|
|
Оценка катастроф программа. Фрагмент примера слабой курсовой. 1. Задание на курсовую работу 2 Выбор методов анализа данных 3
Оглавление
1. Задание на курсовую работу 2
2. Выбор методов анализа данных 3
3. Практическая реализация 5
4. Анализ результатов 6
5. Выводы 10
Список литературы. 11
Разработать программу, позволяющую найти ответы на заданные вопросы:
На какие группы можно разделить катастрофы по степени тяжести и сколько таких групп в пределах оценки от 2 до 10?
Какова максимальная поддержка, при которой можно говорить о связях между континентами и подгруппами катастроф?
Есть ли аномальные данные по тяжести, если есть, то какие?
Анализируемая выборка содержит информацию, разделенную на образцы следующего содержания:
Континент
Страна
Подгруппа катастрофы
Количество катастроф
Смертность от катастрофы
Количество увеченных
Количество пострадавших
Количество бездомных
Всего пострадавших
Всего ущерба нанесено
Ссылка на источник данных: http://www.emdat.be/advanced_search/index.html
2. Выбор методов анализа данных
Анализ данных проводился на основе выборки из 1035 образцов описанного выше содержания.
Для ответа на первый вопрос в качестве значимых свойств были выбраны следующие:
Смертность от катастрофы
Количество увеченных
Количество пострадавших
Количество бездомных
Для кластеризации был выбран алгоритм K-means. Выбор данного алгоритма обусловлен следующими факторами:
В силу большого количества размерностей сложно адекватно определить плотность расположения образцов в различных точках пространства, в связи с чем крайне затруднено использование алгоритмов типа DBSCAN;
Использование иерархических алгоритмов не показательно, т.к. объем данных слишком велик;
K-means прост в реализации и позволяет легко оценить количество кластеров для заданного интервала без специфического алгоритма подбора параметров.
Оценка качества кластеризации была проведена на основании расчета среднеквадратичной ошибки. Данный вид оценки является классическим и наиболее простым, при этом имеет минимальные показатели вычислительных затрат [1].
Для ответа на второй вопрос был выбран алгоритм FPGrow. Фактически, выбор стоял между двумя кандидатами:
Apriori;
FPGrow.
Узким местом в алгоритме a Apriori является процесс генерации кандидатов в популярные предметные наборы [2]. Например, если база данных (БД) транзакций содержит 100 предметов, то потребуется сгенерировать 21001030 кандидатов.
Учитывая то, что выборка содержит сгруппированные по количеству происшествий данные, то фактически, из 1035 образцов объем выборки для поиска ассоциаций возрастает до 22455 образцов, что позволяет нам сделать вывод о неэффективности алгоритма Apriori.
Ответ на третий вопрос был дан путем использования алгоритма K-means с малым количеством кластеров. Так как в нашем случае заранее неизвестно, какие объекты будут аномальны, для анализа был выбран метод кластеризации k-means, как простой и быстрый итеративный алгоритм [3].
3. Практическая реализация
Алгоритмы анализа были реализованы с помощью готовых решений Apache Spark на платформе Databricks. Используемый язык программирования – Python.
Анализ данных для первого вопроса состоял из следующих этапов:
Нормализация данных с использованием функции Normalize();
Реализация пользовательской функции вычисления средней квадратичной ошибки для заданного распределения по кластерам;
Поиск наилучшего распределения с использованием функции KMeans.train().
Поиск лучшего распределения осуществлялся в пределах от 2 до 10 кластеров.
Для реализации алгоритма для второго вопроса сначала необходимо было подготовить данные. Каждый образец, со значением «количество катастроф» больше одного был разбит на соответствующее количество образцов.
Для поиска ассоциаций использовалась функция FPGrowth.train(). При этом было задано начальное значение минимальной поддержки 0.2 и далее, соответственно, это значение уменьшалось с переменным шагом до момента получения не менее 8 связей.
Реализация алгоритмов третьего вопроса заключалась в кластеризации функцией KMeans.train() с количеством кластеров равным 3. Далее были отобраны кластеры, которые содержали менее 20 образцов ( < 2% от общего числа образцов). Соответственно, данные образцы являются аномальными.
4. Анализ результатов
Первый вопрос.
Наилучшее значение по количеству кластеров оказалось значение в 9 кластеров.
Можно объяснить такое распределение кластеров следующим образом:
Однозначно, в отдельные кластеры были выделены как минимум 3 кластера, которые не имеют либо бездомных, либо изувеченных, либо умерших.
Помимо этого, видимо, были сформированы классы комбинаций отсутствия этих параметров (еще 4 кластера).
Два оставшихся кластера сформированы на основании особо тяжких и легких катастроф.
Данные выводы могут быть подтверждены распределением точек на графике (рисунок 1). Конечно, такое представление не слишком удобно для визуального анализа, но здесь приведены все комбинации по два свойства и видно, что в основном точки распределены по осям координат, в соответствии с указанными выше пунктами 1 и 2. Однако есть и точки, расположенные по дуге на удаленном расстоянии от центра (особо тяжкие) и точки, расположенные ближе к центрам координат (легкой тяжести).
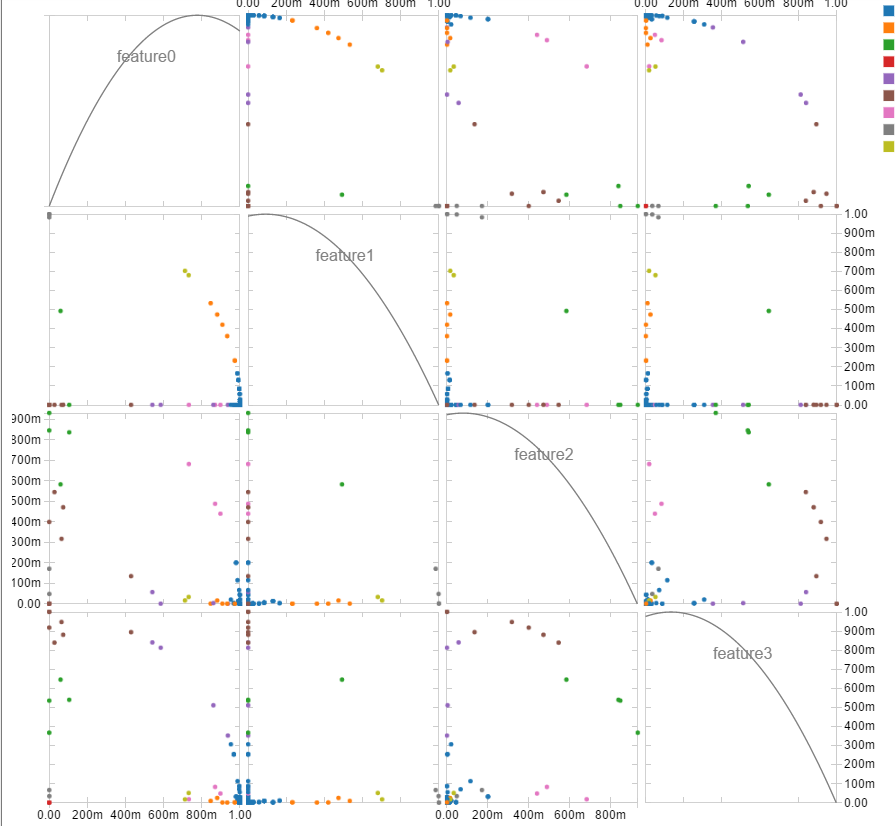
Рисунок 1 Распределение катастроф по степеням тяжести
Второй вопрос.
Результат работы алгоритма дал следующие значения (рисунок 2).

Рисунок 2 Связь континентов и подгруппы катастроф
Предполагалось определить как минимум 8 зависимостей, которые бы соответствовали одной из 8 подгрупп катастроф. Однако в результате мы получили зависимости всего о катастрофах и четырех континентах с уровнем поддержки 0.05.
Можно сделать следующие выводы:
Найдены наиболее типичные катастрофы для 4 континентов.
Америка является наиболее подверженной в силу своей протяженности на множество климатических поясов. Для нее не являются редкостью торнадо и другие природные катаклизмы. На береговой части возможны цунами. Техногенные катастрофы так же не удивительны в силу развитости стран.
Для азиатских стран так же характерны засухи и природные катаклизмы, такие как землетрясения. Техногенные катастрофы однозначно являются не редкостью в Китае, помимо этого можно сказать о множестве крупных и малых катастроф связанных с ядерной энергетикой. Стоит выделить частые цунами в Японии.
Африка и Европа – техногенные катастрофы, что вполне логично, за исключением того, что Африка, как никто другой, страдает от засух. Однако, наиболее вероятно, что в таком бедном районе не ведется особо подробная статистика катастроф, поэтому часть из них, возможно, просто не попала в выборку.
Интересно, что для Океании не найдено никаких связей, что свидетельствует об отсутствии типичных для нее катастроф. И действительно, данный континент не имеет проблем с засухой, обладает хорошим для человека климатом, политическая ситуация спокойная, редкими для данного континента являются различные природные катаклизмы.
Третий вопрос.

Рисунок 3 Аномальные катастрофы
Б
ыли выявлены аномалии, отображенные на рисунке 3.
Данные аномалии характерны огромными размерами ущерба в Азии, в основном в Китае и Индии. Это можно объяснить тем, что для этих стран характерна чрезвычайно большая плотность населения и большая плотность построек. Таким образом, при возникновении какой-либо катастрофы количество ущерба выше, чем в других странах. Заметим, что связь между данными катастрофами и Азиатской частью земли были получены в вопросе два, что так же объясняет большое количество жертв – большая частота возникновения данных катастроф.
5. Выводы
Полученные результаты совпадают с предположениями, сделанными на основе информационного образа анализируемых стран. Все выявленные связи и особенности могут быть логически объяснены без привлечения большого количества допущений, что свидетельствует о правдоподобности полученной информации.
Конечно, данная выборка не является в полной степени презентативной, т.к. некоторые страны (например, Африка) не способны предоставлять полную статистику, либо сбор этой статистики начался сравнительно недавно.
Список литературы.
Мандель И.Д. Кластерный анализ. — М.: Финансы и статистика, 1988. — 176 с.
Чубукова И.А. Data mining. – Курс лекций. – 326 с.
Афанасьева Т.В., Сапунков, А.А., Заварзин Д.В. Применение алгоритма кластеризации k-means для улучшения темпоральной статистики просмотра коммерческих предложений// Автоматизация процессов управления – М: «НПО «Марс», 2016 – № 4 – 41-46 с.
|
|
|
 Скачать 168.38 Kb.
Скачать 168.38 Kb.