Блок Примитивные типы
 Скачать 6.67 Mb. Скачать 6.67 Mb.
|

|
Какое правило должно соблюдаться при использовании нескольких блоков catch (с одним try)? От меньшего к большему. Первыми должны ловиться наименьшие в иерархии исключения. Иначе будут «недостижимые» исключения, которые никогда не будут выполнены программой. Какое правило должно соблюдаться при попытке поймать несколько исключений в одном catch? Если мы ловим несколько исключений и одно из которых является предком первого, то мы должны оставить только предка, иначе компилятор будет ругаться. Исключения прописываются через разделитель |. Зачем создавать свой класс и наследовать его от Exception? Для создания СОБСТВЕННЫХ проверяемых исключительных ситуаций, которые не предусмотрены JVM или компилятором и последующей обработки этих ситуаций. Что такое ошибка, а что такое исключительная ситуация? Исключительная ситуация – ситуация которую мы можем предсказать и обработать. Ошибка возникает на уровне JVM и не может быть обработана программистом (закончилась память в компьютере или переполнен стек – и взять её неоткуда, поэтому и обрабатывать смысла нет). Что нужно делать программисту, если в коде происходит деление на ноль? Нет смысла ловить и обрабатывать ArithmeticException. Как правило, все проверяемые исключения выбрасываются, если в коде есть проблемы, которые можно просто исправить. От каких классов Throwable и его подклассов нельзя наследоваться? Технически от класса Error наследоваться не принято, т.к. это ошибки JVM (серьезные ошибки, которые программист итак обработать не может). Какую информацию можно получить из StackTraceElement? Актуальную информация о текущем состоянии «стека вызовов функций» Когда одна функция вызывает другую, Java-машина помещает в этот стек новый элемент StackTraceElement. Когда функция завершается этот элемент удаляется из стека.  Можно ли так написать try { throw new Object(); }? Это будет ошибкой, т.к. Object не является исключением, хотя и является родителем Throwable. Вся работа с исключениями начинается с класса Throwable. В чём разница между проверяемыми исключениями и непроверяемыми? В чём разница с точки зрения синтаксиса и идеологическая при использовании?   Какое назначение класса Throwable? Методы класса Throwable 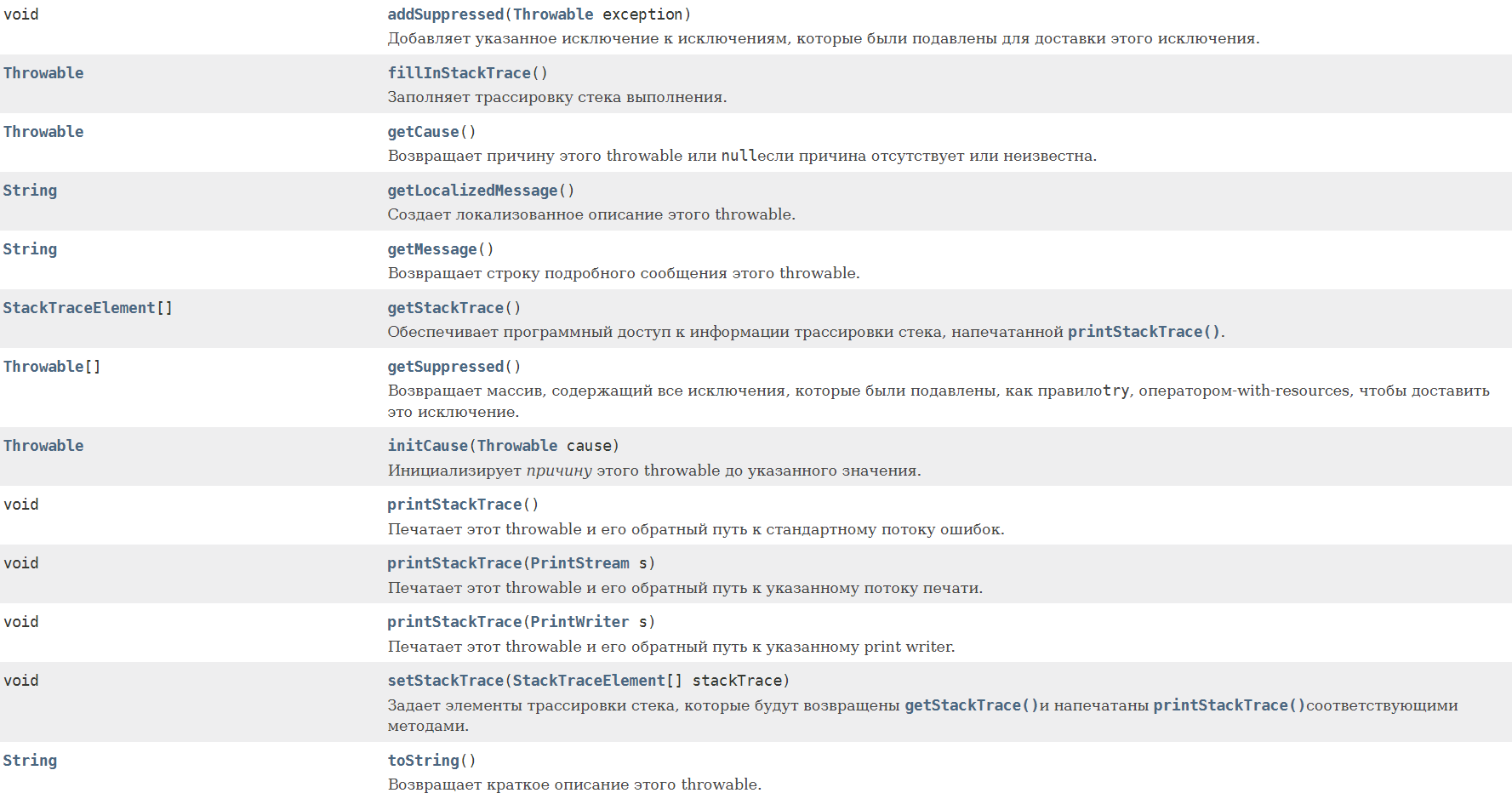 Что происходит если не обработать исключение? Если не было предпринято дополнительных действий, в этой ситуации нет никаких хитростей. Всё приложение, и даже метод main() , выполняется в потоках. Поток, в котором было выброшено и не обработано исключение, остановится, и распечатает стектрейс в вывод System. Что такое подавленные исключения? Подавленные исключения -это дополнительные исключения, которые возникают в операторе try-with-resources ( введенном в Java 7 ) при закрытии ресурсов AutoCloseable. Поскольку при закрытии ресурсов AutoCloseable может возникнуть несколько исключений, дополнительные исключения присоединяются к основному исключению как подавленные исключения. Вы можете получить эти подавленные исключения, вызвав метод Throwable.getSuppressed из исключения, созданного блоком try. Что такое ресурс в конструкции try-with-resources? Ресурс — это объект, который должен быть закрыт после того, как программа закончит с ним работу. «try c ресурсами» берет всю работу по закрытию ресурсов на себя. В качестве ресурса можно использовать любой объект, класс которого реализует интерфейс java.lang.AutoCloseable или java.io.Closable. Что если исключение вылетело сначала в try, а потом в close в конструкции try-with-recources? Какое исключение вылетит? Что будет с другим? Если исключение будет выброшено в основном коде и в методе close(), то приоритетнее будет первое исключение, а второе исключение будет подавлено, но информация о нем сохранится (с помощью метода Throwable.addSuppressed(Throwable exception), который вызывается неявно Java компилятором Когда происходит закрытие ресурса в конструкции try-with-resources если в try возникло исключение: до перехода в catch или после того как catch отработает? До перехода в catch. Порядок действий следующий: try неявное finally catch явное finally Какие есть уровни логирования и для чего они нужны? SEVERE (ошибка) WARNING (предупреждение) INFO (информационное сообщение) CONFIG FINE (сообщение об успешной операции) FINER FINEST В логгере есть ещё Форматтер (Formatter), Хэндлер (Handler) Логгирование позволяет ответить на вопросы, что происходило, когда и при каких обстоятельствах. Без логов сложно понять, из-за чего появляется ошибка, если она возникает периодически и только при определенных условиях. Обязательно ли передавать в метод getLogger() имя класса? Почему так принято? Logger.getLogger создает один регистратор на класс, а не один регистратор на экземпляр класса. Logger.getLogger(Class) является сокращением для getLogger(clazz.getName()). Соглашение, используемое с log4j и другими фреймворками регистрации, - это определение статического регистратора для каждого класса. Причины, по которой многие люди используют тип класса: Прост в использовании. Вам не нужно беспокоиться о дублировании имен Легко проверить класс ведения журнала, так как имя журнала будет отображаться в файле журнала Когда вы распространяете свой класс, люди могут захотеть перенаправить ведение журнала из вашего класса в конкретный файл или в другое место. Сообщения каких уровней мы увидим, задав уровень INFO? INFO и выше (WARNING, SEVERE). Как Java понимает какой уровень главнее при установке .setLevel() Метод setLevel(), как и в объектах регистратора, определяет наименьшую степень серьезности, которая будет отправлена в соответствующее место назначения. Почему существует два метода setLevel()? Уровень, установленный в регистраторе, определяет, какую степень серьезности сообщений он будет передавать своим обработчикам. Уровень, установленный в каждом обработчике, определяет, какие сообщения будет отправлять этот обработчик  Блок 5. Ввод-вывод, доступ к файловой системе 1) Какие существуют виды потоков ввода/вывода? - Разделяют два вида потоков ввода/вывода: байтовые и символьные. 2) Назовите основные предки потоков ввода/вывода - Байтовые: java.io.InputStream, java.io.OutputStream; Символьные: java.io.Reader, java.io.Writer; 3) Что общего и чем отличаются следующие потоки: InputStream, OutputStream, Reader, Writer? – Базовый класс InputStream представляет классы, которые получают данные из различных источников:- массив байтов- строка (String)- файл- канал (pipe): данные помещаются с одного конца и извлекаются с другого- последовательность различных потоков, которые можно объединить в одном потоке- другие источники (например, подключение к интернету). Класс OutputStream - это абстрактный класс, определяющий потоковый байтовый вывод. В этой категории находятся классы, определяющие, куда направляются ваши данные: в массив байтов (но не напрямую в String; предполагается что вы сможете создать их из массива байтов), в файл или канал. Символьные потоки имеют два основных абстрактных класса Reader и Writer, управляющие потоками символов Unicode. Класс Reader - абстрактный класс, определяющий символьный потоковый ввод. Класс Writer - абстрактный класс, определяющий символьный потоковый вывод. В случае ошибок все методы класса передают исключение IOException. 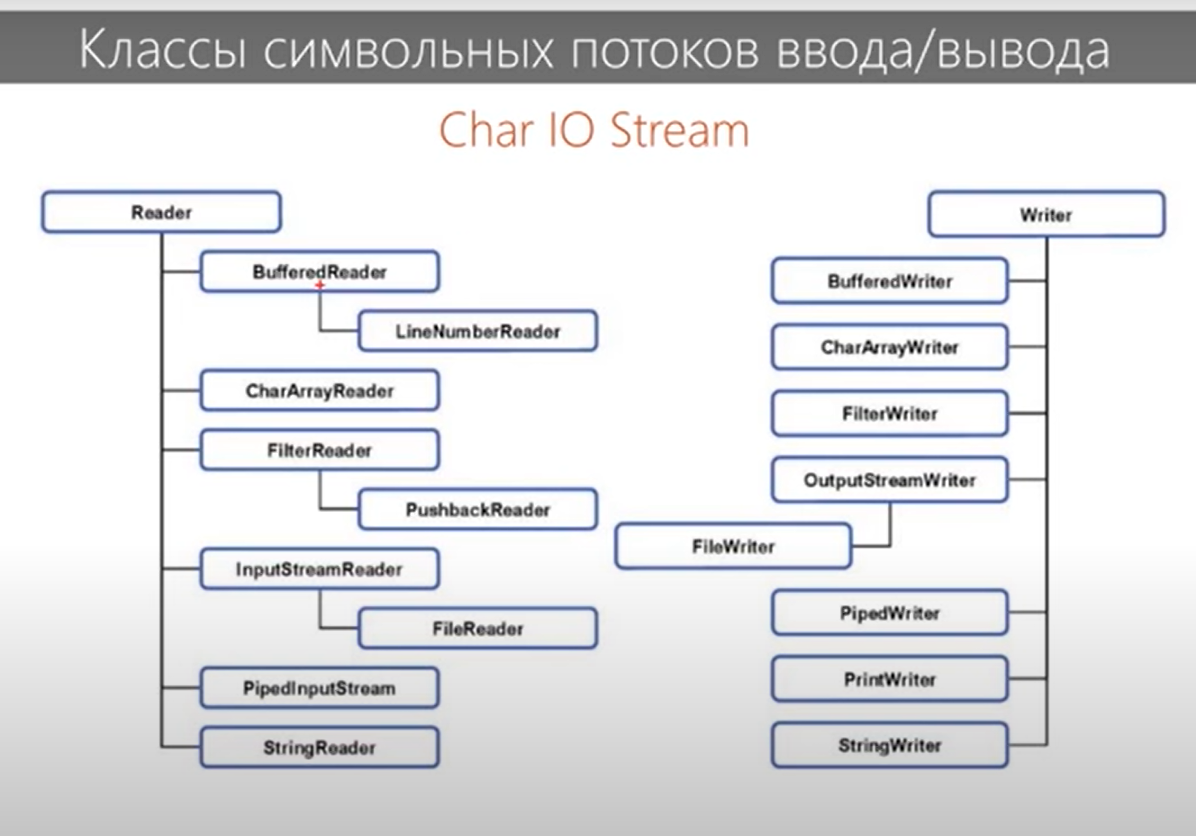 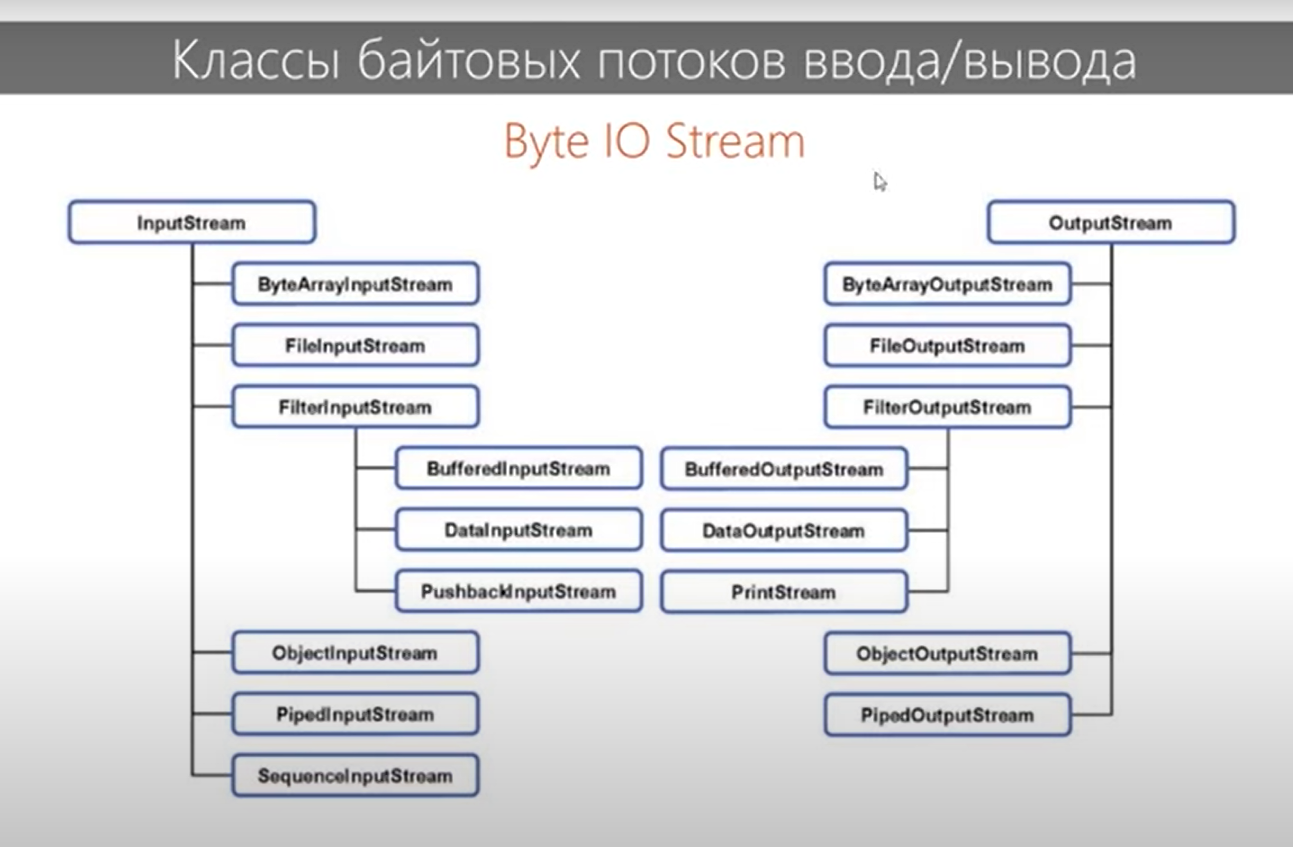 4) Что вы знаете о RandomAccessFile? - Класс RandomAccessFile наследуется напрямую от Object и не наследуется от вышеприведенных базовых классов ввода\вывода. Предназначен для работы с файлами, поддерживая произвольный доступ к их содержимому. Работа с классом RandomAccessFile напоминает использование совмещенных в одном классе потоков DataInputStream и DataOutputStream (они реализуют те же интерфейсы DataInput и DataOutput). Кроме того, метод seek() позволяет переместиться к определенной позиции и изменить хранящееся там значение. При использовании RandomAccessFile необходимо знать структуру файла. Класс RandomAccessFile содержит методы для чтения и записи примитивов и строк UTF-8. Экземпляры этого класса поддерживают как чтение, так и запись в файл произвольного доступа. Файл произвольного доступа ведет себя как большой массив байтов, хранящихся в файловой системе. Существует своего рода курсор или индекс в подразумеваемом массиве, называемый указателем файлаоперации ввода считывают байты, начиная с указателя файла, и продвигают указатель файла мимо прочитанных байтов. Если файл произвольного доступа создан в режиме чтения/записи, то операции вывода также доступны; операции вывода записывают байты, начиная с указателя файла, и продвигают указатель файла мимо записанных байтов. Операции вывода, которые записывают мимо текущего конца подразумеваемого массива, приводят к расширению массива. Указатель файла может быть прочитан getFilePointerметодом и установлен seekметодом. Как правило, для всех процедур чтения в этом классе верно то, что если конец файла достигнут до того, как будет прочитано желаемое количество байтов, то выбрасывается an EOFException(что является своего родаIOException). Если какой-либо байт не может быть прочитан по какой-либо причине, кроме конца файла, генерируется IOExceptionдругой EOFExceptionбайт. В частности, an IOExceptionможет быть брошен, если поток был закрыт. 5) Какие есть режимы доступа к файлу? - RandomAccessFile может открываться в режиме чтения ("r") или чтения/записи ("rw"). Также есть режим "rws", когда файл открывается для операций чтения-записи и каждое изменение данных файла немедленно записывается на физическое устройство. При создании экземпляра RandomAccessFile, мы должны выбрать режим файла, например "r", если вы хотите прочитать данные с файла или "rw" — если вы хотите читать с файла и писать в файл.   А в общем случае режимы доступа к файлу следующие:  6) В каких пакетах лежат классы-потоки? -Классы потоков ввода\вывода лежат в java.io; С JDK 7 добавлен более современный способ работы с потоками - Java NIO. Классы лежат в java.nio. Для работы с архивами используются классы из пакета java.util. 7) Что вы знаете о классах-надстройках? - Классы-надстройки наделяют существующий поток дополнительными свойствами. Примеры классов: BufferedOutputStream, BufferedInputStream, BufferedWriter - буферизируют поток и повышают производительность. Или, например, DataOutputStream и DataInputStream, которые позволяют читать и записывать все примитивные типы из/в массив байт. 8) Какой класс-надстройка позволяет читать данные из входного байтового потока в формате примитивных типов данных? - Для чтения байтовых данных (не строк) применяется класс DataInputStream. В этом случае необходимо использовать классы из группы InputStream. Для преобразования строки в массив байтов, пригодный для помещения в поток ByteArrayInputStream, в классе String предусмотрен метод getBytes(). Полученный ByteArrayInputStream представляет собой поток InputStream, подходящий для передачи DataInputStream. При побайтовом чтении символов из форматированного потока DataInputStream методом readByte() любое полученное значение будет считаться действительным, поэтому возвращаемое значение неприменимо для идентификации конца потока. Вместо этого можно использовать метод available(), который сообщает, сколько еще осталось символов. Класс DataInputStream позволяет читать элементарные данные из потока через интерфейс DataInput, который определяет методы, преобразующие элементарные значения в форму последовательности байтов. Такие потоки облегчают сохранение в файле двоичных данных. Конструктор: DataInputStream(InputStream stream)Методы: readDouble(), readBoolean(), readInt(). 9) Какой класс-надстройка позволяет ускорить чтение/запись за счет использования буфера? - Для этого используются классы, позволяющие буферизировать поток: BufferedInputStream(InputStream in) BufferedInputStream(InputStream in, int size) BufferedOutputStream(OutputStream out) BufferedOutputStream(OutputStream out, int size) BufferedReader(Reader r) BufferedReader(Reader in, int sz),java.io.BufferedWriter(Writer out) BufferedWriter(Writer out, int sz) A BufferedInputStreamдобавляет функциональность к другому входному потоку, а именно возможность буферизации ввода и поддержки методов markandreset. При BufferedInputStreamсоздании создается внутренний буферный массив. Когда байты из потока считываются или пропускаются, внутренний буфер заполняется по мере необходимости из содержащегося входного потока по нескольку байтов за раз. markОперация запоминает точку во входном потоке, и эта resetоперация приводит к тому, что все байты, прочитанные с момента последней markоперации, перечитываются до того, как из содержащегося входного потока будут взяты новые байты. 10) Какие классы позволяют преобразовать байтовые потоки в символьные и обратно? – 1) OutputStreamWriter - мост между классом OutputStream и классом Writer. Символы, записанные в поток, преобразовываются в байты. 2) InputStreamReader - аналог для чтения. При помощи методов класса Reader читаются байты из потока InputStream и далее преобразуются в символы.  11) Какой класс предназначен для работы с элементами файловой системы (ЭФС)? - В отличие от большинства классов ввода/вывода, класс File работает не с потоками, а непосредственно с файлами. Данный класс позволяет получить информацию о файле: права доступа, время и дата создания, путь к каталогу. А также осуществлять навигацию по иерархиям подкаталогов. Класс java.io.File может представлять имя определённого файла, а также имена группы файлов, находящихся в каталоге. Если класс представляет каталог, то его метод list() возвращает массив строк с именами всех файлов. Для создания объектов класса File можно использовать один из следующих конструкторов: File(File dir, String name) - указывается объект класса File (каталог) и имя файла File(String path) - указывается путь к файлу без указания имени файла File(String dirPath, String name) - указывается путь к файлу и имя файла File(URI uri) - указывается объекта URI, описывающий файл. Начиная с Java 7, добавились классы Path и Files из пакета java.nio.files. В них добавили намного больше функциональности, через класс Files теперь можно создавать потоки для работы с файлами. Таким образом, класс File теперь по сути стал рудиментом и остается лишь для сохранения обратной совместимости. 12) Какой символ является разделителем при указании пути к ЭФС? - Для различных систем символ разделителя различается. Вытащить его можно используя file.separator, а так же в статическом поле File.separator. Для Windows это '\'.*На stackoverflow встречал утверждение со ссылкой на документацию, что можно безопасно использовать слэш '/' для всех систем. В комментарии читатель подтвердил это. 13) Что вы знаете об интерфейсе FilenameFilter? - Интерфейс FilenameFilter применяется для проверки попадает ли имя объекта File под некоторое условие. Этот интерфейс содержит единственный метод boolean accept(File pathName). Этот метод необходимо переопределить и реализовать. 14) Что такое сериализация? - Сериализация это процесс сохранения состояния объекта в последовательность байт; десериализация это процесс восстановления объекта, из этих байт. Java Serialization API предоставляет стандартный механизм для создания сериализуемых объектов.      15) Какие условия "благополучной" сериализации объекта? - Чтобы обладать способностью к сериализации, класс должен реализовывать интерфейс-метку Serializable. Так же все атрибуты и подтипы сериализуемого класса должны быть сериализуемы. Если класс предок был несереализуемым, то этот суперкласс должен содержать доступный (public, protected) конструктор без параметров для инициализации полей. Поля, которые не должны быть сериализованы, должны быть помечены ключевым словом transient. 16) Какие классы позволяют архивировать объекты? - DeflaterOutputStream, InflaterInputStream, ZipInputStream, ZipOutputStream, GZIPInputStream, GZIPOutputStream.  DeflaterOutputStream и InflaterInputStream являются при этом предками остальных классов. В этих классах еще в конструкторе используется класс Deflater и Inflater, компрессор и декомпрессор, предназначенные для сжатия и деархивации данных и последующей передачи потоку. 17) Основные отличия между Java IO и Java NIO – IO 1) Блокирующий ввод-вывод Потоки ввода/вывода (streams) в Java IO являются блокирующими. Это значит, что когда в потоке выполнения (tread) вызывается read() или write() метод любого класса из пакета java.io.*, происходит блокировка до тех пор, пока данные не будут считаны или записаны. Поток выполнения в данный момент не может делать ничего другого. 2) Потокоориентированный ввод-вывод. Потокоориентированный ввод/вывод подразумевает чтение/запись из потока/в поток одного или нескольких байт в единицу времени поочередно. Данная информация нигде не кэшируются. Таким образом, невозможно произвольно двигаться по потоку данных вперед или назад. Если вы хотите произвести подобные манипуляции, вам придется сначала кэшировать данные в буфере. NIO 1) Неблокирующий ввод-вывод Неблокирующий режим Java NIO позволяет запрашивать считанные данные из канала (channel) и получать только то, что доступно на данный момент, или вообще ничего, если доступных данных пока нет. Вместо того, чтобы оставаться заблокированным пока данные не станут доступными для считывания, поток выполнения может заняться чем-то другим. 2) Буфероориентированный ввод-вывод. Селекторы Селекторы в Java NIO позволяют одному потоку выполнения мониторить несколько каналов ввода. Вы можете зарегистрировать несколько каналов с селектором, а потом использовать один поток выполнения для обслуживания каналов, имеющих доступные для обработки данные, или для выбора каналов, готовых для записи. 18) В чем отличие Scanner от BufferedReader? - Scanner позволяет разобрать строку на составляющие (токены), с помощью различных разделителей. Он не синхронизирован и, также не выбрасывает исключения. BufferedReader предназначен для чтения потока символов с буферизацией. Также Scanner намного более функциональный, в его конструктор можно передать и файл, и поток, и строку, и консольный ввод. 19) Что делать, если одно из полей сериализовывать не нужно. - Это поле нужно пометить ключевым словом transient. И оно не будет сериализовано. 20) Как сериализовать объект класса? - Нужно пометить его маркерным классом Serializable и передать его методу writeObject() потока ObjectOutputStream. 21) Какие форматы сериализации существуют?- 1. JSON JavaScript Object Notation. Поскольку JSON — объект JavaScript, он поддерживает следующие форматы данных JavaScript: строки (string); числа (number); объекты (object); массивы (array); boolean-значения (true и false); null. Какие же преимущества есть у JSON? Human-readable («человеко-читаемый») формат. Это очевидное преимущество, если твой конечный пользователь — человек. К примеру, на твоем сервере хранится база данных с расписанием авиаперелетов. Клиент-человек запрашивает данные из этой базы с помощью веб-приложения, сидя дома за компьютером. Поскольку тебе нужно предоставить данные в формате, который он сможет понять, JSON будет отличным решением. Простота. Можно сказать — элементарность :) Выше мы привели пример двух JSON-файлов. И даже если ты вообще не слышал о существовании JavaScript (и уж тем более о его объектах), ты легко поймешь, что за объекты там описаны. Вся документация JSON — это одна веб-страница с парой картинок. Широкая распространенность. JavaScript — доминирующий язык фронтенда, и он диктует свои условия. Использование JSON — необходимость. Поэтому огромное число веб-сервисов используют JSON в качестве формата для обмена данными. Каждая современная IDE поддерживает JSON-формат (в том числе Intellij IDEA). Для работы с JSON написана куча библиотек для всех возможных языков программирования. 2. XML  3. BinarySON - тот же JSON только в двоичном представлении.  4. Position based protocol  5. YAML - Yet Another Markup Language В начале своего существования расшифровывался как Yet Another Markup Language — «еще один язык разметки». В то время его позиционировали как конкурента XML. Сейчас же, по прошествии времени, он расшифровывается как «YAML Ain’t Markup Language» («YAML — не язык разметки»). Что же он из себя представляет? Давай представим, что нам нужно создать 3 класса персонажей для нашей компьютерной игры: Воин, Маг и Вор. У них буду следующие характеристики: сила, ловкость, выносливость, набор оружия. Вот как будет выглядеть наш YAML-файл с описанием классов: 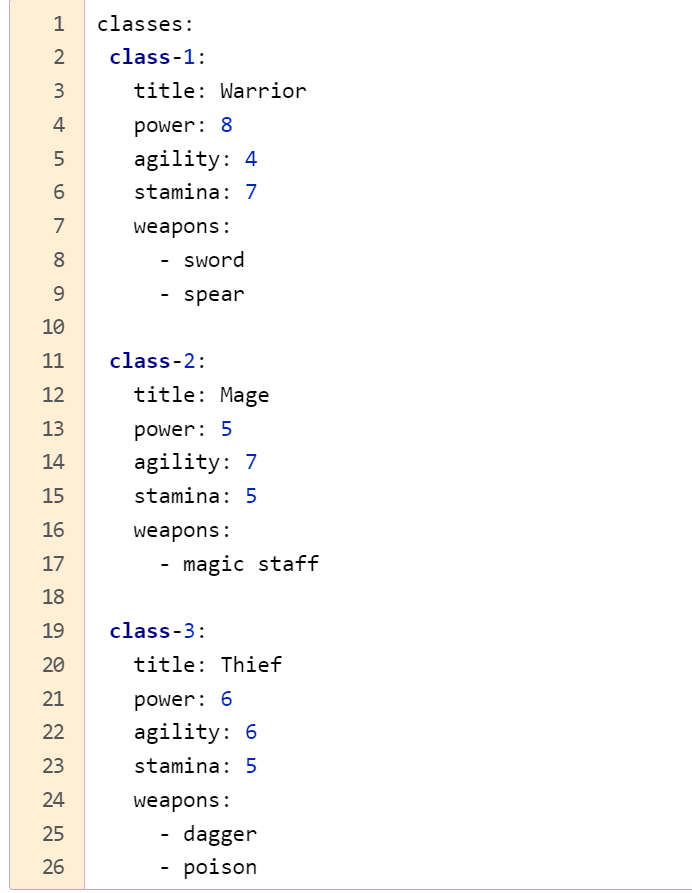 YAML-файл имеет древовидную структуру: одни элементы вложены в другие. Вложенностью мы можем управлять при помощи некоторого количества пробелов, которым обозначаем каждый уровень. Какими же преимуществами обладает YAML-формат? Human-readable. Опять же, даже увидев yaml-файл без описания, ты легко поймешь, какие объекты там описаны. YAML насколько хорошо читается человеком, что главная страница yaml.org — это обычный yaml-файл :) Компактность. Структура файла формируется за счет пробелов: нет необходимости использовать скобки или кавычки. Поддержка структур данных, «родных» для языков программирования. Огромное преимущество YAML перед JSON и многими другими форматами заключается в том, что он поддерживает разные структуры данных. В их числе: !!map Неупорядоченный набор пар ключ:значение без возможности дубликатов; !!omap Упорядоченная последовательность пар ключ:значение без возможности дубликатов; !!pairs: Упорядоченная последовательность пар ключ:значение с возможностью дубликатов; !!set Неупорядоченная последовательность значений, которые не равны друг другу; !!seq Последовательность произвольных значений; Возможность использования anchor и alias Перевод слов «anchor» и «alias» — «якорь» и «псевдоним». В принципе, он довольно точно описывает суть этих терминов в YAML. Они позволяют тебе идентифицировать какой-то элемент в yaml-файле, и ссылаться на него в остальных частях этого файла, если он встречается повторно. Anchor создается с помощью символа &, а alias — с помощью *. 5. В YAML можно встроить данные в других форматах. Например, JSON 22) Cтандартные потоки ввода / вывода? - В языке Java стандартный поток ввода представлен переменной System.in. Эта переменная (объект) имеет тип InputStream. Класс InputStream есть абстрактный и размещается в вершине иерархии классов ввода. Стандартный поток вывода ассоциируется с переменной (объектом) System.out, тип которой PrintStream. Класс PrintStream содержит методы вывода на консоль print() и println(). 23) Классы байтовых потоков ввода и что они делают? – Классы, которые реализуют байтовые потоки ввода унаследованы от абстрактного класса InputStream: InputStream - абстрактный класс, который описывает поток ввода. Данный класс есть базовым для всех других классов системы ввода; BufferedInputStream - класс, который описывает буферизованные поток ввода; ByteArrayInputStream - класс, который описывает поток ввода, читающий байты из массива; DataInputStream -класс, который реализует методы для чтения данных стандартных типов, определенных в Java (int, double, float и т.д.); FileInputStream - класс, который реализует поток ввода, который читает данные из файла; FilterInputStream - это реализация абстрактного класса InputStream; ObjectInputStream - класс, реализующий поток ввода объектов; PipedInputStream - класс, соответствующий каналу ввода; PushbackInputStream - класс, соответствующий потоку ввода, который поддерживает возврат одного байта обратно в поток ввода; SequenceInputStream - класс, который реализует поток ввода, состоящий из двух или более потоков ввода, данные из которых читаются поочередно. 24) Классы байтовых потоков вывода и что они делают?- Классы, которые реализуют байтовые потоки вывода унаследованы от абстрактного класса OutputStream: OutputStream - абстрактный класс, который описывает поток вывода. Все другие классы системы вывода есть подклассами класса OutputStream; BufferedOutputStream - класс, который имплементирует буферизованный поток вывода; ByteArrayOutputStream - класс, который реализует поток вывода, записывающий байты в массив; DataOutputStream - класс, который реализует поток вывода, содержащий методы для чтения данных стандартных типов, определенных в Java (int, float, double и т.п.); FileOutputStream - класс, который соответствует потоку вывода записывающему данные в файл; FilterOutputStream - класс, реализующий абстрактный класс OutputStream; ObjectOutputStream - класс, соответствующий потоку вывода объектов; PipedOutputStream - класс, который ассоциируется с каналом вывода; PrintStream - класс, который представляет собой поток вывода, содержащий методы print() и println(). 25) Классы символьных потоков ввода и что они делают? – Reader - абстрактный класс, описывающий поток ввода символов. Этот класс есть суперклассом для всех нижеследующих подклассов; BufferedReader - класс, который описывает буферизованный поток ввода символов; CharArrayReader - класс, который реализует поток ввода, читающий символы из массива; FileReader - класс, который описывает поток ввода связанный с символьным файлом; FilterReader - класс, представляющий фильтрованный поток чтения; InputStreamReader - класс, который представляет собой поток ввода, превращающий байты в символы; LineNumberReader - класс, соответствующий потоку ввода, который подсчитывает строки; PipedReader - класс, который ассоциируется с каналом ввода; PushbackReader - класс, соответствующий потоку ввода, который позволяет возвращать символы обратно в поток ввода; StringReader - класс, который реализует поток ввода, читающий символы из строки. 26) Классы символьных потоков вывода и что они делают? – Writer - абстрактный класс, описывающий поток вывода символов. Все нижеследующие классы являются подклассами класса Writer; BufferedWriter - класс, который описывает буферизованный поток вывода символов; CharArrayWriter - класс, который соответствует потоку вывода, записывающему символы в массив; FileWriter - класс, который соответствует потоку вывода, записывающему символы в файл; FilterWriter - класс, реализующий фильтрованный поток записи; OutputStreamWriter - класс, реализующий средства преобразования символов в байты; PipedWriter - класс, который ассоциируется с каналом вывода; StringWriter - класс, который реализует поток вывода, записывающий символы в строку. 27) На каком паттерне основана иерархия потоков ввода/вывода? – Объекты классов Java, которые используются для ввода/вывода, для обеспечения необходимой функциональности наслаиваются друг на друга. Такая модель взаимодействия объектов поддерживается в паттерне «Декоратор». В этом паттерне при создании потока нужно использовать несколько объектов. Паттерн «Декоратор» позволяет динамически добавлять объекту новые обязанности, не прибегая при этом к порождению классов. При этом, работа с подобной структурой является более удобной и гибкой, нежели со множеством классов. Для этого, ссылка на декорируемый объект помещается в другой класс, называемый «Декоратором». Причем, и декоратор и декорируемый объект реализуют один и тот-же интерфейс, что позволяет вкладывать несколько декораторов друг в друга, добавляя тем самым декорируемому объекту любое число новых обязанностей. Декоратор переадресует внешние вызовы декорируему объекту сопровождая их наложением дополнительных обязанностей. 28) Как работает метод read()? – Метод read() - возвращает значение целого типа очередного символа, доступного во входном потоке; Метод read(byte arr) - метод для массового считывания данных, который считывает максимум байтов (не более arr.length) из потока, входящих данных в аргумент массива arr и возвращает фактическое количество байтов, считанных из потока. Метод read(char[] cbuf, int offset, int length) считывает данные в массив cbuf, начиная с элемента с индексом offset число length байтов максимум. 29) Как сериализовать статическое поле? – При стандартной сериализации поля, имеющие модификатор static, не сериализуются. Соответственно, после десериализации это поле значения не меняет. При использовании реализации Externalizable сериализовать и десериализовать статическое поле можно, но не рекомендуется этого делать, т.к. это может сопровождаться трудноуловимыми ошибками. 30) Можно ли сериализовать final поле? – Поля с модификатором final сериализуются как и обычные. За одним исключением - их невозможно десериализовать при использовании Externalizable, поскольку final-поля должны быть инициализированы в конструкторе, а после этого в readExternal изменить значение этого поля будет невозможно. Соответственно, если необходимо сериализовать объект с final-полем неоходимо использовать только стандартную сериализацию. 31) Клонирование Java – Чтобы окончательно сделать объект клонируемым, класс должен реализовать интерфейс Cloneable. Интерфейс Cloneable не содержит методов относится к маркерным интерфейсам, а его реализация гарантирует, что метод clone() класса Object возвратит точную копию вызвавшего его объекта с воспроизведением значений всех его полей. В противном случае метод генерирует исключение CloneNotSupportedException. Следует отметить, что при использовании этого механизма объект создается без вызова конструктора. Это решение эффективно только в случае, если поля клонируемого объекта представляют собой значения базовых типов и их обёрток или неизменяемых (immutable) объектных типов. Если же поле клонируемого типа является изменяемым ссылочным типом, то для корректного клонирования требуется другой подход. Причина заключается в том, что при создании копии поля оригинал и копия представляют собой ссылку на один и тот же объект. В этой ситуации следует также клонировать и сам объект поля класса. Такое клонирование возможно только в случае, если тип атрибута класса также реализует интерфейс Cloneable и переопределяет метод clone(). Так как, если это будет иначе вызов метода невозможен из-за его недоступности. Отсюда следует, что если класс имеет суперкласс, то для реализации механизма клонирования текущего класса-потомка необходимо наличие корректной реализации такого механизма в суперклассе. При этом следует отказаться от использования объявлений final для полей объектных типов по причине невозможности изменения их значений при реализации клонирования. Поверхностное копирование копирует настолько малую часть информации об объекте, насколько это возможно. По умолчанию, клонирование в Java является поверхностным, т.е. класс Object не знает о структуре класса, которого он копирует. Клонирование такого типа осуществляется JVM по следующим правилам: Если класс имеет только члены примитивных типов, то будет создана совершенно новая копия объекта и возвращена ссылка на этот объект. Если класс помимо членов примитивных типов содержит члены ссылочных типов, то тогда копируются ссылки на объекты этих классов. Следовательно, оба объекта будут иметь одинаковые ссылки. Глубокое копирование дублирует абсолютно всю информацию объекта: Нет необходимости копировать отдельно примитивные данные; Все члены ссылочного типа в оригинальном классе должны поддерживать клонирование. Для каждого такого члена при переопределении метода clone() должен вызываться super.clone(); Если какой-либо член класса не поддерживает клонирование, то в методе клонирования необходимо создать новый экземпляр этого класса и скопировать каждый его член со всеми атрибутами в новый объект класса, по одному. Есть 3 способа для глубокого клонирования: Переопределенный метод clone(); Сериализация Конструктор клонирования 33) Что такое «каналы»? – Каналы (channels) - это логические (не физические) порталы, абстракции объектов более низкого уровня файловой системы (например, отображенные в памяти файлы и блокировки файлов), через которые осуществляется ввод/вывод данных, а буферы являются источниками или приёмниками этих переданных данных. При организации вывода, данные, которые необходимо отправить, помещаются в буфер, который затем передается в канал. При вводе, данные из канала помещаются в заранее предоставленный буфер. Каналы напоминают трубопроводы, по которым эффективно транспортируются данные между буферами байтов и сущностями по ту сторону каналов. Каналы - это шлюзы, которые позволяют получить доступ к сервисам ввода/вывода операционной системы с минимальными накладными расходами, а буферы - внутренние конечные точки этих шлюзов, используемые для передачи и приема данных. Потоки (streams) применительно к вводу/выводу и работе с файлами. – Абстракция, которая используется для чтения или записи информации (файлов, сокетов, текста консоли и т.д.). 34) Что делает метод read? Почему он возвращает int а не byte? Почему он не может возвращать byte? – Метод читает следующий байт из входящего потока. Когда метод ничего не может считать (конец потока), возвращается -1. Потому что нужно нужен такой тип, который может вместить 1 байт, плюс одно служебное значение -1 (обозначающее конец потока). Диапазон byte в Java лежит от -128 до 127, а возвращаемое значение метода read() лежит в диапазоне от 0 до 255. 35) Что вернет метод read(), если он считывает файл и ему встречается байт равный -1? 255 38) Чем отличается копирование от клонирования. Можно ли клонировать String, массив String самым кратким: копировать: копировать в существующий экземпляр (мелкий или глубокий) clone: replicate to new instance (всегда глубокий) нет консенсуса, поскольку разработчики небрежно обмениваются ими; однако можно лоббировать вышеизложенное на основе: этимология (биология) подразумевает, что понятие "мелкого клона" бессмысленно, поскольку не генетически идентично; клонирование подразумевает полноту для распространения сущность. копирование исторически подразумевает репликацию на существующий носитель (копирование книги или картины и т. д.) Например, фотокопия копирует изображение на существующий лист бумаги; если бы можно было каким-то образом клонировать лист бумаги, результатом был бы новый лист бумаги. можно" скопировать "ссылку на объект, но никогда не "клонировать" ссылку на объект. Клонировать объекты типа String не получится, так как они immutable и не реализуют интерфейс Cloneable. По идее, массив объектов String клонировать получится, но сами объекты в нем останутся immutable. Поэтому при их изменении так или иначе будет создаваться новый объект, как обычно. 39) Как преобразовать считанные байты в символы? Какой класс для этого используется? – InputStreamReader; Массив.можно преобразовать обратно в строку с помощью конструктора «new String(byte[]) Метод «getBytes(charsetName)» класса String – преобразование char в byte 40) В чём отличие File от Path? Path, по большому счету, — это переработанный аналог класса File. Работать с ним значительно проще, чем с File. Во-первых, из него убрали многие утилитные (статические) методы, и перенесли их в класс Files. Во-вторых, в Path были упорядочены возвращаемые значения методов. В классе File методы возвращали то String, то boolean, то File — разобраться было непросто. Полезные методы Path getFileName() — возвращает имя файла из пути; getParent() — возвращает «родительскую» директорию по отношению к текущему пути (то есть ту директорию, которая находится выше по дереву каталогов); getRoot() — возвращает «корневую» директорию; то есть ту, которая находится на вершине дерева каталогов; 41) Почему важно закрывать потоки? Какие потоки можно не закрывать (не вызывать метод close())? - При закрытии потока освобождаются все выделенные для него ресурсы, например, файл. В случае, если поток окажется не закрыт, может происходить утечка памяти. Можно не закрывать промежуточные потоки, а закрыть только главные. Потоки имеют метод BaseStream. close() и реализуют AutoCloseable , но почти все экземпляры потока на самом деле не нужно закрывать после использования. Как правило, только потоки, источником которых является канал ввода-вывода 42) Что делает метод available()? - int available() - возвращает количество байтов ввода, доступные в данный момент для чтения 43) Можно ли использовать flush() для небуферизированного потока и что будет. Гарантируется ли запись данных в файл при вызове flush()? - Вообще метод flush() очищает выходной поток и заставляет записывать все буферизованные выходные байты. Общий контракт сброса заключается в том, что его вызов указывает на то, что, если какие-либо ранее записанные байты были буферизованы реализацией выходного потока, такие байты должны быть немедленно записаны в их предполагаемое место назначения. Вызов метода flush() гарантирует только то, что байты, ранее записанные в поток, передаются операционной системе для записи, но не гарантирует записи на диск. По идее ничего случиться не должно. 45) Что возвращает перегруженный read. Какое максимальное значение вернет? - int read() возвращает целочисленное представление следующего байта в потоке. Когда в потоке не останется доступных для чтения байтов, данный метод возвратит число -1. Максимальное значение 255 46) Для чего нужен Scanner? Что такое токен в Scanner? Отличие Scanner’a от BufferedReader’a? Есть ли у сканера буфер? – Класс Scanner используется для получения (считывания) данных введенных пользователем в виде String, byte, short, int, long, float, double. Сканер выполняет поиск токенов во входной строке. Токен (или маркер) представляет собой серию цифровых или буквенно-цифровых символов, которая заканчивается разделителем. Разделителем может быть символ табуляции, возврат каретки (перевод строки или же просто ‘Enter’), конец файла или пробел.Сканер неявно создает буфер, т.к. основан на интерфейсе Readable - и единственный метод в этом интерфейсе основан на буфере. Scanner работает медленно, но зато предоставляет очень широкий API с кучей удобных методов, а BufferedReader работает быстрее, потому что читает часть входных данных в буфер, откуда они быстрее читаются по частям, то есть обращение к консоли происходит реже. 47) Методы класса File? Как создать файл на компьютере с помощью java? Как удалить директорию с файлами. Что если в ней есть вложенные директории ? В чём отличие File от Path? Основные методы: createNewFile() (создает новый пустой файл с именем данного абстрактного пути), delete() (удаляет данный файл или каталог), exists() (проверяет, существует ли данный файл или каталог), 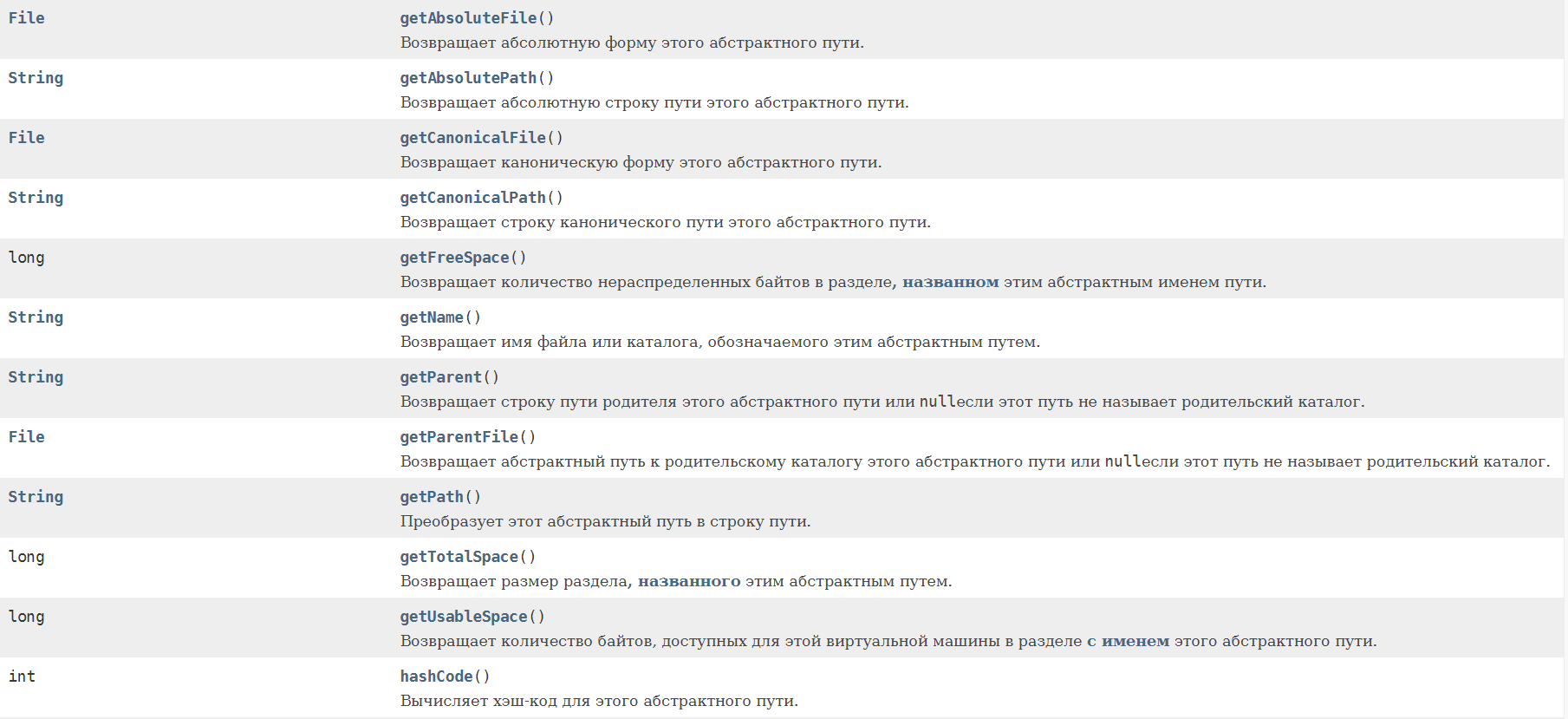 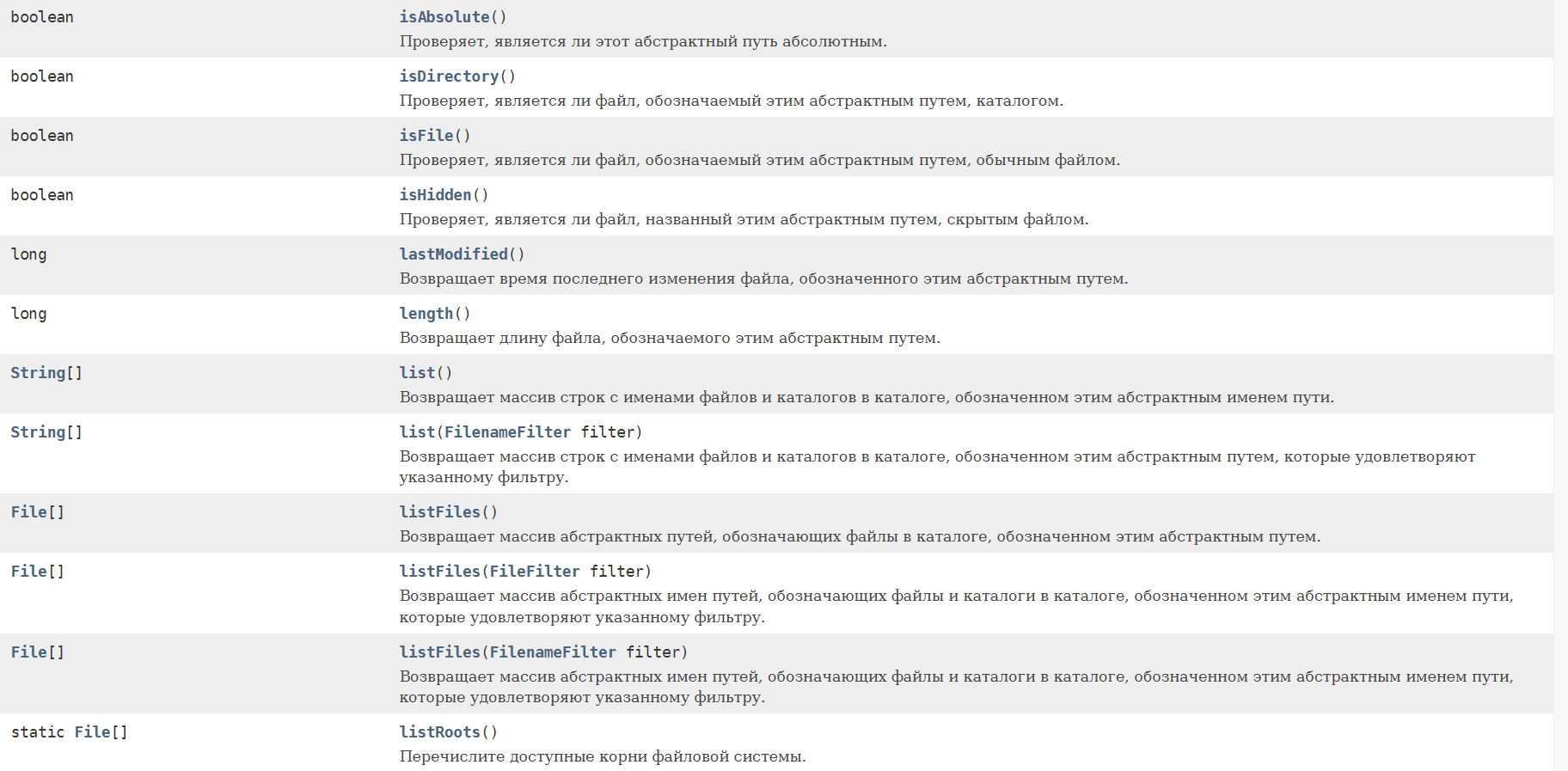  При удалении директории она должна быть пустой, иначе метод не сработает. Поэтому для удаления директорий с помощью класса File прописывают вручную рекурсивный обход. 48) Какие поля не сериализуются? При стандартной сериализации поля, имеющие модификатор static, не сериализуются. Соответственно, после десериализации это поле значения не меняет. 49) Что будет при сериализации объекта у которого есть поле и оно не Serializable? – 1) В таком случае код скомпилируется. 2) Но в рантайме при попытке сериализации , когда мы дойдем до этого поля и объекта, мы получим NotSerializableException. 50) Externalizable vs Serializable? - При записи Serializable класса весь контроль над сериализацией достается JVM. С помощью определения специальных методов можно кастомизировать его части. Метод readObject при этом обычно начинается с вызова стандартной части сериализации – ObjectInputStream.defaultReadObject(). Интерфейс Externalizable расширяет Serializable и добавляет методы записи и чтения writeExternal и readExternal. Входной и выходной потоки-аргументы в них представлены более абстрактно чем в специальных методах – интерфейсами ObjectInput и ObjectOutput. Этот интерфейс позволяет реализовать полностью свой механизм сериализации, стандартно запишется только идентификатор класса. Никакой автоматической работы с классом-родителем также не предусмотрено. Методы readObject и writeObject игнорируются. Ключевое слово transient эффекта на Externalizable не имеет. Externalizable объект в отличие от Serializable десерализуется не в обход конструктора, так что должен иметь конструктор без аргументов. 51) Какие интерфейсы реализует InputStream/ OutputStream/ Reader/ Writer? - Closeable, AutoCloseable 52) Пример адаптера и декоратора из IO? Паттерн «Адаптер», на самом деле, является одним из немногих, который программисты применяют на практике, сами того не осознавая. Адаптер можно найти, пожалуй в любой современной программой системе — будь это простое приложение или, например, Java API. Взглянем более детально на проблему, для понимая того как должен выглядеть Адаптер. Проблема, опять-таки, заключается в повторном использовании кода. Иными словами, есть клиент, который умеет работать с некоторым интерфейсом, назовем его клиентским. Есть класс, который, в принципе, делает то, что нужно клиенту но не реализует клиентский интерфейс. Безусловно, программирование нового класса довольно бессмысленная трата времени и ресурсов. Проще адаптировать уже существующий код к виду, пригодному для использования клиентом. Для этого и существует адаптер. Причем, разделяют два вида адаптеров — Object Adapter (адаптер на уровне объекта) и Class Adapter (адаптер на уровне класса). Мы рассмотри оба, но по порядку. Блок 6. Generics. Collections Что такое Generic? Обобщения — это параметризованные типы. С их помощью можно объявлять классы, интерфейсы и методы, где тип данных указан в виде параметра. Обобщения добавили в язык безопасность типов. Преимущества кода с использованием Generic по сравнению с кодом без Generic: - Более строгая проверка типов во время компиляции. - Отсутствие необходимости приведения типов. - Возможность реализации общих алгоритмов, не завязанных на конкретных типах. Что было до дженериков? До появления дженериков использовались коллекции для хранения объектов любого типа, т.е. непатентованных. Теперь универсальные шаблоны заставляют Java-программиста хранить определенный тип объектов. В частности, теперь ошибки несоответствия типов вылетают на этапе компиляции, а не в runtime. Что можно поставить в дженерики, что нельзя? Что можно типизировать? Что нельзя параметризировать? Можно типизировать только ссылочные типы. Нельзя типизировать примитивные типы. Невозможно объявить статические поля, типы которых являются параметрами типа. Невозможно использовать приведение или instanceof с параметризованными типами. Что такое WildCard и всё что с ними связано? Wildcard — это дженерик вида , что означает, что тип может быть чем угодно. Используется, например, в коллекциях, где для всех коллекций базовым типом является Сollection.    Что такое PECS ? «Producer-Extends Consumer-Super». Как объясняется в многочисленных статьях, если у нас есть некая коллекция, типизированная wildcard верхней границей (extends) – то это, «продюсер». «Он только «продюсирует», предоставляет элемент из контейнера, а сам ничего не принимает». Если же у нас коллекция, типизированная wildcard по нижней границе (super) – то это, «потребитель», который «только принимает, а предоставить ничего не может». Что такое даймонд оператор? Что такое raw type? К чему приводит использование raw type? Стирание типов? Что такое стирание и сырые типы? Основная цель diamoind <> оператора упростить использование универсальных шаблонов при создании объекта . Это позволяет избежать непроверенных предупреждений в программе и делает программу более читаемой. Raw Types (сырые типы) – Это имя универсального класса или интерфейса без каких-либо аргументов типа. их нужно избегать. Пример сырого типа List <> list = new ArrayList<>; Пример нормального типа List Стирание типов - во время компиляции компилятор имеет полную информацию о типе, но эта информация обычно намеренно отбрасывается при создании байтового кода в процессе, известном как стирание типов. Это делается таким образом из-за проблем совместимости: целью разработчиков языка было обеспечение полной совместимости исходного кода и полной совместимости байтового кода между версиями платформы. Если бы он был реализован по-другому, вам пришлось бы перекомпилировать устаревшие приложения при переходе на более новые версии платформы. Если поле типизировано дженериком, то как в байт коде будет представлен этот тип? Будет представлен как экземпляр Object. В чем отличие в записях в параметре метода: (Collection collection) и ((Collection collection)? В первом случае вместо мы можем подставить абсолютно любой тип, а во втором только T и его наследников. Параметр vs Аргумент (в дженериках)? Параметр типа (type parameter). Используются при объявлении дженерик-типов. Например, для Box Аргумент типа (type argument). Тип объекта, который может использоваться вместо параметра типа. Например, для Box Paper — это аргумент типа. Статические методы как они типизируются Collection? Как параметризовать статический метод? Generic-поля не могут быть статическими, статические методы не могут иметь generic-параметры или обращаться к generic-полям. Параметризация в классе используется для параметризации его экземпляров, а поэтому недоступна в статических методах. Но статические методы можно параметризовать отдельно от класса, прописав после модификатора static параметризованный тип, а после возвращаемое значение. Пример: public static Какие структуры данных вы знаете? Простыми словами, структура данных – это контейнер, который хранит информацию в определенном виде. Из-за такой «компоновки» она может быть эффективной в одних операциях и неэффективной в других. Цель разработчика – выбрать из существующих структур оптимальный для конкретной задачи вариант. |