Ревью #1 - JDBC, Hibernate. 1. Что такое Maven Для чего он нужен Как добавлять в проект библиотеки без него
 Скачать 0.65 Mb. Скачать 0.65 Mb.
|

|
Хранимая процедура - это блок кода, который сохраняется в базе данных и может быть вызван для выполнения на стороне сервера БД. Она может содержать любые операторы SQL, управляющие конструкции, переменные и параметры. Хранимые процедуры создаются и хранятся на сервере БД, и могут быть вызваны клиентским приложением по требованию. Хранимые процедуры позволяют повысить производительность, расширяют возможности программирования и поддерживают функции безопасности данных. (Вот пример создания хранимой процедуры на SQL для базы данных MySQL:  Эта хранимая процедура называется get_user и имеет три параметра: user_id - входной параметр типа INT, user_name и user_email - выходные параметры типа VARCHAR(50). Внутри хранимой процедуры выполняется запрос к таблице users, и результаты запроса записываются в переменные user_name и user_email. После создания хранимой процедуры ее можно вызывать из приложения, используя JDBC CallableStatement, как показано в предыдущем ответе.) 7. Что такое sql-injection? SQL-инъекция (или SQLi) – уязвимость, которая позволяет атакующему использовать фрагмент вредоносного кода на языке SQL для манипулирования базой данных и получения доступа к потенциально ценной информации. Вредоносный код вставляется в строки, которые позже будут переданы на экземпляр SQL Server для анализа и выполнения. (' or'1'='1) Как защитить приложение от sql-injection? Использовать PreparedStatement вместо Statement. При использовании Statement строки запроса и значений складываются. Т.к. выражение or'1'='1' всегда равно true, то даже без указания пароля мы получим все данные.) При использовании PreparedStatement имеется шаблон запроса и данные в него вставляются, с отражением кавычек. Т.е. все кавычки были отражены слешем, инъекция не удалась. Так же можно создать проверки всех вводимых данных – числа, строки, даты, данные в специальных форматах. Числа Для проверки переменной на числовое значение используется функция is_numeric(n);, которая вернёт true, если параметр n — число, и false в противном случае. Строки Большинство взломов через SQL происходят по причине нахождения в строках «необезвреженных» кавычек, апострофов и других специальных символов. Для такого обезвреживания нужно использовать функцию addslashes($str);, которая возвращает строку $str с добавленным обратным слешем (\) перед каждым специальным символом. Данный процесс называется экранизацией. (Магические кавычки Магические кавычки – эффект автоматической замены кавычки на обратный слэш (\) и кавычку при операциях ввода/вывода.) Отличие Statement от PreparedStatement? Statement - мы должны заботиться о кавычках в запросе и ставить их там где они нужны. PreparedStatement - вставляет значения в запрос и за счет методов setString setInt и прочих. Он сам понимает где нужны кавычки, а где нет. Соответственно все входные данных оборачивает ими. Преимуществ PreparedStatement по сравнению с Statement: 1) PreparedStatement помогает нам предотвратить атаки с использованием SQL-инъекций, поскольку он автоматически экранирует специальные символы. 2) PreparedStatement позволяет нам выполнять динамические запросы с вводом параметров. 3) PreparedStatement предоставляет различные типы методов установки для установки входных параметров запроса. 4) PreparedStatement быстрее, чем Statement. Это становится более заметным, когда мы повторно используем PreparedStatement или используем его методы пакетной обработки для выполнения нескольких запросов. 5) PreparedStatement помогает нам писать объектно-ориентированный код с помощью методов установки, тогда как с Statement мы должны использовать конкатенацию строк для создания запроса. Если необходимо установить несколько параметров, написание запроса с использованием конкатенации строк выглядит очень некрасиво и подвержено ошибкам. 8. Что такое ResultSet? Как с ним работать? Что такое ResultSet? Интерфейс ResultSet — представляет собой результат выполнения запроса к базе данных. Он содержит набор строк, который может быть получен и обработан по одной строке за раз. (Внутри него таблица.) ResultSet позволяет перемещаться по строкам результата, извлекать данные из столбцов и выполнять другие операции над полученными данными. Это интерфейс, который предоставляет методы для работы с результатами выполнения SQL-запросов. Экземпляры этого элемента содержат данные, которые были получены в результате выполнения SQL – запроса. Он работает как итератор и “пробегает” по полученным данным. Объект с результатом запроса, который вернула база. Внутри него таблица. Как с ним работать? Для работы с ResultSet необходимо выполнить следующие шаги: 1) Создать объект Statement или PreparedStatement, который будет использоваться для выполнения запроса к базе данных. 2) Выполнить запрос к базе данных, используя созданный объект Statement или PreparedStatement. 3) Получить объект ResultSet из выполненного запроса, вызвав метод executeQuery() на объекте Statement или PreparedStatement. 4) Обработать результат, перемещаясь по строкам ResultSet, извлекая данные из столбцов и выполняя другие операции над полученными данными. (Пример кода для работы с ResultSet: 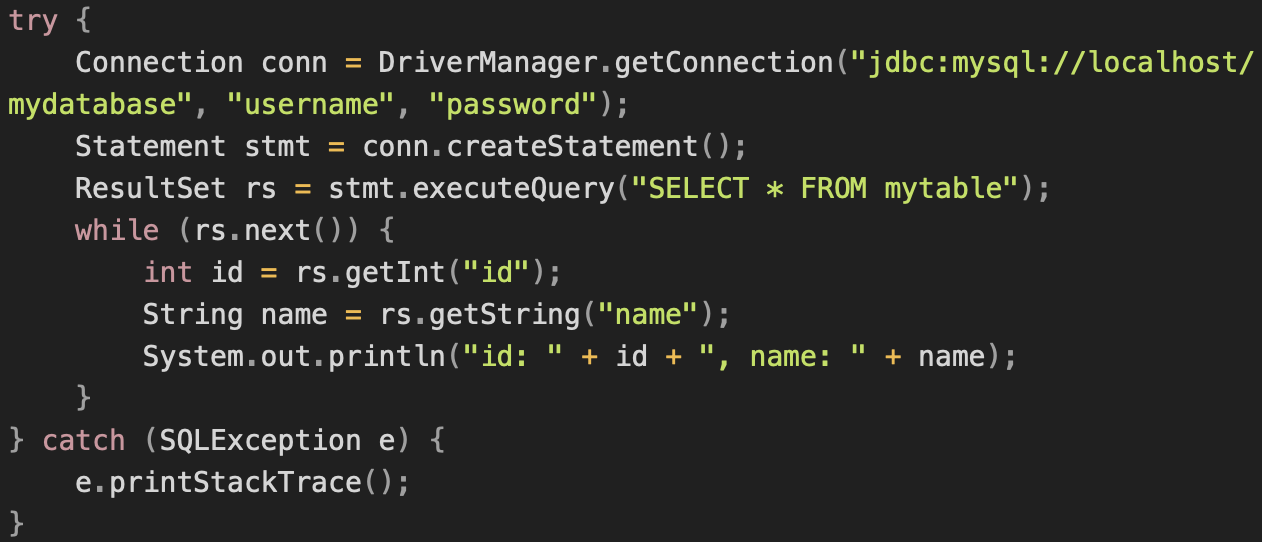 В этом примере мы создаем соединение к базе данных, создаем объект Statement, выполняем запрос к базе данных и получаем объект ResultSet. Затем мы перемещаемся по строкам ResultSet, извлекаем данные из столбцов и выводим их на консоль.) Как с помощью ResultSet получить данные из 2 строки 2 колонки таблицы? Для получения данных из 2 строки 2 колонки таблицы с помощью ResultSet необходимо сделать следующее: 1. Используя метод next() переместитесь на вторую строку таблицы. 2. Используя метод getXXX(2) (где XXX - тип данных, которые нужно получить (например, getInt(2), getString(2) и т.д.) получаем значение второй колонки второй строки. Вывод на экран значения 2 столбца 2 строки неизвестного типа данных: PreparedStatement ps = connection.prepareStatement("SELECT * FROM tableName"); ResultSet resultSet = ps.executeQuery(); resultSet.next(); // переход на 1 строку resultSet.next(); // переход на 2 строку Object value = resultSet.getObject(2); // присваиваем значение 2 столбца System.out.println(value); Пример кода: ResultSet rs = ... // create ResultSet object int val1, val2; rs.next(); // move to first row val1 = rs.getInt(2); // get the value from second column of first row rs.next(); // move to second row val2 = rs.getInt(2); // get the value from second column of second row System.out.println("Value1: " + val1 + " , Value2: " + val2); (В этом примере мы используем getInt(2), потому что мы хотим получить значения только из второй колонки второй строки. Если нужно получить значение из другой колонки, то нужно передавать другой порядковый номер столбца в метод getInt().) Методы и их описание Доступ к данным ResultSet обеспечивает посредством набора get-методов, которые организуют доступ к колонкам текущей строки. Метод ResultSet.next используется для перемещения к следующей строке ResultSet, делая ее текущей. void deleteRow() - Удаляет текущую строку из результирующего набора и базы данных int getRow() - Возвращает номер текущей строки Statement getStatement() - Возвращает экземпляр Statement, который произвел данный результирующий набор boolean next/previou ()- позволяют переместиться в результирующем наборе на одну строку вперед или назад
result.getInt("columnName");... 9. Рассказать про паттерн DAO Паттерн DAO (Data Access Object) используется в приложениях для управления доступом к данным. Его основная задача заключается в том, чтобы разделить бизнес-логику приложения и доступ к данным. Это позволяет создать слой доступа к данным, который может быть изменен независимо от остальной части приложения. Смысл в том, чтобы создать специальную прослойку, которая будет отвечать исключительно за доступ к данным (работа с базой данных или другим механизмом хранения). Подразумевает абстрагирование всей работы с базой данных в отдельном слое. DAO позволяет разделить слой доступа к данным на две части. Должен состоять из: DAO интерфейс (или суперкласс), определяет методы, которые могут быть использованы для получения, создания, обновления и удаления данных из базы данных DAO реализация, целевой класс, реализующий методы интерфейса. Особенности использования паттерна DAO: 1) Используется для абстрагирования и инкапсулирования доступа к источнику данных; 2) Управляет соединением с источником данных для получения и записи данных; 3) Реализует необходимый для работы с источником данных механизм доступа; 4) Выполняет функцию адаптера между компонентом и источником данных. Преимущества использования паттерна DAO: Разделение бизнес-логики приложения и слоя доступа к данным; Упрощение тестирования приложения; Улучшение модульности приложения; Упрощение замены хранилища данных. 10. Что такое JPA? (когда за вас пишутся все запросы, а вы только работаете с объектами) (JPA - унифицированный интерфейс для взаимодействия с БД.) JPA (Java Persistence API) это спецификация (стандарт, технология Java EE и Java SE), обеспечивающая объектно-реляционное отображение (ORM) простых JAVA-объектов (Plain Old Java Object - POJO) и предоставляющая универсальный API для управления (сохранения, получения и управления) такими объектами в БД. Сама Java не содержит реализации JPA. JPA позволяет разработчикам работать с объектами и классами Java вместо SQL, упрощая процесс взаимодействия с базой данных. Он позволяет использовать аннотации Java для настройки отображения Java-классов на таблицы в базе данных. Сам JPA не умеет (ни сохранять, ни) управлять объектами, JPA только определяет правила игры: как должен действовать каждый провайдер (Hibernate, EclipseLink, OJB, Torque и т.д.), реализующий стандарт JPA. Для этого JPA определяет интерфейсы, которые должны быть реализованы провайдерами. Также JPA определяет правила, как должны описываться метаданные отображения и как должны работать провайдеры. Каждый провайдер обязан реализовывать всё из JPA, определяя стандартное получение, сохранение и управление объектами. Помимо этого, провайдеры могут добавлять свои личные классы и интерфейсы, расширяя функционал JPA. (JAVA-код, написанный только с использованием интерфейсов и классов JPA, позволяет разработчику гибко менять одного провайдера на другого. Например, если приложение использует Hibernate как провайдера, то ничего не меняя в коде можно поменять провайдера на любой другой. Но, если мы в коде использовали интерфейсы, классы или аннотации, например, из Hibernate, то поменяв провайдера на EclipseLink, эти интерфейсы, классы или аннотации уже работать не будут.) - API в пакете javax.persistance (набор интерфейсов EntityManager, Query, EntityTransaction), - JPQL - объектный язык запросов (запросы выполняются к объектам) - Metadata - аннотации или xml (JPA также обеспечивает управление жизненным циклом объектов, что означает, что приложение может сохранять, обновлять и удалять объекты из базы данных с помощью стандартного API. JPA является частью Java EE, но может быть использован и в Java SE приложениях. Реализации JPA включают Hibernate, EclipseLink, OpenJPA и другие.) 11. Что такое ORM? ORM (Object-Relational Mapping) - подход к взаимодействию с БД, который позволяет работать с таблицами БД не напрямую, а через entity объекты (таблица БД, представленная в виде объекта в коде). Т.е. позволяет связывать объектно-ориентированный код с реляционной базой данных. (Позволяет работать с объектами, как будто это коллекции данных.) ORM-системы позволяют управлять объектами из базы данных, не писав SQL-запросы вручную. (Они также могут автоматически создавать таблицы базы данных на основе модели данных объектов приложения и обратно, генерировать SQL-запросы на основе методов объектов, сохранять и загружать данные в базу данных.) (JPA - унифицированный интерфейс для взаимодействия с БД.) Преимущества ORM в сравнение с JDBC: Позволяет нашим бизнес методам обращаться не к БД, а к Java-классам; Ускоряет разработку приложения; Основан на JDBC; Отделяет SQL-запросы от ОО модели; Позволяет не думать о реализации БД; Сущности основаны на бизнес-задачах, а не на стуктуре БД; Управление транзакциями. 12. Что такое Hibernate? Hibernate - популярный ORM фреймворк для работы с базами данных в Java-приложениях с открытым исходным кодом. Hibernate - это провайдер, реализующий спецификацию JPA. Hibernate полностью реализует JPA плюс добавляет функционал в виде своих классов и интерфейсов, расширяя свои возможности по работе с сущностями и БД. Hibernate использует аннотации и XML-конфигурацию для сопоставления объектов Java с таблицами в базе данных и обеспечивает механизмы для выполнения запросов и манипулирования данными. (Он также предоставляет инструменты для управления транзакциями и поддержки кэширования данных, что позволяет улучшить производительность приложений.) Зачем нужен: - решает задачу связи классов Java с таблицами базы данных - обеспечивает связь типов данных Java с типами данных SQL - предоставляет средства для автоматической генерации и обновления набора таблиц, построения запросов и обработки полученных данных и может значительно уменьшить время разработки, которое обычно тратится на ручное написание SQL- и JDBC-кода. - автоматизирует генерацию SQL-запросов и освобождает разработчика от ручной обработки результирующего набора данных и преобразования объектов, максимально облегчая перенос (портирование) приложения на любые базы данных SQL. 13. В чем разница между JPA и Hibernate? Как связаны все эти понятия? JPA это спецификация (которая определяет стандартные интерфейсы и аннотации для работы с объектно-реляционным отображением), а Hibernate - это провайдер, реализующий спецификацию JPA. Hibernate полностью реализует JPA плюс добавляет функционал в виде своих классов и интерфейсов, расширяя свои возможности по работе с сущностями и БД. Сам JPA не умеет (ни сохранять, ни) управлять объектами, JPA только определяет правила игры: как должен действовать каждый провайдер (Hibernate, EclipseLink, OJB, Torque и т.д.), реализующий стандарт JPA. (JPA (Java Persistence API) - это стандарт для управления объектно-реляционным отображением (ORM) в Java-приложениях. JPA предоставляет единый интерфейс для управления данными, независимо от того, какая система управления базами данных (СУБД) используется. JPA определяет набор аннотаций и интерфейсов, которые позволяют отображать Java-объекты на таблицы базы данных. Hibernate - это одна из реализаций JPA. Он предоставляет более широкий функционал, чем JPA, и может использоваться как самостоятельный ORM-фреймворк. Hibernate предоставляет удобный и мощный способ отображения Java-объектов на таблицы базы данных и облегчает работу с базами данных в Java-приложениях. В общем случае, JPA - это стандарт, определяющий API для ORM в Java, а Hibernate - это одна из реализаций этого стандарта, с расширенным функционалом. В отличие от Hibernate, JPA не имеет своей собственной реализации и должен быть реализован отдельно в каждой СУБД. Таким образом, Hibernate можно использовать как отдельный ORM-фреймворк, а JPA можно использовать для стандартизации управления данными в Java-приложениях. Кроме того, многие функции Hibernate доступны через JPA-интерфейс, и многие аннотации Hibernate являются частью стандарта JPA.) 14. Какие классы/интерфейсы относятся к JPA/Hibernate? Классы и интерфейсы, относящиеся к JPA и Hibernate, могут быть разделены на несколько категорий: 1) Сущности (Entities): это объекты, которые представляют таблицы в базе данных. В JPA сущности обозначаются аннотацией @Entity. В Hibernate, помимо аннотаций, сущности также могут быть описаны с помощью файлов маппинга в формате XML. 2) Менеджеры сущностей (Entity Managers): это объекты, которые управляют жизненным циклом сущностей в приложении. Они обеспечивают CRUD-операции (create, read, update, delete), а также поиск и выборку данных. В JPA менеджер сущностей представлен интерфейсом EntityManager, а в Hibernate — классом Session. 3) Фабрики (Factories): это объекты, которые используются для создания других объектов, таких как менеджеры сущностей, провайдеры персистенции и т.д. В JPA фабрика представлена интерфейсом EntityManagerFactory, а в Hibernate — классом SessionFactory. 4) Запросы (Queries): это объекты, которые представляют запросы к базе данных. В JPA они реализованы с помощью интерфейса Query, а в Hibernate — классов Query и Criteria. 5) Транзакции (Transactions): это объекты, которые управляют транзакциями базы данных. В JPA они реализованы с помощью интерфейса EntityTransaction, а в Hibernate — класса Transaction. 6) Провайдеры персистенции (Persistence Providers): это реализации JPA, которые позволяют использовать этот API в конкретном приложении. Например, Hibernate является провайдером персистенции для JPA. (В целом, JPA и Hibernate взаимосвязаны следующим образом: JPA является спецификацией, которая определяет стандартные интерфейсы и аннотации для работы с объектно-реляционным отображением, а Hibernate является одним из многих провайдеров персистенции, который реализует эту спецификацию.) (SessionFactory (org.hibernate.SessionFactory) - неизменяемый потокобезопасный объект с компилированным маппингом для одной базы данных. Необходимо инициализировать SessionFactory всего один раз. Экземпляр SessionFactory используется для получения объектов Session, которые используются для операций с базами данных. Session (org.hibernate.Session) - однопоточный короткоживущий объект, который предоставляет связь между объектами приложения и базой данных. Он оборачивает JDBC java.sql.Connection и работает как фабрика для org.hibernate.Transaction. Разработчик должен открывать сессию по необходимости и закрывать ее сразу после использования. Экземпляр Session является интерфейсом между кодом в java приложении и hibernate framework и предоставляет методы для операций CRUD. Transaction (org.hibernate.Transaction) - однопоточный короткоживущий объект, используемый для атомарных операций. Это абстракция приложения от основных JDBC или JTA транзакций. org.hibernate.Session может занимать несколько org.hibernate.Transaction в определенных случаях.) 15. Основные аннотации Hibernate, рассказать. |