Разбор первой сессии. Диаграммы er соответствует требованиям 1
 Скачать 249.43 Kb. Скачать 249.43 Kb.
|

|
Здравствуйте. Сегодня решил сделать первую сессию информационной системы «Лопушок». Начну сразу с критериев оценивания и с того, что вообще надо сделать. Читая предметную область и понимаю, что информационная система «Лопушок» это про тебя, понимаешь, что надо переходить сразу во введение. Там сказано, что надо всего лишь создать подсистему для работы с продукцией: просмотр списка продукции, добавление/удаление/редактирование данных о продукции, управление списком материалов, необходимых для производства продукции. То е Дизайн базы данных ERD Название диаграммы ER соответствует требованиям 0.1 Основные сущности определены 1.2 Минус 20% за каждую ошибку Отношения определены правильно с учетом отсутствующих объектов 1 Минус 20% за каждую ошибку Все атрибуты (поля) рассмотрены и определены 2 Минус 20% за каждую ошибку Созданы ограничения на связи между сущностей, отражающие характер предметной области 0.5 Минус 30% за каждую ошибку Идентификатор в таблице присутствует 0.3 Минус 20% за каждую ошибку Разработанная база данных находится в 3НФ (при наличии минимального необходимого набора) 0.9 Минус 0.3 балла за НФ Дизайн базы данных Таблицы и поля названы в соответствии с индустриальными стандартами Импорт данных Все данные загружены верно и в правильном формате 2 Замечание: не сказано каким образом загружены Минус 10% за каждые 10% незагруженных данных Все данные о материалах для изготовления продукции загружены верно и в правильном формате 2 Минус 10% за каждые 10% незагруженных данных Все данные о материалах загружены верно и в правильном формате 1 Минус 10% за каждые 10% незагруженных данных Вопрос: как загрузить не в правильном формате? Разработка базы данных Созданы таблицы необходимые для описанной подсистемы и реализуемого функционала 0.5 Минус 20% за каждую ошибку Созданы поля в таблицах 0.6 Минус 20% за каждую ошибку Созданы типы данных полей 0.7 Минус 20% за каждую ошибку Созданы связи между таблицами 0.5 Минус 20% за каждую ошибку Созданы первичные ключи Минус 50% за каждую ошибку То есть анализируя папку импорт можно прийти к выводу, что и какие таблицы нам нужны, а также какие связи существуют в подсистеме. 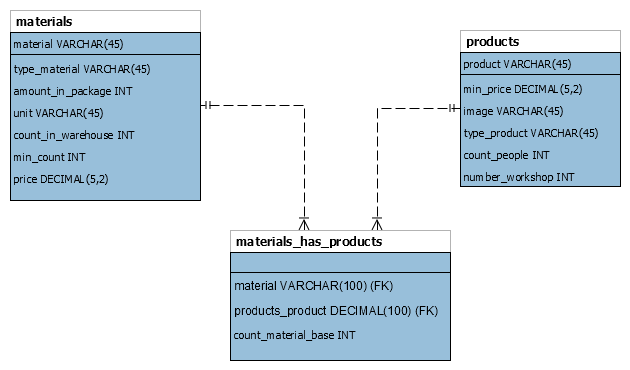 Рис. 1. Диаграмма На рисунке 1 показана ERD – диаграмма, которая построена по анализу импорта исходных данных. Сразу видно, что тут нет стандартного идентификатора id, который обычно принято делать для удобства. Фрагмент исходных данных для связи таблиц materials и products говорит о том, что эти таблицы находятся в связи многие ко многим и целесообразней использовать в таких случаях автоикрементный id вместо полного названия первичных ключей продуктов и материалов. Но тут у нас возникает проблема, что таблицы не находится в 3 нормальной форме. Она даже не находится в первой нормальной форме (значения в первичном ключе не атомарные). Если мы будет уходить в такой модели построения таблицы (например, декомпозицией или сделаем составной первичный ключ), то нам придется менять структуру исходных данных, которые надо импортировать. По этой же причине мы не может сделать соединяющую таблицу из id, так как придется самим делать исходные данные по тем исходным данным, которые уже у нас есть.  Рисунок 2 – Фрагмент исходных данных для соединяющей таблицы Таким образом мы либо значительно усложним себе задачу, чтобы довести таблицы и исходные данные до 3НФ, либо потеряем специально 0.9 балла. Напомню, что критерий выглядит так: разработанная база данных находится в 3НФ (при наличии минимального необходимого набора). Минус 0.3 балла за НФ. Минимальный набор – это и есть те таблицы, исходные данные для которых представлены в первой сессии. Далее мы может экспортировать ERD – диаграмму в git. Теперь перейдем к разработке базы данных. Тут у нас есть два пути. Первый путь – это движение от модели ERD – диаграммы с помощью forward eingeneering формируем sql – скрипт, который можно выполнить и получить в базе данных таблицы. Естественно, Workbench сгенерирует много вспомогательного кода. Далее представлен скрипт -- MySQL Workbench Forward Engineering SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0; SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0; SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'; -- ----------------------------------------------------- -- Schema test_data -- ----------------------------------------------------- -- ----------------------------------------------------- -- Schema test_data -- ----------------------------------------------------- CREATE SCHEMA IF NOT EXISTS `test_data` DEFAULT CHARACTER SET utf8 ; USE `test_data` ; -- ----------------------------------------------------- -- Table `test_data`.`materials` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `test_data`.`materials` ( `material` VARCHAR(45) NOT NULL, `type_material` VARCHAR(45) NOT NULL, `amount_in_package` INT UNSIGNED NOT NULL, `unit` VARCHAR(45) NOT NULL, `count_in_warehouse` INT NOT NULL, `min_count` INT NOT NULL, `price` DECIMAL(5,2) UNSIGNED NOT NULL, PRIMARY KEY (`material`)) ENGINE = InnoDB; -- ----------------------------------------------------- -- Table `test_data`.`products` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `test_data`.`products` ( `product` VARCHAR(45) NOT NULL, `min_price` DECIMAL(5,2) UNSIGNED NOT NULL, `image` VARCHAR(45) NOT NULL DEFAULT '/default/image.jpg', `type_product` VARCHAR(45) NOT NULL, `count_people` INT NOT NULL, `number_workshop` INT UNSIGNED NOT NULL, PRIMARY KEY (`product`)) ENGINE = InnoDB; -- ----------------------------------------------------- -- Table `test_data`.`materials_has_products` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `test_data`.`materials_has_products` ( `material` VARCHAR(100) NOT NULL, `products_product` DECIMAL(100) NOT NULL, `count_material_base` INT NOT NULL, INDEX `fk_materials_has_products_products1_idx` (`products_product` ASC) VISIBLE, INDEX `fk_materials_has_products_materials_idx` (`material` ASC) VISIBLE, CONSTRAINT `fk_materials_has_products_materials` FOREIGN KEY (`material`) REFERENCES `test_data`.`materials` (`material`) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINT `fk_materials_has_products_products1` FOREIGN KEY (`products_product`) REFERENCES `test_data`.`products` (`product`) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; SET SQL_MODE=@OLD_SQL_MODE; SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS; SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS; Можно отредактировать данный скрипт под свои нужды. То есть нам надо создать каркас для импорта данных. Готовая база данных с таблицами представлена на рисунке 3.  Рисунок 3 – База данных Теперь остается правильно импортировать данные. Следует учесть, что предварительно нужно отредактировать данные для того, чтобы соотнести их с правильным форматом типа столбца, иначе можно просто не «переварить» данные. С помощью проб и ошибок, боли и муки, слабоумии и отваги удалось выяснить три пути импорта данных. Даже четыре пути. Четвертый путь – это для тех, кто не сдается. Первый путь – использовать возможности оболочки MySQL Workbench. Здесь нас ждем множество приключений с кодировками, версиями MySQL сервера, версиями MySQL Workbench, а также ограничение на форматы импортируемых данных (csv и json). Это прекрасный путь у вас дома (это не точно), но не на экзамене. Я не доверяю этому пути. Второй путь использовать чистый SQL – код, но в рамках Workbench. Это команда LOAD DATA. Здесь нам потребуется наша память, потому что команда не короткая. Важную роль здесь играет гибкость настройки, а также возможность игнорирования первой строки (вспоминаем импортируемые файлы). Также данная команда принимает больше форматов на импорт. Опять же здесь ключевое слово LOCAL (разрешает загружать данные локально). Если она не сработает, то надо прописывать в настройках учетной записи Workbench OPT_LOCAL_1. LOAD DATA LOCAL INFILE 'data.txt' INTO TABLE tbl_name FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\r\n' IGNORE 1 LINES; Пусть номер 3. Это как путь номер 2, только из-под командной строки. То есть вам вообще без разницы на все оболочки. Вы работаете чисто с mysql, как настоящий программист. Нюанс заключается в том, что надо при соединении с базой данных иметь исполняемый файл (здесь нам на помощь придут доблестный работники вычислительного центра и создадут где-нибудь тайный репозиторий с нужными файлами, в том числе mysql.exe). Но надо будет немного потрудиться и прописать все руками, начиная от соединения mysql –local-infile -u root -h localhost -p password Естественно, что параметры свои. Тут ключевая роль отдана опции –local-infile Четвертый путь самый долгий и самый надежный. Просто использовать команду INSERT INTO построчно. Да, долго. Все равно вам редактировать файл. В конце концов, главное результат, а каким способом вы загрузили данные не важно. Главное не сколько ты падал, а сколько ты поднимался. Ну вы поняли). Применение техники номер два представлено на рисунке 3.  Рисунок 3. Импорт материалов Здесь пришлось отредактировать поле price, чтобы сделать его атомарным, а также сделать тип decimal(10,2). В любом случае ошибки подскажут вам, что у вас не так при импорте. В данном случае, предупреждение. Импорт материалов показан на рисунке 4 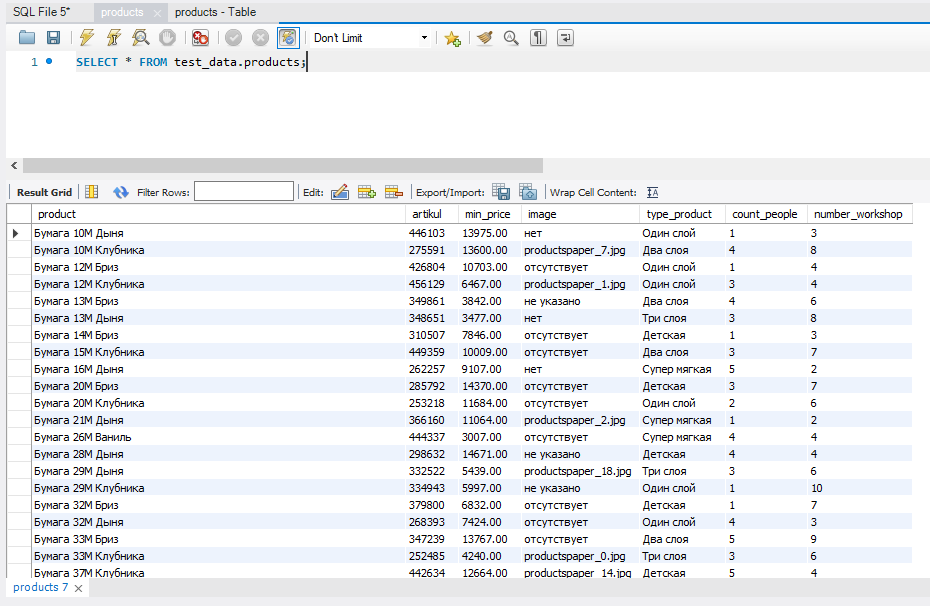 Рисунок 4. Импорт материалов Изначально исходный файл был форматом csv. Стоит учесть тот факт, что разделитель в таком случае в команде LOAD DATA стоит поменять на ‘ ; ’. Далее на рисунке 5 показа импорт связующей таблицы.  Рисунок 5 – Связующая таблица В данном случает потребовалось прописать временное разрешение на игнорирование ограничений внешнего ключа SET FOREIGN_KEY_CHECKS=0; Замечание: скорее всего вам не с первого раза удастся импортировать верно данные в полном объеме и правильном формате. Поэтому не лишней будет команда Delete from table1 SET SQL_SAFE_UPDATES = 0; Вывод: проделав первую сессию много времени тратиться только на редактирование данных. Можно считать, что первая сессия является очень легкой сессией. Здесь можно набрать максимальное количество баллов. В данном случает таблицы не находятся в 3НФ, поэтому 0.9 балов мы жертвуем на дополнительное время |