курсовая 2. 1 Постановка задачи 4 2 Формальная модель задачи 5
 Скачать 0.89 Mb. Скачать 0.89 Mb.
|

 Содержание Введение 3 1 Постановка задачи 4 2 Формальная модель задачи 5 3 Структура программы………………………………………………….....16 3.1 Лексический анализатор 16 3.2 Синтаксический анализатор 18 3.3 Семантический анализатор 20 3.4 Генерация ПОЛИЗа программы 22 3.5 Интерпритация ПОЛИЗа программы 24 4 Структурная организация данных 31 4.1 Спецификация входной информации 31 4.2 Спецификация выходной информации 31 4.3 Спецификация процедур и функций 31 5 Разработка алгоритма решения задачи 32 5.1 Укрупненная схема алгоритма программного средства 32 5.2 Детальная разработка алгоритмов отдельных подзадач 33 6 Установка и эксплуатация программного средства 34 7 Работа с программным средством 35 Заключение 36 Список использованных источников 37 Приложение А – Текст программы 38 Введение Теория формальных языков, грамматик и автоматов составляет фундамент синтаксических методов. Основы этой теории были заложены Н. Хомским в 40–50-е годы XX столетия в связи с его лингвистическими работами, посвященными изучению естественных языков. Но уже в следующем десятилетии синтаксические методы нашли широкое практическое применение в области разработки и реализации языков программирования. В настоящее время искусственные языки, использующие для описания предметной области текстовое представление, широко применяются не только в программировании, но и в других областях. С их помощью описывается структура всевозможных документов, трехмерных виртуальных миров, графических интерфейсов пользователя и многих других объектов, используемых в моделях и в реальном мире. Для того чтобы эти текстовые описания были корректно составлены, а затем правильно распознаны и интерпретированы, применяются специальные методы их анализа и преобразования. В основе данных методов лежит теория формальных языков, грамматик и автоматов. Теория формальных языков, грамматик и автоматов дала новый стимул развитию математической лингвистики и методам искусственного интеллекта, связанных с естественными и искусственными языками. Кроме того, ее элементы успешно применяются, например, при описании структур данных, файлов, изображений, представленных не в текстовом, а двоичном формате. Эти методы полезны при разработке своих трансляторов даже там, где уже имеются соответствующие аналоги. Несмотря на то, что к настоящему времени разработаны тысячи различных языков и их компиляторов, процесс создания новых приложений в этой области не прекращается. Это связно как с развитием технологии производства вычислительных систем, так и с необходимостью решения все более сложных прикладных задач. Такая разработка может быть обусловлена различными причинами, в частности, функциональными ограничениями, отсутствием локализации, низкой эффективностью существующих компиляторов. Целью курсовой работы являться: закрепление теоретических знаний в области теории формальных языков, грамматик, автоматов и методов трансляции; формирование практических умений и навыков разработки собственного компилятора модельного языка программирования; закрепление практических навыков самостоятельного решения инженерных задач, развитие творческих способностей студентов и умений пользоваться технической, нормативной и справочной литературой. 1 Постановка задачи Разработать компилятор модельного языка, выполнив следующие действия. 1) В соответствии с номером варианта составить формальное описание модельного языка программирования с помощью: а) РБНФ; б) диаграмм Вирта; в) формальных грамматик. 2) Написать пять содержательных примеров программ, раскрывающих особенности конструкций учебного языка программирования, отразив в этих примерах все его функциональные возможности. 3) Составить таблицы лексем и диаграмму состояний с действиями для распознавания и формирования лексем языка. 4) По диаграмме с действиями написать функцию сканирования текста входной программы на модельном языке. 5) Разработать программное средство, реализующее лексический анализ текста программы на входном языке. 6) Реализовать синтаксический анализатор текста программы на модельном языке методом рекурсивного спуска. 7) Построить цепочку вывода и дерево разбора простейшей программы на модельном языке из начального символа грамматики. 8) Дополнить синтаксический анализатор процедурами проверки семантической правильности программы на модельном языке в соответствии с контекстными условиями вашего варианта. 9) Распечатать пример таблиц идентификаторов и двуместных операций. 10) Показать динамику изменения содержимого стека при семантическом анализе программы на примере одного синтаксически правильного выражения. 11) Записать правила вывода грамматики с действиями по переводу в ПОЛИЗ программы на модельном языке. 12) Пополнить разработанное программное средство процедурами, реализующими генерацию внутреннего представления введенной программы в форме ПОЛИЗа. 13) Разработать интерпретатор ПОЛИЗа программы на модельном языке. 14) Составить набор контрольных примеров, демонстрирующих: а) все возможные типы лексических, синтаксических и семантических ошибок в программах на модельном языке; б) перевод в ПОЛИЗ различных конструкций языка; в) представить ход интерпретации синтаксически и семантически правильной программы с помощью таблицы. 2 Формальная модель задачи Процесс компиляции включает два основных этапа: анализ и синтез. На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Программа переводится во внутреннее представление, понятное компилятору. На этапе синтеза порождается текст результирующей программы, результатом этапа является объектный код. В составе компилятора имеются также процедуры и функции, ответственные за анализ и исправление ошибок, которые в случае обнаружения последних, должны полно и точно информировать пользователя о типе ошибки и месте ее возникновения. Данные этапы состоят в свою очередь из более мелких этапов, называемых фазами компиляции: синтаксический анализ, синтаксический анализ, семантический анализ, подготовка к генерации кода, генерация кода. Лексический анализатор производит чтение символов программы на исходном языке и строит из них слова (лексемы) исходного языка, которые передаются для дальнейшей обработки на этапе синтаксического анализа. Синтаксический разбор - часть компилятора, выполняющая выделение синтаксических конструкций в тексте исходной программы, обработанной лексическим анализатором. На этой же фазе проверяется синтаксическая правильность программы. Семантический анализ - часть компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме непосредственно проверки выполняются преобразования текста, требуемые семантикой входного языка. В данной реализованной программе семантические проверки входят в состав синтаксического анализатора. На фазе подготовки к генерации кода выполняются предварительные действия, непосредственно связанные с синтезом текста результирующей программы, но еще не ведущие к порождению текста на выходном языке. На фазе генерации кода порождаются команды, составляющие предложения выходного языка и в целом текст результирующей программы. Грамматика - это описание способа построения предложений некоторого языка. Для полного формального определения грамматики кроме правил порождения цепочек языка необходимо задать также алфавит языка. Формально грамматика G определяется как четверка G(VT, VN,P,S), где VT: множество терминальных символов; VN: множество нетерминальных символов; P: множество правил вывода S: начальный символ грамматики. РБНФ в соответствии с вариантом: <буква>::= A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z <цифра> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 <число>::= <целое> | <действительное> <целое>::= <двоичное> | <восьмеричное> | <десятичное> | <шестнадцатеричное> <двоичное>::= {/ 0 | 1 /} (B | b) <восьмеричное>::= {/ 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 /} (O | o) <десятичное>::= {/ <цифра> /} [D | d] <шестнадцатеричное>::= <цифра> {<цифра> | A | B | C | D | E | F | a | b | c | d | e | f} (H | h) <действительное>::= <числовая_строка> <порядок> | [<числовая_строка>] . <числовая_строка>[порядок] <числовая_строка>::= {/ <цифра> /} <порядок>::= ( E | e )[+ | -] <числовая_строка> <идентификатор> ::= <буква> { <буква> | <цифра> } <ключевое_слово> ::= or | and | not | integer | real | boolean| ass | if | then | else | for | to | do | while| read | write | true | false <разделитель> ::= < > | = | < | <= | > | >= | + | - | * | / | ; | : | ( | ) | { | } | , | . | <тип>::= integer | real | boolean <описание>::= <тип> <идентификатор> { , <идентификатор> } <оператор>::= <составной> | <присваивания> | <условный> | <фиксированного_цикла> | <условного_цикла> | <ввода> | <вывода> <составной>::= <оператор> { ( : | перевод строки) <оператор> } <операнд>::= <слагаемое> {<операции_группы_сложения> <операнд>} <выражение>::= <операнд>{<операции_группы_отношения> <операнд>} <присваивания>::= <идентификатор> ass <выражение> <условный>::= if <выражение> then <оператор> [ else <оператор>] <фиксированного_цикла>::= for <присваивания> to <выражение> do <оператор> <условного_цикла>::= while <выражение> do <оператор> <ввода>::= read«(»<идентификатор> {, <идентификатор> } «)» <вывода>::= write «(»<выражение> {, <выражение> } «)» <программа>::= program var<описание> begin<оператор> {; <оператор>} end. <операции_группы_отношения>:: = < > | = | < | <= | > | >= <операции_группы_сложения>:: = + | - | or <операции_группы_умножения>::= * | / | and <унарная_операция>::= not <слагаемое>::= <множитель> {<операции_группы_умножения> <множитель>} <множитель>::= <идентификатор> | <число> | <логическая_константа> | <унарная_операция> <множитель> | «(»<выражение>«)» <логическая_константа>::= true | false Правила вывода грамматики модельного языка М: P program var D1 begin S1 end. D1 O;| D1;O; O integer I1 | real I1 | boolean I1 I1 I | I1, I S1 S |S1; S Z1 : |ENTER S S Z1 S | if E then S| if E then S else S | while E do S | for I ass E to E do S | read(I1) | write(E2) | I ass E E2 E E1 | E1<>E1| E1=E1 | E1<E1 | E1<=E1|E1>E1 | E1>=E1 El T | T+E1 | T-E1 | T or El T F | F*T | F/T | F and T F I | N | L | not F | (E) L true | false I C | IC | IR Z41 | b Z42 O | o Z43 D | d Z44 H | h N R21Z41 | R81Z42 | R101 Z43 | R101 | R161Z44| V R21 R2 | R21 R2 R81 R8 | R81 R8 R101 R10 | R101R10 R161 R10 | R161R16 Z2 | - Z3 | e V R101 P | .R101 P |R101 .R101 P | .R101|R101 .R101 P Z3 Z2 R101 | Z3R101 C A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z R2 0 | 1 R8 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 R10 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 R16 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F Ниже представлены диаграммы Вирта: цифра  буква  и 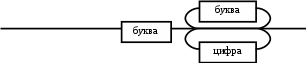 дентификатор дентификаторчисло  ц 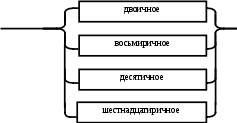 елое елоед  воичное воичноед  есятичное есятичное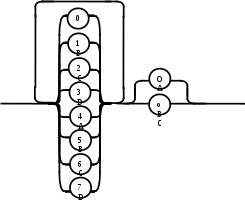 восьмиричное Шестнадцатиричное 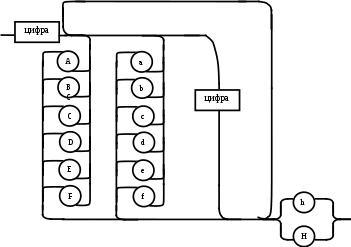 действительное 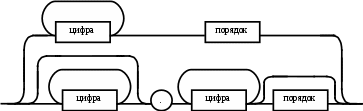 порядок  ключевое_слово 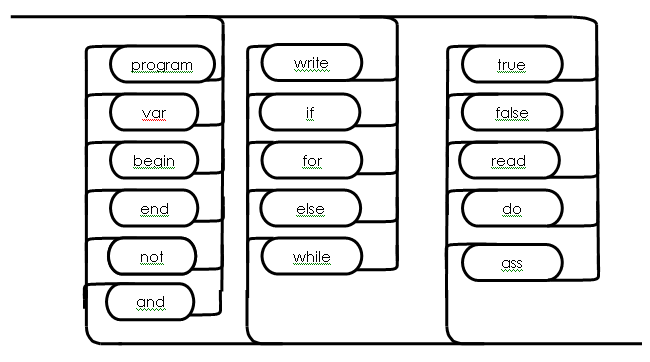 Разделитель  п  рограмма рограммаописание  о 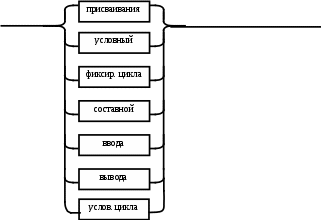 ператор ператорприсваивания  у  словный словныйу  сл. цикла сл. циклафикс. цикла 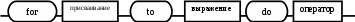 с 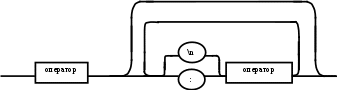 оставной оставной ввода  вывода  в 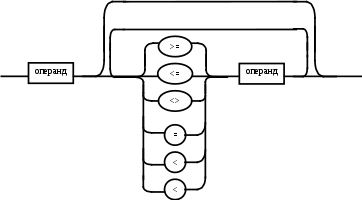 ыражение ыражение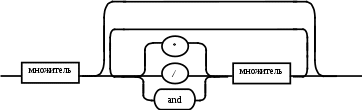 слагаемое множитель 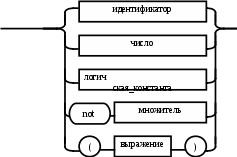 о 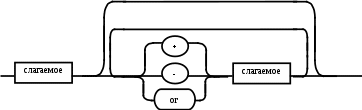 перанд перандл  огическая_константа огическая_константаПримеры программ для описываемого языка program var integer k,n,sum,i; boolean r; begin read(n); sum ass 0 i ass 1; while i<=n do read(k) sum ass sum+k {комментарий} i ass i+1; write(sum) end. program var real a,b,c,d,e,x; begin a ass .35; b ass 1.26; c ass 5e-1; d ass 1.2E-1; e ass .3e+1; x ass 154.36; write(x) end. program var integer i,a; begin read(a); for i ass 0 to a do write (i) end. 3 Структура программы 3.1 Лексический анализатор Лексический анализатор (ЛА) – это первый этап процесса компиляции, на котором символы, составляющие исходную программу, группируются в отдельные минимальные единицы текста, несущие смысловую нагрузку – лексемы. Задача лексического анализа - выделить лексемы и преобразовать их к виду, удобному для последующей обработки. ЛА использует регулярные грамматики. ЛА необязательный этап компиляции, но желательный по следующим причинам: 1) замена идентификаторов, констант, ограничителей и служебных слов лексемами делает программу более удобной для дальнейшей обработки; 2) ЛА уменьшает длину программы, устраняя из ее исходного представления несущественные пробелы и комментарии; 3) если будет изменена кодировка в исходном представлении программы, то это отразится только на ЛА. В процедурных языках лексемы обычно делятся на классы: служебные слова; ограничители; числа; идентификаторы. Каждая лексема представляет собой пару чисел вида (n, k), где n – номер таблицы лексем, k - номер лексемы в таблице. Входные данные ЛА - текст транслируемой программы на входном языке. Выходные данные ЛА - файл лексем в числовом представлении. Для модельного языка М таблица служебных слов (1) будет иметь вид: 1)Program 2)var 3)begin 4)end 5)ass 6)or 7)and 8)not 9)for 10)to 11)do 12)read 13)write 14)if 15)then 16)else 17)while 18)true 19)false 20)integer 21)Boolean 22)real Таблица ограничителей (2) содержит: 1)13 2)<> 3)<= 4)>= 5)= 6)< 7)> 8)+ 9)- 10)* 11)/ 12); 13): 14)( 15)) 16){ 17)} 18), 19). 20)W 21)R 22)! 23)!F 24)$ 25)% Таблицы идентификаторов (4) и чисел (3) формируются в ходе лексического анализа. Входные данные ЛА: program var integer a,b; begin read(a,b); if a>b then write (a) else write (b) end. Выходные данные ЛА: { (1,1) (1,2) (1,20),(4.1),(2,18),(4.2) (2,12) (1,3) (1,12) (2,14) (4,1) (2,18) (4,2) (2,15) (2,12) (1,14) (4,1) (2,7) (4,2) (1,15) (1,13) (2,14) (4,1) (2,15) (1,16) (1,13) (2,14) (4,2) (2,15)(1,4),(2,19) } Анализ текста проводится путем разбора по регулярным грамматикам и опирается на способ разбора по диаграмме состояний, снабженной дополнительными пометками-действиями. Смысл этой конструкции: если текущим является состояние А и очередной входной символ совпадает с Для удобства разбора вводится дополнительное состояние диаграммы ER, попадание в которое соответствует появлению ошибки в алгоритме разбора. Переход по дуге, не помеченной ни одним символом, осуществляется по любому другому символу, кроме тех, которыми помечены все другие дуги, выходящие из данного состояния. Алгоритм. Разбор цепочек символов по ДС с действиями Шаг 1. Объявляем текущим начальное состояние в диаграмме состояний H. Шаг 2. До тех пор, пока не будет достигнуто состояние ER или конечное состояние диаграммы состояний, считываем очередной символ анализируемой строки и переходим из текущего состояния диаграммы состояний в другое по дуге, помеченной этим символом, выполняя при этом соответствующие действия. Состояние, в которое попадаем, становится текущим. Составим ЛА для модельного языка М. Предварительно введем следующие обозначения для переменных, процедур и функций. Переменные: 1) СН – очередной входной символ; CS – текущее состояние буфера накопления лексем с возможными значениями: Н – начало, I – идентификатор, N – число, С – комментарий, M – конец программы («}»), N2 – запись двоичного числа, N8 – запись восьмеричного числа, N16 – запись шестнадцатеричного числа, N10 – запись десятичного числа, ER –ошибка; t - таблица лексем анализируемой программы с возможными значениями: TW – таблица служебных слов М-языка, TL – таблица ограничителей М-языка, TI – таблица идентификаторов программы, TC – таблица чисел; 4) z - номер лексемы в таблице t (если лексемы в таблице нет, то z=0). Процедуры и функции: 1) gc – процедура считывания очередного символа текста в переменную СН; 2) let – логическая функция, проверяющая, является ли переменная СН буквой; 3) digit - логическая функция, проверяющая, является ли переменная СН цифрой; 4) nill – процедура очистки буфера S; 5) add – процедура добавления очередного символа в конец буфера S; 6) look(n,k) – процедура поиска лексемы из буфера S в таблице с номером n с возвращением номера лексемы в таблице, k – количество элементов в таблице; 7) put(t) – процедура записи лексемы из буфера S в таблицу t, если там не было этой лексемы, иначе возвращает номер данной лексемы в таблице; 8) out(n, k) – процедура записи пары чисел (n, k) в файл лексем; Диаграмма состояний с действиями для модельного языка 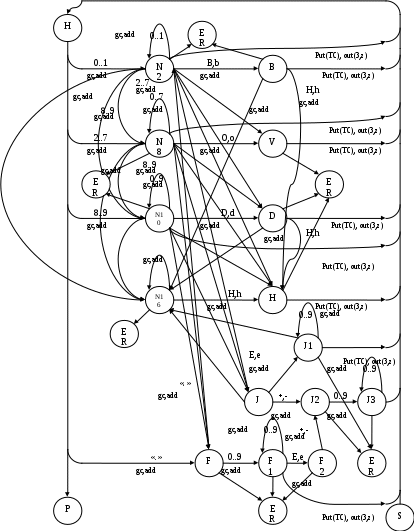 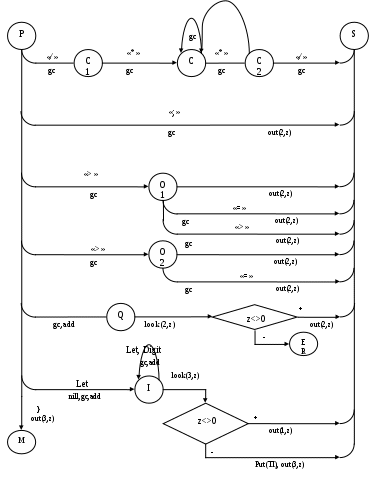 Рисунок 1 – Диаграмма состояний с действиями для модельного языка М 3.2 Синтаксический анализатор Задача синтаксического анализатора (СиА) - провести разбор текста программы, сопоставив его с эталоном, данным в описании языка. Для синтаксического разбора используются контекстно-свободные грамматики. Один из эффективных методов синтаксического анализа – метод рекурсивного спуска. В основе метода рекурсивного спуска лежит левосторонний разбор строки языка. Исходной сентенциальной формой является начальный символ грамматики, а целевой – заданная строка языка. На каждом шаге разбора правило грамматики применяется к самому левому нетерминалу сентенции. Данный процесс соответствует построению дерева разбора цепочки сверху вниз, следующим образом. Для каждого нетерминального символа грамматики создается своя процедура, носящая его имя. Задача этой процедуры – начиная с указанного места исходной цепочки, найти подцепочку, которая выводится из этого нетерминала. Если такую подцепочку считать не удается, то процедура завершает свою работу вызовом процедуры обработки ошибок, которая выдает сообщение о том, что цепочка не принадлежит языку грамматики и останавливает разбор. Если подцепочку удалось найти, то работа процедуры считается нормально завершенной и осуществляется возврат в точку вызова. Тело каждой такой процедуры составляется непосредственно по правилам вывода соответствующего нетерминала, при этом терминалы распознаются самой процедурой, а нетерминалам соответствуют вызовы процедур, носящих их имена. Входные данные – файл лексем в числовом представлении. Выходные данные – заключение о синтаксической правильности программы или сообщение об имеющихся ошибках. Цепочка вывода и дерево разбора Рассмотрим пример следующей программы: program var int a,b; begin for a ass 1 to 3 do b ass b+1; end Дерево разбора       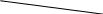    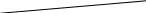 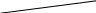      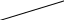  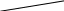  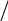  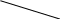              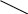           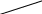 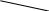      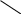    Цепочка вывода: P program var D1 begin S1 end program var О1 begin S end program var int I1; begin for I ass E to E do S end program var int C,I; begin for C ass E1 to E1 do I ass E; end program var int a,C; begin for a ass T to T do C ass E1;end program var int a,b; begin for a ass F to F do b ass E1+T; end program var int a,b; begin for a ass N to N do b ass T+F; end program var int a,b; begin for a ass R101 to R101 do b ass F+N; end program var int a,b; begin for a ass R10 to R10 do b ass I+R101 ;end program var int a,b; begin for a ass 1 to 3 do b ass C+ R10;end program var int a,b; begin for a ass 1 to 3 do b ass b+1; end       3.3 Семантический анализатор программы В ходе семантического анализа проверяются отдельные правила записи исходных программ, которые не описываются КС-грамматикой. Эти правила носят контекстно-зависимый характер, их называют семантическими соглашениями или контекстными условиями. Рассмотрим пример построения семантического анализатора (СеА) для программы на модельном языке М. Соблюдение контекстных условий для языка М предполагает три типа проверок: 1) обработка описаний; 2) анализ выражений; 3) проверка правильности операторов. В оптимизированном варианте СиА и СеА совмещены и осуществляются параллельно. Поэтому процедуры СеА будем внедрять в ранее разработанные процедуры СиА. Обработка описаний. Задача обработки описаний – проверить, все ли переменные программы описаны правильно и только один раз. Решается расширением таблицы идентификаторов. Задача анализа выражений – проверить описаны ли переменные, встречающиеся в выражениях, и соответствуют ли типы операндов друг другу и типу операции. Эти задачи решаются следующим образом. Вводится таблица двуместных операций (таблица 2) и стек, в который в соответствии с разбором выражения B заносятся типы операндов и знак операции. После семантической проверки в стеке оставляется только тип результата операции. В результате разбора всего выражения в стеке остается тип этого выражения. Пример. Дано выражение b-4+8. Дерево разбора выражения:  1)  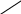   2) 3)
  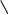     
    
     Рисунок 2 – Анализ выражения b-4+8 Проверка правильности операторов Задачи проверки правильности операторов: 1) выяснить, все ли переменные, встречающиеся в операторах, описаны; 2) установить соответствие типов в операторе присваивания слева и справа от символа «ass»; 3) определить, является ли выражение E в операторах условия и цикла булевым. Задача решается проверкой типов в соответствующих местах программы. Пример таблицы идентификаторов Таблица 1 – Таблица идентификаторов на этапе семантического анализа
Пример таблицы двуместных операций Таблица 2 – Таблица двуместных операций
3.4 Генерация ПОЛИЗа программы В ПОЛИЗе операнды записаны слева направо в порядке использования. Знаки операций следуют таким образом, что знаку операции непосредственно предшествуют его операнды. Пример 1: Для выражения в обычной (инфиксной записи) a*(b+c)-(d-e)/f ПОЛИЗ будет иметь вид: abc+*de-f/-. Справедливы следующие формальные определения. Определение: Если B является единственным операндом, то ПОЛИЗ выражения B – это этот операнд. Определение: ПОЛИЗ выражения B1 B2, где - знак бинарной операции, B1 и B2 – операнды для , является запись Определение: ПОЛИЗ выражения B, где - знак унарной операции, а B – операнд , есть запись Определение: ПОЛИЗ выражения (B) есть ПОЛИЗ выражения B. |