаях. На уровне ресивера должна быть реализована политика балансировки нагрузки, так как некоторые датчики могут не иметь локальных ресиверов. Алгоритм работы заключается в том, что датчик отправляет запросы на ресивер и получает ответы о получает ответ о доступности. Если датчик не получает ответ от локального ресивера, он отправляет широковещательный сигнал на другие ресиверы в зоне видимости данной сети. После получения ответа от удалённого ресивера происходит отправка информации через него. Эта схема является более практичной и отказоустойчивой. В качестве системы управления базы данных ресивера хорошо подойдёт SQlite, так как в базе данных необходимо хранить большое количество одинаковых структурированных данных, а также, данный продукт достаточно компактный для встраивания в ресивер. Ещё одним плюсом в пользу SQlite является то, что исходный код данной СУБД находится в открытом доступе. Если провести аналогию, то ресивер – это доска объявлений. Датчики приходят и в определённые места вешают информацию по своему текущему состоянию. В свою очередь сбор информации происходит последовательным считыванием данных объявлений. Буфер. Необходим для фильтрации поступающих запросов и кеширования данных. Является промежуточным этапом в схеме передачи данных с датчиков на сервер. Данный этап нужен для распределения запросов и рассылки данных на серверную часть. Позволяет избежать потери информации. Клиентская часть. В данной работе рассматриваются несколько вариантов для реализации клиентской части. Первым вариантом можно рассматривать создание отдельных приложений для работы с функционалом данной системы. Для прототипа данный вариант подходит отлично, также для первоначального тестирования, так как в данном приложении не будет большого функционала. Основными функциями клиентской части приложения будет просмотр показания датчиков и расчёт текущего долга. Второй вариант подходит к реализации в итоговой версии. Он заключается во включении данного функционала в уже имеющееся приложение как дополнительный функции. Такая реализация позволит уменьшить количество приложений у пользователя, что уменьшит количество отрицательных реакций, а также станет дополнительным рекламным ходом для других пользователей банковского приложения [42]. Для написания приложения под Android можно использовать такие языки программирования как Kotlin или Java. В проектируемой модели предполагается использование Kotlin для написания данного приложения потому, что данный язык программирования обладает следующими свойствами [43]: Компилируется в JavaScript и в байт-код JVM. Поддерживает все существующие Java-фреймворки и библиотеки. Простой для изучения. Открытый исходный код. Существует автоматическая конвертация в Java и обратно. Имеет проверку на Null результат. Для написания приложения под iOS в модели рассматриваются такие языки как Swift и React Native. Проект предполагает использование Swift, так как это компилятор с открытым исходным кодом, а также создан компанией Apple специально для разработчиков под iOS и macOS [44]. При необходимости, например, дабы сократить время на создание приложения можно использовать React Native. Этот выбор обоснован тем, что код написанный на данном фреймворке можно переиспользовать для написания приложения для другой платформы. Также в данной модели учитывается вариант создания Web интерфейса для удобства взаимодействия с данной системой [45]. Приложение для управляющей компании. Для создания web интерфейса планируется использовать Scala. Scala – это объектно-ориентированный язык программирования. Данный язык обладает такими особенностями как функциональность и переиспользуемость написанного кода, что существенно сократит время на создание данного проекта. Управляющая компания. Для управляющей компании в модели учитывается функционал при разработке web части клиентской сферы, с реализованной исходя из ролевой модели. Пользователи будут разделены на группы с разным набором инструментов, зависящих от необходимости в той или иной операции на платформе, например, обычный пользователь имеет доступы только на чтение информации о состоянии датчиков или о балансе на лицевом счёте по каждому адресу. Для работников управляющих компаний будет возможность менять тариф и тому подобное. Для работников банка возможность чтения статистики платежей и так далее. Такая модель поможет обезопасить работу с созданным интерфейсом, а также исключить возможные действия по изменению критических объектов системы со стороны лиц, не имеющих на это право. Кластер Рисунок 19. Структурная схема кластера 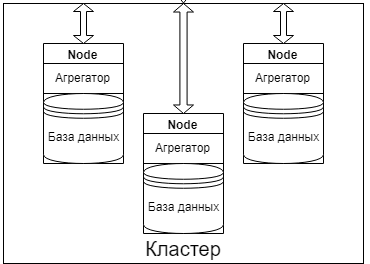 Кластер состоит из некоторого набора Node, которая является основной серверной частью. Каждая из таких Node состоит из агрегатора и базы данных. Агрегатор. Агрегатор отвечает за работу с данными. Он умеет обрабатывать полученные данные, конвертировать их в формат, приемлемы для хранения и сохранять их в базу данных. Также агрегатор умеет обрабатывать запросы пользователей и применять необходимые модели работы с запросами и данными. Также рассматривается вариант обучения данного агрегатора при таковой необходимости [46]. База данных. Рисунок 20. Схема базы данных 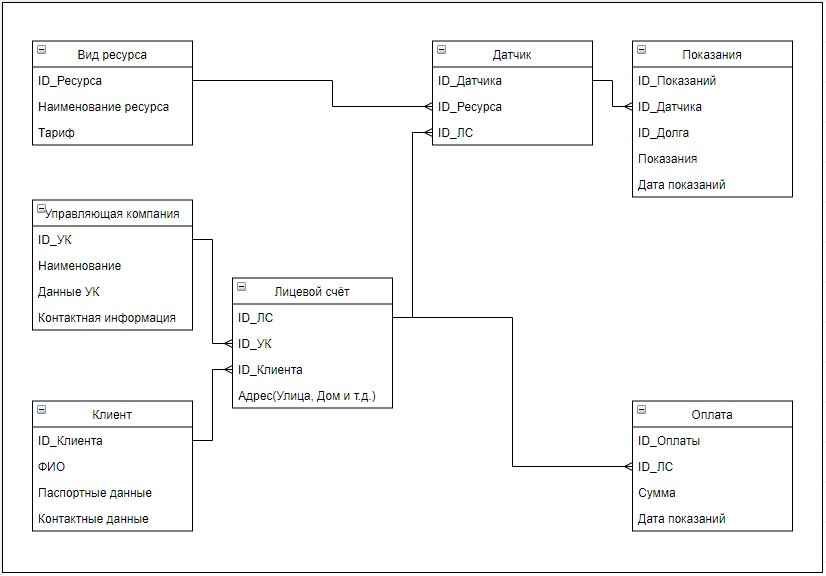 Отвечает за агрегирование, обработку и хранение данных, полученных от счётчиков. Для данной базы данных необходимо учитывать, что система управления базой данных должна справляться с большим количеством запросов. В качестве такой СУБД выбрана PostgreSQL. Она является объектно-реляционной СУБД и обладает большим количеством поддерживаемых типов данных, а также, имеет открытый исходный код и обеспечивает целостность данных. Также данная СУБД поддерживает расширение функционала, за счёт возможности сохранения своих процедур [47]. Каждая Node не знает о существовании других таких же элементов и является самодостаточной. В каждой точке хранится полный набор данных, что позволяет продолжать бесперебойную работу всей системы. При этом позволяя обрабатывать огромное количество запросов от пользователей и обработку получаемых данных. 9. Агрегация данных Для реализации агрегации данных подойдёт Apache Spark. Spark – это фреймворк с открытым исходным кодом, предназначенный для обработки слабоструктурированных данных. В этом фреймворке используются специальные примитивы для обработки в оперативной памяти, что позволяет получить высокую скорость работы системы, особенно при необходимости многократного доступа к загружаемым в память данным пользователя. Агрегатор данных позволит создавать и анализировать полученную информацию, вести отчётность и статистику [48]. Рисунок 21. Схема агрегатора |