ос и с. ОСиС. 1. Классификация программного обеспечения
 Скачать 2.7 Mb. Скачать 2.7 Mb.
|

|
ВНУТРЕННИЕ КОМАНДЫ Внутренними командами называют те команды, которые не требуют запуска отдельных файлов – утилит, и содержатся в ядре ОС. К внутренним командам относятся те, которые отвечают за свойства системы в целом, и внутренних сервисов в частности. 16. Внешние команды Внешними командами являются команды, которые существуют отдельными модулями ОС и требуют запуска дополнительных приложений – файлов. К ним также относятся те файлы, которые не предназначены для использования ядром ОС, но несут необходимые функции в своём исполняемом коде. Такие команды называют вспомогательными или программами – утилитами. 17. Понятие пользователя. Понятие идентификатора пользователя Ответ на этот вопрос вы можете найти в главе 33 18. Понятие группы. Понятие идентификатора группы Ответ на этот вопрос вы можете найти в главе 33. 19. Виртуальная память. SWAP Понятие Виртуальным (virtual) называется ресурс, который пользовательской программе представляется обладающим свойствами, отличными от тех, которые он имеет. Термин виртуальная память обычно ассоциируется с возможностью адресовать пространство памяти, гораздо большее, чем емкость реальной памяти конкретной ЭВМ. Концепция виртуальной памяти является далеко не новой. Впервые она была реализована в вычислительной машине Atlas, созданной в Манчестерском университете в Англии в 1960 году. Эта концепция позволяет создавать и запускать приложения, которые требуют памяти больше, чем есть у компьютера. Виртуальная память и организация защиты памяти Концепция виртуальной памяти Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений. Прежде всего к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем. В любой момент времени компьютер выполняет множество процессов или задач, каждая из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче тем более, что многие задачи реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности. Она делит физическую память на блоки и распределяет их между различными задачами. При этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение. Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объема. Если программа становилась слишком большой для физической памяти, часть ее необходимо было хранить во внешней памяти (на диске) и задача приспособить ее для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведенного ей пространства физической памяти. Виртуальная память освободила программистов от этого бремени. Она автоматически управляет двумя уровнями иерархии памяти: основной памятью и внешней (дисковой) памятью. Кроме того, виртуальная память упрощает также загрузку программ, обеспечивая механизм автоматического перемещения программ, позволяющий выполнять одну и ту же программу в произвольном месте физической памяти. Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами. Ниже рассмотрены оба типа организации виртуальной памяти. Страничная организация памяти В системах со страничной организацией основная и внешняя память (главным образом дисковое пространство) делятся на блоки или страницы фиксированной длины. Каждому пользователю предоставляется некоторая часть адресного пространства, которая может превышать основную память компьютера и которая ограничена только возможностями адресации, заложенными в системе команд. Эта часть адресного пространства называется виртуальной памятью пользователя. Каждое слово в виртуальной памяти пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер страницы, а младшие - как номер слова (или байта) внутри страницы. Управление различными уровнями памяти осуществляется программами ядра операционной системы, которые следят за распределением страниц и оптимизируют обмены между этими уровнями. При страничной организации памяти смежные виртуальные страницы не обязательно должны размещаться на смежных страницах основной физической памяти. Для указания соответствия между виртуальными страницами и страницами основной памяти операционная система должна сформировать таблицу страниц для каждой программы и разместить ее в основной памяти машины. При этом каждой странице программы, независимо от того находится ли она в основной памяти или нет, ставится в соответствие некоторый элемент таблицы страниц. Каждый элемент таблицы страниц содержит номер физической страницы основной памяти и специальный индикатор. Единичное состояние этого индикатора свидетельствует о наличии этой страницы в основной памяти. Нулевое состояние индикатора означает отсутствие страницы в оперативной памяти. Для увеличения эффективности такого типа схем в процессорах используется специальная полностью ассоциативная кэш-память, которая также называется буфером преобразования адресов (TLB traнсlation-lookaside buffer). Хотя наличие TLB не меняет принципа построения схемы страничной организации, с точки зрения защиты памяти, необходимо предусмотреть возможность очистки его при переключении с одной программы на другую. Поиск в таблицах страниц, расположенных в основной памяти, и загрузка TLB может осуществляться либо программным способом, либо специальными аппаратными средствами. В последнем случае для того, чтобы предотвратить возможность обращения пользовательской программы к таблицам страниц, с которыми она не связана, предусмотрены специальные меры. С этой целью в процессоре предусматривается дополнительный регистр защиты, содержащий описатель (дескриптор) таблицы страниц или базово-граничную пару. База определяет адрес начала таблицы страниц в основной памяти, а граница - длину таблицы страниц соответствующей программы. Загрузка этого регистра защиты разрешена только в привилегированном режиме. Для каждой программы операционная система хранит дескриптор таблицы страниц и устанавливает его в регистр защиты процессора перед запуском соответствующей программы. Отметим некоторые особенности, присущие простым схемам со страничной организацией памяти. Наиболее важной из них является то, что все программы, которые должны непосредственно связываться друг с другом без вмешательства операционной системы, должны использовать общее пространство виртуальных адресов. Это относится и к самой операционной системе, которая, вообще говоря, должна работать в режиме динамического распределения памяти. Поэтому в некоторых системах пространство виртуальных адресов пользователя укорачивается на размер общих процедур, к которым программы пользователей желают иметь доступ. Общим процедурам должен быть отведен определенный объем пространства виртуальных адресов всех пользователей, чтобы они имели постоянное место в таблицах страниц всех пользователей. В этом случае для обеспечения целостности, секретности и взаимной изоляции выполняющихся программ должны быть предусмотрены различные режимы доступа к страницам, которые реализуются с помощью специальных индикаторов доступа в элементах таблиц страниц. Следствием такого использования является значительный рост таблиц страниц каждого пользователя. Одно из решений проблемы сокращения длины таблиц основано на введении многоуровневой организации таблиц. Частным случаем многоуровневой организации таблиц является сегментация при страничной организации памяти. Необходимость увеличения адресного пространства пользователя объясняется желанием избежать необходимости перемещения частей программ и данных в пределах адресного пространства, которые обычно приводят к проблемам переименования и серьезным затруднениям в разделении общей информации между многими задачами. Сегментация памяти Другой подход к организации памяти опирается на тот факт, что программы обычно разделяются на отдельные области-сегменты. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается своя собственная нумерация слов, начиная с нуля. Обычно в подобных системах обмен информацией между пользователями строится на базе сегментов. Поэтому сегменты являются отдельными логическими единицами информации, которые необходимо защищать, и именно на этом уровне вводятся различные режимы доступа к сегментам. Можно выделить два основных типа сегментов: программные сегменты и сегменты данных (сегменты стека являются частным случаем сегментов данных). Поскольку общие программы должны обладать свойством повторной входимости, то из программных сегментов допускается только выборка команд и чтение констант. Запись в программные сегменты может рассматриваться как незаконная и запрещаться системой. Выборка команд из сегментов данных также может считаться незаконной и любой сегмент данных может быть защищен от обращений по записи или по чтению. Для реализации сегментации было предложено несколько схем, которые отличаются деталями реализации, но основаны на одних и тех же принципах. В системах с сегментацией памяти каждое слово в адресном пространстве пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер сегмента, а младшие - как номер слова внутри сегмента. Наряду с сегментацией может также использоваться страничная организация памяти. В этом случае виртуальный адрес слова состоит из трех частей: старшие разряды адреса определяют номер сегмента, средние - номер страницы внутри сегмента, а младшие - номер слова внутри страницы. Как и в случае страничной организации, необходимо обеспечить преобразование виртуального адреса в реальный физический адрес основной памяти. С этой целью для каждого пользователя операционная система должна сформировать таблицу сегментов. Каждый элемент таблицы сегментов содержит описатель (дескриптор) сегмента (поля базы, границы и индикаторов режима доступа). При отсутствии страничной организации поле базы определяет адрес начала сегмента в основной памяти, а граница - длину сегмента. При наличии страничной организации поле базы определяет адрес начала таблицы страниц данного сегмента, а граница - число страниц в сегменте. Поле индикаторов режима доступа представляет собой некоторую комбинацию признаков блокировки чтения, записи и выполнения. Таблицы сегментов различных пользователей операционная система хранит в основной памяти. Для определения расположения таблицы сегментов выполняющейся программы используется специальный регистр защиты, который загружается операционной системой перед началом ее выполнения. Этот регистр содержит дескриптор таблицы сегментов (базу и границу), причем база содержит адрес начала таблицы сегментов выполняющейся программы, а граница - длину этой таблицы сегментов. Разряды номера сегмента виртуального адреса используются в качестве индекса для поиска в таблице сегментов. Таким образом, наличие базово-граничных пар в дескрипторе таблицы сегментов и элементах таблицы сегментов предотвращает возможность обращения программы пользователя к таблицам сегментов и страниц, с которыми она не связана. Наличие в элементах таблицы сегментов индикаторов режима доступа позволяет осуществить необходимый режим доступа к сегменту со стороны данной программы. Для повышения эффективности схемы используется ассоциативная кэш-память. Отметим, что в описанной схеме сегментации таблица сегментов с индикаторами доступа предоставляет всем программам, являющимся частями некоторой задачи, одинаковые возможности доступа, т. е. она определяет единственную область (домен) защиты. Однако для создания защищенных подсистем в рамках одной задачи для того, чтобы изменять возможности доступа, когда точка выполнения переходит через различные программы, управляющие ее решением, необходимо связать с каждой задачей множество доменов защиты. Реализация защищенных подсистем требует разработки некоторых специальных аппаратных средств. Рассмотрение таких систем, которые включают в себя кольцевые схемы защиты, а также различного рода мандатные схемы защиты, выходит за рамки данного обзора. Память, как аппаратное устройство Любая процессорная (микроконтроллерная) система устроена, в общем-то, одинаково. Существует устройство, называемое "процессор", которое умеет в самом общем смысле "перерабатывать информацию" - получая на вход информацию одну, на выходе оно создаёт информацию другую. Естественно, вполне детерминированную – алгоритм этого самого преобразования описывается "программой". Но для нас сейчас это не важно, сейчас нас интересует ответ только на один вопрос – как именно "процессор" обменивается с "внешним миром". И принцип на котором это взаимодействие построено коротко именуется "архитектура общая шина". Он изображён на рис.1, на котором показано три устройства – процессор и два ОЗУ: 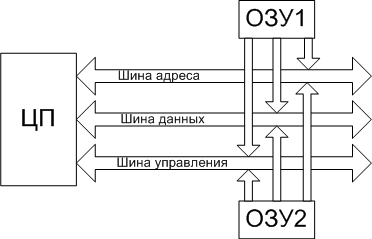 рис 1. Схема архитектуры "общая шина" Видно, что в составе этой шины выделяется три группы линий (которые есть не что иное, как самые обычные электрические проводники) – "шина управления", по которой процессор подаёт сигналы управления, "шина данных", по которой передаются двоичные числа, которые считаются "данными" и "шина адреса", по которой передаются такие же числа, но они считаются "адресом". Разрядность шины (число линий, по которым одновременно передаются биты ) обычно совпадает с разрядностью самого процессора. Так, у 32-хразрядного процессора обычно же и 32-хразрядная шина, хотя можно построить и иную конфигурацию. Физическое ОЗУ (Random Access Memory, RAM) представляет собой компонент, который "разделён" на некоторое количество ячеек, которые могут хранить в себе комбинации битов. Ячейки отличаются друг от друга номером, который ОЗУ воспринимает с "шины адреса", а связь содержимого ячейки с внешним миром осуществляется посредством "шины данных". Принципиальная схема организации ОЗУ приведена на рис.2:  рис 2. Принципиальная схема организации ОЗУ "Цикл памяти" в общем виде выглядит так. Процессор, желающий прочитать содержимое ячейки с адресом M устанавливает этот адрес на "шину адреса" и ставит на "шину управления" сигнал "чтение". ОЗУ, получив этот сигнал, выставляет содержимое своей ячейки с таким номером на "шину данных" и ставит на шину управления сигнал "готово". Получив этот сигнал процессор воспринимает состояние шины данных и убирает сигнал "читать". Запись в ОЗУ происходит аналогично – процессор ставит на шину данных число, подлежащее записи, на шину адреса – номер записываемой ячейки, а на шину управления – сигнал "запись". ОЗУ, получив этот сигнал, воспринимает состояние шины данных и сохраняет его в ячейке с номером M. Здесь мы не будем касаться вопроса, как процессор "считывает байт", когда ширина шины данных фактически – несколько байтов. Не очень грубое для программиста допущение состоит в том, что из ОЗУ всегда считываются столько байтов, сколько составляют ширину шины, а из них процессором выбирается только один... Естественно, что количество ячеек в одном устройстве памяти – ограничено. Физически это выражается в том, что не всякое возможное на шине адреса число приведёт к "срабатыванию ячейки" - возможно, что ячейки с таким адресом просто физически не существует (на приведённом рис. 1 предполагается, что часть доступного диапазона адресов обслуживается одним ОЗУ, а часть – другим, они "срабатывают" на разные адреса). Обычно диапазон "вообще возможных адресов" значительно больше того диапазона адресов, на которое в состоянии откликнуться "физическое ОЗУ" - сравните, например 232 (4Гб) и 227 (128Мб). Причина этого – исключительно экономическая и техническая. Память и стоит каких-то денег и занимает какой-то объём. Возможность же процессора адресовать больше – в данном случае есть не что иное, как нереализованный резерв. Описанную модель обращения с физической памятью легко "поднять выше" - на уровень программиста. Ведь "читать слово" и "писать слово" - разные команды процессора, это его дело какие числа на какие шины ставить, программист только снабжает процессор эти самым "адресом" прямо или косвенно указывая его в самой команде. А модель набора ячеек как раз и получается в виде непрерывной строки с диапазоном адресов от какого-то "младшего" до какого-то "старшего" - программисту-то какое дело ОЗУ1 хранит данную ячейку или ОЗУ2 ? И в ранних процессорных системах именно так оно и было – адреса, которые программист указывал в командах были именно теми, которые процессор выставлял на шину адреса. И, хотя программист мог, например в качестве адреса указать число 221он этого не делал, ибо знал, что последняя "срабатывающая" ячейка располагается по адресу 220-1. Попытка обратиться по адресу большему приносила либо "мусор", либо прерывание – это зависело от конструкции машины. Операционная система MS DOS – как раз и есть пример такой программы, работающей с процессором в т.н. "режиме реального адреса". Шло время, процессоры становились мощнее, программы – требовали всё большего объёма памяти. Это – совершенно закономерный процесс, поскольку процессор, могущий перерабатывать большой объём информации нет смысла укомплектовывать малым объёмом памяти – чтобы много информации перерабатывать надо прежде всего уметь много информации и хранить. И - мощность процессоров росла гораздо быстрее, чем возможность технологии производить большие и дешёвые ОЗУ. "Узким местом" всей процессорной системы стала физическая память. В этих обстоятельствах внимание архитекторов обратилось к неиспользуемому резерву – если процессор по ширине своей шины может адресовать 4Г разных ячеек, то нельзя ли каким-нибудь способом сделать так, что они "как бы есть", хотя на самом деле их и нет? Т.е. речь шла о механизме (архитектурном решении), который бы позволил эмулировать больший объём памяти, чем тот объём физических ОЗУ, которым на самом деле располагала машина. Понятно, что такую иллюзию нужно было создать только у самого "источника адресов" - у программы, обращающейся в память. Ведь если она сможет указать в команде (по другому задать адрес программа не может) число 230 (1Г) и получить осмысленное значение данных, то она по прежнему может считать, что у неё есть ОЗУ объёмом 1Г, какая ей разница, какое аппаратное устройство на этот адрес "срабатывает" и как именно? Поэтому речь шла прежде всего об аппаратном решении – в описанной выше архитектуре памяти "что поставил - то и прочитал", а для создания требуемой иллюзии нужно было, чтобы адрес, который задаётся в команде процессора и адрес, который процессор ставит на шину адреса – как-то соотносились друг с другом, но были разными. И это преобразование одного в другое должно было быть однозначным, незаметным для программы и очень быстрым – ведь такое преобразование должно было применяться к каждому адресу, выставляемому процессором! Общий принцип архитектурного решения, удовлетворяющего сформулированным требованиям можно описать так. В процессоре должен быть особый узел – блок преобразования адреса (БПА). Программа указывает свой адрес (его теперь естественно назвать "логическим"), он попадает в этот блок, блок что-то с ним делает такое, чтобы из этого адреса сделать "физический" - адрес заведомо существующей в системе физической ячейки памяти, и лишь затем такой преобразованный адрес попадает на шину адреса. Шина данных – не изменяется. А схема "цикла памяти" расширяется на фазу преобразования адреса. Такой режим работы процессора получил название "режим виртуального адреса". А как можно выполнить такое преобразование? Когда логический адрес соответствует какому-то физическому – всё понятно. Например, всякий логический адрес мы можем складывать с константой (операция быстрая, делается "на лету") – диапазон физических адресов просто сдвинется (будет отличаться от тех адресов, что указаны в командах), но соответствие-то останется. А ведь мы хотим раздвинуть диапазон! Это означает, что когда-то на вход преобразователя адреса придёт такой логический адрес, которому соответствует несуществующая физическая ячейка. Верно. В таком случае процессор должен сделать два дополнительных действия – во-первых, он должен вызвать особое прерывание "запрашиваемой памяти – нет", т.е. вызвать специальную программу-обработчик. Во-вторых, он должен "открутить назад" свой счётчик команд – прерывание вызвано считанной командой, которая попыталась обратиться к несуществующим данным. В "нормальной системе" такое событие – фатально, а здесь процессор должен "сделать вид" что он эту самую команду только собирается исполнить. Что должен делать обработчик этого прерывания? Он должен... обеспечить ранее не существовавшие, а теперь понадобившиеся данные. Как??? Например, взять и загрузить их откуда-нибудь на то самое место физической памяти, которое действительно есть, сообщить в блок преобразования адреса, что этому самому запрошенному "логическому адресу" теперь соответствует вот такой физический и ... просто вернуть управление. Поскольку процессор перед этим свой счётчик команд "открутил назад", то, после возврата из прерывания, он повторно выбирает ту самую команду, которая прерывание вызвала - теперь эти данные уже существуют – и исполнение программы продолжится как ни в чём ни бывало. Вот и почти всё аппаратное решение! Тем не менее, в нём пока непонятны две вещи – во-первых, сам алгоритм преобразования адреса. Во-вторых – откуда загружать эти "виртуальные данные" и как. Делать это побайтно и пословно – фактически иметь "запасное ОЗУ" (которого мы как раз иметь-то и не хотим), поскольку единственной просматриваемой альтернативой ОЗУ (другим устройством, умеющим хранить данные – чудес на свете не бывает) является диск, а он – устройство блочное, байты адресовать не умеет. Обе проблемы решаются в комплексе – ведь и преобразование адреса не может быть выполнено "с точностью до байта" - это тоже означает, что для однозначного преобразования нужно иметь "второй комплект байтов". Поэтому преобразование адреса производится по таблице – выборка из таблицы ничуть не более медленная операция, чем сложение. А само преобразование логического адреса делается так, как показано на рис. 3. Логический адрес делится на две части, простым проведением границы между битами. Старшая часть адреса называется "адрес страницы", а младшая "адрес внутри страницы". Страница и есть та самая порция информации, которую обработчик прерывания "несуществующие данные" (точно это прерывание называется "страничная ошибка") загружает с диска в ОЗУ. Её размер не должен быть очень маленьким, поскольку иначе "страничная ошибка" будет возникать часто и машина просто будет гонять данные из памяти на диск и обратно. Но, с другой стороны, её размер не должен быть и слишком большим – на загрузку тратится время. А программе на странице может понадобиться всего-то сотня байт, а потом она перейдет по другому адресу, который соответствует уже другой странице – и снова загрузка. В блоке преобразования адреса ведётся специальная таблица, в которой адресу страницы (старшей части логического адреса) соответствует реальный адрес физической памяти, где эта страница расположена. Каждая строка этой таблицы – адрес загруженной в ОЗУ страницы, т.е. страницы физически доступной в данный момент для обращения. Преобразователь адреса "режет" поступивший логический адрес на части "страничный" и "внутри страницы" и пытается найти в этой таблице соответствие – какой же физический адрес соответствует данному страничному. Если такое соответствие находится, то к физическому адресу страницы прибавляются младшие биты "адрес внутри страницы" и получается адрес физического байта, который в данный момент соответствует данному логическому адресу – адресация возможна и проходит, как и в системе с "реальным адресом" - программа и не узнает, что в действительности "срабатывала" ячейка не с тем адресом, который был указан в программе. Если же соответствие не находится, т.е. обнаруживается, что нужная страница не значится в таблице как "загруженная", блок преобразования адреса возбуждает прерывание "страничная ошибка" и сообщает обработчику какую страницу необходимо загрузить. Обработчик должен – отыскать на диске ту самую страницу, найти ей место в физической памяти, загрузить страницу и исправить в блоке преобразования адреса адрес страницы в таблице. Когда в физической памяти есть не занятые страницы – всё просто. А если всё место уже занято другими страницами? Тогда обработчик должен какую-то страницу вытеснить – записать её на диск с тем, чтобы на её место вписать нужную. Какую? Мнения на сей счёт могут быть различными, но наиболее употребительный алгоритм вытесняет ту страницу, к которой давно не было обращений. С этой целью в "страничной таблице" ведётся и счётчик времени обращения – исключительно аппаратное решение, которое не удлиняет цикла памяти. Когда обработчик вернёт управление процессор вновь исполнит ту же команду, попытка обращения которой к памяти оказалась неуспешной, но в блоке преобразования адреса требуемая страница уже будет числиться "загруженной" - обращение к памяти пройдёт успешно. 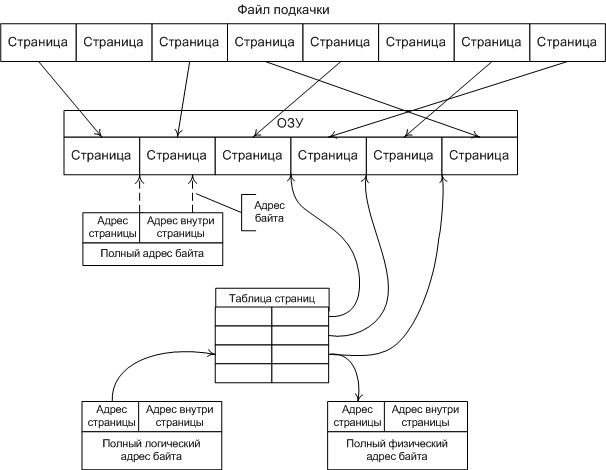 рис 3. Схема преобразования логического адреса в физический Поэтому общая схема программно-аппаратного механизма, обеспечивающего описанным способом создание иллюзии наличия большей оперативной памяти, чем есть в действительности, приведена на рис. 4. Первое, что сразу бросается в глаза – без диска (без хранилища вытесненных страниц) эта схема не работает вообще. Где-то нужно иметь этот самый "файл подкачки". Второе – объём реального ОЗУ влияет на быстродействие машины, поскольку чем он больше, тем реже приходится обращаться к загрузке страниц. А вот объём действительно доступной памяти уже не определяется ОЗУ – он определяется именно объёмом "файла подкачки". И может быть сделан хоть на весь доступный диапазон адресов - 4 Гб для 32-хразрядного адреса. Именно это обычно и называется "механизм виртуальной памяти". 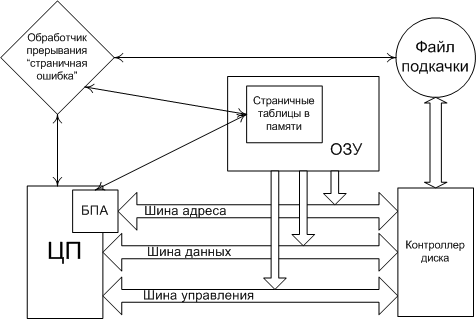 рис 4. Общая схема механизма виртуальной памяти Но то, что приведено выше – только принципиальная схема. Действительность ещё сложнее – поскольку современные процессоры изначально ориентированы на "многозадачность" к схеме виртуальной памяти предъявляется и ещё одно требование – разные процессы должны обладать разными "адресными пространствами", т.е. схема адресации физической памяти должна быть такой, чтобы ни при каких обстоятельствах один процесс не мог адресовать память, принадлежащую другому процессу. Хочется подчеркнуть – это требование не вытекает из требований ни к машине, ни к памяти, ни вообще к аппаратной части. Оно вытекает из существующей технологии создания надёжных программ, а машина – должна поддерживать его. Модель такой памяти предполагает, что один и тот же логический адрес со значением X, но порождённый в разных процессах, должен приводить на разные страницы физической памяти. Такой режим адресации процессора носит название "режима защищенного адреса", так что полное название режима в котором процессор может делать всё вышеупомянутое звучит как "режим защищённого виртуального адреса" - именно он и есть основной рабочий режим процессора под управлением современных операционных систем. Поэтому нарисованная на рис.4 схема усложняется. В блоке преобразования адреса (фактически, конечно, это хранится в некоторой статически распределённой области ОЗУ, той, которая никогда не участвует в страничном обмене) имеется не вообще одна таблица преобразования страничного адреса, а – ещё по одной таблице на процесс, в которых отмечается, какие страницы каким процессам принадлежат. И при переключении процессов эти таблицы в блоке преобразования адреса тоже переключаются. Фактически преобразование адреса и поиск нужной страницы происходят в два этапа – сначала выясняется является ли для данного процесса адресуемой запрашиваемая страница, а потом – где именно она расположена. Делается это аппаратно и элементы процессора, которые выполняют это сложное преобразование оптимизированы настолько, что физический адрес байта преобразователь вычисляет чуть ли не за такт до того, как получит себе на вход логический адрес подлежащий преобразованию. Так что вся эта сложность не приводит к уменьшению абстрактного быстродействия машины. Хотя, конечно, машина с виртуальной памятью в среднем работает медленнее, чем аналогичная машина с памятью исключительно реальной – на страничный обмен тратится время, которое недополучает исполняющаяся "программа пользователя". Ещё раз повторим – сказанное выше есть только близкая к реальному воплощению в существующих процессорах принципиальная схема. Более подробное и точное знание о том, как функционирует обозначенный механизм нужно немногим программистам, а они его знают и так. Для нас, обычных программистов, сказанное – только необходимое основание для того, чтобы перейти к собственно предмету данной статьи – как устроено в операционной системе использование описанных аппаратных возможностей и что оно даёт программисту, использующему, например, платформу Win32. Организация и управление виртуальной памятью Основные концепции Суть концепции виртуальной памяти заключается в том, что адреса, к которым обращается выполняющийся процесс, отделяются от адресов, реально существующих в первичной (физической) памяти. Те адреса, на которые делает ссылки выполняющийся процесс, называются виртуальными, а те адреса, которые существуют в первичной памяти, называются реальным адресами. Диапазон виртуальных адресов, к которым может обращаться выполняющийся процесс, называется пространством виртуальных адресов V этого процесса. Диапазон реальных адресов, существующих в конкретной машине, называется пространством реальных адресов R этого компьютера. Хотя диапазон реальных адресов для конкретного компьютера ограничен объемом имеющейся у него памяти, диапазон виртуальных адресов ограничен только количеством битов в адресе. Каждый бит может быть либо установлен, либо сброшен; таким образом, например, процессор имеющий 32-разрядные адреса, является обладателем виртуального пространства в 232 байт, или 4 Гбайт. Несмотря на то, что процессы обращаются только к виртуальным адресам, в действительности они должны работать с реальной памятью. Таким образом, во время выполнения процесса виртуальные адреса необходимо преобразовывать в реальные, причем нужно это делать быстро, т.к. в противном производительности ЭВМ будет резко снижена. 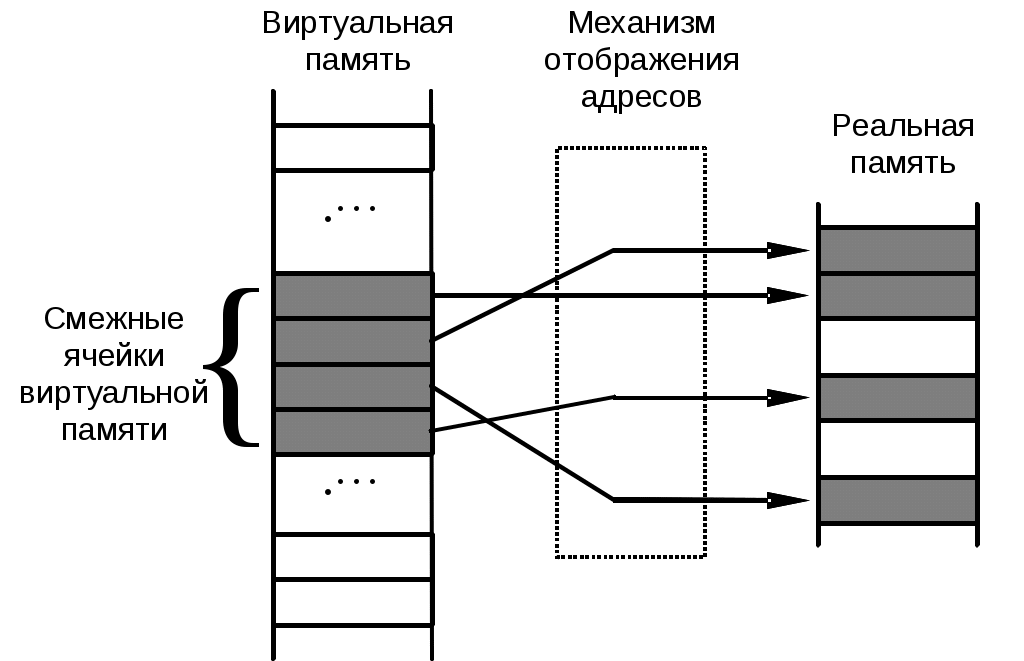 Для установления соответствия между виртуальными и реальными адресами разработаны различные способы. Чаще всего используется так называемый механизм динамического преобразования адресов (DAT – Dynamic Adress Transformation), который обеспечивает преобразование виртуальных адресов в реальные во время выполнения процесса. Все подобные системы обладают тем свойством, что смежные адреса виртуального адресного пространства процесса не обязательно будут смежными в реальной памяти. Это свойство называется “искусственной смежностью”. Таким образом, пользователь освобождается от необходимости размещения своих процедур и данных в реальной памяти. Он получает возможность писать программы наиболее естественным образом, прорабатывая только алгоритм и структуры программы и игнорируя конкретные особенности структуры аппаратных средств. Кроме преобразования виртуальных адресов в реальные, перед системой с виртуальной памятью стоит еще одна задача – выгружать на диск часть содержимого памяти, когда она переполняется. При этом ОС определяет, какие данные можно удалить из основной памяти и поместить на временное хранение в файл на жестком диске, который называется файлом подкачки (страничным файлом, файлом свопинга). Когда эти данные вновь потребуются выполняющемуся процессу, ОС считывает их обратно с диска в память. Такой обмен между основной памятью и внешним запоминающим устройством называется свопингом. Поблочное отображение Механизм динамического преобразования адресов должен вести таблицы, показывающие, какие ячейки виртуальной памяти в текущий момент находятся в реальной памяти и где именно они размещаются. Если бы такое отображение осуществлялось пословно или побайтно, то информация об отображении была бы столь велика, что для ее хранения потребовалось бы столько же или даже больше реальной памяти, чем для самих процессов. Поэтому, чтобы реализация виртуальной памяти имела смысл, необходим метод, позволяющий существенно сократить объем информации отображения. Поскольку индивидуальное отображение элементов информации неоправданно, то их обычно группируют в блоки, а система следит за тем, в каких местах реальной памяти размещаются различные блоки виртуальной памяти. Чем больше размер блока, тем меньшую долю емкости реальной памяти приходится затрачивать на хранение информации отображения. Однако крупные блоки требуют большего времени на обмен между внешней и первичной памятью и с большей вероятностью ограничивают число процессов , которые могут совместно использовать первичную память. При реализации виртуальной памяти возникает вопрос о том, следует ли все блоки делать одинакового или разных размеров. Если блоки имеют одинаковый размер, то они называются страницами, а соответствующая организация виртуальной памяти называется страничной. Если блоки могут быть разных размеров, то они называются сегментами, а соответствующая организация сегментной. В некоторых системах оба этих подхода комбинируются, т.е. сегменты реализуются как объекты переменных размеров, формируемые из страниц фиксированного размера. 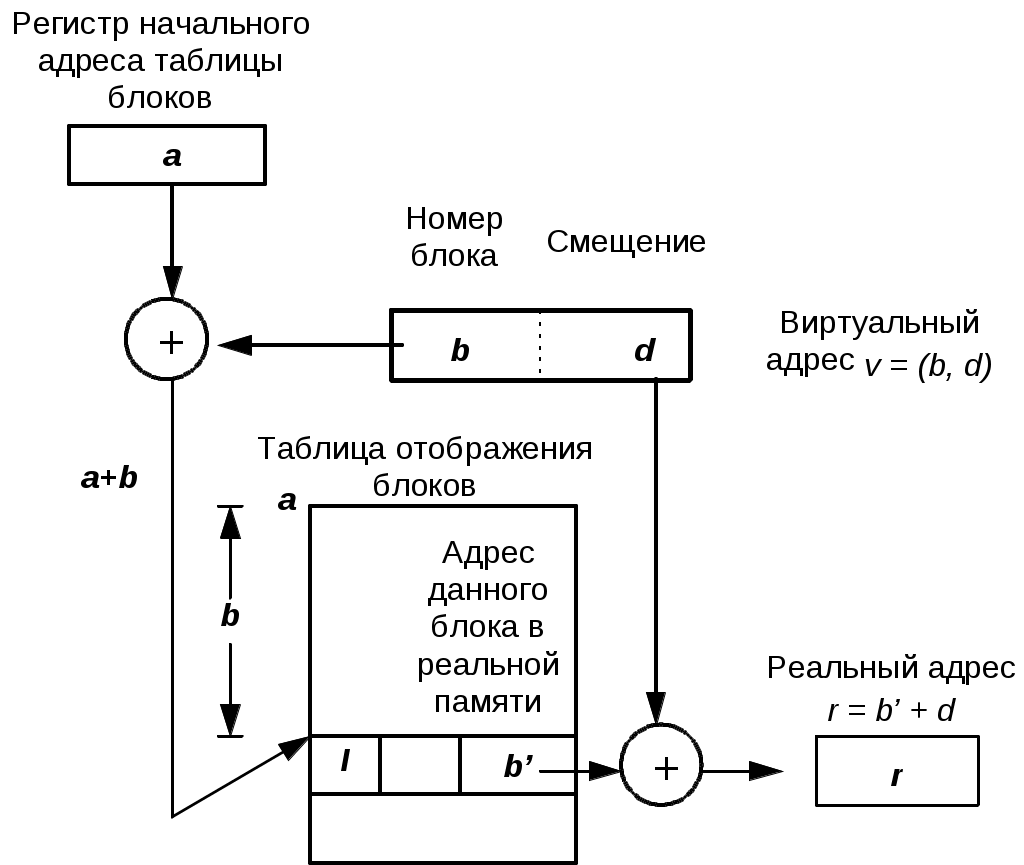 Преобразование виртуального адреса в поблочном отображении Адреса в системе поблочного отображения являются двухкомпонентными (двумерными). Чтобы обратиться к конкретному элементу данных, программа указывает блок, в котором этот элемент находится и смещение этого элемента относительного начала блока. Виртуальный адрес v указывается при помощи упорядоченной пары (b,d), где b – номер блока, в котором размещается соответствующий элемент, а d – смещение относительно начального адреса этого блока.
Преобразование адреса виртуальной памяти v = (b,d) в адрес реальной памяти r осуществляется следующим образом. Каждый процесс имеет собственную таблицу отображения блоков, которую система ведет в реальной памяти. Реальный адрес a этой таблицы загружается в специальный регистр ЦП, называемый регистром начального адреса таблицы блоков. Таблица отображения блоков содержит по одной строке для каждого блока процесса, причем эти строки идут в последовательном порядке, сначала блок 0, затем 1, и т.д. Номер блока b суммируется с базовым адресом a таблицы, образуя реальный адрес строки таблицы для блока b. Эта строка содержит реальный адрес b’ блока b в реальной памяти. К этому начальному адресу b’ прибавляется смещение d, так что образуется нужный адрес r = b’+d. Важно отметить, что поблочное отображение осуществляется динамически во время выполнения процесса. Поэтому, если механизм отображения реализован недостаточно эффективно, то накладные расходы могут привести к ухудшению характеристик системы. Страничная организация Виртуальный адрес в страничной системе – это упорядоченная пара (p, d), где p – номер страницы в виртуальной памяти, а d – смещение в рамках страницы p, где размещается адресуемый элемент.
Процесс может выполняться, если его текущая страница находится в первичной памяти. Страницы переписываются из внешней памяти в первичную и размещаются в ней в блоках, называемых страничными кадрами и имеющих точно такой же размер, как и поступающие страницы. Страничные кадры начинаются с адресов первичной памяти, кратных фиксированному размеру страницы. Поступающая страница может быть помещена в любой свободный страничный кадр.  Разделение реальной памяти на страничные кадры Динамическое преобразование адресов в системе со страничной организацией осуществляется следующим образом. Выполняющийся процесс обращается по виртуальному адресу v = (p, d). Механизм отображения адресов ищет номер страницы p в таблице отображения страниц и определяет , что эта страница находится в страничном кадре c порядковым номером p’. Адрес первичной памяти a, с которого начинается страничный кадр p’ (если размер страницы равняется p) определяется произведением a = (p)(p’). Адрес реальной памяти r формируется затем путем конкатенации a и d. Стратегии вталкивания (подкачки) страниц Их цель – определить, в какой момент следует переписать страницу или сегмент из вторичной памяти в первичную. Подкачка страниц по запросу Традиционно считается, что наиболее рационально загружать в основную память страницы, необходимые для работы процесса, по его запросу. Не следует переписывать ни одной страницы из внешней памяти в основную до тех пор, пока к ней явно не обратится выполняющийся процесс. В пользу этой стратегии можно привести такие аргументы: гарантируется, что в память будут переписаны только те страницы, которые фактически необходимы для работы процесса; минимальны накладные расходы на то, чтобы определить, какие страницы следует разместить в памяти. К существенным недостаткам можно отнести лишь неэффективное использование первичной памяти. Т.к. процесс должен накапливать в памяти требуемые страницы по одной, то при появлении ссылки на каждую новую страницу процессу приходится ждать, пока эта страница будет передана в основную память. При подкачке страниц принято оценивать величину “пространство-время”, которая применяется для оценки использования памяти процессом. Эта величина соответствует заштрихованной площади на рисунке, приведенном ниже. Уменьшение произведения “пространство-время” за счет уменьшения периодов ожидания процессом нужных ему страниц является важнейшей целью всех стратегий управления памятью. 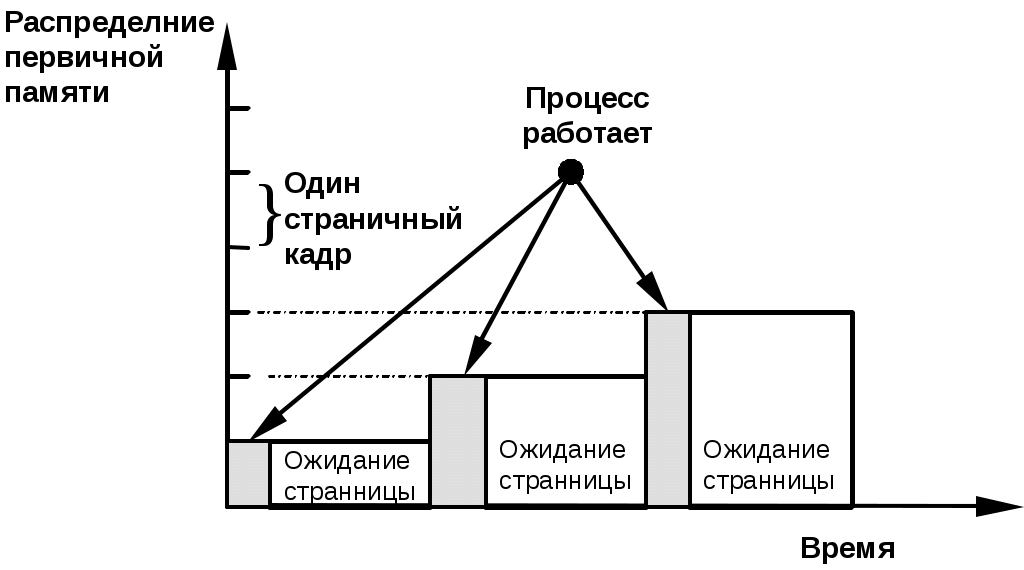 Подкачка страниц с упреждением При этой стратегии ОС пытается заблаговременно предсказать, какие страницы потребуются процессу, а затем когда в основной памяти появляется свободное место, загружает в нее эти страницы. Пока процесс работает со своими текущими страницами, система запрашивает новые страницы, которые уже будут готовы к использованию, когда процесс к ним обратится. Если решения о выборе страниц принимать с большой вероятностью правильно, то это позволит резко сократить общее время выполнения данного процесса. Подкачка по запросу с кластеризацией Данная стратеги использует достоинства первых двух стратегий и применяется в ОС Windows NT. Ее суть заключается в следующем: когда ОС генерирует прерывание по отсутствию нужной страницы в основной памяти, загружается сама нужная страница и небольшое количество окружающих ее страниц. Такая схема пытается минимизировать количество прерываний по отсутствию страниц в памяти. Стратегии размещения страниц При возникновении прерывания по отсутствию нужной страницы в первичной памяти система должна определить, в какое место физической памяти следует загрузить виртуальную страницу (блок). В системах со страничной организацией виртуальной памяти такое решение принимается достаточно тривиально, поскольку поступающая страница может быть помещена в любой страничный кадр. Поэтому для этой цели чаще всего выбирается первый свободный страничный кадр. Системы с сегментной организацией требуют стратегий размещения, аналогичных тем, которые используются для управления реальной памятью с переменными разделами. Стратегия первого подходящего. Поступающее задание помещается в первый встретившийся свободный сегмент основной памяти достаточного размера. Такая стратегия позволяет быстро принять решение о размещении блока. Стратегия наиболее подходящего. Поступающей сегмент помещается в ту область, где ему наиболее “тесно”, так что остается минимальное неиспользуемое пространство. В технической литературе описана еще одна стратегия – стратегия наименее подходящего. При помещении программы в память нужно занимать свободный участок наибольшего размера. После помещения программы в такой участок остающийся свободный участок зачастую также оказывается большим, и таким образом, в него можно разместить относительно большую новую программу. Стратегии выталкивания страниц В системах со страничной организацией все страничные кадры бывают заняты. В этом случае программы управления памятью, входящие в ОС, должны решать, какую страницу следует удалить из первичной памяти, чтобы освободить место для поступающей страницы. Принцип оптимальности Этот принцип говорит о том, что для обеспечения оптимальных скоростных характеристик и эффективного использования ресурсов следует заменять ту страницу, к которой в дальнейшем не будет новых обращений в течение наиболее длительного времени. Реализовать эту стратегию невозможно, т.к. мы не умеем предсказывать будущее. Однако можно использовать другие стратегии, которые в той или иной мере приближаются к принципу оптимальности. Выталкивание случайной страницы В этом случае все страницы, находящиеся в реальной памяти, могут быть выбраны для выталкивания с равной вероятностью, в том числе и следующая страница, к которой будет производиться обращение. Поэтому в реальных системах эта стратегия не применяется. Выталкивание первой пришедшей страницы (FIFO – First-In-First-Out) Каждой странице в момент поступления присваивается временная метка. Когда появляется необходимость удалять из основной памяти какую-нибудь страницу, то выбирается та, которая находилась в памяти дольше других. В пользу подобной стратегии можно привести тот аргумент, что у данной страницы уже были возможности использовать свой шанс, и пора дать такую возможность другим страницам. Но в равной степени такая стратегия будет приносить ущерб: будут замещаться активно используемые страницы, поскольку тот факт, что страница долго находится в памяти может означать, что она постоянно в работе. К тому же имеет место некоторое явление, называемое аномалией FIFO. Его суть заключается в том, что иногда увеличение количества страничных кадров, выделяемых процессу, приводит к увеличению частоты прерываний по отсутствию нужных страниц для этого процесса. Рассмотрим рисунок: 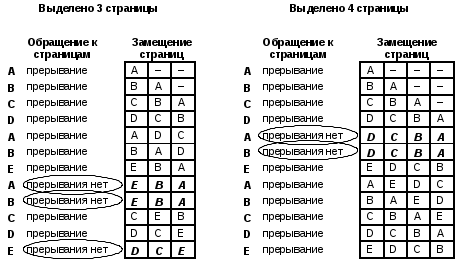 Выталкивание дольше всего не использовавшейся страницы (LRU – Least-Recently-Used) Эта стратегия предусматривает, что для выталкивания следует выбирать ту страницу, которая не использовалась дольше других. При ее использовании при каждом обращении к странице ее временная метка обновляется. В ее пользу можно высказать такой аргумент – если страница давно не использовалась, то он входит в число редко используемых страниц. Но использование этой стратегии сопряжено с рядом трудностей. Во-первых, трудности чисто технического характера – ее реализация сопряжена с дополнительными временными затратами, что существенно влияет на производительность ОС. Во-вторых, может случиться, что страница, к которой дольше всего не было обращений, станет следующей используемой страницей (если программа к этому моменту пройдет очередной цикл). Поэтому нам придется загружать только что вытолкнутую страницу. Выталкивание реже всего используемой страницы (LFU – Least-Frequently-Used) При использовании этой стратегии используется наименее интенсивно используемая страница или обращения к которой наименее часты. У этого механизма есть серьезный недостаток – довольно часто будет выталкиваться та страница, которая была только что загружена и успела использоваться только один раз, в то время как к другим страницам могли обращаться уже несколько раз. Таким образом, любой механизм выталкивания не исключает опасности принятия нерационального решения. Наиболее близким приближением к принципу оптимальности является NUR. Выталкивание не использовавшейся в последнее время страницы (NUR – Not – Used - Recently) Эта стратегия основывается на принципе: к страницам, которые в последнее время не использовались, вряд ли будут обращения и в ближайшем будущем, так что их можно заменять на вновь поступающие страницы. Этот механизм предусматривает введение двух аппаратных битов-признаков на страницу. Это: бит-признак обращения = 0, если к странице обращений не было; =1, если к странице были обращения; бит-признак модификации = 0, если страница не изменялась, =1, если страница изменялась. Стратегия NUR реализуется следующим образом. Первоначально биты-признаки обращения и модификации для всех страниц устанавливаются в 0. При обращении к какой-либо странице бит-признак обращения устанавливается в 1, а в случае изменения содержимого устанавливается в 1 и ее бит-признак модификации. Когда нужно выбрать страницу для выталкивания, пытаемся прежде всего найти такую страницу, к которой не было обращений. В противном случае, нам ничего не остается, как вытолкнуть ту страницу, к которой были обращения. Если к странице обращения были, то мы проверяем, подвергалась ли она изменению или нет. Если нет, то заменяем ее из тех соображений, что это связано с меньшими затратами. В противном случае нам придется заменять модифицированную страницу. Если память работает интенсивно, то вскоре мы не сможем отличить те страницы, которые вытолкнуть наиболее рационально. Один из широко используемых способов решения этой проблемы заключается в том, что все биты-признаки обращений сбрасываются и устанавливаются в 0 затем, чтобы механизм выталкивания оказался вновь в исходном состоянии. Такой алгоритм предусматривает существование четырех групп страниц:
Страницы групп с меньшими номерами будут выталкиваться в первую очередь. Отметим, что группа 2 обозначает на первый взгляд нереальную ситуацию, она включает страницы, к которым не было обращений, но они оказались модифицированными. На самом деле это результат того, что биты-признаки обращения периодически сбрасываются. Рабочие множества П. Дж. Деннинг разработал концепцию рабочих множеств, согласно которой выталкивается та страница, которая не входит в подмножество наиболее активно использующихся страниц процесса. Этой стратегией пользуется ОС Windows NT. Рабочим множеством считают минимальное количество страниц процесса, которое должно находиться в памяти, прежде чем процесс сможет выполняться. Если число страниц меньше рабочего набора, то процесс постоянно “пробуксовывает”, поскольку программа многократно будет подкачивать одни и те же страницы из внешней памяти. В момент создания процессу назначается минимальный размер рабочего набора, т.е. минимальное количество страниц процесса, которые гарантированно будут присутствовать в памяти во время его выполнения. Если процессу потребуются дополнительные страницы, то система в случае небольшой загруженности основной памяти позволит сразу же разместить их. В противном случае, из рабочего набора процесса будет удалена какая-нибудь страница, используя одну из стратегий выталкивания (чаще всего FIFO). Таким образом получаем, что во время работы процесса его рабочие множества динамически меняются – к текущему рабочему множеству добавляются ли удаляются некоторые страницы. Ниже на рисунке показано, как мог бы использовать первичную память процесс при управлении памятью по рабочим множествам. 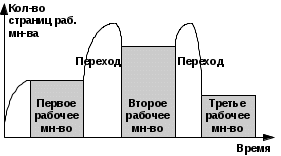 Этот рисунок иллюстрирует одну из самых серьезных трудностей, связанных с выбором этой стратегии: поскольку рабочие множества меняются во времени, нужно избегать перегрузок первичной памяти и возникающего вследствие пробуксирования. Виртуальная память в действии Обработка обращения к данным начинается с анализа адреса виртуальной памяти. MMU ищет этот адрес в своих таблицах, которые отображают адреса виртуальной памяти на физическую память. Это позволяет определить, находятся ли требуемые данные в оперативной памяти или в файле подкачки, либо их требуется извлекать с жесткого диска. После того как все необходимые шаги по загрузке данных выполнены, их адрес в оперативной памяти сообщается центральному процессору 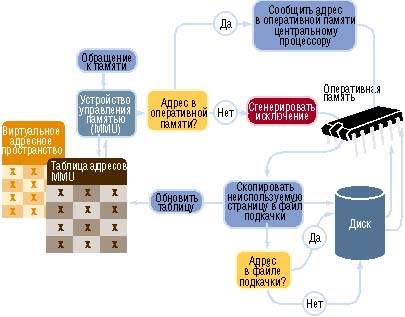 |