Файлсерверная архитектура
 Скачать 108.7 Kb. Скачать 108.7 Kb.
|

|
Файл-серверная архитектурапредставляет наиболее простой случай распределенной обработки данных, согласно которой на сервере располагаются только файлы данных, а на клиентской части находятся приложения пользователей вместе с СУБД. Файл-сервер представляет собой достаточно мощную по производительности и оперативной памяти компьютера, являющуюся центральным узлом локальной сети. Файл-сервер в среде сетевой операционной системы организует доступ к файлам, полностью эквивалентным файлам операционной системы и расположенным во внешней памяти файл-сервера. При данном подходе программы СУБД располагаются в оперативной памяти рабочих станций локальной сети, а файлы базы данных - на магнитных дисках файл-сервера. Специальный интерфейсный модуль распознает, где находятся файлы, к которым осуществляется обращение. 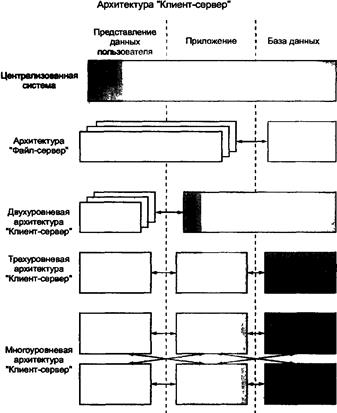 Рис. 12.2. Варианты клиент-серверной архитектуры КЭИС В связи с этим данная СУБД может работать как с локальными базами данных, так и с центральной базой данных. Синхронизация совместного использования базы данных файл-сервера возлагается на систему управления базами данных, которая должна обеспечивать блокирование записей на время их корректировки, чтобы сделать их недоступными с других рабочих станций. Использование файл-серверов предполагает, что вся обработка данных выполняется на рабочей станции, а файл-сервер лишь выполняет функции накопителя данных и средств доступа. Двухуровневая клиент-серверная архитектура основана на использовании только сервера базы-данных (DB-сервера), когда клиентская часть содержит уровень представления данных, а на сервере находится база данных вместе с СУБД и прикладными программами. DB-сервер отличается от файл-сервера тем, что в его оперативной памяти, помимо сетевой операционной системы, функционирует централизованная СУБД, которая обеспечивает совместное использование рабочими станциями базы данных, размещенной во внешней памяти этого DB-сервера. DB-сервер дает возможность отказаться от пересылки по сети файлов данных целиком и передавать только ту выборку из базы данных, которая удовлетворяет запросу пользователя. При этом возможно разделение пользовательского приложения на две части: одна часть выполняется на сервере и связана с выборкой и агрегированием данных из базы данных, а вторая часть по представлению данных для анализа и принятия решения выполняется на клиентской машине. Таким образом, увеличивается общая производительность информационной системы в результате объединения вычислительных ресурсов сервера и клиентской рабочей станции. Обращение к базе данных осуществляется на языке SQL, который фактически стал стандартом для реляционных баз данных. Отсюда сервер баз данных часто называют SQL-сервером, который поддерживается всеми реляционными СУБД: Oracle, Informix, MS SQL, ADABAS D, InterBase, SyBase и др. Клиентское приложение может быть реализовано на языке настольных СУБД (MS Access, FoxPro, Paradox, Clipper и др.). При этом взаимодействие клиентского приложения с SQL-сервером осуществляется через ODBC-драйвер (Ореn Data Base Connectivity), который обеспечивает возможность пересылки и преобразования данных из глобальной базы данных в структуру базы данных клиентского приложения. Применение этой технологии позволило разработчикам не заботиться о специфике работы с той или иной СУБД и делать свои системы переносимыми между базами данных. За время своего существования ODBC стал стандартом де-факто на алгоритм доступа к разнородным базам данных, и на сегодняшний день насчитывается более 160 прикладных систем, которые работают с источниками информации через драйверы ODBC. Трехуровневая клиент-серверная архитектура позволяет помещать прикладные программы на отдельные серверы приложений, с которыми через API-интерфейс (Application Program Interface) устанавливается связь клиентских рабочих станций. Работа клиентской части приложения сводится к вызову необходимых функций сервера приложения, которые называются «сервисами». Прикладные программы в свою очередь обращаются к серверу базы данных с помощью SQL запросов. Такая организация позволяет еще более повысить производительность и эффективность КЭИС за счет: · многократности повторного использования общих функций обработки данных в множестве клиентских приложений при существенной экономии системных ресурсов; · параллельности в работе сервера приложений и сервера базы данных, причем сервер приложений может быть менее мощным по сравнению с сервером базы данных; · оптимизации доступа к базе данных через сервер приложений из клиентских мест путем диспетчеризации выполнения запросов в вычислительной сети; · повышения скорости/и надежности обработки данных в результате дублирования программного обеспечения на нескольких серверах приложений, которые могут заменять друг друга в сети в случае перегрузки или выхода из строя одного из них; · переноса функций администрирования системы по проверке полномочий доступа пользователей с сервера базы данных на сервер приложений. Многоуровневая архитектура «Клиент-сервер» создается для территориально-распределенных предприятий. Для нее в общем случае характерны отношения «многие ко многим» между клиентскими рабочими станциями и серверами приложений, между серверами приложений и серверами баз данных. Такая организация позволяет более рационально организовать информационные потоки между структурными подразделениями в процессе выполнения общих деловых процессов. Так, каждый сервер приложений, как правило, обслуживает потребности какой-либо одной функциональной подсистемы и сосредоточивается в головном для подсистемы структурном подразделении, например, сервер приложения по управлению сбытом - в отделе сбыта, сервер приложения по управлению снабжением - в отделе закупок и т.д. Естественно, что локальная сеть каждого из подразделений обеспечивает более быструю реакцию на запросы основного контингента пользователей из соответствующего подразделения. Интегрированная база данных находится на отдельном сервере, на котором обеспечиваются централизованное ведение и администрирование общих данных для всех приложений. Выделение нескольких серверов баз данных особенно актуально для предприятий с филиальной структурой, когда в центральном офисе используется общая база данных, содержащая общую нормативно-справочную, планово-бюджетную информацию и консолидированную отчетность, а в территориально-удаленных филиалах поддерживается оперативная информация о деловых процессах. При обработке данных в филиалах для контроля используется плановая и нормативно-справочная информация из центральной базы данных, а в центральном офисе получение консолидированной отчетности сопряжено с обработкой оперативной информации филиалов. Для сокращения объема передачи данных по каналам связи в распределенной информационной системе предлагается репликация данных, то есть тиражирование данных на взаимодействующих серверах баз данных с автоматическим поддержанием соответствия копий данных. При этом возможны следующие режимы репликации: · синхронный режим, когда тиражируемые данные обновляются по мере возникновения необходимости одновременно на серверах баз данных во всех копиях. Требуемое быстродействие каналов для синхронного режима - единицы Мбит в секунду; · асинхронный режим, когда тиражирование данных выполняется в строго определенные моменты времени, например каждый час работы информационной системы. Требуемое быстродействие каналов для асинхронного режима - единицы Кбит в секунду. Асинхронный режим может вызывать откладывание выполнения транзакций до момента обновления данных. Направление тиражирования между серверами баз данных может быть: · равноправным, т.е. в обоих направлениях; · сверху-вниз типа «ведущий/ведомый», когда на серверах филиалов содержатся только некоторые подмножества данных центральной базы данных; · снизу-вверх по консолидирующей схеме, когда при обновлении данных в филиалах в определенные моменты времени обновляется центральная база данных. Рассмотрим технологическую сеть техно-рабочего проектирования трехуровневой клиент-серверной КЭИС (рис. 12.3). Эта операция выполняется на основе описания предметной области D1 и технического задания D4, а также универсумов сетевых операционных систем и технических платформ (U1), серверов БД (U2), программных средств разработки КЭИС (U3). Выходом данной технологической операции служат описание выбранной конфигурации технических средств и сетевой операционной системы D3, описание выбранного сервера БД - D2, описание выбранных программных средств разработки КЭИС – D5, описание функциональной структуры КЭИС - D6. Сущность операции сводится к выбору программно-технической среды реализации КЭИС и распределению функций обработки данных КЭИС по уровням клиент-серверной архитектуры. 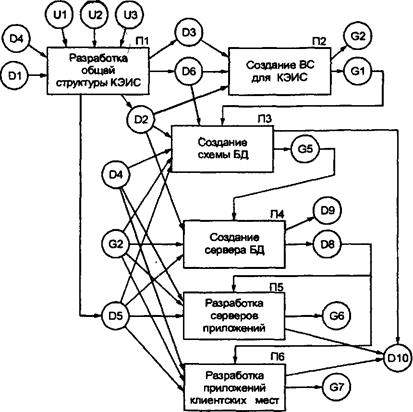 Рис. 12.3. Технологическая сеть техно-рабочего проектирования трехуровневой клиент-серверной КЭИС: D1 - описание предметной области; D2 - описание выбранного сервера БД; D3 - описание выбранной конфигурации технических средств и сетевой операционной системы; D4 - техническое задание; D5 - описание выбранных программных средств разработки КЭИС; D6 - описание функциональной структуры КЭИС; D8 - права доступа различным категориям пользователей КЭИС; D9 - журнал заполнения областей БД; D10 - сопровождающая документация; U1 - универсум сетевых операционных систем и технических платформ; U2 - универсум серверов БД; U3 - универсум программных средств разработки КЭИС; G1 - вычислительная сеть; G2 - СУБД; GS - SQL-описание БД с управляющими элементами; G6 – программное обеспечение сервера; G7 - приложения клиентских мест. Выбор сетевых операционных систем во многом зависит от технической платформы вычислительных средств. При использовании платформы INTEL наиболее распространенными сетевыми ОС являются WINDOWS 95, 98, NT 2000. При использовании других платформ, таких, как: IBM; SUN; HP и других, применяют ОС UNIX различных версий для соответствующих платформ. Выбор сервера БД для КЭИС основывается на анализе рынка серверов БД по различным критериям: · независимость от типа аппаратной архитектуры; · независимость от программно-аппаратной платформы; · поддержка стандарта открытых систем; · поддержка многопроцессорной и параллельной обработки данных; · оптимальное хранение распределенных данных; · поддержка WEB-серверов и работа с Интернет; · поддержка вторичных индексов; · непрерывная работа; · защита от сбоев; · простота использования. В качестве примера рассмотрим сравнение по вышеназванным критериям серверов БД ORACLE 7.0 , MS SQL SERVER и ADABAS D. Сравнительный анализ серверов БД представлен в табл. 12.1. Выбор программных средств разработки КЭИС определяется требованиями применяемой технологии проектирования КЭИС (см. гл. 13-14). Разработка общей функциональной структуры корпоративной информационной системы на основе функционально-ориентированной или объектно-ориентированной модели проблемной области (см. гл. 13) заключается в определении: · функций сервера БД; · функций серверов приложений; · функций клиентских мест; · информации, которая необходима для выполнения этих функций; · распределения серверов и клиентских мест по узлам вычислительной сети; · прав доступа пользователей к КЭИС. Таблица 12.1 Сравнительный анализ серверов БД
Основными правами доступа являются следующие: · права на доступ к вычислительным ресурсам. Такие права задаются администратором вычислительной сети с помощью инструментов сетевой операционной системы. Процесс задания прав заключается в назначении различным категориям пользователей прав доступа к ресурсам сети и возможности выполнения над ними функции чтения, редактирования, записи. Например, пользователю с именем manager1 доступны ресурсы, представленные в табл. 12.2. Таблица 12.2. Задание прав доступа
· права на доступ к объектам схемы базы данных КЭИС. Такие права задаются администратором сервера БД с помощью инструментов серверной СУБД. Процесс задания прав заключается в назначении различным категориям пользователей возможности выполнения над объектами схемы БД функций чтения, редактирования, записи. Например, пользователю с именем manager1 доступны объекты, представленные в табл. 12.3. Таблица 12.3. Права доступа к объектам схемы базы данных
Создание ВС заданной архитектуры для КЭИС заключается в закупке и монтаже оборудования, а также инсталляции сетевого программного обеспечения и СУБД. На основе описания функциональной структуры D6, описания выбранной конфигурации технических средств и сетевой операционной системы D3, описания выбранного сервера БД D2 происходят создание вычислительной сети G1 и установка СУБД G2. На основе технического задания D4, описания выбранных программных средств разработки D5, описания функциональной структуры КЭИС D6, описания выбранного сервера БД D2 и его СУБД G2, конфигурации вычислительной сети G1 осуществляются разработка схемы БД с управляющими элементами - G5 и ее документирование D10. Создание схемы БД сводится к выполнению следующих технологических операций (рис. 12.4): Проектирование структуры распределенной базы данных (П31). Разработка структуры распределенной базы данных D7 происходит на основе описания функциональной структуры КЭИС D6, как правило, с помощью CASE-технологии - D5 с учетом описания выбранного сервера БД D2 в конкретной программно-технической среде G1 и СУБД G2. В результате строятся модель базы данных и подмодели для различных категорий пользователей на основе установления им прав доступа к данным. Создание области базы данных (П32). Создание области базы данных G3 заключается в инициализации областей внешней памяти (системной, хранения данных, транзакций, хранения архивных данных). Данная операция выполняется системным администратором БД, который использует для этих целей средства СУБД сервера БД G2 и спроектированную структуру базы данных D7. Загрузка SQL-описания БД (ПЗЗ). Загрузка SQL-описания БД G4 осуществляется системным администратором БД на основе схемы базы данных D7 средствами СУБД сервера БД G2. Разработка управляющих элементов БД (триггеров, процедур и т. д.) (П34). Разработка управляющих элементов G5, к которым относятся хранимые процедуры и триггеры, осуществляется на основе структуры базы данных D7 с учетом ее SQL-описания БД G4 и возможностей средств СУБД сервера БД G2. В результате получается готовая для эксплуатации схема базы данных с управляющими элементами, которая документируется в D10. 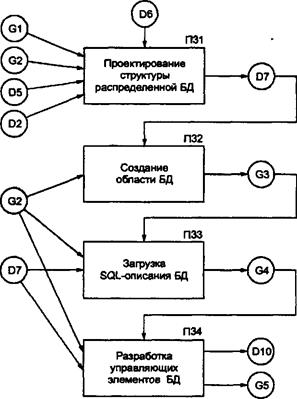 Рис. 12.4.Технологическая сеть проектирования базы данных в клиент-серверной среде: D2 - описание выбранного сервера БД, D5 - описание выбранных программных средств разработки КЭИС, D6 - описание функциональной структуры КЭИС; D7 - структура базы данных; D10 - сопровождающая документация, G1 - вычислительная сеть; G2 - СУБД, G3 - область базы данных, G4 - SQL-описание БД; G5 - SQL-описание БД с управляющими элементами. Хранимая процедура представляет собой вариант программного наполнения базы данных, основная функция которой - функциональное расширение схемы БД. Хранимая процедура выполняет то или иное логическое действие. Например, администратор банковской системы создает хранимую процедуру, которая реализует функцию «занести на счет номер X сумму Y». Разработчик приложения пользуется этой процедурой, но не знает, как именно она работает. Это дает следующие преимущества: · когда меняется алгоритм данного действия, то администратор меняет только эту хранимую процедуру и все приложения сразу начинают работать по-новому; · независимо от типа рабочего места, использующего хранимую процедуру, одно и то же действие выполняется одинаково, что повышает надежность разработанной системы; · хранимая процедура пишется одним человеком, а используется многими, следовательно, повышаются темпы разработки КЭИС; · повышается скорость обработки запросов пользователей за счет того, что действия по анализу хранимой процедуры выполняются единожды при определении этой процедуры. Триггер БД - это механизм «событие - действие», который автоматически выполняет некоторый набор SQL-операторов, когда происходит некоторое событие. Событиями, на которые можно установить триггер, являются модификации данных. Причем триггер связан с конкретной таблицей БД. Триггер хранится как объект в базе данных. Создание триггеров позволяет установить правила обеспечения ссылочной целостности сервера БД. На основании разработанной схемы БД с управляющими элементами G5, описания выбранного сервера БД D2 и его СУБД G2 осуществляется создание сервера БД, то есть физическое наполнение БД и настройка программ доступа СУБД. Выходом данной операции служат физическое установление прав доступа различным категориям пользователей КЭИС D8, журнал заполнения областей БД D9. Разработка серверов приложений (П5) Исходя из информационных потребностей пользователей D4 и их прав D8, используя программные средства разработки D5, разрабатывается сервер приложения G5 и сопровождающая документация D10. В состав сервера приложений входят набор сервисов (функций обработки данных) и монитор транзакций, осуществляющий управление выполнением сервисов по обслуживанию клиентских потребностей. Разработка клиентских приложений на рабочих станциях (П6) На основе информационных потребностей пользователей D4 и их прав D8, используя программные средства разработки D5, создаются приложения клиентских мест G7, а также сопровождающая документация D10. В частности, осуществляется проектирование пользовательского интерфейса клиентских частей приложений. Клиент-серверная архитектура КЭИС упрощает взаимодействие пользователей с информационной системой и между собой в процессе выполнения деловых процессов или длинных транзакций. Под длинной транзакцией будем понимать совокупность операций делового процесса, требующих обращения к КЭИС, каждая из которых не имеет ценности без выполнения всей совокупности. Под короткой транзакцией или просто транзакцией будем понимать отдельное обращение к одному из компонентов КЭИС или обращение клиента к серверу. С помощью обработки длинных транзакций КЭИС позволяет управлять достаточно сложными цепочками операций делового процесса как единым целым. Такие информационные системы называют системами оперативной обработки транзакций (OLTP - OnLine Transaction Processing). Основой современных систем оперативной обработки транзакций является управление рабочими потоками (workflow), в которых пользователи-клиенты взаимодействуют между собой и со множеством программных приложений через специальную управляющую программу. Системы оперативной обработки транзакций могут распространяться и на межорганизационное взаимодействие предприятий с помощью специально разработанных Интернет-приложений в глобальной вычислительной сети. Под рабочим потоком будем понимать совокупность информационного и материального потоков в цепочке операций делового процесса. |