Вопросы по SQL. Вопросы по SQL с собеседований. Delete truncate
 Скачать 120.37 Kb. Скачать 120.37 Kb.
|

|
Вопросы по SQL с собеседований Вопрос 1. В чем разница между операторами DELETE и TRUNCATE?
№ Вопрос 2. Из каких подмножеств состоит SQL? DDL (Data Definition Language, язык описания данных) — позволяет выполнять различные операции с базой данных, такие как CREATE (создание), ALTER (изменение) и DROP (удаление объектов). DML (Data Manipulation Language, язык управления данными) — позволяет получать доступ к данным и манипулировать ими, например, вставлять, обновлять, удалять и извлекать данные из базы данных. DCL (Data Control Language, язык контролирования данных) — позволяет контролировать доступ к базе данных. Пример — GRANT (предоставить права), REVOKE (отозвать права). Вопрос 3. Что подразумевается под СУБД? Какие существуют типы СУБД? База данных — структурированная коллекция данных. Система управления базами данных (СУБД) — программное обеспечение, которое взаимодействует с пользователем, приложениями и самой базой данных для сбора и анализа данных. СУБД позволяет пользователю взаимодействовать с базой данных. Данные, хранящиеся в базе данных, могут быть изменены, извлечены и удалены. Они могут быть любых типов, таких как строки, числа, изображения и т. д. Существует два типа СУБД: Реляционная система управления базами данных: данные хранятся в отношениях (таблицах). Пример — MySQL. Нереляционная система управления базами данных: не существует понятия отношений, кортежей и атрибутов. Пример — Mongo. Вопрос 4. Что подразумевается под таблицей и полем в SQL? Таблица — организованный набор данных в виде строк и столбцов. Поле — это столбцы в таблице. Например: Таблица: Student_Information Поле: Stu_Id, Stu_Name, Stu_Marks Вопрос 5. Что такое соединения в SQL? Для соединения строк из двух или более таблиц на основе связанного между ними столбца используется оператор JOIN. Он используется для объединения двух таблиц или получения данных оттуда. В SQL есть 4 типа соединения, а именно: Inner Join (Внутреннее соединение) Right Join (Правое соединение) Left Join (Левое соединение) Full Join (Полное соединение) Вопрос 6. В чем разница между типом данных CHAR и VARCHAR в SQL? И Char, и Varchar служат символьными типами данных, но varchar используется для строк символов переменной длины, тогда как Char используется для строк фиксированной длины. Например, char(10) может хранить только 10 символов и не сможет хранить строку любой другой длины, тогда как varchar(10) может хранить строку любой длины до 10, т.е. например 6, 8 или 2. Вопрос 7. Что такое первичный ключ (Primary key)? 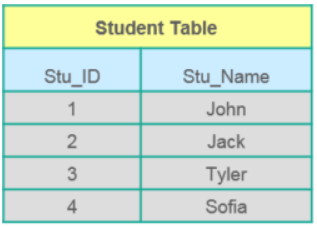 Первичный ключ — столбец или набор столбцов, которые однозначно идентифицируют каждую строку в таблице. Однозначно идентифицирует одну строку в таблице Нулевые (Null) значения не допускаются _Пример: в таблице Student StuID является первичным ключом. Вопрос 8. Что такое ограничения (Constraints)? Ограничения (constraints) используются для указания ограничения на тип данных таблицы. Они могут быть указаны при создании или изменении таблицы. Пример ограничений: NOT NULL CHECK DEFAULT UNIQUE PRIMARY KEY FOREIGN KEY Вопрос 9. В чем разница между SQL и MySQL? SQL — стандартный язык структурированных запросов (Structured Query Language) на основе английского языка, тогда как MySQL — система управления базами данных. SQL — язык реляционной базы данных, который используется для доступа и управления данными, MySQL — реляционная СУБД (система управления базами данных), также как и SQL Server, Informix и т. д. Вопрос 10. Что такое уникальный ключ (Unique key)? Однозначно идентифицирует одну строку в таблице. Допустимо множество уникальных ключей в одной таблице. Допустимы NULL-значения (прим. перевод.: зависит от СУБД, в SQL Server значение NULL может быть добавлено только один раз в поле с UNIQUE KEY). Вопрос 11. Что такое внешний ключ (Foreign key)? Внешний ключ поддерживает ссылочную целостность, обеспечивая связь между данными в двух таблицах. Внешний ключ в дочерней таблице ссылается на первичный ключ в родительской таблице. Ограничение внешнего ключа предотвращает действия, которые разрушают связи между дочерней и родительской таблицами. Вопрос 12. Что подразумевается под целостностью данных? Целостность данных определяет точность, а также согласованность данных, хранящихся в базе данных. Она также определяет ограничения целостности для обеспечения соблюдения бизнес-правил для данных, когда они вводятся в приложение или базу данных. Вопрос 13. В чем разница между кластеризованным и некластеризованным индексами в SQL? Различия между кластеризованным и некластеризованным индексами в SQL: Кластерный индекс используется для простого и быстрого извлечения данных из базы данных, тогда как чтение из некластеризованного индекса происходит относительно медленнее. Кластеризованный индекс изменяет способ хранения записей в базе данных — он сортирует строки по столбцу, который установлен как кластеризованный индекс, тогда как в некластеризованном индексе он не меняет способ хранения, но создает отдельный объект внутри таблицы, который указывает на исходные строки таблицы при поиске. Одна таблица может иметь только один кластеризованный индекс, тогда как некластеризованных у нее может быть много. Вопрос 14. Напишите SQL-запрос для отображения текущей даты. В SQL есть встроенная функция GetDate (), которая помогает возвращать текущий timestamp/дату. Вопрос 15. Перечислите типы соединений Существуют различные типы соединений, которые используются для извлечения данных между таблицами. Принципиально они делятся на четыре типа, а именно: 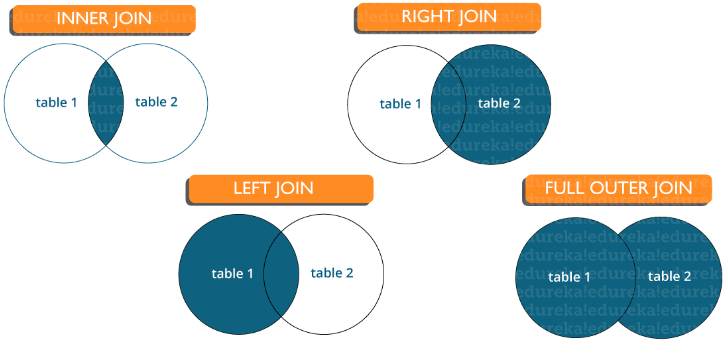 Inner join (Внутреннее соединение): в MySQL является наиболее распространенным типом. Оно используется для возврата всех строк из нескольких таблиц, для которых выполняется условие соединения. Left Join (Левое соединение): в MySQL используется для возврата всех строк из левой (первой) таблицы и только совпадающих строк из правой (второй) таблицы, для которых выполняется условие соединения. Right Join (Правое соединение): в MySQL используется для возврата всех строк из правой (второй) таблицы и только совпадающих строк из левой (первой) таблицы, для которых выполняется условие соединения. Full Join (Полное соединение): возвращает все записи, для которых есть совпадение в любой из таблиц. Следовательно, он возвращает все строки из левой таблицы и все строки из правой таблицы. Вопрос 16. Что вы подразумеваете под денормализацией? Денормализация — техника, которая используется для преобразования из высших к низшим нормальным формам. Она помогает разработчикам баз данных повысить производительность всей инфраструктуры, поскольку вносит избыточность в таблицу. Она добавляет избыточные данные в таблицу, учитывая частые запросы к базе данных, которые объединяют данные из разных таблиц в одну таблицу. Вопрос 17. Что такое сущности и отношения? Сущности: человек, место или объект в реальном мире, данные о которых могут храниться в базе данных. В таблицах хранятся данные, которые представляют один тип сущности. Например — база данных банка имеет таблицу клиентов для хранения информации о клиентах. Таблица клиентов хранит эту информацию в виде набора атрибутов (столбцы в таблице) для каждого клиента. Отношения: отношения или связи между сущностями, которые имеют какое-то отношение друг к другу. Например — имя клиента связано с номером учетной записи клиента и контактной информацией, которая может быть в той же таблице. Также могут быть отношения между отдельными таблицами (например, клиент к счетам). Вопрос 18. Что такое индекс? Индексы относятся к методу настройки производительности, позволяющему быстрее извлекать записи из таблицы. Индекс создает отдельную структуру для индексируемого поля и, следовательно, позволяет быстрее получать данные. Вопрос 19. Опишите различные типы индексов. Есть три типа индексов, а именно: Уникальный индекс (Unique Index): этот индекс не позволяет полю иметь повторяющиеся значения, если столбец индексируется уникально. Если первичный ключ определен, уникальный индекс может быть применен автоматически. Кластеризованный индекс (Clustered Index): этот индекс меняет физический порядок таблицы и выполняет поиск на основе значений ключа. Каждая таблица может иметь только один кластеризованный индекс. Некластеризованный индекс (Non-Clustered Index): не изменяет физический порядок таблицы и поддерживает логический порядок данных. Каждая таблица может иметь много некластеризованных индексов. Вопрос 20. Что такое нормализация и каковы ее преимущества? Нормализация — процесс организации данных, цель которого избежать дублирования и избыточности. Некоторые из преимуществ: Лучшая организация базы данных Больше таблиц с небольшими строками Эффективный доступ к данным Большая гибкость для запросов Быстрый поиск информации Проще реализовать безопасность данных Позволяет легко модифицировать Сокращение избыточных и дублирующихся данных Более компактная база данных Обеспечивает согласованность данных после внесения изменений Вопрос 21. В чем разница между командами DROP и TRUNCATE? Команда DROP удаляет саму таблицу, и нельзя сделать Rollback команды, тогда как команда TRUNCATE удаляет все строки из таблицы (прим. перевод.: в SQL Server Rollback нормально отработает и откатит DROP). Вопрос 22. Объясните различные типы нормализации. Существует много последовательных уровней нормализации. Это так называемые нормальные формы. Каждая последующая нормальная форма включает предыдущую. Первых трех нормальных форм обычно достаточно. Первая нормальная форма (1NF) — нет повторяющихся групп в строках Вторая нормальная форма (2NF) — каждое неключевое (поддерживающее) значение столбца зависит от всего первичного ключа Третья нормальная форма (3NF) — каждое неключевое значение зависит только от первичного ключа и не имеет зависимости от другого неключевого значения столбца Вопрос 23. Что такое свойство ACID в базе данных? ACID означает атомарность (Atomicity), согласованность (Consistency), изолированность (Isolation), долговечность (Durability). Он используется для обеспечения надежной обработки транзакций данных в системе базы данных. Атомарность. Гарантирует, что транзакция будет полностью выполнена или потерпит неудачу, где транзакция представляет одну логическую операцию данных. Это означает, что при сбое одной части любой транзакции происходит сбой всей транзакции и состояние базы данных остается неизменным. Согласованность. Гарантирует, что данные должны соответствовать всем правилам валидации. Проще говоря, вы можете сказать, что ваша транзакция никогда не оставит вашу базу данных в недопустимом состоянии. Изолированность. Основной целью изолированности является контроль механизма параллельного изменения данных. Долговечность. Долговечность подразумевает, что если транзакция была подтверждена (COMMIT), произошедшие в рамках транзакции изменения сохранятся независимо от того, что может встать у них на пути (например, потеря питания, сбой или ошибки любого рода). Вопрос 24. Что вы подразумеваете под «триггером» в SQL? Триггер в SQL — особый тип хранимых процедур, которые предназначены для автоматического выполнения в момент или после изменения данных. Это позволяет вам выполнить пакет кода, когда вставка, обновление или любой другой запрос выполняется к определенной таблице. Вопрос 25. Какие операторы доступны в SQL? В SQL доступно три типа оператора, а именно: Арифметические Операторы Логические Операторы Операторы сравнения Вопрос 26. Совпадают ли значения NULL со значениями нуля или пробела? Значение NULL вовсе не равно нулю или пробелу. Значение NULL представляет значение, которое недоступно, неизвестно, присвоено или неприменимо, тогда как ноль — это число, а пробел — символ. Вопрос 27. В чем разница между перекрестным (cross join) и естественным (natural join) соединением? Перекрестное соединение создает перекрестное или декартово произведение двух таблиц, тогда как естественное соединение основано на всех столбцах, имеющих одинаковое имя и типы данных в обеих таблицах. Вопрос 28. Что такое подзапрос в SQL? Подзапрос — это запрос внутри другого запроса, в котором определен запрос для извлечения данных или информации из базы данных. В подзапросе внешний запрос называется основным запросом, тогда как внутренний запрос называется подзапросом. Подзапросы всегда выполняются первыми, а результат подзапроса передается в основной запрос. Он может быть вложен в SELECT, UPDATE или любой другой запрос. Подзапрос также может использовать любые операторы сравнения, такие как >, < или =. Вопрос 29. Какие бывают типы подзапросов? Существует два типа подзапросов, а именно: коррелированные и некоррелированные. Коррелированный подзапрос: это запрос, который выбирает данные из таблицы со ссылкой на внешний запрос. Он не считается независимым запросом, поскольку ссылается на другую таблицу или столбец в таблице. Некоррелированный подзапрос: этот запрос является независимым запросом, в котором выходные данные подзапроса подставляются в основной запрос. Вопрос 30. Перечислите способы получить количество записей в таблице? Для подсчета количества записей в таблице вы можете использовать следующие команды: SELECT * FROM table1 SELECT COUNT(*) FROM table1 SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2 Ещё 35 вопросов с ответами опубликуем в следующей части… Следите за новостями! Теги: SQL Oracle MS SQL Server MySQL DELETE и TRUNCATE подмножества SQL DDL DML DCL СУБД объединения в SQL Inner Join Right Join Left Join Full Join CHAR и VARCHAR2 Primary key Constraints Unique key Foreign key Денормализация Unique Index Clustered Index Non-Clustered Index DROP и TRUNCATE свойство ACID в БД |