ревью. 1 Что такое дженерики Какую проблему они решают. 2 Wildcard 3 Принцип pecs 4 Параметризация статических методов
 Скачать 104.74 Kb. Скачать 104.74 Kb.
|

|
1) Что такое дженерики? Какую проблему они решают. 2) Wildcard 3) Принцип PECS 4) Параметризация статических методов. 5) Что такое коллекция. Иерархия коллекций. 6) Внутреннее устройство коллекций. 1) Что такое дженерики? Какую проблему они решают? (//1, //2) Дженерики (обобщения) — это особые средства языка Java для реализации обобщённого программирования: особого подхода к описанию данных и алгоритмов, позволяющего работать с различными типами данных без изменения их описания. Одно из назначений дженериков — более сильная проверка типов во время компиляции и устранение необходимости явного приведения. Дженерики позволяют типизировать методы. Короче говоря, дженерики позволяют типам (классам / интерфейсам / методам) быть параметрами при определении классов, интерфейсов и методов. Дженерики позволяют повторно использовать один и тот же код с разными входными данными (параметрами типов). Когда появились дженерики? Дженерики появились в Java 5, в Java 7 появился даймонд оператор. До появления дженериков использовались коллекции (Java Collection Framework) для хранения объектов любого типа, т.е. непатентованных. Дженерики и поля класса Невозможно типизировать статические поля, нестатические можно Если поле типизировано дженериком как в байт коде будет представлен этот тип? Object Какой механизм обеспечивает обратную совместимость сырых типов и дженериков? (//1) Стирание типов или Type Erasure – стирание какой-либо информация о дженериках при компиляции. Стирание типов и дженерики сделаны так, чтобы обеспечить обратную совместимость со старыми версиями JDK. Стирание типов состоит из трех действий: 1. Если параметры ограничены (bounded), вместо типа-параметра в местах использования подставляется верхняя граница, иначе Object; 2. В местах присвоения значения типа-параметра в переменную обычного типа добавляется каст к этому типу; 3. Генерируются bridge-методы. Это когда компилятор генерирует новый метод, который совпадает по сигнатуре с родительским. В его теле параметр кастуется и вызов делегируется в пользовательский метод. Информация о типах стирается только из методов и полей, но остается в метаинформации самого класса. Получить эту информацию в Runtime можно с помощью Reflection, методом Field#getGenericType. Тип со стертой информацией о дженериках называется «Non-reifiable». Стирание типов позволяет не создавать при применении дженериков новые классы, в отличие от, например, шаблонов C++. Параметр vs Аргумент (в дженериках) Параметр типа (type parameter). Используются при объявлении дженерик-типов. Например, для Box Аргумент типа (type argument). Тип объекта, который может использоваться вместо параметра типа. Например, для Box Paper — это аргумент типа. 2) Wildcard (//1) У дженериков есть понятие Wildcard – это дженерик вида , что означает, что тип может быть чем угодно (List - лист неизвестного типа). Используется, например, в коллекциях, если планируется использовать функционал класса Object. Wildcard в свою очередь делятся на три типа: Upper Bounded Wildcards - Unbounded Wildcards - Lower Bounded Wildcards - Чему эквивалентно - неограниченный символ подстановки, это означает, что тип может быть чем угодно. Что такое даймонд оператор? Оператор <> был введен в Java 7, чтобы сделать код более читабельным и, по сути, является синтаксическим сахаром. <> добавляет вывод типов и уменьшает многословность при использовании дженериков. Компилятор, видя справа <>, смотрит на левую часть, где расположено объявление типа переменной, в которую присваивается значение. И по этой части понимает, каким типом типизируется значение справа. Что такое raw type? Это имя универсального класса или интерфейса без каких-либо аргументов типа (пример List<> kist = new ArrayList<>()). Они нужны только для поддержки обратной совместимости кода, «сырые типы» являются не «типобезопасными». В подобную коллекцию можно положить любые типы. К чему приводит использование raw type? Придется каждый раз использовать явное приведение типов, отсутствие типобезопасности – что может привести к ошибкам во время Runtime. Отличие raw type от даймонд оператора? Если мы используем типизированные типы необходимо всегда использовать diamond синтаксис иначе получим в логе uses unchecked or unsafe operations. Если класс типизирован, всегда указывать тип в дженерике. Можно ли объявить так: class Animal {} Так объявить нельзя. Цель параметризации класса - передать внутрь тип-переменную, которая будет использована внутри класса. Wildcard для этого не подходит. 3) Принцип PECS (//1, //2) «Producer - extends, Consumer - super». С Wildcard действует так называемый Get Put principle, Данный принцип ещё называют принципом PECS. * Используйте ExClass>, когда вы только получаете значения из структуры (Ковариантность) * Используйте ExClass >, когда вы только помещаете значения в структуру (Контрвариантный) * НЕ используйте подстановочный знак, когда вы хотите и получить и поместить что-то в структуру (Инвар.) Если метод имеет аргументы с параметризованным типом (например, Collection то в случае, если аргумент — производитель ( а если аргумент — потребитель (consumer), нужно использовать . Производитель и потребитель, кто это такие? Очень просто: если метод читает данные из аргумента, то этот аргумент — производитель, а если метод передаёт данные в аргумент, то аргумент является потребителем. Важно заметить, что определяя производителя или потребителя, мы рассматриваем только данные типа T. Инвариантность — отсутствие наследования между производными типами. Если Cat — это подтип Animals, то List Ковариантность — это сохранение иерархии наследования исходных типов в производных типах в том же порядке. Например, если Cat — это подтип Animals, то List Следовательно, с учетом принципа подстановки можно выполнить такое присваивание: List Контрвариантность — это обращение иерархии исходных типов на противоположную в производных типах. Например, если Cat — это подтип Animals, то List Следовательно, с учетом принципа подстановки можно выполнить такое присваивание: List
4) Параметризация статических методов Что можно параметризировать? Можно параметризировать только ссылочные типы. Что нельзя параметризировать? Нельзя параметризировать примитивы, нельзя параметризировать enum, анонимные классы и классы-исключения (Exception). Невозможно объявить статические поля, типы которых являются параметрами типа. Невозможно использовать приведение или instanceOf с параметризированными типами. Как параметризировать статический метод? Так же, как и обычный метод, но с одним отличием – перед возвращаемым значением должен явно быть указан дженерик. Статические методы не могут иметь или обращаться к generic-полям. public static public static Что мы можем подставить в метод с параметром , если класс параметризован как Class Если метод статический, то любой тип, T / R / U Если метод не статический, то только T В чем отличие в записях в параметре метода: (Collection collection) и ((Collection collection)? Во втором случае мы можем присвоить в эту ссылку любую коллекцию типа T или наследника T, а также получить предков T из этой коллекции, ничего положить в неё нельзя (ковариантность). В первом случае мы можем присвоить в эту ссылку коллекцию любого типа. Положить в эту коллекцию ничего нельзя, получить из неё можно только Object. 5) Что такое коллекция. Иерархия коллекций. Коллекции – это хранилища, поддерживающее различные способы накопления и упорядочения объектов с целью обеспечения возможностей эффективного доступа к ним. Коллекции похожи на массивы, но имеют намного большей возможностей. Основной функционал определен в интерфейсе Collection. (не путать с классом Collections – утилитарным классом, который содержит методы для работы с коллекциями). Какие структуры данных вы знаете? Структура данных – это контейнер, который хранит информацию в определенном виде. Из-за такой «компоновки» она может быть эффективной в одних операциях и неэффективной в других. Цель разработчика – выбрать из существующих структур оптимальный для конкретной задачи вариант. Array (T[]) - когда количество элементов фиксировано и требуются индексы. Enum – перечисление может включать конструкторы, поля и методы LinkedList - когда необходимо добавить элементы в оба конца списка. В противном случае используйте List. List - когда количество элементов не фиксировано и необходимо использовать индексы. Stack - когда вам нужно внедрить LIFO (Last In First Out). Queue - когда необходимо реализовать FIFO (First In First Out). HashMap - когда вам нужно использовать пары ключ-значение для быстрого добавления и поиска. HashTable - когда вам нужно использовать пары ключ-значение (ключ-значение) для быстрого добавления и поиска, а элементы не имеют определенного порядка. Отличие коллекции от массива? Массивы — это простые конструкции фиксированного размера, и поэтому они могут хранить только заданное количество элементов. Коллекции — это более сложный, но более гибкий тип данных. Размер коллекции можно изменять: вы можете добавлять и удалять из коллекции элементы (удалять из любой позиции). 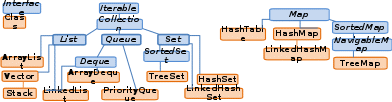 Иерархия коллекций На чем основаны основные реализации коллекций? List - упорядоченный список, в котором у каждого элемента есть индекс. Дубликаты значений допускаются. Set - неупорядоченное множество уникальных элементов. Queue - очередь. В таком списке элементы можно добавлять только в хвост, а удалять — только из начала. Так реализуется концепция FIFO (first in, first out) — «первым пришёл — первым ушел». Map - состоит из пар «ключ-значение». Ключи уникальны, а значения могут повторяться. Порядок элементов не гарантирован. Map позволяет искать объекты (значения) по ключу. Map не наследуется от интерфейса Collection, но входит в состав фреймворка Collections. Что такое Map? Что должно быть уникальным? Map – интерфейс. Map содержит пары ключ - значение (Entry). Map должна содержать уникальные ключи. Почему Map не входит в Collection? List, Set и Queue это коллекции однотипных объектов, тогда как Map это подразумевает 2 типа объектов (пар ключ-значение). Соответственно некоторые методы интерфейса Collection нельзя использовать в Map. Например, метод remove(Object o) в интерфейсе Collection предназначен для удаления элемента, тогда как такой же метод remove(Object key) в интерфейсе Map - удаляет элемент по заданному ключу. В чём разница между Queue и Deque и Stack? Queue (односторонняя очередь) - когда элементы можно получить в том порядке, в котором добавляли (FIFO) Deque (двусторонняя очередь) - можно вставлять/получать элементы из начала и конца. (LIFO / FIFO) Stack работает по схеме LIFO. Всякий раз, когда вызывается новый метод, содержащий примитивные значения или ссылки на объекты, то на вершине стека под них выделяется блок памяти. Расскажи отличие List от Set? List хранит объекты в порядке вставки, элемент можно получить по индексу. Set не может хранить одинаковых элементов. Методы интерфейса Collection? add (E obj) (return boolean) addAll (Collection coll) (return boolean) clear () contains (Object o) (return boolean) containsAll (Collection coll) (return boolean) equals (Object obj) (return boolean) - сравнивание 2-х коллекций hashCode () (return hashCode коллекции) isEmpty () (return boolean) iterator () (return итератор коллекции) remove (Object obj) (return boolean) removeAll (Collection сoll) (return boolean) retainAll (Collection сoll) (return boolean) - удаляет все элементы кроме входящих в коллекцию size () (return int) toArray() (return Object[]) возвращает массив копий элементов коллекции. removeIf (Predicate filter) - удаляет элементы из коллекции, по условию. toArray(T[] a) (return T[]) возвращает массив копий элементов коллекции 6) Внутреннее устройство коллекций ARRAYLIST / LINKEDLIST Отличие ArrayList от LinkedList? ArrayList - это список на основе массива. LinkedList - связанный список на основе элементов и связи между ними. Отличие двусвязного и односвязного списка Двусвязный список похож на обычный связный список, только элементы в нем хранят ссылки не только на следующий, но и на предыдущий элемент. Благодаря этому свойству, можно перемещаться по списку вперед и назад. Как устроен LinkedList? LinkedList – двусвязный список. В LinkedList элементы фактически представляют собой звенья одной цепи. У каждого элемента помимо тех данных, которые он хранит, имеется ссылка на предыдущий и следующий элемент. Объект List, содержит поля header и size. header — псевдо-элемент списка. Его значение всегда равно null Внутри класса LinkedList существует static inner класс Entry, с помощью которого создаются новые элементы. Каждый раз при добавлении нового элемента, по сути выполняется два шага: создается новый экземпляр класса Entry переопределяются указатели на предыдущий и следующий элемент Когда лучше использовать ArrayList, а когда LinkedList? ArrayList - это список на основе массива. LinkedList - связанный список на основе элементов и связи между ними. Если часто вставляете/удаляете элементы - выбираем LinkedList, в противном случае ArrayList. LinkedList когда требуется провести много операций именно вначале списка. Так как перебор элементов списка предположим до середины будет занимать много времени, тогда как сама вставка/удаление пройдет за константное время. ArrayList при вставке / удалении элемента в середине списка вызывает смещение элементов, но проводится оно, нативной низко-уровневой командой System.arraycopy и не занимает много времени, так же в ArrayList нет дополнительных расходов на хранение связки между элементами. Скорость вставки элемента в начало середину и конец у ArrayList vs LinkedList ? У ArrayList вставка и удаление элементов в конце происходит быстро, а в середину и начало - медленно, потому что приходится сдвигать все элементы после операции с элементом. Чтобы вставить/удалить элемент в LinkedList необходимо всего лишь поменять ссылки в соседних элементах, поэтому эта операция осуществляется быстрее. Почему последняя строчка не скомпилируется? List ArrayList
Слева и справа разные типы, у дженериков нет наследования в данном виде. Мы имеем по 100 тыс. элементов в ArrayList и LinkedList и хотим вставить еще 100 тыс., куда будет быстрее вставка? ArrayList при вставке / удалении в середине списка вызывает смещение элементов, но проводится оно нативной низкоуровневой командой System.arraycopy и не занимает много времени. LinkedList оптимальнее, когда требуется провести много операций именно в начале списка. Вставка в LinkedList происходит за константное время. Как работает метод contains() в ArrayList, LinkedList, HashSet? Метод contains в Arraylist использует метод indexOf (), который использует в свою очередь метод indexOfRange (). Там совершается обход элементов в цикле и если элемент не null, то вызывается стандартный метод equals (сравнение ссылок). Тоже самое для LinkedList. В методе contains HashSet используются «корзины» и поиск объекта происходит сначала по hashcode, а только потом по equals. HASHMAP Как работает HashMap? Расскажите подробно, как работает метод put? Что происходит при коллизии? Структура данных, которая хранит пары ключ-значение. Класс HashMap наследуется от класса AbstractMap и реализует следующие интерфейсы: Map, Cloneable, Serializable. HashMap это фактически массив Нодов (Node), каждый элемент массива образует односвязный список Нодов (LinkedList). Каждому элементу массива соответствует один список. HashMap работает по принципам хеширования. Хеширование - это способ преобразования любой переменной/объекта в уникальный код после применения любой формулы/алгоритма к их свойствам. Node – это вложенный класс внутри HashMap, который имеет поля int hash, K key, V value, Node Расскажите подробно, как работает метод put? 1) Сначала проверяется, равен ли ключ null. Если ключ null, значение помещается в таблицу на нулевую позицию, так как хеш код null = 0 2) Если ключ не null, то рассчитывается хеш-значение использую хеш-код ключа, с помощью метода hashCode(). 3) Вызывается метод indexFor(hash, table.lengh()) для вычисления индекса, куда будет помещен объект Node (или TreeNode при древовидной структуре). Хеш-значение трансформируется так, что его значение сопоставлялось с количеством элементов в массиве. 4) Если в данном бакете уже есть объекты, то в конец списка добавляется новый Node, ссылка на него записывается в предыдущий. 5) Если в списке был найдет элемент с таким же ключом, то он заменяется. Добавление, поиск и удаление элементов выполняется за константное время, при условии, что хеш-функция должны равномерно распределять элементы по корзинам, в этом случае временная сложность для этих 5-ти операций будет не ниже lg N, а в среднем случае как раз константное время. Чем ограничен размер Hashmap? HashMap использует массив, размер которого всегда равен степени двойки, поэтому он может состоять не более чем из 2 в 30 степени = 1073741824 элементов (поскольку следующая степень двойки больше Integer.MAX_VALUE). Однако вы можете продолжать добавлять элементы в таблицу до бесконечности, поскольку цепочки хэшей представляют собой простые связанные списки. Производительность будет снижаться по мере роста цепочки хеширования. Как расширяется HashMap? При каких условиях лист в HashMap преобразуется в красно-черное дерево? * Первоначальный размер HashMap = 16 бакетов (ячеек массива). Когда массив заполняется на 75% (loadFactory = 0.75), размер массива увеличивается в 2 раза, т.е. 32 бакета. * При увеличении размера массива все объекты, уже содержащиеся в HashMap, будут распределены уже по новым бакетам с учетом их нового количества. * Каждый бакет содержит в себе ноды, когда этих нодов становится 7, а бакетов 64, то структура Нодов перестраивается в красно-черное дерево(TreeNode). Что такое красно-черное дерево? Это один из видов самобалансирующихся бинарных деревьев поиска (каждый узел имеет не более 2-х наследников), гарантирующих логарифмический рост высоты дерева от числа узлов и позволяющее быстро выполнять основные операции: добавление, удаление и поиск узла. Как обойти HashMap через for-each? Вызвать метод entrySet(), который возвращает Set объектов Entry (пар ключ-значение), далее преобразовать в стрим методом stream() и на стриме вызвать forEach(). * Вызвать метод keySet(), у него вызвать iterator, на нем выполнить while Как итерироваться по мапе? Получить методом entrySet() Set объектов Entry, далее можно циклом for, можно foreach через стрим. Итерация с использованием Iterator (с дженериками или без) - Это единственный метод, который позволяет удалять записи с карты во время итерации, вызывая iterator.remove(). С точки зрения производительности этот метод равен Итерации For-Each. Может ли null быть ключём в HashMap? HashMap оперирует с null-ключом без каких-либо проблем, хэшкод у null в HashMap = 0 Как работает метод get в HashMap? (что возвращает get() в мапе) Метод get имеет ту же логику что и put. Как только HashMap определяет ключ объекта, переданного в аргументе, он просто возвращает значение соответствующего объекта Node. Если же совпадений не найдено, метод get вернет null. Как сравниваются ключи в мапе? Сравниваются по хешкоду, при необходимости по equals Что происходит с нодами когда мапа перестраивается? ХешКоды ключей пересчитываются и ноды перераспределяются по корзинам с учетом новой структуры. Когда под мапу выделяется память? При объявлении(?) При расширении (?) HASHSET Три реализации Set. Упорядоченность в HashSet, LinkedHashSet, TreeSet (Какая упорядоченность в какой и почему)? К семейству интерфейса Set относятся HashSet, TreeSet и LinkedHashSet. В множествах Set разные реализации используют разный порядок хранения элементов. В HashSet порядок элементов на основе hash-таблиц, оптимизирован для быстрого поиска. В контейнере TreeSet объекты хранятся на основе «деревьев» отсортированными по возрастанию. LinkedHashSet хранит элементы в порядке добавления. HashSet массив в котором бакеты -связанные массивы (LinkedList). default размер 16 бакетов, load factor 0.75, удваивает размер, может хранить null, не хранит порядок элементов, т.к. бакет определяется по хэшу, макс бакетов 2^30 (1073741824) LinkedHashSet - массив с корзинами, но элементы в нем связаны двунаправленным списком. Хранит порядок добавления элементов. TreeSet (бинарное красно-чёрное дерево - сортирует по умолчанию). Как реализован HashSet? Класс HashSet реализует интерфейс Set, основан на хэш-таблице, а также поддерживается с помощью экземпляра HashMap. Хранит уникальные элементы и допускает null, не потокобезопасен, не поддерживает порядок вставки. Как работает HashSet? Реализует интерфейсы Set / Serializable / Cloneable Обычный массив, в котором бакеты - связанные массивы default размер 16, load factor 0.75, удваивает размер, может хранить null Не допускает дублей, не синхронизирован, построен на HashMap Поля выступают в роли ключей HashMap, значениями HashMap выступает константа Порядок добавления элементов вычисляется с помощью хэш-кода Элементы не упорядочены, нет никаких гарантий, что элементы будут в том же порядке спустя какое-то время Операции добавления, удаления и поиска будут выполняться за константное время Что кладётся на место значения в HashSet? Метод add у HashSet вызывает метод put у внутреннего объекта HashMap – на место ключа кладётся добавляемый элемент, на место значения кладётся константа new Object() (метод возвращает Boolean) константа private static final Object PRESENT = new Object() Почему в HashSet вместо value не null а new Object? HashSet хранит new Object(), потому что в контракте указывается метод remove() который возвращает true, если указанный объект существовал и был удален. Для этого он использует обёртку, HashMap#remove() который возвращает удаленное значение. Если бы вы сохранили null вместо объекта, то вызов HashMap#remove() вернул бы null, что было бы неотличимо от результата попытки удалить несуществующий объект, и контракт HashSet.remove() не мог бы быть выполнен. Null в TreeSet? В красно-черное дерево нельзя поместить ни null, ни объекты, которые JVM не может сравнить (больше-меньше). 4) Параметризация статических методов Что произойдет? Почему отработает 2 метод? Как это исправить? public class Ex1 { public static void main(String[] args) { List Gen gen = new Gen(); gen.m(integerList); } static class Gen for (T s : collection) { System.out.println(s); } } for (String s : list) { System.out.println(s); } } } При такой записи отработает второй метод и вылетит исключение ClassCastException. Нужно добавить WildCard чтобы отработал первый метод: Gen gen = new Gen<>(); Gen ITERATOR Что такое Iterator? Это объект с состоянием итерации. Он позволяет проверить, есть ли в нем следующий элемент, используя hasNext() и перейти к следующему элементу используя next(). Так же имеет метод remove(). Как реализовать Iterator? С помощью метода интерфейса Collection - iterator(). Он возвращает итератор – объект, реализующий интерфейс iterator. В каких случаях нужно использовать Iterator? И почему? Можно использовать итератор в случае если есть необходимость удаления элементов из коллекции при обходе (при использовании для удаления for each будет выброшено исключение ConcurrentModificationEx). В чём разница между Iterable и Iterator? Iterable – интерфейс в котором есть один метод, который возвращает iterator. Iterator – это объект с состоянием итерации. Можно ли с помощью цикла for-each изменить поле объектов, которые находятся в массиве? И можно ли изменить сам объект? Элемент из КОЛЛЕКЦИИ в цикле for-each удалить нельзя, т.к. нельзя проводить одновременно итерацию (перебор) коллекции и изменение ее элементов. Итератор этого учесть не может. Значения элементов массива менять можно! Зачем в итераторе метод remove? Метод remove удаляет текущий элемент, который был получен последним вызовом next. В обычном цикле при итерации по коллекции нельзя изменять размер коллекции, в итераторе – можно. Отличие Iterator и ListIterator. ListIterator расширяет интерфейс Iterator. ListIterator может быть использован только для перебора элементов коллекции List. Iterator позволяет перебирать элементы только в одном направлении, при помощи метода next(). Тогда как ListIterator позволяет перебирать список в обоих направлениях (методы next и previous). ListIterator не указывает на конкретный элемент: его текущая позиция располагается между элементами, которые возвращают методы previous() и next(). При помощи ListIterator вы можете модифицировать список, добавляя/удаляя элементы с помощью методов add() и remove(). Iterator не поддерживает данного функционала. КОЛЛИЗИЯ Что такое коллизия? Ситуация, когда у разных объектов одинаковые хеш-коды называется — коллизией. Вероятность возникновения коллизии зависит от используемого алгоритма генерации хеш-кода. Потому, что хеш-код имеет интовый размер 32 бита, а поэтому его значения конечны. Т.е входных данных может бесконечное множество, а выходов только в рамках значений int (2,147 млрд). Но хеш-функция считается устойчивой к коллизиям, когда вероятность обнаружения коллизии настолько мала, что для этого потребуются миллионы лет вычислений. Если хеш-коды разные, то и входные объекты гарантированно разные. Если хеш-коды равны, то входные объекты не всегда равны. Коллизия возникает в том числе, если два объекта key имеют одинаковый хэш-код. Как будет разрешаться коллизия? Существует два основных способа разрешения коллизий: Метод цепочек: В этом случае корзина (bucket) может хранить несколько элементов, и хранятся они, в большинстве случаев, в виде связного списка (linked list). Метод открытой адресации: Здесь, при возникновении коллизии, происходит поиск некоторой свободной ячейки, куда и добавляется очередной элемент. В Java, для разрешения коллизий, используется метод цепочек. Изначально, корзина в HashMap представляет из себя связный список (LinkedList). При возникновении коллизии, очередная пара добавляется в этот список. В последних версиях JDK, в случае, если количество нодов в бакете достигает 7, то происходит преобразование связного списка в красно-черное дерево, при этом, найти элемент в HashMap в худшем случае уже можно за O(log(n)), а не за O(n), как в связном списке. |