Базы данных и системы управления базами данных. Глава 4, часть 1_р. 4. Базы данных и системы управления базами данных Базы данных в структуре информационных систем
 Скачать 6.18 Mb. Скачать 6.18 Mb.
|

4. Базы данных и системы управления базами данных4.1. Базы данных в структуре информационных системОдно из важнейших направлений, связанных с использованием вычислительной техники, служит для создания, хранения и обработки больших массивов данных. Программные продукты этого направления — информационные системы. Информационная система представляет собой аппаратно-программный комплекс, обеспечивающий выполнение следующих функций: ввод данных об объектах некоторой предметной области; хранение и защита данных во внешней памяти вычислительной системы; дополнение, удаление, изменение, сортировка и выборка введенных данных; обобщение данных и составление нужных отчетов с предоставлением пользователю удобного интерфейса. Одной из особенностей информационных систем является то, что объем данных может измеряться миллиардами байт. Поэтому в такой системе данные обязательно должны быть структурированы, чтобы из всего многообразия данных удобно было выбирать только некоторые из них, отвечающие определенным критериям. Совокупность взаимосвязанных данных называется структурой данных. Если эта структурированная совокупность данных относится к одной предметной области, то говорят о базе данных (БД). Исторически понятие база данных сложилась как альтернатива файловой организации данных при хранении их на ЭВМ. Понятие базы данных возникло в результате стандартизации и унификации данных, хранящихся на ЭВМ с целью использования для других приложений. При этом описание данных уже не скрыто в обслуживающих их программах, а явным образом декларируется и хранится в самой базе. Итак, база данных — это реализованная с помощью компьютера информационная структура (модель), отражающая состояние данных и их отношения между собой. Опыт использования баз данных позволяет выделить общий набор их рабочих характеристик: полнота — чем полнее база данных, тем вероятнее, что она содержит нужную информацию; правильная организация — чем лучше структурирована база данных, тем легче в ней найти необходимые сведения; актуальность — база должна постоянно обновляться, т. е. в каждый момент соответствовать состоянию отражаемого ею объекта; удобство для использования — база данных должна быть проста и удобна и иметь развитые методы доступа к любой части информации. Как любой программный продукт, БД обладает собственным жизненным циклом, который в свою очередь определяет жизненный цикл всей информационной системы. Жизненный цикл включает в себя следующие основные этапы: планирование разработки БД; определение требований к системе; сбор и анализ требований пользователей; проектирование базы данных: концептуальное проектирование БД; логическое проектирование БД; физическое проектирование БД; разработка приложений; реализация; загрузка данных и тестирование; эксплуатация и сопровождение. В современной технологии баз данных предполагается, что создание баз данных, их поддержка и обеспечение доступа пользователей к базам осуществляется централизованно с помощью специального программного инструментария — систем управления базами данных (СУБД). СУБД — это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации. 4.2. Классификация баз данных и виды моделей данныхПо технологии обработки данных базы подразделяются на централизованные и распределенные. Централизованная база данных хранится в памяти одной вычислительной системы (машины). Такой способ использования часто применяется в локальных сетях. Распределенная база состоит из нескольких, возможно пересекающихся и даже дублирующих друг друга частей, хранимых в различных ЭВМ сети. По способу доступа базы разделяются на базы данных с локальным доступом и базы данных с сетевым (удаленным) доступом. При разработке БД на этапе концептуального проектирования подробно рассматривается предметная область, данные, их свойства и связи между ними. При этом применяются две методологии моделирования: семантическая и объектно-ориентированная. При семантическом моделировании главное внимание уделяется структуре данных, объектно-ориентированный подход нацелен на описание поведения объектов данных и способах манипулирования с ними. Сближение этих двух подходов привело к понятию объектно-ориентированных баз данных. Большинство существующих БД используют понятия и идеи объектно-ориентированных БД. Предметная область баз данных рассматривается как объектная система и имеет следующие составляющие: объект; средство; время; связь. Объект — это то, о чем накапливается информация в БД и что может быть однозначно идентифицировано. Объекты могут быть атомарными и составными. Для составного объекта определяется его внутренняя структура. Каждый объект в текущий момент времени взаимодействует с другими объектами определенным набором средств и связей. Атрибут — это поименованная характеристика объекта, с помощью которой моделируется какое-то свойство объекта. Каждый объект имеет свои атрибуты, которые могут быть простыми и составными. Простые атрибуты не могут быть разделены на более мелкие компоненты, а остальные могут. Атрибуты, с помощью которых можно идентифицировать экземпляр объекта, называются ключами. В качестве ключей иногда можно использовать несколько атрибутов, один из которых выбирается в качестве первичного ключа. Идентификацию некоторых объектов приходится осуществлять с помощью составных ключей, которые включают несколько атрибутов. Объекты могут быть связаны между собой. Существует несколько типов связей, для характеристик которых, так же как и для объектов, можно использовать атрибуты. Структурными элементами наиболее распространенных баз данных являются поля, записи и файлы. Полем называется элементарная единица логической организации данных, которая имеет имя, тип, длину, точность и соответствует неделимой единице информации — реквизиту. Запись — совокупность логически связанных полей. Файлом называется совокупность экземпляров записей одной структуры (рис. 4.1). Другими словами файл — это чаще всего таблица, поле — столбец, а запись — строка этой таблицы. 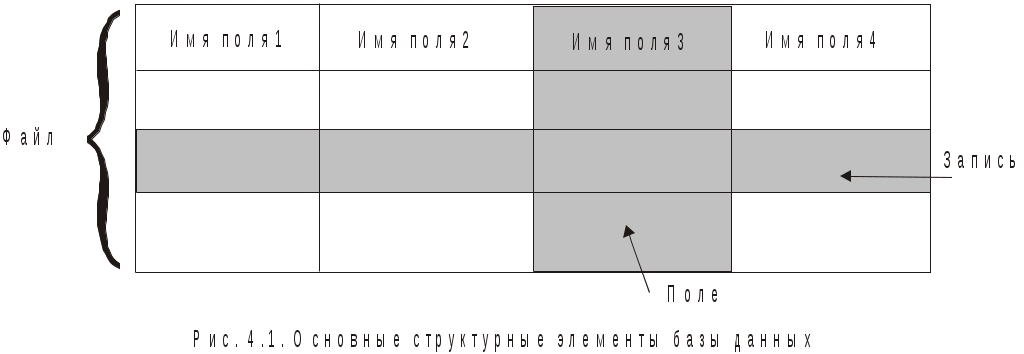 Рис. 4.1. Основные структурные единицы базы данных Основой СУБД являются два языка — язык описания данных (ЯОД) и язык манипулирования данными (ЯМД). С помощью языка описания данных программисты описывают структуру и содержимое базы данных. Язык манипулирования данными является средством, которое применяется пользователями для выполнения операций над данными, хранящимися в базе. В основе любой базы данных лежит модель данных, т. е. их информационная структура. Модель базы данных — это множество структур данных и операций манипулирования с этими структурами. Если БД не содержит никаких внешних данных, в ней все равно имеется информация. Эта информация — структура самой базы. Структура определяет методы занесения данных и хранения их в базе. Итак, модель данных — это некоторая абстракция, в которой отражаются самые важные аспекты функционирования выделенной предметной области. Описано много разнообразных моделей, используемых в базах данных. Все их можно разделить на три категории: объектные модели данных; модели данных на основе записей; физические модели данных. Наибольшее распространение получили модели данных на основе записей. В них БД состоит из нескольких записей фиксированного формата и разных типов. Информационные модели данных на основе записей подразделяются на: теоретико-графовые (ТГ): иерархические модели; сетевые модели; теоретико-множественные (ТМ): реляционные модели. В теоретико-графовых моделях предусматривается одновременная обработка только одиночных объектов данных из БД. Доступ к БД поддерживается созданием соответствующих прикладных программ с собственным интерфейсом. Механизмы доступа к данным и навигации по структуре данных в таких моделях достаточно сложны, особенно в сетевой модели. Теоретико-множественные модели используют математический аппарат реляционной алгебры (знаковой обработки множеств). Данные в таких БД представлены в виде совокупностей таблиц, над которыми могут выполняться операции, сформулированные в терминах реляционной алгебры. В иерархической БД существует упорядоченность элементов в записи. Объекты, связанные иерархическими отношениями, образуют ориентированный граф — дерево. Для этой структуры характерна подчиненность объектов нижнего уровня объектам верхнего уровня (рис. 4.2). Иерархическую базу данных образует, например, каталог файлов, хранимых на диске, а дерево каталогов — наглядная демонстрация ее структуры. Первые системы управления базами данных использовали иерархическую модель данных. Самой известной СУБД, использующей модель данных этого типа, является система фирмы IBM — Information Management System (IMS), первая версия которой появилась в 1968 году. 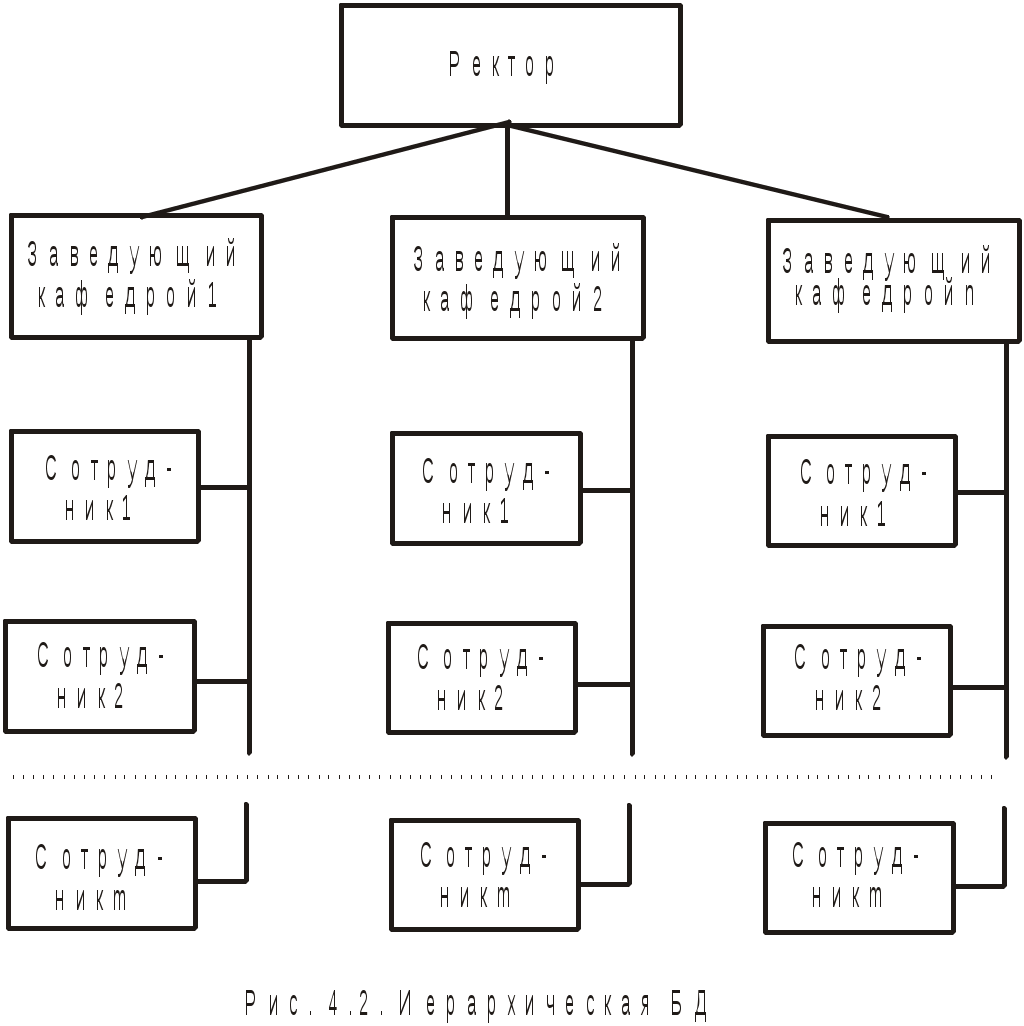 Рис. 4.2. Иерархическая БД Основными информационными единицами в иерархической системе данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Сегмент образуется из значений полей данных. В иерархической модели вершине графа-дерева соответствует сегмент, а дугам — типы связей "предок-потомок". Каждый сегмент-потомок должен иметь в точности одного предка. В целом иерархическая БД состоит из упорядоченного набора нескольких экземпляров одного типа дерева. При этом граф-дерево обладает следующими свойствами: имеется только одна вершина графа — корень, в которую не заходит ни одно ребро; в вершины единственный проход к порожденной вершине лежит через ее исходную вершину; каждый потомок имеет только одного предка; нет замкнутых петель и циклов; сегмент, у которого нет потомков, называется листовым сегментом. При работе с древовидной структурой используются два метода доступа ко всем вершинам внутри дерева: прямой порядок обхода дерева (от корня с нисходящим обходом поддеревьев до нужного уровня) и обратный порядок обхода дерева ( от 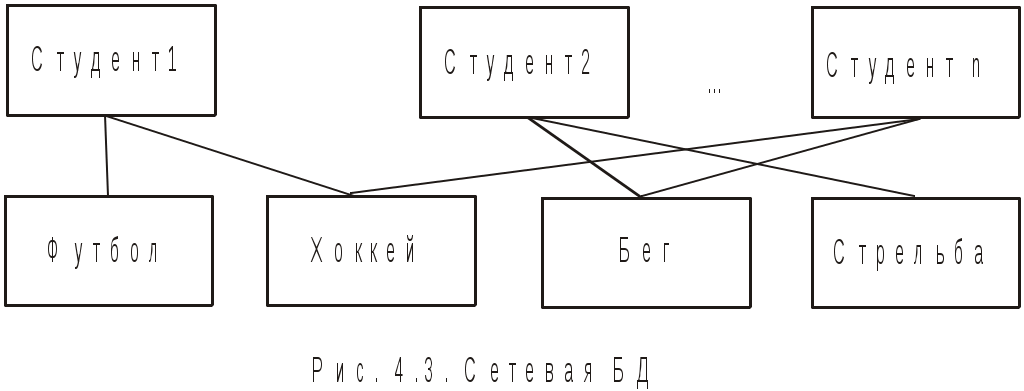 Рис. 4.3. Сетевая БД Сетевая БД отличается большей гибкостью, т. к. в ней существует возможность дополнительно к вертикальным иерархическим связям добавить горизонтальные связи. Сетевая структура представляет собой произвольный граф, здесь каждый элемент может быть связан с любым другим элементом (рис. 4.3). Произвольный граф состоит из вершин (узлов), соединенных ребрами. В сетевой модели узлы представляют собой объекты в виде типов записей данных, а ребра — связи между объектами. Основное отличие графовых форм представления данных в сетевой структуре от данных в иерархической структуре состоит в том, что потомок в графе может иметь любое число предков. Типичным представителем СУБД, использующих сетевую модель данных, является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах фирмы IBM.  Рис. 4.4. Основные структуры сетевой модели данных Основными типами структур данных в сетевых моделях являются элементы данных, агрегаты данных, записи и наборы (рис. 4.4). Элемент данных — это наименьшая поименованная информационная единица данных, доступная пользователю. Следующему уровню обобщения соответствует агрегат данных — поименованная совокупность элементов данных внутри записи или другого агрегата. Запись — конечный уровень композиции элементов данных. Каждая запись представляет собой именованную структуру, содержащую один или более элементов данных. Тип записи — это совокупность логически связанных экземпляров записей. Тип записей моделирует некоторый класс объектов реального мира. Наконец, набор — это поименованная двухуровневая иерархическая структура, содержащая запись владельца и записи членов. Наборы выражают связи между типами записей. Сетевой граф БД устроен значительно сложнее иерархического и имеет следующие свойства: БД может содержать любое количество наборов и записей; между двумя типами записей может быть любое количество наборов; тип записи может быть владельцем в одних типах наборов и членом в других типах наборов, а может и не быть членом какого-то типа набора; только один тип записи может быть владельцем в каждом наборе; типы наборов могут образовывать циклическую структуру; один и тот же тип записи может быть владельцем нескольких типов наборов и одновременно может быть членом нескольких типов наборов. Недостатком сетевой модели является сложность ее реализации. Реляционными (от англ. relation) являются БД, содержащие информацию, организованную в виде прямоугольных таблиц. Реляционные БД характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений. Создатель реляционной модели — сотрудник фирмы IBM Э. Ф. Кодд1. Одним из основных преимуществ реляционной модели является еёе однородность. Все данные рассматриваются как хранимые в таблицах и только в таблицах. Каждая строка такой таблицы имеет один и тот же формат. В настоящее время реляционный подход к построению бахз данных наиболее распространёен. Этот подход имеет следующие достоинства: использование сравнительно небольшого набора абстракций, позволяющих моделировать большинство предметных областей; наличие простого математического аппарата, опирающегося на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода; возможность навигации по БД без знания конкретной физической организации данных на внешних носителях. Основные теоретические результаты реляционного подхода были получены в 70-е годы XX столетия. Большой вклад в развитие реляционной алгебры и нормализации отношений внес Э. Ф. Кодд. В частности в статье, опубликованной в журнале "Computer Word" он сформулировал двенадцать правил, которым должна соответствовать настоящая реляционная база данных. Реляционные системы не сразу получили широкое распространение. Даже сейчас не существует такой реляционной БД, в которой поддерживались бы все до единой возможности реляционной технологии. К настоящему времени основными недостатками реляционной технологии являются: ограниченность реляционных БД при использовании, например, в системах автоматического проектирования (САПР), в которых используются очень сложные структуры; ограниченные возможности адекватного отражения семантики предметной области. Итак, реляционная БД — это конечный набор отношений. Отношения используются для представления объектов и для представления связей между объектами. Каждое отношение — это двумерная таблица, состоящая из строк и столбцов, причем строки соответствуют записям, а столбцы атрибутам. Атрибут — это поименованный столбец отношения. Свойства объекта, его характеристики определяются значениями атрибутов. Хотя понятия "отношение" и "таблица" иногда рассматриваются как синонимы, их следует различать: отношением является не любая таблица, а лишь таблица, обладающая определенными свойствами. Будем в последующем изложении употреблять термин "таблица" с учетом этого замечания. Каждая реляционная таблица, представляя двумерный массив (см. рис. 4.1), обладает следующими свойствами: каждый элемент таблицы — один элемент данных; все столбцы однородны, т. е. все элементы в столбце имеют одинаковый тип и длину; каждый столбец имеет уникальное имя; одинаковые строки в таблице отсутствуют; порядок следования строк и столбцов произвольный. Рассмотрим основные свойства полей БД и используемые типы данных на примере реляционной СУБД Microsoft Access. В ней все поля имеют следующие основные свойства: имя поля — определяет обращение к данным этого поля, используется в качестве заголовков столбцов таблиц; тип поля — определяет тип данных, содержащихся в данном поле; размер поля — задает предельную длину поля (в символах); формат поля — определяет способ форматирования данных в адресах памяти, принадлежащих полю; значение по умолчанию — это значение вводится в адреса поля автоматически и является средством автоматизации вода данных; условие на значение — ограничение, используемое для проверки правильности ввода данных; сообщение об ошибке — текстовое сообщение, выдаваемое при попытке ввода в поле ошибочных данных; обязательное поле — свойство, определяющее обязательность заполнения данных этого поля; индексированное поле — свойство, ускоряющее операции по поиску и сортировке записей и проверяющее записи на наличие дублирования данных. Так как в разных полях могут храниться данные разного типа, то свойства полей зависят от типа хранимых данных. Таблицы баз данных допускают работу с большим количеством разных типов данных по сравнению с другими программами стандартных Windows-приложений. Основные типы данных, используемые в Microsoft Access следующие: текстовый — тип, используемый для хранения текста длиной до 255 символов; поле MEMO — специальный тип для хранения больших объемов текста (до 65 535 символов). Физически такой текст хранится не в поле, а в другом месте базы данных, в поле же хранится лишь указатель на этот текст; числовой — тип для хранения действительных чисел; дата/время — тип данных для хранения календарных дат и текущего времени; денежный — тип для хранения денежных сумм. Данные этого типа имеют некоторые особенности по сравнению с действительными числами и хранятся отдельно; счетчик — специальный тип данных для натуральных чисел с автоматическим наращиванием. Используется для порядковой нумерации записей; логический — тип для хранения логических величин; поле объекта OLE — специальный тип данных, предназначенный для хранения мультимедийных объектов. Эти объекты, как и объекты полей MEMO, хранятся в специальном месте БД, а в поле объекта OLE хранится лишь ссылка на этот адрес; гиперссылка — специальное поле для хранения адресов Web-объектов Интернета. При щелчке на ссылке происходит запуск браузера и воспроизведение объекта в его окне. Во всех базах данных реализован особый способ сохранения данных, отличный от способа сохранения данных в файловых системах. В части операций, как обычно, участвует операционная система компьютера, но некоторые операции сохранения происходят в обход операционной системы. Операции изменения структуры базы данных, создание новых таблиц или иных объектов происходят при сохранении файла базы данных, т. е. об этих операциях СУБД предупреждает пользователя. С другой стороны, операции по изменению содержания данных, не затрагивающие структуру базы, выполняются автоматически и без предупреждения. Все изменения, вносимые в таблицы базы, сохраняются на диске без нашего ведома, т. е. происходит работа с жестким диском напрямую, вне операционной системы. 4.3. Нормализация отношений в реляционных базах данныхОтношения в реляционной базе данных представлены в виде таблиц, строки которых соответствуют записям, а столбцы — атрибутам отношений — полям. Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. Чтобы связать две реляционные таблицы, необходимо ключ первой ввести в состав ключа второй таблицы. 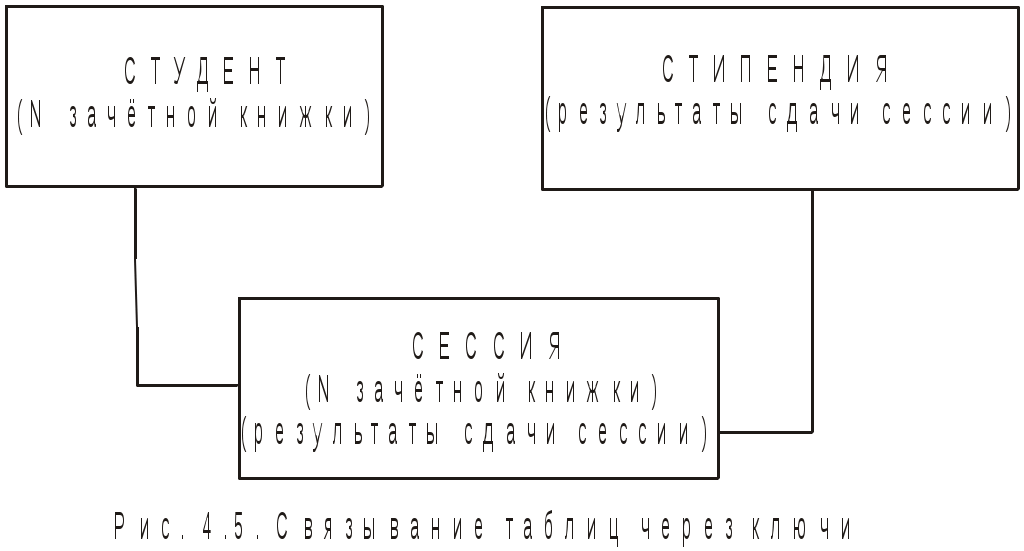 Рис. 4.5. Связывание таблиц через ключи Например, рассмотрим БД, состоящую из трех связанных таблиц: СТУДЕНТ(номер зачетной книжки, Ф., И., О., дата рождения, группа), СЕССИЯ(номер зачетной книжки, оценка1, оценка2,…, оценка n, результаты сдачи сессии), СТИПЕНДИЯ(результаты сдачи сессии, размер стипендии). Отношения СТУДЕНТ и СЕССИЯ имеют совпадающие ключи (номер зачетной книжки). Таблица СЕССИЯ имеет первичный ключ номер зачетной книжки и содержит внешний ключ результаты сдачи сессии, который обеспечивает ее связь с таблицей СТИПЕНДИЯ (рис. 4.5). В реляционных базах данных определены три типа связей: один к одному (1:1) — любая запись в первой таблице может быть связана только с одной записью второй таблицы и наоборот; один ко многим (1:М) — любая запись первой таблицы связана с несколькими записями второй, но любая запись во второй таблице связана только с одной записью первой таблицы; многие ко многим (М:М) — каждой записи первой таблицы соответствуют несколько записей второй и наоборот. В явном виде эта связь в реляционных БД не поддерживается, но имеются способы ее косвенной организации путем создания дополнительных таблиц. Одни и те же данные могут группироваться в таблицы различными способами, т. е. возможна организация различных наборов отношений взаимосвязанных информационных объектов. Группировка атрибутов (столбцов) в отношениях (таблицах) должна быть рациональной, их дублирование минимизировано. В реляционных базах данных отношения (таблицы) содержат как структурную, так и семантическую информацию. Структурная информация связана с объявлением отношений. Семантическая информация выражается множеством известных функциональных зависимостей между атрибутами отношений, имеющимися в схеме. Таким образом, в отношениях (таблицах) практически всегда присутствуют функциональные зависимости. Для устранения нежелательных функциональных зависимостей между атрибутами (столбцами) Э. Кодд предложил использовать разработанный им процесс нормализации отношений. Это процедура декомпозиции (разложения), при которой данное множество отношений заменяется другим множеством отношений (при этом число их возрастает), являющихся проекциями первых. Другими словами, нормализация — это пошаговый обратимый процесс замены данной схемы отношений другой схемой, в которой отношения имеют более простую и регулярную структуру. Итак, нормализация отношений — формальный аппарат ограничений на формирование таблиц, который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение БД. Различают шесть нормальных форм: 1НФ — первую нормальную форму; 2НФ — вторую нормальную форму; 3НФ — третью нормальную форму; НФБК — нормальную форму Бойса-Кодда; 4НФ — четвертую нормальную форму; 5НФ — пятую нормальную форму. Каждая нормальная форма определяет ограничения на данные: 1НФ, 2НФ, 3НФ — ограничивают зависимость не первичных атрибутов от ключей; НФБК — ограничивает зависимость первичных атрибутов; 4НФ — формирует ограничения на виды многозначных зависимостей; 5НФ — вводит другие типы зависимостей: зависимости соединения. Каждая нормальная форма более высокого уровня предполагает, что анализируемое отношение уже находится в нормальной форме на уровне ниже рассматриваемого. Для реляционных баз данных необходимо, чтобы все отношения базы данных обязательно находились в 1НФ, однако практически всегда стремятся довести уровень нормализации базы данных хотя бы до 3НФ. Отношение называется нормализованным или приведенным к первой нормальной форме, если все его атрибуты простые, т. е. неделимы. В противном случае отношение считается ненормализованным и ему соответствует многоуровневая таблица (иерархия) в отличие от однородной табличной структуры нормализованного отношения. Преобразование отношений к первой нормальной форме может привести к увеличению количества реквизитов (полей) отношения и изменению ключа. Например, отношение СТУДЕНТ(номер зачетной книжки, Ф., И., О., дата рождения, группа) находится в первой нормальной форме. Если бы поля Ф., И., О. были бы объединены в одно, то нормализация отношений состояла бы в фрагментации данного поля. Разработчики БД изначально строят так исходные отношения, чтобы они были в первой нормальной форме. Один из распространенных подходов приведения к 1НФ заключается в том, что в процессе преобразований, которое называется выравниванием таблицы, повторяющиеся группы устраняются путем организации дополнительных записей по одной на каждый элемент повторяющейся группы. Вторая нормальная форма применяется к отношениям с составным ключом, т. е. к таким отношениям, первичный ключ которых состоит из двух или более атрибутов. Отношение, у которого первичный ключ включает только один атрибут, всегда находится во 2НФ. Для описания второй и третьей нормальных форм требуется ввести понятие о функциональной зависимости полей (атрибутов). Функциональная зависимость полей — это зависимость, при которой в экземпляре информационного объекта определенному значению ключевого поля соответствует только одно значение не ключевого поля. Таким образом, это логическая связь не ключевых полей с общим для них ключом. В случае составного ключа вводится понятие функционально полной зависимости. Функционально полная зависимость не ключевых полей заключается в том, что каждое не ключевое поле функционально зависит от ключа, но не зависит ни от какой части составного ключа. Отношение будет находится во второй нормальной форме, если оно находится в первой нормальной форме, и каждое не ключевое поле функционально полно зависит от составного ключа. Так отношение СТУДЕНТ находится во второй нормальной форме, т. к. его не ключевые поля функционально зависят от ключа номер зачетной книжки. Отношение СЕССИЯ, имеющее составной ключ номер зачетной книжки + результаты сдачи сессии находится в первой нормальной форме, но не находится во второй, т. к. поля оценка1, оценка2,…, оценка n не находятся в полной функциональной зависимости от составного ключа, а лишь от его составной части. Для перевода этого отношения во вторую нормальную форму необходимо исключить из него поля оценка1, оценка2,…, оценка n, т. е. исходное отношение надо разбить на два связанных отношения РЕЗУЛЬТАТЫ(номер зачетной книжки, оценка1, оценка2,…, оценка n) и СЕССИЯ(номер зачетной книжки, результаты сдачи сессии). Связь между ними будет осуществляться по полю номер зачетной книжки (рис. 4.6). 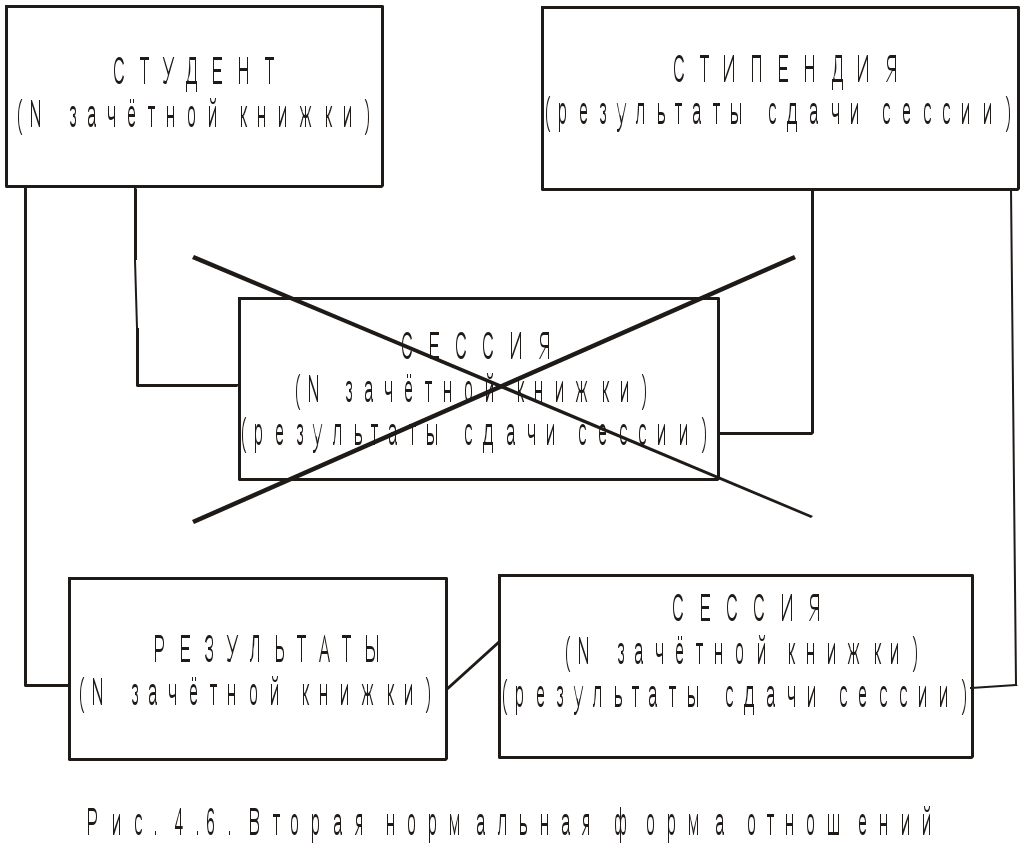 Рис. 4.6. Вторая нормальная форма отношений Понятие третьей нормальной формы связано с понятием транзитивной зависимости. Транзитивная зависимость наблюдается в том случае, если одно из двух описательных полей зависит от ключа, а другое описательное поле зависит от первого поля. 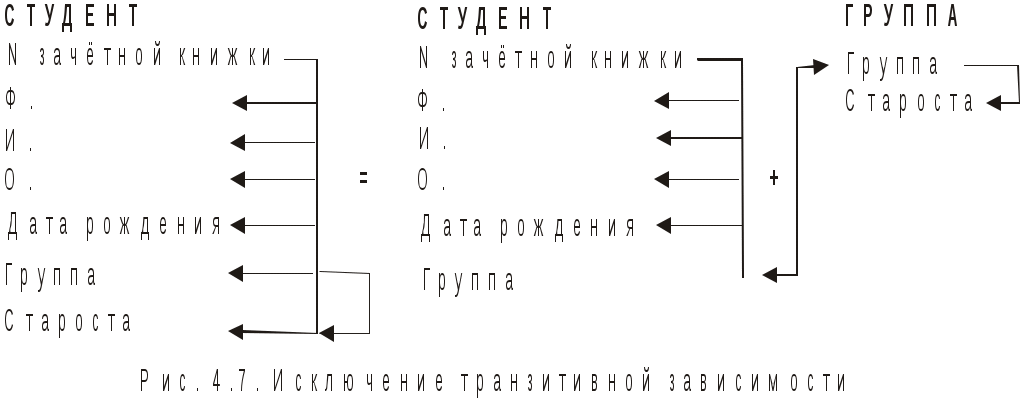 Рис. 4.7. Исключение транзитивной зависимости Отношение будет находиться в третьей нормальной форме, если оно находится во второй нормальной форме, и каждое не ключевое поле не транзитивно (т. е. напрямую) зависит от первичного ключа. Отношение СТУДЕНТ находится в третьей нормальной форме. Если в состав описательных полей этого информационного объекта добавить фамилию старосты группы — староста, то появится транзитивная зависимость не ключевого поля староста от ключа через не ключевое поле группа. Для устранения транзитивной зависимости описательных полей необходимо произвести "расщепление" исходного информационного объекта. В результате такого расщепления часть полей удаляется из исходного объекта и включается в состав других, новых информационных объектов: СТУДЕНТ(номер зачетной книжки, Ф., И., О., дата рождения, группа), ГРУППА(группа, староста) (рис. 4.7). 4.4. Проектирование баз данныхПроектирование баз данных достаточно сложный процесс, содержащий обычно следующие этапы: анализ предметной области; проектирование и кодирование БД; тестирование и сопровождение. Анализ предметной области выполняется разработчиком БД совместно с заказчиком. В этом анализе описываются информационные объекты, принимаются правила организации и кодировки данных. Описывается список исходных и выходных данных, оговаривается интерфейс. На этом этапе собранные данные анализируются на предмет устранения дублирования и противоречивости в данных, неоднозначности их определений и описаний, выявляются и формируются правила обработки информации и принятия решений. Результатом этого этапа являются: список всех создаваемых и используемых элементов данных; перечень прикладных задач, их характеристик и используемых в них данных; список принимаемых решений в управлении описанных процессов; список возможных текущих изменений в БД. Пользовательские модели представления данных должны быть интегрированы в концептуальную модель данных. Наиболее известными подходами концептуализации являются анализ сущностей и представление знаний. При создании концептуальной схемы БД применяются два подхода: "нисходящий" и "восходящий". Второй используется для проектирования простых БД с небольшим количеством атрибутов. В этом случае работа начинается с нижнего уровня — уровня определения атрибутов, которые затем группируются в отношения в соответствии с существующими между ними связями. Полученные отношения подвергаются нормализации, результатом этого процесса является создание нормализованных взаимосвязанных таблиц, основанных на функциональных зависимостях между атрибутами. Сложные базы данных проектируются по нисходящей технологии. Начинается этот процесс с разработки моделей данных, которые содержат несколько высокоуровневых сущностей и связей, затем выделяются и уточняются низкоуровневые сущности, связи и относящиеся к ним атрибуты. В последние годы мощным инструментом организации плохо структурированных знаний и построения концептуальных моделей сложных предметных областей стал системный анализ. В качестве основных принципов системного анализа при построении моделей используются: рассмотрение объекта с различных точек зрения, выявления аспектов изучаемого объекта с учетом их взаимосвязи; расчленение объекта на более простые подсистемы, т. к. каждая подсистема проще, чем вся система в целом; выделение иерархических отношений типа "целое-часть" между компонентами системы разных уровней и отношений эквивалентности между компонентами одного уровня. Принятая концептуальная модель должна удовлетворять таким критериям как: структурная достоверность, выразительность, отсутствие избыточности, расширяемость, целостность, способность к совместному использованию. Цель второй фазы проектирования базы данных состоит в создании логической модели данных. Логической моделью называют модель, отражающую особенности представления о функционировании объекта одновременно многих типов пользователей. При ее проектировании должна быть уже выбрана определенная модель данных (реляционная, сетевая, иерархическая). На этапе логического проектирования создаются следующие документы: набор подсхем БД; спецификации для физического проектирования приложений; руководства по разработке программ с интерфейсами пользователя и межпрограммными интерфейсами; руководства по сопровождению БД. На физическом уровне решаются вопросы размещения данных на внешних носителях. Действия, выполняемые на этом этапе, весьма специфичны для различных моделей данных. Например, для реляционных моделей создаются: описания набора реляционных таблиц и ограничений на них; конкретные структуры хранения данных и методы доступа к ним, обеспечивающие оптимальную производительность системы с БД; средства защиты создаваемой системы. Тестирование должен проходить любой программный продукт, тем более такой как БД. При тестировании всегда используются реальные данные. Помимо обнаружения возможных ошибок, сбор статистических данных на стадии тестирования позволяет установить показатели качества и надежности созданного программного обеспечения. Этап сопровождения является самым продолжительным в жизненном цикле любой БД. Основные действия на этом этапе сводятся к наблюдению за созданной системой и поддержке ее нормального функционирования. Проектирование БД представляет собой длительный, трудоемкий и слабо формализированный процесс, от которого зависит жизнеспособность и эффективность проектируемой БД, ее способность к развитию. 4.5. Этапы развития СУБД. Реляционная СУБД Microsoft Access — пример системы управления базами данныхПервые СУБД были ориентированы на однопользовательский режим работы с базой данных и имели очень ограниченные возможности. Языки подобных СУБД представляли собой сочетание команд выборки, организации диалога, генерации отчетов. Среди СУБД для персональных компьютеров долгое время доминировало семейство dBASE. Эта СУБД появилась одной из первых на рынке программных продуктов данного профиля. Семейство dBASE включает ряд программ (dBASE II, III, III+, IV) и связанных с ними СУБД Clipper, FoxBASE, Paradox. Последняя СУБД этого семейства — Visual FoxPro, созданная в 1995 году, интегрирована с современными программными продуктами фирмы Microsoft. В настоящее время широко используются несколько СУБД, предназначенных как для работы на ПК, так и основанные на идеологии "клиент-сервер". В их числе можно отметить реляционные СУБД Microsoft Visual FoxPro, Microsoft SQL Server и Microsoft Access. MS Access (англ. access — доступ) — это функционально полная реляционная СУБД, являющаяся одним из компонентов пакета Microsoft Office. Впервые Microsoft Access 1.0 была представлена в ноябре 1992 года. Благодаря исходной поддержке языка SQL и легкости в использовании она быстро завоевала симпатии пользователей. Всю базу данных Access хранит на диске в виде одного файла с расширением mbd, но поддерживает и другие стандарты баз данных. Данные хранятся в виде таблиц-отношений (см. рис. 4.1).  Рис. 4.8. Окно новой базы данных Типичными операциями в СУБД Access являются: работа с таблицами (создание, модификация, удаление таблиц, модификация схем взаимодействия таблиц); ввод данных в таблицы непосредственно или с помощью форм, проверка вводимых данных; поиск данных в таблицах по определенным критериям (выполнение запросов); создание отчетов о содержимом базы данных. 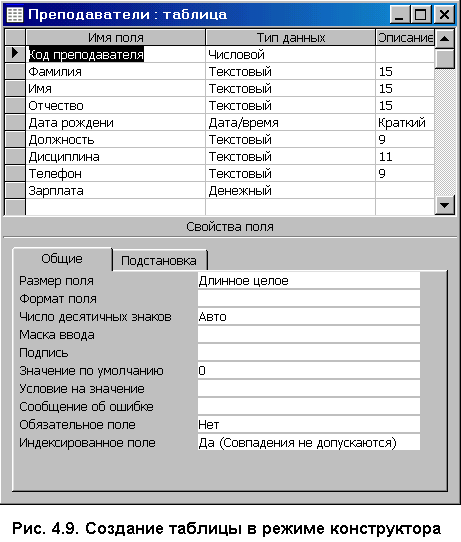 Рис. 4.9. Создание таблицы в режиме конструктора При запуске Access появляется окно создания новой или открытия старой базы данных со списком имеющихся на ПК баз данных. При выборе существующей базы или создании новой появляется окно базы данных (рис. 4.8). В этом окне сосредоточены все рычаги управления базой данных. С помощью вкладки <Объекты>можно выбрать тип нужного объекта (Таблицы, Запросы, Формы, Отчеты, Макросы, Модули). Таблицы — это объекты, которые определяются и используются для хранения данных. Новую таблицу можно создать тремя способами: в режиме конструктора; с помощью мастера; путем вода данных. Создание таблицы в режиме конструктора является, по сути, ручным вводом всех данных о таблице. Здесь задаются имена, свойства и типы полей, их число (рис. 4.9). В этом режиме каждая строка верхней панели рис. 4.9 соответствует одному из полей определяемой таблицы. На нижней панели находится редактор свойств полей, имеющий скрытые элементы управления. 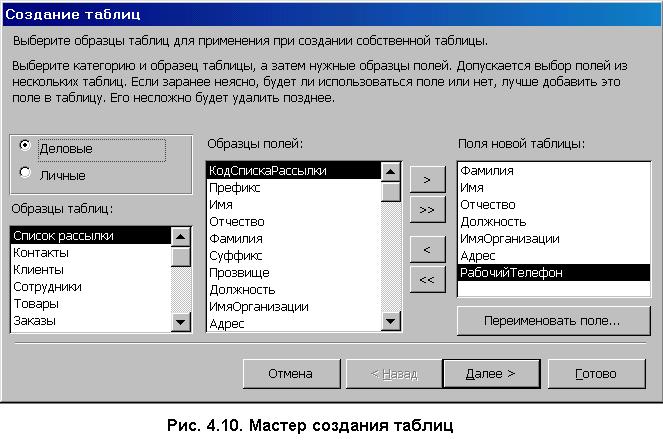 Рис. 4.10. Мастер создания таблиц Мастер для создания таблиц применяется для быстрого и удобного создания распространенных таблиц. Для создания новой таблицы нужно дважды щелкнуть левой кнопкой мыши на соответствующем пункте раздела таблицы. В появившемся окне (рис. 4.10) следует выбрать образец таблицы и образцы полей. После нажатия кнопки <Готово> появится конструктор таблиц, где нужно ввести описания и свойства полей. A Запрос — это объект, позволяющий пользователю получить нужные данные из одной или нескольких таблиц. Запросы являются главным инструментом управления базами данных. В Access для создания запросов удобно использовать визуальные средства. Можно создавать запросы на выбор, обновление, удаление и добавление данных. Создать запрос можно в режиме мастера и в режиме конструктора. Надо помнить, что ответы на запросы получаются путем "разрезания" и "склеивания" таблиц по строкам и столбцам, и что ответы будут также иметь форму таблиц. В Access можно создавать следующие типы запросов: запрос на выборку; запрос с параметрами и перекрестный запрос; запрос на изменение данных (создание таблиц, обновление, добавление и удаление записей); запросы SQL. Запрос на выборку используется наиболее часто. Этот запрос создает не физическую таблицу на диске, а виртуальную в оперативной памяти, которая существует, пока запросом пользуются. В Access предусмотрена возможность создавать сложные запросы на языке SQL. Доступ в режим SQL осуществляется командами Запрос | Вид| Режим SQL. Конструирование таких запросов требует специальных знаний. Форма — объект, предназначенный для удобного отображения данных из одной или нескольких таблиц. Форма — это формат (бланк) показа данных на экране компьютера. Строится форма только на основе таблиц и запросов, создать новую форму можно всего двумя способами: конструктором и мастером. В форму могут быть внедрены рисунки, диаграммы, аудио (звук) и видео (изображение). 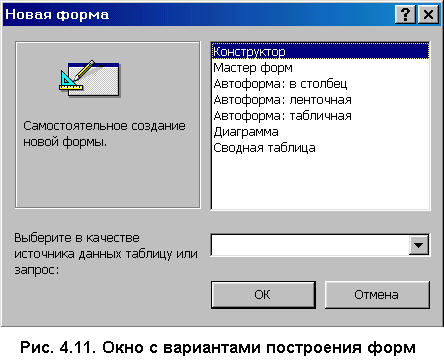 Рис. 4.11. Окно с вариантами построения форм Создание форм с помощью мастера является самым распространенным способом создания форм благодаря простоте и удобству использования. Для этого в режиме базы данных нужно открыть вкладку <Формы> и щелкнуть по кнопке <Создать>, откроется окно, в котором указаны способы создания формы (рис. 4.11). В режиме конструктора можно создать сложные специальные формы, но это доступно только опытному пользователю. Мастер форм дает возможность автоматически создать форму на основе выбранных полей. Access в режиме диалога выясняет у пользователя, какую форму он хочет получить, и создает ее автоматически. Затем эту форму можно подправить в режиме конструктора. Автоформы являются частными случаями мастера форм и используются, например, тогда, когда базовая таблица одна, содержит немного полей и нужно быстро создать простую форму. Отчет — это объект, предназначенный для создания документа, который впоследствии может быть распечатан или включен в документ другого приложения. Организация процесса создания отчетов является одним из главных достоинств Access. Широкие возможности по изменению свойств позволяют создавать самые разнообразные отчеты. Отчеты, как и формы, могут создаваться на основе таблиц и запросов, но не позволяют вводить данные. В Access все отчеты подразделяются на шесть категорий: одностолбцовые отчеты. Здесь в одном длинном столбце перечисляются значения всех полей таблицы или запроса; ленточные отчеты, в которых значения каждой записи помещаются в отдельную строку; многостолбцовые отчеты; отчеты с группировкой данных. В этих отчетах можно вычислять итоговые значения для групп записей; почтовые наклейки для печати имен и адресов; свободные отчеты, содержащие подчиненные отчеты, причем каждый подчиненный отчет создается на основе независимых источников данных. Макрос — объект, представляющий собой структурированное описание одного или нескольких действий, которые выполняет Access в ответ на определенное событие. В макросы можно включать макрокоманды, которые выполняют элементарные действия в БД, например, открывают таблицы и формы, запускают другие макросы и т. п. В Access используется свыше 40 макрокоманд. Модуль — объект, содержащий программы на языке MS Access Basic. Эти программы выполняют мелкие вспомогательные действия, из которых состоит процесс работы в базе данных. 1 Эдгар Франк Кодд (1923—2003 гг.) — английский математик. |