бд и ис. БД и ИС. Базы данных и информационные системы Основные понятия
 Скачать 4.43 Mb. Скачать 4.43 Mb.
|

|
Базы данных и информационные системы Основные понятия В основе решения многих задач лежит обработка информации. Для облегчения обработки информации создаются информационные системы (ИС). Автоматизированными называют ИС, в которых применяют технические средства, в частности, ЭВМ. ИС – это совокупность аппаратно-программных средств, задействованных для решения некоторой прикладной задачи. Банк данных (БнД) – является разновидностью ИС, в которой реализованы функции централизованного хранения и накопления обрабатываемой информации, организованной в одну или несколько БД. БнД в общем случае состоит из следующих компонентов: базы (нескольких баз) данных, системы управления базами данных, словаря данных, администратора, вычислительной системы и обслуживающего персонала. База данных (БД) – представляет собой совокупность специальным образом организованных данных, хранимых в памяти ВС и отображающих состояние объекта и их взаимосвязей в рассматриваемой предметной области. Логическую структуру, хранимой в БД информации, называют моделью представления данных. К основным моделям представления данных (моделям данных) относятся следующие: иерархическая, сетевая, реляционная, пост реляционная, многомерная и объектно-ориентированная. СУБД – комплекс языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. Приложение – представляет собой программу или комплекс программ, обеспечивающих автоматизацию обработки информации для прикладной задачи. Приложения могут создаваться в среде или вне среды СУБД. Словарь данных (СД) – представляет собой подсистему БнД предназначенную для централизованного хранения информации о структурах данных, взаимосвязях файлов БД друг с другом, типах данных и форматах их представления, принадлежности данных пользователю, кодах защиты и разграничения доступа и т.п. Администратор БД (АБД) – есть лицо или группа лиц, отвечающих за выработку требования к БД, её проектирования, создания, эффективного использования и сопровождения. В процессе эксплуатации АБД обычно следит за функционированием ИС, обеспечивает защиту от не санкционированного доступа, контролирует избыточность, не противоречивость, сохранность и достоверность хранимой в БД информации. Для пользовательских СУБД роль АБД возлагается на пользователя СУБД. В вычислительной среде АБД, как правило, взаимодействует с администратором сети. С обязанности последнего входят: контроль за функционированием аппаратно-программных средств в сети, реконфигурация сети, восстановление ПО после сбоев и отказов оборудования, профилактические мероприятия и обеспечение разграничения доступа. Вычислительная система (ВС) – представляет собой совокупность взаимосвязанных и согласованно действующих ЭВМ или процессоров и других устройств, обеспечивающих автоматизацию процессов приёма, обработки и выдачи информации потребителю.         ИС ЭС БнД СУБД БД Обслуживающий персонал выполняет функции поддержания технических и программных средств в работоспособном состоянии. Он проводит профилактические, регламентные, восстановительные и другие работы по плану, а также по мере необходимости. Реляционная модель данных. Основные понятия. Реляционная модель данных предложена сотрудником IBM Эдгаром Коддом и основывается на понятии «отношения» Relation. В наглядной форме представления отношения является привычное для человеческого восприятия двумерная таблица. В реляционных СУБД отслеживается взаимное соответствие записей различных таблиц. Мощь реляционных СУБД заключается в их способности выбирать соответствующие данные из этих таблиц и создавать ответы на вопросы, которые нельзя получить только из одной такой таблицы. Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов. Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени. 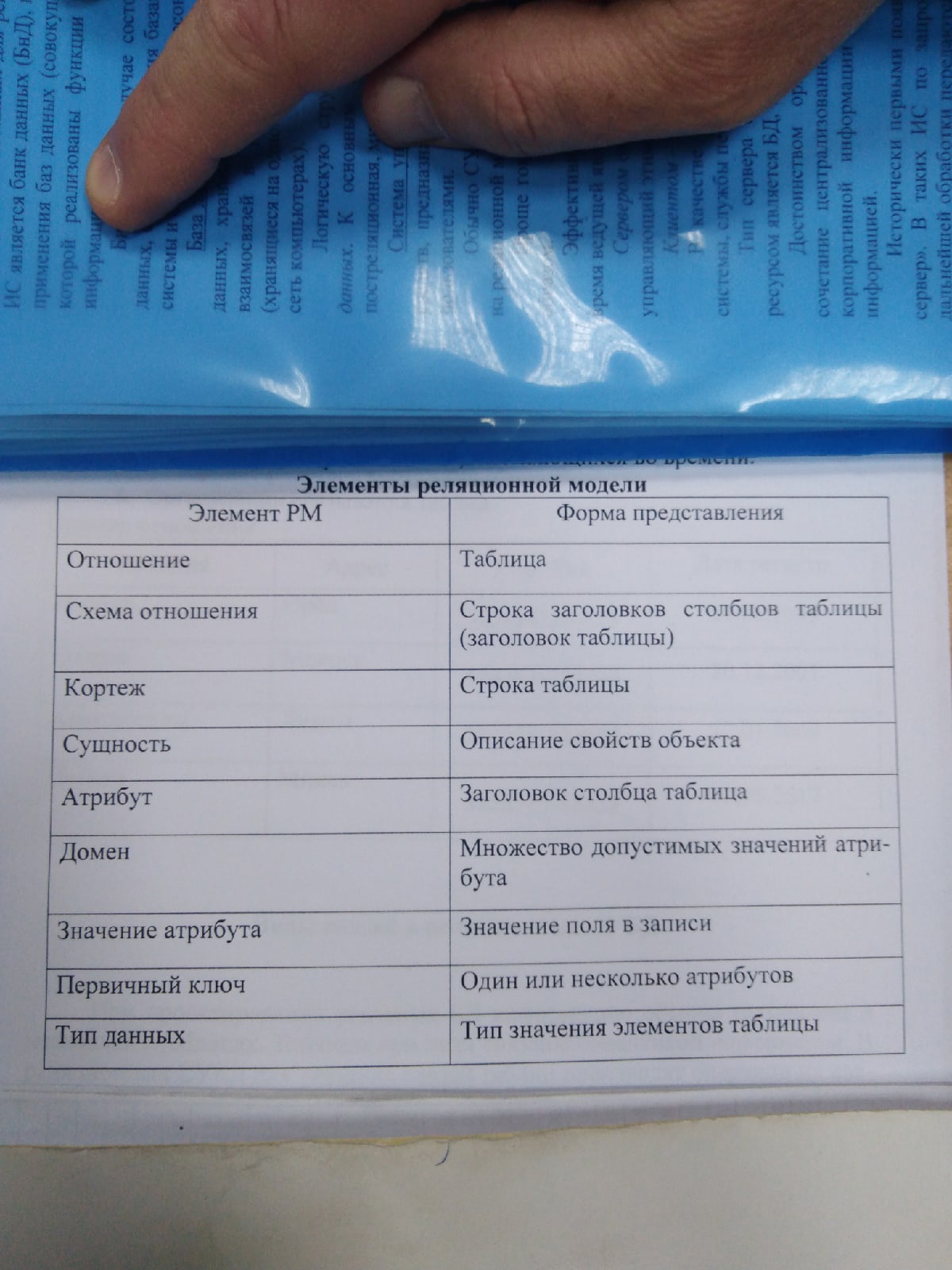 Отношение является важнейшим понятием и представляет собой двумерную таблицу содержащую некоторые данные. Сущность есть объект любой природы данные о котором хранятся в БД. Данные о сущности хранятся в отношении. Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы. Схема отношения (заголовок отношения) представляет собой список имен атрибутов. Каждому картежу соответствует строка таблицы. Множество собственно кортежей отношения часто называют мощностью (содержимым, телом) отношением. ёпта Домен представляет собой множество всех возможных значений определённого атрибута отношений. Первичным ключом (ключом отношения, ключевым атрибутом) называется атрибут отношения однозначно идентифицирующий каждый из его кортежей. Ключи обычно используют для достижения следующих целей: Исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются). Упорядочивание кортежей. Ускорение работы с кортежами отношений. Организаций связывания таблиц.  Виды связи в реляционных базах данных При проектировании реальных баз данных информацию обычно размещают в нескольких таблицах. Таблицы при этом связаны с семантикой информации (смыслом). В реляционных СУБД для указания связи таблиц производят операции их связывания. Многие СУБД при связывании таблиц автоматически выполняют контроль целостности вводимых данных в соответствии с установленными связями. Между таблицами могут устанавливать бинарные (между двумя таблицами), тернарные (между тремя таблицами) и, в общем случае n-арные связи наиболее часто встречаются бинарные. При связывании двух таблиц выделяют основную и дополнительную (подчиненную) таблицы. Логическое связывание таблиц происходит при помощи ключа связи. Ключ связи по аналогии с обычным ключом таблицы состоит из одного или нескольких полей которые в данном случае называют полями связи. Существуют следующие основные виды связи: 1:1 1: ко многим (1:m) Многие:1 (m:1) Многие: многим (m:n)  Дадим характеристику названным видам связи между двумя таблицами и приведем примеры их использования Примечание: *-первичный ключ +-ключ связи (поле связи) Связь вида 1:1 образуется в случае, когда все поля связи основной и дополнительной таблиц являются ключевыми т.е. ключи совпадают Поскольку значения в ключевых полях обеих таблиц не повторяются, обеспечивается взаимно однозначная соответствие записей из этих таблиц. Сами таблицы, по сути, здесь становятся равноправными. Пример 1. *+О1
*+Д1
Вид связи 1: М Связь 1: М имеет место в случае, когда одной записи основной таблицы соответствует несколько записей второй таблицы. Пример 2. Пусть имеется 2 таблицы: О2 и Д2. В таблице О2 содержится информация о видах компьютерных устройств, а в таблице Д2 – сведения о фирмах производителях этих устройств и количестве данного товара на складе. О2 *+
Д2 +
Связь вида м:1. Связь вида М:1 имеет место в случае, когда одной или нескольким записям основной таблицы ставится в соответствие одна запись дополнительной таблицы. Пример 3. В основной таблице О3 содержится информация о товарах частного магазина (продуктовый), их поставщиках и количестве единиц товара на складе. В дополнительной таблице Д3 содержатся подробные сведения о поставщиках. О3 +
Д3 *+
Связь вида M:N. Самый общий вид связи M:N возникает в случаях когда нескольким записям основной таблицы соответствует несколько записей дополнительной таблицы. Пример 4. Пусть в основной таблице О4 содержится информация о том на каких автобусах могут работать водители нек. автобусного парка. Таблица Д4 содержит сведения о том, кто из штата механиков эти автобусы обслуживает. 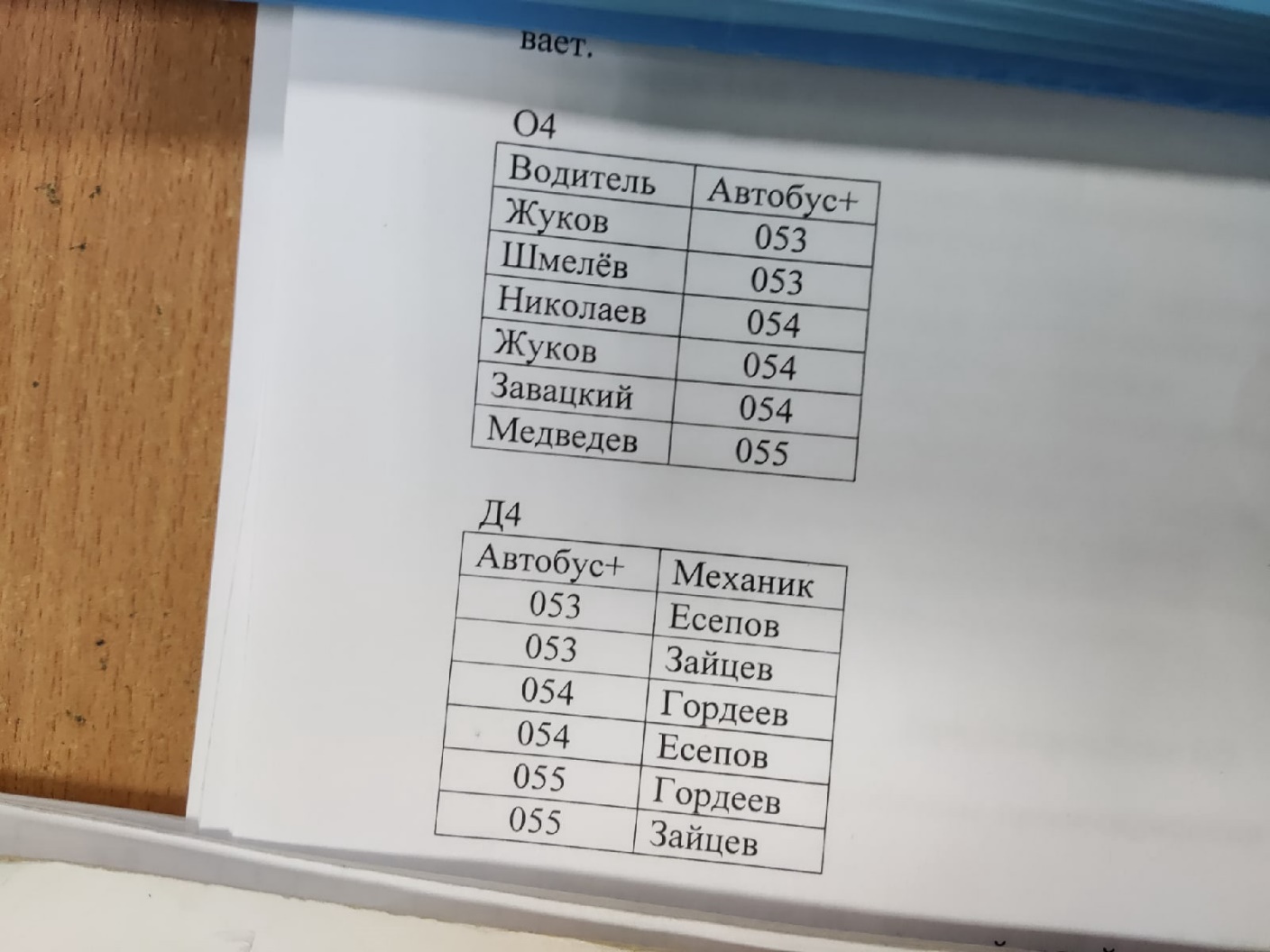 Исходя из определения полей связи этих таблиц, можно составить новую таблицу О4Д4, записями которой будут псевдозаписи. Таблица О4Д4 будет выглядеть следующим образом. 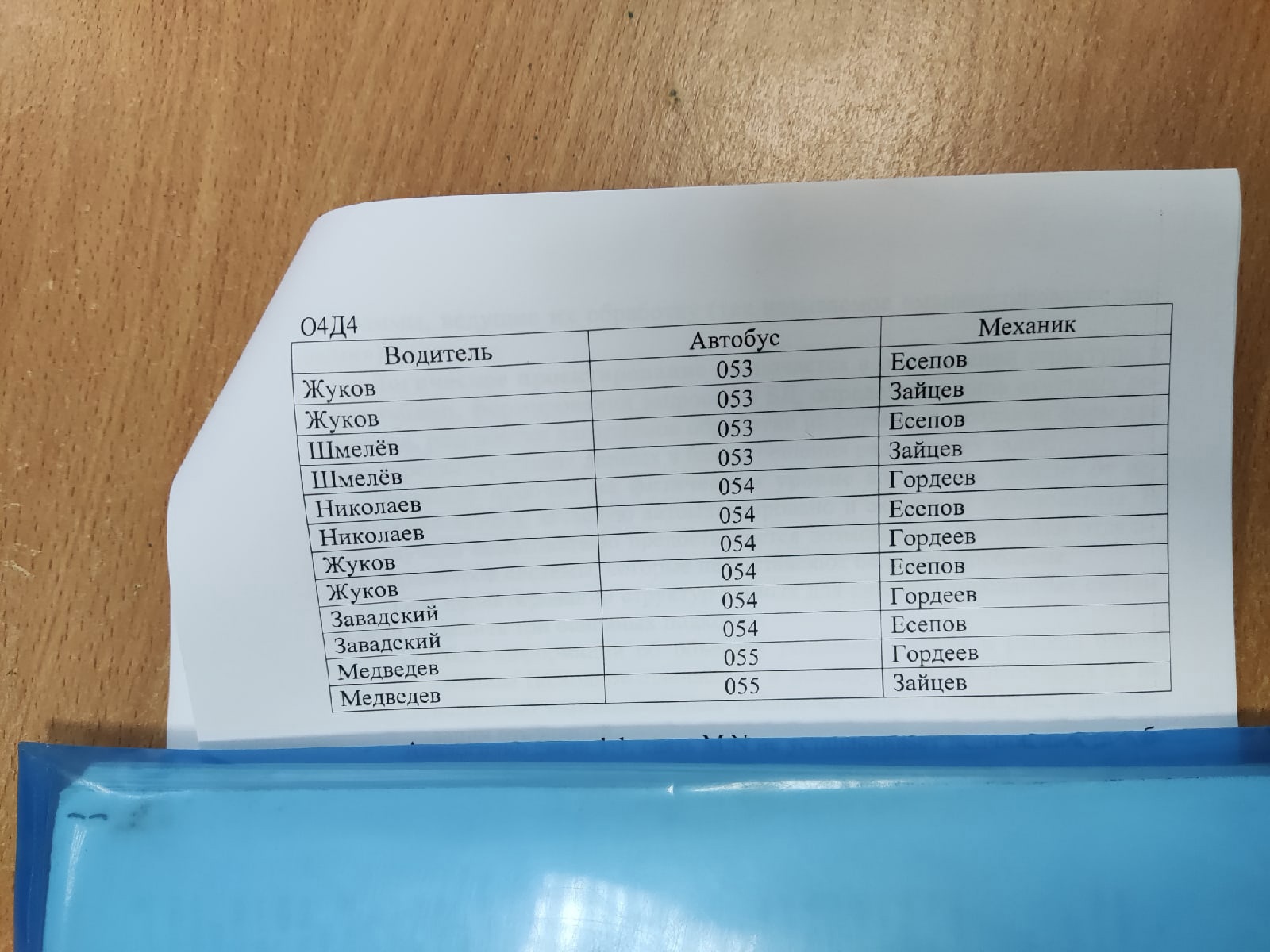 Аналогично связи 1:1, связь M:N не устанавливает подчиненности таблиц. Из перечисленных видов связи наиболее широко используется связь вида 1:M. Связь вида 1:1 можно считать частным случает связи 1:М. связь М:1 по сути, является «зеркальным отображением» связи 1:М. оставшийся вид связи M:N характеризуется как слабый вид связи или даже как отсутствие связи. Для обеспечения достоверности хранимой информации необходим контроль целостности связи, заключающийся в анализе содержимого двух таблиц на соблюдение следующих правил: Каждой записи основной таблицы соответствует нуль или более записей дополнительно таблицы. В дополнительной таблице нет записей, которые не имеют родительских записей в основной таблице. Каждая запись дополнительной таблицы имеет только одну родительскую запись в основной таблице. Проектирование БД. Проблемы проектирования БД.  проектирование ИС включающих в себя БД осуществляется на концептуальном, логическом и физическом уровнях. проектирование ИС включающих в себя БД осуществляется на концептуальном, логическом и физическом уровнях.На концептуальном уровне определяется общая структура информационного массива – она и называется моделью данных в соответствии с выбранной модель строится ИС, в которой будут хранится данные, а также программы, ведущие их обработку (так называемое манипулирование данными). Логическое проектирование заключается в определении структуры и числа таблиц, формировании запросов к БД, определение типа отчетных документов, разработки алгоритмов обработки информации, создание форм для ввода и редактирования данных в базе и решения ряда других задач. Решение проблем на физическом уровне во многом зависит от используемой СУБД, зачастую автоматизирована и скрыта от пользователя. В ряде случаев пользователю предоставляется возможность настройки отдельных параметров системы, которые не составляют большой проблемы. При проектировании структур данных для автоматизированных систем можно выделить 3 основных подхода: Сбор информации об объектах решаемой задачи в рамках одной таблицы (исходное отношение) и последующая декомпозиция её на несколько взаимосвязанных таблиц на основе процедуры нормализации отношений. Формирование знаний о системе (определение типов исходных данных и их взаимосвязей) и требований к обработке данных, получение с помощью case-системы (система автоматизации и разработки БД) готовые схемы БД или даже готовой прикладной ИС. Структурирование информации для использования в ИС в процессе проведения системного анализа на основе совокупности правил и рекомендации. Избыточное дублирование данных и аномалии. Следует различать простое (не избыточное) и избыточное дублирование данных. Наличие первого из них допускается в БД, а избыточное дублирование данных может приводить к проблемам при их разработке. Рассмотрим проблемы избыточного и не избыточного дублирования данных. Пример не избыточного (простого дублирования). СГ
Пример избыточного (избыточности) дублирования. СГК
Пример избавления от избыточности при помощи декомпозиции. СГ ГК
Процедура декомпозиции отношения СГК на два отношения СГ и ГК является основной процедурой нормализации отношений. Избыточное дублирование данных создает проблемы при обработке кортежей отношений, названный Эдгаром Коддом «аномалиями обновления отношений». Аномалиями будем называть такую ситуацию в таблицах БД, которая приводит к противоречиям в БД, либо существенно осложняет обработку данных. Выделяют 3 основных вида аномалий: Аномалии модификаций (или редактирования). Аномалии удаления. Аномалии добавления. Аномалии модификаций проявляются в том, что при изменении значений одного данного может повлечь за собой просмотр всей таблицы и соответствующее изменение некоторых других записей таблицы. Аномалии удаления состоят в том, что при удалении какого-либо данного из таблицы, может пропасть и другая информация, которая не связана на прямую с удаляемым данным. Аномалии добавления возникают в случаях, когда информацию в таблицу нельзя поместить до тех пор, пока она не полная, либо вставка новой записи требует дополнительного просмотра таблицы. Средством исключения избыточности отношений, и, как следствие, аномалий является нормализация отношений. Нормализация отношений. Процесс нормализации – это разбитие таблицы на две или более с целью ликвидации дублирования данных и потенциальной их противоречивости. Окончательная цель нормализации сводится к получению такого проекта БД в котором каждый факт появляется лишь в одном месте. Каждая таблица в реляционной модели удовлетворяет условию, в соответствии с которым на пересечении любой строки и столбца таблицы всегда находится единственное атомарное значение, и никогда не может быть множества таких значений. Говорят, что таблица, удовлетворяющая такому условию, находится в первой нормальной форме. Теперь в дополнении к первой нормальной форме можно определить дальнейшие уровни нормализации. По существу, таблица находится во 2 НФ если она находится в первой нормальной форме и удовлетворяет кроме того некоторому дополнительному условию. Таблица находится в 3 НФ если она находится во 2 НФ и удовлетворяет кроме того некоторому дополнительному условию. Нормальные формы. Таблица находится в 1НФ тогда и только тогда, когда она не содержит одинаковых строк и в любом допустимом значении этой таблицы каждая её строка содержит только одно значение для каждого атрибута. Таблица находится во 2НФ если она удовлетворяет определению 1НФ и все её атрибуты, не входящие в первичный ключ связаны полной функциональной зависимостью с первичным ключом. Таблица находится в 3НФ если она удовлетворяет определению 2НФ и ни один из не её ключевых атрибутов не связан функциональной зависимостью с любым другим не ключевым атрибутом. Таблица находится в НФ бойса-кодда (НФБК) тогда и только тогда года любая функциональная зависимость между её не ключевыми атрибутами сводится к полной функциональной зависимости от возможного первичного ключа. В следующих нормальных формах (4НФ и 5НФ) учитываются не только функциональные, но и многозначные зависимости между атрибутами. Для того чтобы привести определения этих нормальных форм введем понятие полной декомпозиции таблицы. Полной декомпозицией таблицы называют такую совокупность произвольного числа её проекций соединения, которых полностью совпадает с содержимым таблицы. Далее дадим определение высших НФ. Таблица находится в 5НФ тогда и только тогда каждый её полный декомпозиции все проекции содержат возможный ключ. 4НФ является частным случаем 5НФ, когда полная декомпозиция должна быть соединением ровно двух проекций. Структурированный язык запросов SQL. Общая характеристика языка. Язык SQL предназначен для выполнения операций над таблицами (создание, удаление, изменение структуры) и над данными таблиц (выборка, изменения, добавление, удаление), а также некоторых сопутствующих операций. SQL является не процедурным языком и не содержит операторов управления, организации подпрограмм, ввода/вывода и т.п. Язык SQL не обладает функциями полноценного языка разработки, а ориентирован на доступ ка данным поэтому его включают в состав средств разработки программ. В этом случае его называют встроенным SQL. Различают два основных метода использования, встроенного SQL: статический и динамический. При статическом использовании языка (статический SQL) в тексте программы имеются вызовы функций языка SQL, которые жестко включаются в выполняемый модуль после компиляции. Изменения в вызываемых функциях могут быть на уровне отдельных параметров вызовов с помощью переменных языка программирования. При динамическом использовании языка (динамический SQL) предполагается динамическое построение вызовов SQL функций и интерпретация этих вызовов, например, обращение к данным удаленной базы, в ходе выполнения программы. Динамический метод применяется обычно в случаях, когда в приложении заранее не известен вид SQL вызова и он строится в диалоге с пользователем. Основным назначением языка SQL (как и других языков для работы с БД) является подготовка и выполнение запросов. В результате выборки данных из одной или нескольких таблиц может быть получено множество записей, называемые представлением. Представление по существу является таблицей, формируемой в результате выполнения запроса. По одним и тем же таблицам можно построить несколько представлений. Само представление описывается путём указания идентификатора представления и запроса, который должен быть выполнен для его получения. Можно сказать, что оно является разновидностью хранимого запроса. Рассмотрим формат и основные возможности важнейших операторов, за исключением специфических операторов, отмеченных в таблице символом *. Несущественные операнды и элементы синтаксиса (например, принятые во многих системах программирования правило ставить «;» в конце оператора) будем опускать. 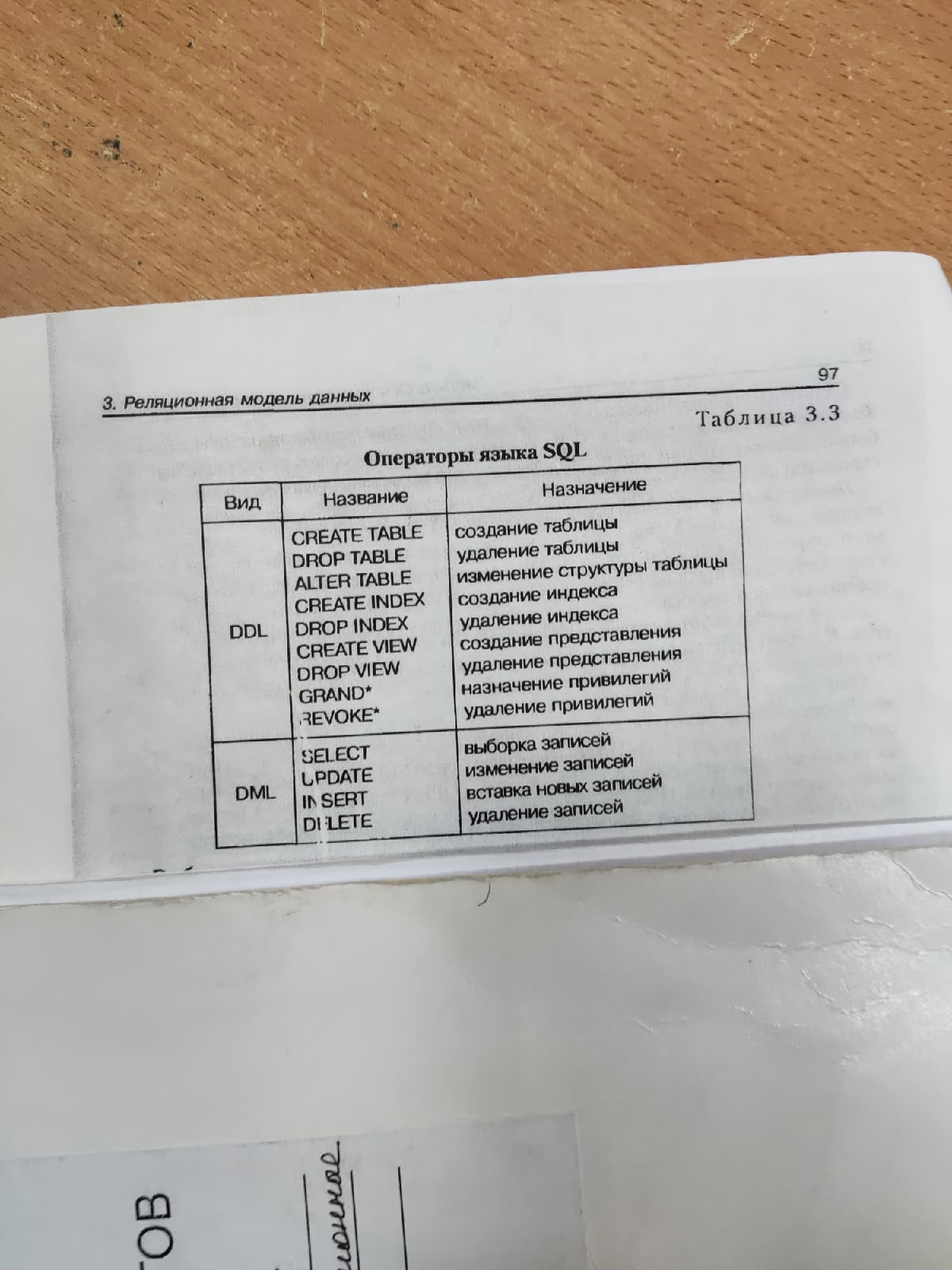      SELECT это наиболее важный оператор из всех операторов SQL. Функциональные возможности его огромны. Рассмотрим основные из них. Оператор SELECT позволяет производить выборку и вычисления над данными их одной или нескольких таблиц. Результатом выполнения оператора является ответная таблица, которая может иметь (ALL) или не иметь (DISTINCT) повторяющиеся строки. По умолчанию в ответную таблицу включаются все строки, в том числе и повторяющиеся. В отборе данных участвуют записи одной или нескольких таблиц перечисленных в списке операнда FROM. Список данных может содержать имена столбцов, участвующих в запросе, а также выражения над столбцами. В простейшем случае в выражениях можно записывать имена столбцов, знаки арифметических операций (+, -, *, |, константы и круглые скобки). Если в списке данных записано выражение, то на ряду с выборкой данных выполняются вычисления, результаты которых попадают в новый (создаваемой) столбец ответной таблицы. При использовании специальных данных иных столбцов нескольких таблиц для указания принадлежности столбца к некой таблице используют конструкции вида: <имя таблицы>. <имя столбца>. Операнд WHERE задает условие, которому должны удовлетворять записи результирующей таблицы. Выражение <условия выборки> является логическим, его элементами могут быть: имена столбцов, операции сравнения, арифметические операции, логические связки (and, or, not), скобки, специальные функции (LIKE, NULL, IN). Операнд GROUP BY позволяет выделять в результирующем множестве записей, группа записей с совпадающими значениями в столбцах, перечисленных за ключевыми словами GROUP BY. Выделение групп требуется для использования в логических выражениях операндов VERY и HAVING, а также для выполнения операций (вычислений) над группами. В логических и арифметических выражениях можно использовать следующие групповые операции (функции): AVG (среднее значение в группе), MAX (максимальное значение в группе), MIN (минимальное значение в группе), SUM (сумма значений в группе), COUNT (число значений в группе). Операнд HAVING действует совместно с операндом GROUP BY и используется для дополнительной селекции записей во время определения групп. Правила записей <условия поиска> аналогично правилам формирования <условия выборки>. Операнд ORDER BY задает порядок сортировки результирующего множества. Обычно каждая <спецификация> представляет собой пару вида: <имя столбца> [ASC|DESC]. Замечание. Оператор SELECT может иметь и другие более сложные синтаксические конструкции, которые мы подробно рассматривать не будем, а поясним их смысл. Одной из таких конструкций, например, являются так называемые под запросы, они позволяют формулировать вложенные запросы, когда результат одного оператора SELECT используются в логическим выражении, условия выборки операнда VERY другого оператора SELECT. Вторым примером более сложной формы оператора SELECT является оператор отобранные записи в дальнейшем предполагается модифицировать (конструкция FOR UPDATE OF) СУБД после выполнения такого оператора обычно блокирует (защищает) отобранные записи от модификации их другими пользователями. Еще один случай специфического использования оператора SELECT – выполнение объединений результирующих таблиц при выполнении нескольких операторов SELECT (операнд UNION).     |