33. Модели данных. Иерархическая, сетевая, реляционная модели баз данных
 Скачать 413.27 Kb. Скачать 413.27 Kb.
|

|
33. Модели данных. Иерархическая, сетевая, реляционная модели баз данных База данных (БД)представляет собой совокупность структурированных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области. Логическую структуру данных, хранимых в базе, называют моделью представления данных. К основным моделям представления данных (моделям данных) относятся иерархическая, сетевая, реляционная. Система управления базами данных (СУБД) —это комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями. Обычно СУБД различают по используемой модели данных. Так, СУБД, основанные на использовании реляционной модели данных, называют реляционными СУБД. Для работы с базой данных зачастую достаточно средств СУБД. Однако если требуется обеспечить удобство работы с БД неквалифицированным пользователям или интерфейс СУБД не устраивает пользователей, то могут быть разработаны приложения. Их создание требует программирования. Приложение представляет собой программу или комплекс программ, обеспечивающих автоматизацию решения какой-либо прикладной задачи. Приложения могут создаваться в среде или вне среды СУБД — с помощью системы программирования, использующей средства доступа к БД, к примеру, Delphi или С++ Вuildег. Приложения, разработанные в среде СУБД, часто называют приложениями СУБД, а приложения, разработанные вне СУБД, — внешними приложениями. Словарь данных представляет собой подсистему БД, предназначенную для централизованного хранения информации о структурах данных, взаимосвязях файлов БД друг с другом, типах данных и форматах их представления, принадлежности данных пользователям, кодах защиты и разграничения доступа и т. п. Информационные системы, основанные на использовании БД, обычно функционируют в архитектуре клиент-сервер. В этом случае БД размещается на компьютере-сервере, и к ней осуществляется совместный доступ. Серверомопределенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом, клиентом —компьютер (программа), использующий этот ресурс. В качестве ресурса компьютерной сети могут выступать, к примеру, базы данных, файлы, службы печати, почтовые службы. Достоинством организации информационной системы на архитектуре клиент-сервер является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации с индивидуальной работой пользователей. Согласно основному принципу архитектуры клиент-сервер, данные обрабатываются только на сервере. Пользователь или приложение формируют запросы, которые поступают к серверу БД в виде инструкций языка SQL. Сервер базы данных обеспечивает поиск и извлечение нужных данных, которые затем передаются на компьютер пользователя. Достоинством такого подхода в сравнении предыдущим является заметно меньший объем передаваемых данных. Выделяют следующие виды СУБД : * полнофункциональные СУБД; * серверы БД; * средства разработки программ работы с БД. Полнофункциональные СУБД представляют собой традиционные СУБД. К ним относятся dBaseIV, Microsoft Access, Microsoft FoxPro и др. Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Серверы БД обеспечивают обработку запросов клиентских программ обычно с помощью операторов SQL. Примерами серверов БД являются: Microsoft SQL Server, InterBase и др. В роли клиентских программв общем случае могут использоваться СУБД, электронные таблицы, текстовые процессоры, программы электронной почты и др. Средства разработки программ работы с БД могут использоваться для создания следующих программ: * клиентских программ; * серверов БД и их отдельных компонентов; * пользовательских приложений. Модель данных–этометод (принцип) логической организации данных, реализуемый в СУБД. По используемой модели данныхСУБД разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и др. Некоторые СУБД могут одновременно поддерживать несколько моделей данных. Для работы с данными, хранящимися в базе, используются следующие типы языков: * язык описания данных — высокоуровневый непроцедурный язык декларативного типа, предназначенный для описания логической структуры данных; * язык манипулирования данными — совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам. Основное различие между моделями баз данных состоит в характере описания взаимосвязи и взаимодействия между объектами и атрибутами базы данных. Связи объектов могут быть следующих типов: ¾ "один к одному"; ¾ "один ко многим"; ¾ "многие ко многим". "Один к одному" - это взаимно однозначное соответствие, которое устанавливается между одним объектом и одним атрибутом. Связь "один-к-одному" определяет такое отношение между таблицами, когда каждой записи в подчиненной таблице соответствует только одна запись в главной таблице. Наличие связей между таблицами "один-к-одному" обычно не говорит о хорошей структуре базе данных, поскольку свидетельствует о том, что две таблицы имеют полностью совпадающие поля, а это ведет к нерациональному расходу дискового пространства. Связь "один-ко-многим" в структурах баз данных является наиболее общепринятой. При этом типе связи каждой записи главной таблицы соответствует одна или несколько записей в подчиненной таблице. Структура связей типа "один-ко-многим" позволяет избежать избыточности данных и дублирования записей. Связь типа "многие-ко-многим" выражает такое отношение между таблицами, когда многие записи одной таблицы могут быть связаны со многими записями другой таблицы. Иерархическая модель баз данных (ИМД) основана на графическом способе и предусматривает поиск данных по одной из ветвей «дерева», в котором каждая вершина имеет только одну связь с вершиной более высокого уровня. Для осуществления поиска необходимо указать полный путь к данным, начиная с корневого элемента. 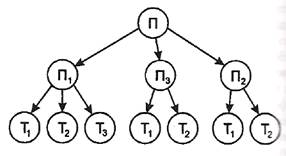 Рис. 1 – Иерархическая модель баз данных Сетевая модель баз данных (СМД) также основана на графическом способе, но допускает усложнение «дерева» без ограничения количества связей, входящих в вершину. Это позволяет строить сложные поисковые структуры. 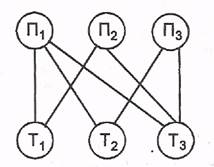 Рис. 2 – Сетевая модель баз данных Реляционная модель баз данных (РМД) реализует табличный способ. В реляционной модели базы данных взаимосвязи между элементами данных представляются в виде двумерных таблиц, называемых отношениями. Отношения обладают следующими свойствами: ¾ каждый элемент таблицы представляет собой один элемент данных (повторяющиеся группы отсутствуют); ¾ элементы столбца имеют одинаковую природу, и столбцам однозначно присвоены имена; ¾ в таблице нет двух одинаковых строк; ¾ строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания. Реляционная модель БД имеет дело с тремя аспектами данных: со структурой данных, с целостностью данных и с манипулированием данными. Под структурой понимается логическая организация данных в БД, под целостностью данных понимают безошибочность и точность информации, хранящейся в БД, под манипулированием данными - действия, совершаемые над данными в БД. Достоинства реляционной модели: ¾ простота построения; ¾ доступность понимания; ¾ возможность эксплуатации базы данных без знания методов и способов ее построения; ¾ независимость данных; ¾ гибкость структуры и др. Недостатки реляционной модели: ¾ низкая производительность по сравнению с иерархической и сетевой модели; ¾ сложность программного обеспечения; ¾ избыточность элементов. 6. Этапы и тенденция развития информационных систем Информационная система — взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки и выдачи информации в интересах достижения поставленной цели. Современное понимание информационной системы предполагает использование в качестве основного технического средства переработки информации персонального компьютера. В крупных организациях наряду с персональным компьютером в состав технической базы информационной системы может входить мэйнфрейм или суперЭВМ. Кроме того, техническое воплощение информационной системы само по себе ничего не будет значить, если не учтена роль человека, для которого предназначена производимая информация и без которого невозможно ее получение и представление. Необходимо понимать разницу между компьютерами и информационными системами. Компьютеры, оснащенные специализированными программными средствами, являются технической базой и инструментом для информационных систем. Информационная система немыслима без персонала, взаимодействующего с компьютерами и телекоммуникациями. Развитие информационных систем можно рассматривать: 1. С позиций развития самой техники, появления новой технической базы, порождающей новые информационные потребности. 2. С точки зрения совершенствования самих автоматизированных информационных систем (АИС). Первый аспект предполагает два этапа: один — до появления ЭВМ, связанный с именами изобретателей первых вычислительных устройств, таких как Б. Паскаль, П.Л. Чебышев, Ч. Беббидж и др.; второй — с развитием ЭВМ. Первое поколение ЭВМ (1950-е гг.) было построено на базе электронных ламп и представлено моделями: ЭНИАК, «МЭСМ», «БЭСМ-1», «М-20», «Урал-1», «Минск-1». Все эти машины имели большие размеры, потребляли большое количество электроэнергии, имели малое быстродействие, малый объем памяти и невысокую надежность. В экономических расчетах они не использовались. Второе поколение ЭВМ (1960-е гг.) было на основе полупроводников и транзисторов: «БЭСМ-6», «Урал-14», «Минск-32». Использование транзисторных элементов в качестве элементной базы позволило сократить потребление электроэнергии, уменьшить размеры отдельных элементов ЭВМ и всей машины, вырос объем памяти, появились первые дисплеи и др. Эти ЭВМ уже использовались для решения экономических задач. Третье поколение ЭВМ (1970-е гг.) было на малых интегральных схемах. Его представители — IBM 360 (США), ряд ЭВМ единой системы (ЕС ЭВМ), машины семейства малых с СМ I по СМ IV. С помощью интегральных схем удалось уменьшить размеры ЭВМ, повысить их надежность и быстродействие. Четвертое поколение ЭВМ (1980-е гг.) было на больших интегральных схемах (БИС) и было представлено IBM 370 (США), ЕС-1045, ЕС-1065 и пр. Они представляли собой ряд программно-совместимых машин на единой элементной базе, единой конструкторско-технической основе, с единой структурой, единой системой программного обеспечения, единым унифицированным набором универсальных устройств. Широкое распространение получили персональные (ПЭВМ), которые начали появляться с 1976 г. в США (An Apple). Они не требовали специальных помещений, установки систем программирования, использовали языки высокого уровня и общались с пользователем в диалоговом режиме. В настоящее время, в период информатизации, строятся ЭВМ на основе сверхбольших интегральных схем (СБИС). Они обладают огромными вычислительными мощностями и имеют относительно низкую стоимость. Их можно представить не как одну машину, а как вычислительную систему, связывающую ядро системы, которое представлено в виде супер-ЭВМ, и ПЭВМ на периферии. Это позволяет существенно сократить затраты человеческого труда и эффективно использовать труд машины. Главной тенденцией развития АИС является постоянное стремление к улучшению. Оно достигается благодаря совершенствованию технических и программных средств, что порождает новые информационные потребности и ведет к совершенствованию информационных систем. Охарактеризуем поколения информационных систем. 1. Первое поколение АИС (1960-1970 гг.) строилось на базе вычислительных центров по принципу «одно предприятие — один центр обработки». 2. Второе поколение АИС (1970-1980 гг.) характеризуется переходом к децентрализации ИС. Информационные технологии проникают в отделы, службы предприятия. Появились пакеты и децентрализованные базы данных, стали внедряться двух, трехуровневые модели организации систем обработки данных. 3. Третье поколение АИС (1980-нач.1990 гг.): характерен массовый переход к распределенной сетевой обработке на базе персональных компьютеров с объединением разрозненных рабочих мест в единую ИС. 4. Четвертое поколение АИС характеризуется сочетанием централизованной обработки на верхнем уровне с распределенной обработкой на нижнем. Наблюдается тенденция к возврату на крупных и средних предприятиях к использованию в ИС мощных ЭВМ в качестве центрального узла системы и дешевых сетевых терминалов (рабочих станций). 5. Современные информационные системы на предприятиях создаются на основе локальных и распределенных сетей ЭВМ, новых технологий принятия управленческих решений, новых методов решения профессиональных задач конечных пользователей и т.д. 4.2. Задачи для практических занятий контрольной работы Задача выполняется в среде MS Access и включает следующие этапы: проектирование базы данных: определение вида и состава таблиц базы данных – таблицы Студенты и Экзамены; заполнение таблиц данными (табл. 4 и 5); выбор дополнительных полей для таблицы Студенты (табл. 2), соответствующих варианту контрольной работы (табл. 3) и заполнение их данными; установление связей между таблицами базы данных; формирование по каждому варианту трех различных видов запросов: 2 запроса на выборку с условием по нескольким полям и один запрос с вычисляемым полем; создание отчета с помощью Мастера отчётов; модификация отчета средствами Конструктора отчетов. При проектировании базы данных необходимо выбрать из таблицы 2 перечень дополнительных показателей, в соответствии с номером задачи. Например, задаче 1 соответствуют дополнительные показатели: 11, 12,13. Таблица 2 Перечень дополнительных полей для таблицы Студенты
Распределение показателей в соответствии с номером задачи приведено в таблице 3. Таблица 3
Решение: 1. В качестве примера рассмотрим базу данных, состоящую из двух таблиц: Студенты и Экзамены. - Для формирования таблицы Студенты используются следующие показатели: Фамилия Имя Отчество Семейное положение Количество детей Шифр Дата рождения Пол Факультет Направление Группа Квалификация Адрес Ин яз Стипендия Воинское звание - Для формирования таблицы Экзамены используются следующие показатели: Шифр обучающийся Дисциплина Дата сдачи экзамена Оценка 2. Установим связи между таблицами: Таблица «Студенты» включает в себя следующие поля (рис. 1): 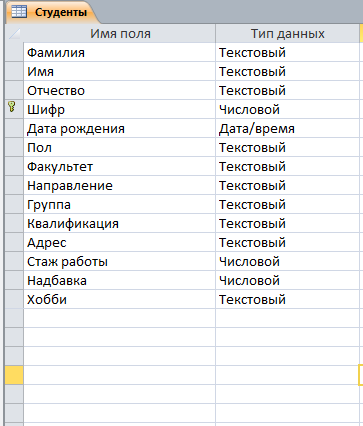 Рис. 1. Таблица «Студенты» Таблица «Экзамены» включает в себя следующие поля (рис. 2): 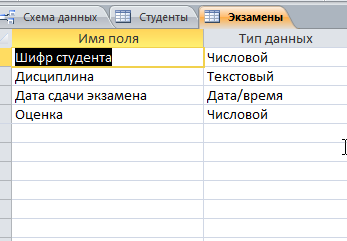 Рис. 2. Таблица «Экзамены» Между таблицами установим связи, в соответствии с рис. 3. 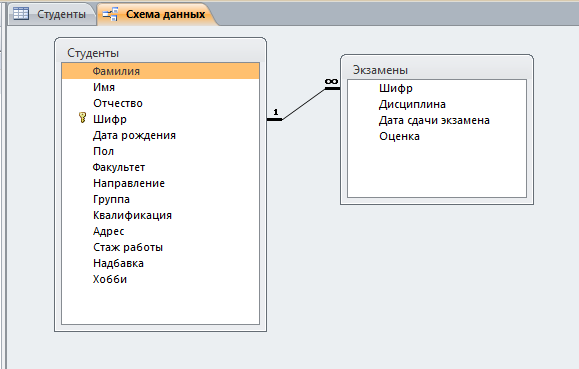 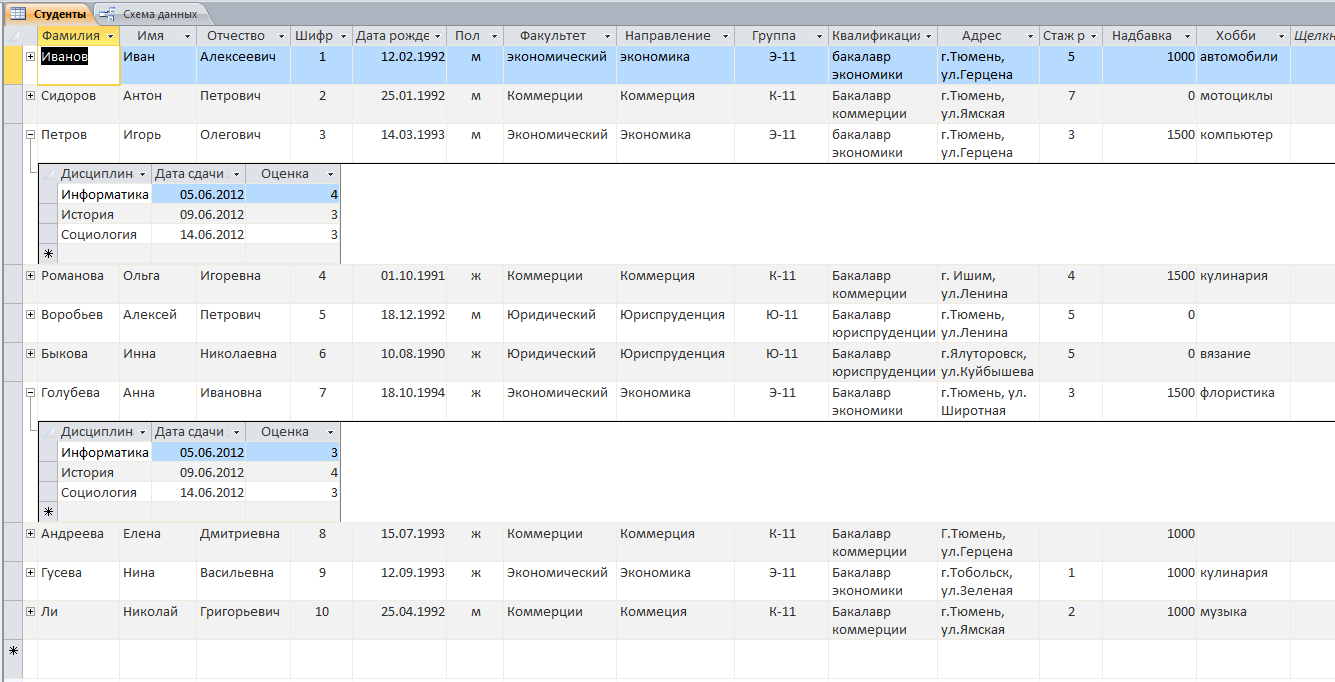 Рис. 3. Схема связей между таблицами «Студенты» и «Экзамены» 3. Заносим данные в созданные таблицы (см. табл. 4, 5). Таблица 4. 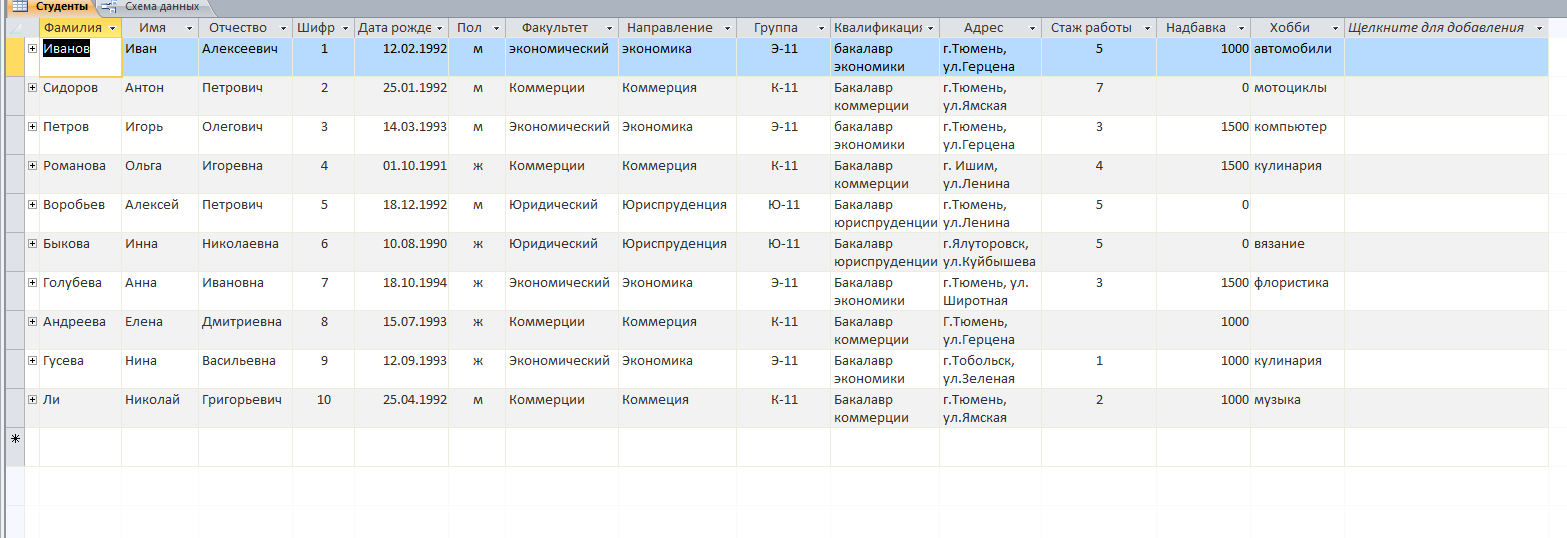 Таблица 5. Таблица 5.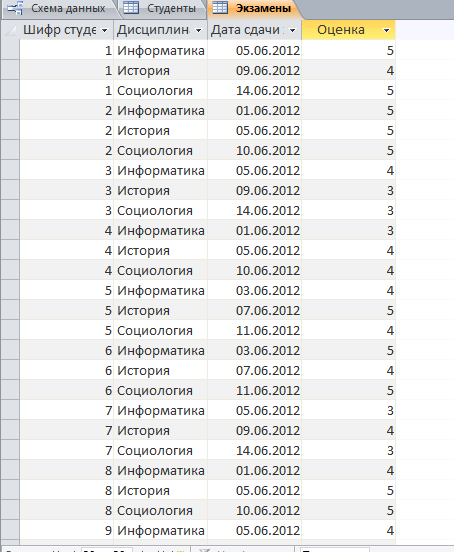 4. Сформируем 3 запроса: получить список студентов факультета юридического, сдавших социологию на 5; получить список студентов группы К-11, у которых день рождения летом. получить список студентов – женщин, изучающих Английский язык. Запрос 1 С помощью Конструктора запросов сформируем запрос на выборку (рис.6), извлекающий из таблиц созданной базы данных фамилии обучающихся, обучающихся на экономическом факультете. Для этого используем поля «Фамилия», «Имя», «Отчество» и «Факультет» из таблицы Студенты и поля «Дисциплина» и «Оценка» из таблицы Экзамены. В строку Условия отбора для поля «Факультет» введем условие «Юридический», для поля «Оценка» введем условие «>4», а для поля «Дисциплина» условие «Социология». В результате выполнения запроса будет получена таблица. 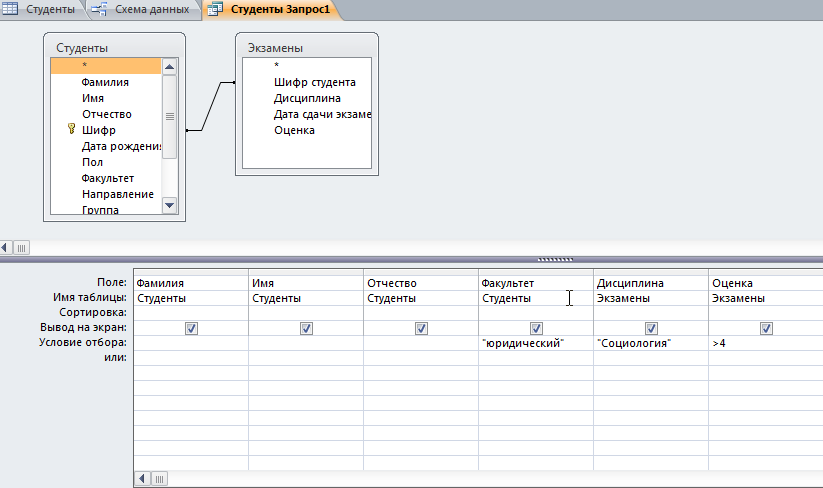 Рис. 5. Конструктор запроса на выборку обучающихся юридического факультета, сдавших социологию на 3 В результате выполнения запроса будет получена таблица, представленная на рис. 6. 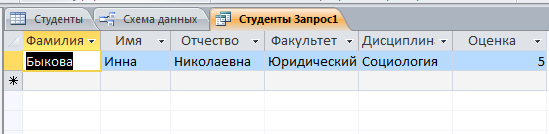 Рис. 6. Выборка по запросу 1 Запрос 2 (рис. 7), извлекающий из базы данных фамилии студентов, у которых день рождения летом. В запрос на выборку включаем поля «Фамилия», «Имя», «Отчество» и «Дата рождения» из таблицы «Студенты». В бланке запроса С помощью Конструктора запросов сформируем запрос на выборку с помощью Построителя выражений создаем вычисляемое поле: Выражение 1: = Month([Студенты]![Дата рождения]), Заменив «Выражение 1» на «Месяц рождения», получим: Месяц рождения: Month([Студенты]![Дата рождения]) В строке Условие отбора для вычисляемого поля зададим условие отбора Between 3 and 5. 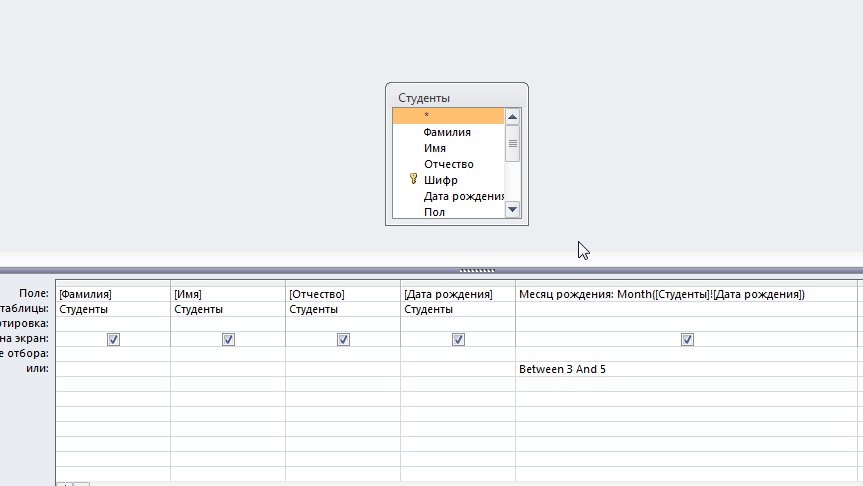 Рис. 7. Конструктор запроса на выборку обучающихся, у которых день рождения весной В результате выполнения запроса будет получена таблица, представленная на рис. 8. 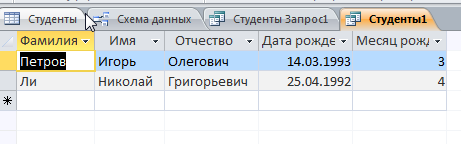 Рис. 8. Выборка по запросу 2 Запрос 3 С помощью Конструктора запросов сформируем запрос на выборку (рис. 9), извлекающий из созданной базы данных фамилии студентов-девушек, получающих стипендию. 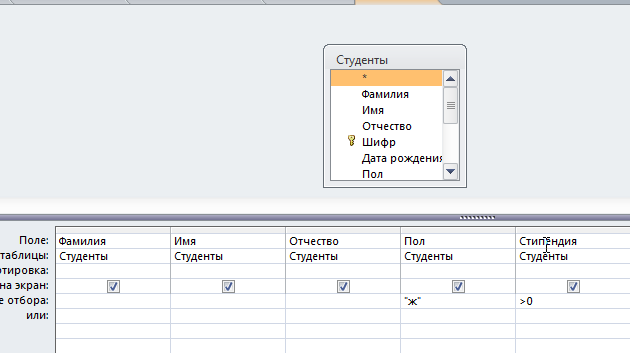 Рис. 9. Конструктор запроса на выборку студентов-девушек, получающих стипендию Для выполнения запроса используем поля «Фамилия», «Имя», «Пол» и «Группа» из таблицы Студенты. В строку «Условия отбора» поля Пол студентавведем значение «Ж», а в строку «Условия отбора» поля Стипендия введем значение «>0». В результате выполнения запроса будет получена таблица, представленная на рис. 10. 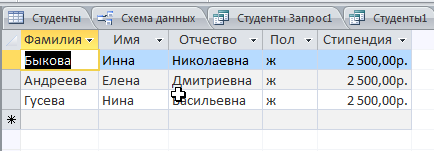 Рис.10. Выборка по запросу 3 5. Создание отчетов С помощью Мастера отчетов в пошаговом режимесоздадим отчет «Результаты сдачи экзаменов»: формируем список необходимых полей; выбираем вид представления данных по таблице Экзамены; добавляем уровень группировки отчета по полю Дисциплина; при необходимости указываем наличие сортировки по какому-либо полю; вид макета для отчета выбираем структура. В созданный отчет внесем изменения в режиме Конструктора отчетов (рис. 11): 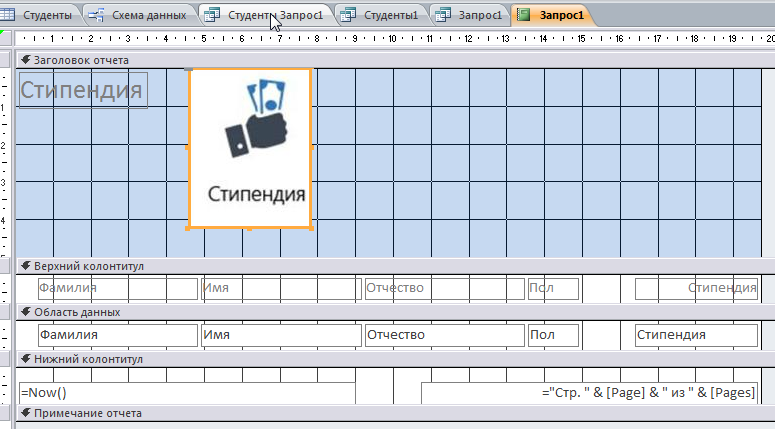 Рис. 11. Вид отчета в режиме Конструктора В результате выполнения указанных действий получим отчет следующего вида (рис. 12). 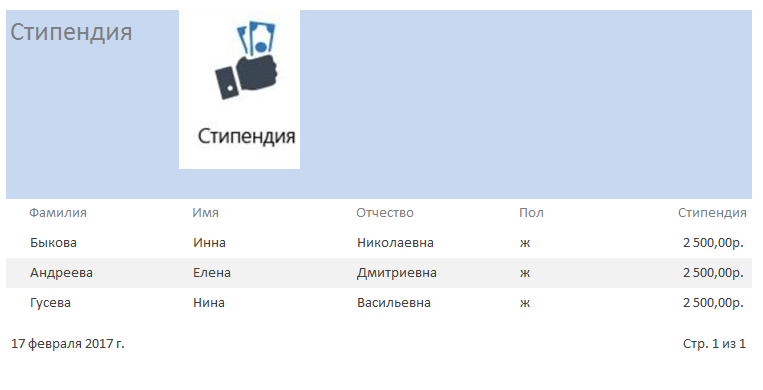 Рис. 12. Отчет «Результаты сдачи экзаменов» в режиме предварительного просмотра СПИСОК ЛИТЕРАТУРЫ 1. ВАРФОЛОМЕЕВА АЛЕСАНДРА ОЛЕГОВНА. Информационные системы предприятия : учебное пособие для вузов / ВАРФОЛОМЕЕВА АЛЕСАНДРА ОЛЕГОВНА, А. В. Коряковский, В. П. Романов. - 2-е изд., перераб.и доп. - М. : Инфра-М, 2017. - 330с. : ил. - (Высшее образование: Бакалавриат). - Библиогр.:с.322-325. - ISBN 978-5-16-012274-8. 2. Информационные системы в экономике: Учебник / Балдин К.В., Уткин В.Б., - 7-е изд. - М.: Дашков и К, 2017. - 395 с.: 60x84 1/16 ISBN 978-5-394-01449-9. - Режим доступа: http://znanium.com/go.php?id= 3. Шустова Л.И. Базы данных : учебник / Л.И. Шустова, О.В. Тараканов. — М. : ИНФРА-М, 2017. — 304 с. + Доп. материалы [Электронный ресурс; - Режим доступа: http://www.znanium.com]. — (Высшее образование: Бакалавриат). — www.dx.doi.org/10.12737/11549. 4. Информационные системы в экономике / Титоренко Г.А., - 2-е изд. - М.:ЮНИТИ-ДАНА, 2015. - 463 с.: ISBN 978-5-238-01167-7. - Режим доступа: http://znanium.com/go.php?id=872661 5. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2016. - 283 с.: 60x90 1/16. – (Высшее образование: Бакалавриат) (Переплёт 7БЦ) ISBN 978-5-16-005549-7. - Режим доступа: http://znanium.com/go.php?id=536732 6. КОРПОРАТИВНЫЕ информационные системы управления : учебник для вузов / под науч. ред. Н.М. Абдикеева, О.В. Китовой. - М. : Инфра-М, 2015. - 464с. : ил. - (Высшее образование: Магистратура). - Библиогр. в конце глав. - ISBN 978-5-16-010922-1. 7. СИСТЕМА управления базами данных MS ACCESS : практикум / сост.: Т.А. Брякотнина, Ю.В. Ярославцева; ЧОУ ВО Центросоюза РФ СибУПК. - Новосибирск, 2016. - 64с. 8. Информационные технологии финансовой системы. Электронный ресурс: https://studopedia.su/10_153648_informatsionnie-tehnologii-finansovoy-sistemi.html 9. Нетесова О.Ю. ИНФОРМАЦИОННЫЕ СИСТЕМЫ И ТЕХНОЛОГИИ В ЭКОНОМИКЕ. Электронный ресурс: https://studme.org/212063/informatika/informatsionnye_sistemy_i_tehnologii_v_ekonomike 10. Информационные ресурсы сети Интернет. Электронный ресурс: http://infofi | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||