6 Дженерики, коллекции. Что такое дженерики
 Скачать 360 Kb. Скачать 360 Kb.
|

|
Значение, которое кладется в HashSet кладется на место ключа или значения внутренней мапы? На место ключа. На место значения кладется экземпляр (new Object()). Как работает метод contains в HashSet Цель метода contains состоит в том, чтобы проверить, присутствует ли элемент в данном HashSet. Он возвращает true если элемент найден, в противном случае false. Null в TreeSet Документация по TreeSet#add в Java 7 гласит: NullPointerException - если указанный элемент имеет значение null и этот набор использует естественный порядок или его компаратор не разрешает пустые элементы Таким образом, поскольку вы не указали пользовательскую реализацию компаратора, которая может обрабатывать нулевые значения, вы получаете NPE. Еще одно отличие состоит в том, что HashSet может хранить нулевые объекты, а TreeSet их не позволяет. Если мы попытаемся сохранить нулевой объект в TreeSet , операция приведет к выброшенному исключению NullPointerException . Единственное исключение было в Java 7, когда в TreeSet разрешалось иметь ровно один нулевой элемент Чем Set отличается от List Set не добавляет новых методов, только вносит изменения унаследованные. В частности, метод add() добавляет элемент в коллекцию и возвращает true, если не было такого элемента. Разрешено наличие только одной ссылки типа null." В чем отличия TreeSet и HashSet? HashSet быстрее, чем TreeSet В HashSet элементы в случайном порядке, в TreeSet в отсортированном. HashSet обеспечивает постоянную производительность - О(1) - для большинства операций, таких как add () , remove () и contains () , по сравнению с временем log(n), предлагаемым TreeSet." Map - интерфейс также находится в составе JDK c версии 1.2 и предоставляет базовые методы для работы с данными вида «ключ — значение». Также как и Collection, он был дополнен дженериками в версии Java 1.5. 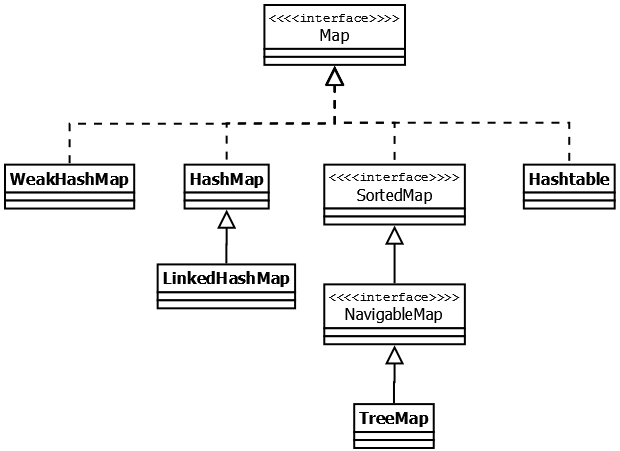 Hashtable — реализация такой структуры данных, как хэш-таблица. Она не позволяет использовать null в качестве значения или ключа. Эта коллекция была реализована раньше, чем Java Collection Framework, но в последствии была включена в его состав. Hashtable является синхронизированной (почти все методы помечены как synchronized). Из-за этой особенности у неё имеются существенные проблемы с производительностью. HashMap — коллекция является альтернативой Hashtable. Двумя основными отличиями от Hashtable являются то, что HashMap не синхронизирована и HashMap позволяет использовать null как в качестве ключа, так и значения. Так же как и Hashtable, данная коллекция не является упорядоченной: порядок хранения элементов зависит от хэш-функции. LinkedHashMap — это упорядоченная реализация хэш-таблицы. Здесь, в отличии от HashMap, порядок итерирования равен порядку добавления элементов. Данная особенность достигается благодаря двунаправленным связям между элементами (аналогично LinkedList). Но это преимущество имеет также и недостаток — увеличение памяти, которое занимает коллекция. TreeMap — реализация Map основанная на красно-чёрных деревьях. Как и LinkedHashMap является упорядоченной. По-умолчанию, коллекция сортируется по ключам с использованием принципа "natural ordering", но это поведение может быть настроено под конкретную задачу при помощи объекта Comparator, который указывается в качестве параметра при создании объекта TreeMap. WeakHashMap — реализация хэш-таблицы, которая организована с использованием weak references. Другими словами, Garbage Collector автоматически удалит элемент из коллекции при следующей сборке мусора, если на ключ этого элеметна нет жёстких ссылок. Что такое Map Map — это структура данных, которая содержит набор пар “ключ-значение”. По своей структуре данных напоминает словарь, поэтому ее часто так и называют. В то же время, Map является интерфейсом, и содержит основные реализации: Hashmap, LinkedHashMap, Hashtable, TreeMap. Что должно быть уникальным в Map ключ Почему Map не входит в Collection? Map – пара ключ/значение, тогда как Collection представляет собой набор группы объектов, хранящихся в структурированном виде, и имеет определенный механизм доступа. Причина, по которой карта не расширяет интерфейс Collections, заключается в том, что add(E e) не поддерживает пару ключевых значений, например Map put(K, V). Строение HashMap что внутри Node "HashMap – внутри состоит из корзин и списка элементов, на которые ссылаются корзины. Корзины – массив Элементы (Node) – связанный список, то есть каждый элемент списка имеет указатель на следующий элемент. При добавлении нового элемента, хэш-код ключа определяет корзину для элемента с помощью hashFunction(), который принимает hashCode ключа и возвращает номер корзины. В корзине есть ссылка на связанный список, в который будет положен наш объект. Идет проверка, есть ли элементы в этом списке. Если нету, то корзина получает ссылку нового элемента, если есть, то происходит прохождение по списку элементов и сравнивание элементов в списке. Проверяется равенство hashcode. Зная о коллизии, проводится еще сравнивание ключей методом equals. Если оба равны: идет перезапись Если не равен equals: добавляется элемент в конец списка Как расширяется HashMap По мере увеличения количества элементов в HashMap емкость расширяется. HashMap имеет поле loadFactor. Оно может быть задано через конструктор. По умолчанию - 0.75. Его произведение на количество корзин дает нам необходимое число объектов которое нужно добавить чтобы состоялось удвоение количества корзин. Например если у нас мапка с 16-ю(default) корзинами, а loadFactor равняется 0.75, то расширение произойдет когда мы добавим 16 * 0.75 = 12 объектов. После удвоения все объекты будут перераспределены с учетом нового количества корзин " Как работает HashMap. HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек. Объект HashMap имеет ряд основных свойств: • table — Массив типа Entry[], который является хранилищем ссылок на списки (цепочки) значений (также называют bucket’ом); • loadFactor — Коэффициент загрузки. Значение по умолчанию 0.75 является хорошим компромиссом между временем доступа и объемом хранимых данных; • threshold — Предельное количество элементов, при достижении которого, размер хэш-таблицы увеличивается вдвое. Рассчитывается по формуле (capacity * loadFactor); • size — Количество элементов HashMap-а; В конструкторе происходит проверка валидности переданных параметров и установка значений соответствующих свойств объекта. (capacity по умолчанию имеет размер 16). Как работает метод get в HashMap. Аналогично put вычисляется для ключа hash и номер элемента массива и выполняется обход хранящегося в нем списка и при нахождении соответствия hash и ключу возвращается value, при не нахождении возвращается null. Какой хэш-код у null в HashMap Хэш код null равен 0 Может ли null быть ключом в HashMap. Может, элемент будет сохранен или перезаписан. Хэш-код будет равен 0. null допускается как в ключе (будет только одна пара с таким ключом), так и в значении; Детальная работа метода put (key, value) в HashMap 1. Вычисляется хэш ключа. Если ключ null, хэш считается равным 0. Чтобы достичь лучшего распределения, результат вызова hashCode() «перемешивается»: его старшие биты XOR-ятся на младшие. 2. Значения внутри хэш-таблицы хранятся в специальных структурах данных – нодах, в массиве. Из хэша высчитывается номер бакета – индекс для значения в этом массиве. Полученный хэш обрезается по текущей длине массива. Длина – всегда степень двойки, так что для скорости используется битовая операция &. 3. В бакете ищется нода. В ячейке массива лежит не просто одна нода, а связка всех нод, которые туда попали. Исполнение проходит по этой связке (цепочке или дереву), и ищет ноду с таким же ключом. Ключ сравнивается с имеющимися сначала на ==, затем на equals. 4. Если нода найдена – её значение просто заменяется новым. Работа метода на этом завершается. 5. Если ноды с таким же ключом в бакете пока нет – добавляемая пара ключ-значение запаковывается в новый объект типа Node, и прикрепляется к структуре существующих нод бакета. Ноды составляют структуру за счет того, что в ноде хранится ссылка на следующий элемент (для дерева – следующие элементы). Кроме самой пары и ссылок, чтобы потом не считать заново, записывается и хэш ключа. 6. В случае, когда структурой была цепочка а не дерево, и длина цепочки превысила 7 элементов – происходит процедура treeification – превращение списка в самобалансирующееся дерево. В случае коллизии это ускоряет доступ к элементам на чтение с O(n) до O(log(n)). У comparable-ключей для балансировки используется их естественный порядок. Другие ключи балансируются по порядку имен их классов и значениям identityHashCode-ов. Для маленьких хэш-таблиц (< 64 бакетов) «одеревенение» заменяется увеличением (см. п.8). 7. Если новая нода попала в пустую ячейку, заняла новый бакет – увеличивается счетчик структурных модификаций. Изменение этого счетчика сообщит всем итераторам контейнера, что при следующем обращении они должны выбросить ConcurrentModificationException. 8. Когда количество занятых бакетов массива превысило пороговое (capacity * load factor), внутренний массив увеличивается вдвое, а для всего содержимого выполняется рехэш – все имеющиеся ноды перераспределяются по бакетам по тем же правилам, но уже с учетом нового размера. Что такое коллизия Коллизия это когда два разных объекта попадают в одну корзинку(связанный список). Причиной этому служат то, что они имеют одинаковый hashcode. Для более эффективной работы с HashMap hashcode не должен повторяться для не эквивалентных объектов 2 причины коллизии 1. Этот сценарий может возникнуть из-за того, что в соответствии с контрактом equals и hashCode два неравных объекта в Java могут иметь одинаковый хэш-код . 2. Это также может произойти из-за конечного размера базового массива, то есть до изменения размера. Чем меньше этот массив, тем выше вероятность столкновения. Проще говоря, когда количество записей в хеш-таблице превышает пороговое значение, Карта повторно хешируется так, что она имеет примерно вдвое больше сегментов, чем раньше. Коллизия возникает, когда хеш-функция возвращает одно и то же местоположение корзины для двух разных ключей. Что происходит при коллизии Коллизия,или, точнее, коллизия хэш-кода в HashMap , — это ситуация, когда два или более ключевых объекта создают одно и то же конечное хеш-значение и, следовательно, указывают на одно и то же местоположение корзины или индекс массива. Имейте в виду, что значение хеш-функции ключа определяет корзину, в которой будет храниться объект. Таким образом, если хэш-коды любых двух ключей сталкиваются, их записи все равно будут храниться в одной и той же корзине. Как будет разрешаться коллизия При возникновении коллизии, происходит поиск некоторой свободной ячейки, куда и добавляется очередной элемент. ● external chaining или метод цепочек (реализован в HashMap) — Осуществляется добавление нового элемента в этот список. ● linear probing или метод открытой адресации (реализован в IdentityHashMap) – заключается в поиске первой пустой ячейки после той, на которую указала хеш-функция Как обойти HashMap через for-each? Методы entrySet;Values(); keyset() Что такое бинарное дерево поиска (BST) Бинарное дерево – иерархическая упорядоченная структура данных, состоящая из узлов и связей между ними, каждый узел имеет не более 2х сыновей (потомков – левого и первого). Узлы без потомков принято называть листьями. Применяется для реализации множеств и ассоциативных массивов (TreeSet, TreeMap). * Элементы, хранящиеся в данных структурах, должны быть Comparable или в самой структуре должен быть реализован comparatror для сравнения этих элементов. Главное правило распределения по таким деревьям: в левом поддереве от рассматриваемого узла должны храниться ключи «меньшие», а в правом – «большие». Новый элемент при вставлении становится сыном для листа после прохождения и сравнения узлов от корня дерева до этого листа. При удалении возможно два случая: 1) когда у узла один потомок, тогда этот узел просто убирается, а на его место встает потомок со своим поддеревом. 2). Когда у узла два потомка, тогда находится минимальный узел у правого потомка и ставится на место удаляемого узла. Такая структура ускоряет алгоритм поиска элемента (O(log(n)) в оптимальном случае, когда глубина одинаковая). *такие деревья не являются сбалансированными и в худшем случае (при последовательном добавлении только больших или только меньших элементов) могут выродиться и сложность операций с таким деревом станет как у обычного списка O(n) Красно-чёрные деревья 5 свойств Красно-черные деревья относятся к сбалансированным бинарным деревьям поиска. Как бинарное дерево, красно-черное обладает свойствами: 1) Все поддеревья являются бинарными деревьями поиска. 2) Для каждого узла с ключом выполняется критерий упорядочения: ключи всех левых потомков < ключ < ключи всех правых потомков Свойства красно-черных деревьев: 1) Каждый узел окрашен либо в красный, либо в черный цвет (в структуре данных узла появляется дополнительное поле – бит цвета). 2) Корень окрашен в черный цвет. 3) Листья (так называемые NULL-узлы) окрашены в черный цвет. 4) Красные узлы в качестве дочерних могут иметь только черные. Черный узел может иметь любые дочерние узлы. Новые узлы добавляются на места листьев. 5) Пути от узла к его листьям должны содержать одинаковое количество черных узлов (это черная высота - глубина). *Действительно, красно-черные деревья не гарантируют строгой сбалансированности (разница высот двух поддеревьев любого узла не должна превышать 1). Но соблюдение свойств красно-черного дерева позволяет обеспечить выполнение операций вставки, удаления и выборки за время O(log(n)). При каких условиях в HashMap лист преобразуется в красно-черное дерево? Когда длина цепи более 8, список превращаются в красно-черное дерево. (При наличии более 8 записей в одном бакете и общее количество бакетов более 64) Условия перестраивания HashMap в красно-чёрное дерево. 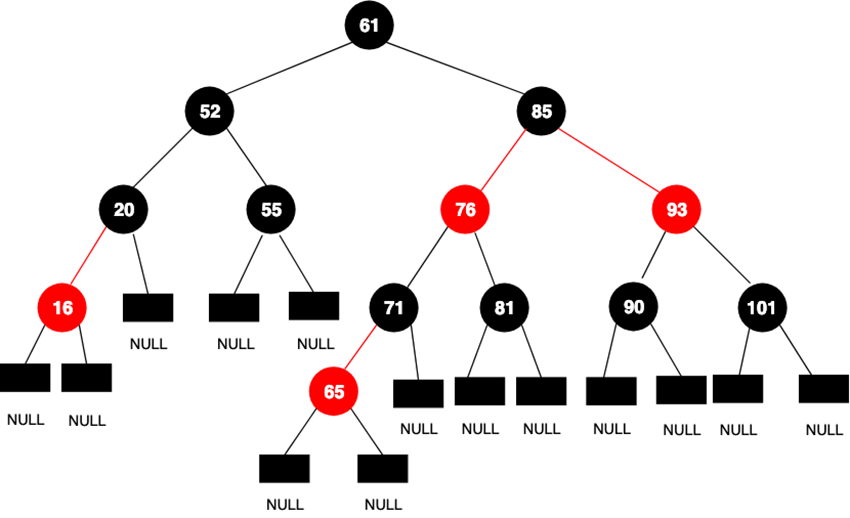 При наличии не менее 8 записей (TREEIFY_THRESHOLD) в одном бакете и общее количество бакетов более 64 (MIN_TREEIFY_CAPACITY). Красно-черное дерево само себя балансирует по формуле log от n. Интерфейс List 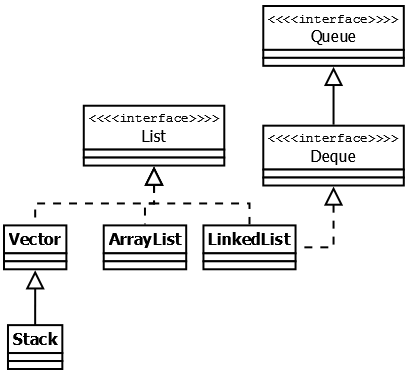 Реализации этого интерфейса представляют собой упорядоченные коллекции. Кроме того, разработчику предоставляется возможность доступа к элементам коллекции по индексу и по значению (так как реализации позволяют хранить дубликаты, результатом поиска по значению будет первое найденное вхождение). Vector — реализация динамического массива объектов. Позволяет хранить любые данные, включая null в качестве элемента. Vector появился в JDK версии Java 1.0, но как и Hashtable, эту коллекцию не рекомендуется использовать, если не требуется достижения потокобезопасности. Потому как в Vector, в отличии от других реализаций List, все операции с данными являются синхронизированными. В качестве альтернативы часто применяется аналог — ArrayList. Stack — данная коллекция является расширением коллекции Vector. Была добавлена в Java 1.0 как реализация стека LIFO (last-in-first-out). Является частично синхронизированной коллекцией (кроме метода добавления push()). После добавления в Java 1.6 интерфейса Deque, рекомендуется использовать именно реализации этого интерфейса, например ArrayDeque. ArrayList — как и Vector является реализацией динамического массива объектов. Позволяет хранить любые данные, включая null в качестве элемента. Как можно догадаться из названия, его реализация основана на обычном массиве. Данную реализацию следует применять, если в процессе работы с коллекцией предпалагается частое обращение к элементам по индексу. Из-за особенностей реализации поиндексное обращение к элементам выполняется за константное время O(1). Но данную коллекцию рекомендуется избегать, если требуется частое удаление/добавление элементов в середину коллекции. LinkedList — ещё одна реализация List. Позволяет хранить любые данные, включая null. Особенностью реализации данной коллекции является то, что в её основе лежит двунаправленный связный список (каждый элемент имеет ссылку на предыдущий и следующий). Благодаря этому, добавление и удаление из середины, доступ по индексу, значению происходит за линейное время O(n), а из начала и конца за константное O(1). |