практические работы. Методические указания к лабораторной работе (1). Федерации федеральное агентство по образованию государственное
 Скачать 0.67 Mb. Скачать 0.67 Mb.
|

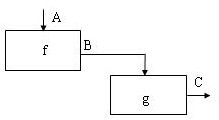
Характеристика программного модуля. Потоки данных и процессыХарактеристики программного модуляПриступая к разработке каждой программы ПС, следует иметь в виду, что она,как правило,является большой системой,поэтому необходимо принять меры для ее упрощения. Для этого такую программу разрабатывают по частям, которые называются программными модулями. А сам такой метод разработки программ называют модульным программированием. Программный модуль −это любой фрагмент описания процесса, оформ- ляемый как самостоятельный программный продукт, пригодный для использо- вания в описаниях процесса. Это означает, что каждый программный модуль программируется, компилируется и отлаживается отдельно от других модулей программы, и тем самым, физически разделен с другими модулями программы. Более того,каждый разработанный программный модуль может включаться в состав разных программ, если выполнены условия его использования, деклари- рованные в документации по этому модулю. Таким образом, программный мо- дуль может рассматриваться и как средство борьбы со сложностью программ, и как средство борьбы с дублированием в программировании (т.е. как средство накопления и многократного использования программистских знаний). Модульное программирование призвано, в процессе разработки про- грамм, борьбы со сложностью, обеспечивает независимость компонент систе- мы, и использование иерархических структур. Для избежание сложностей формулируются определенные требования, которым должен удовлетворять программный модуль,т.е.выявляются основ- ные характеристики «хорошего» программного модуля. Выделить хороший с этой точки зрения модуль является серьезной творческой задачей. Для оценки приемлемости выделенного модуля используются некоторые критерии. Так, Хольт предложил следующие два общих таких критерия: −хороший модуль снаружи проще, чем внутри; −хороший модуль проще использовать, чем построить. Майерс предлагает для оценки приемлемости программного модуля ис- пользовать более конструктивные его характеристики: −размер модуля, −прочность (связность) модуля, −сцепление с другими модулями, – рутинность модуля (независимость от предыстории обращений к нему). Характеристики программного модуля по МайерсуРазмермодуля измеряется числом содержащихся в нем операторов или строк. Сцеплениемодуля − это мера его зависимости по данным от других моду- лей. Характеризуется способом передачи данных. Чем слабее сцепление модуля с другими модулями, тем сильнее его независимость от других модулей. Для оценки степени сцепления Майерс предлагает упорядоченный набор из шести видов сцепления модулей. Рутинностьмодуля − это его независимость от предыстории обращений к нему.Модуль будем называтьрутинным,если результат(эффект)обращения к нему зависит только от значений его параметров (и не зависит от предысто- рии обращений к нему). Модуль будем называть зависящим от предыстории, если результат (эффект) обращения к нему зависит от внутреннего состояния этого модуля, изменяемого в результате предыдущих обращений к нему. Суще- ствуют некоторые рекомендации по использованию зависящих от предыстории модулей: всегда следует использовать рутинный модуль, если это не приводит к плохим (не рекомендуемым) сцеплениям модулей; зависящие от предыстории модули следует использовать только в слу- чае,когда это необходимо для обеспечения параметрического сцепле- ния; в спецификации зависящего от предыстории модуля должна быть чет- ко сформулирована эта зависимость таким образом, чтобы было воз- можно прогнозировать поведение (эффект выполнения) данного моду- ля при разных последующих обращениях к нему. В связи с последней рекомендацией может быть полезным определение внешнего представления (ориентированного на информирование человека) со- стояний зависящего от предыстории модуля. В этом случае эффект выполнения каждой функции (операции), реализуемой этим модулем, следует описывать в терминах этого внешнего представления,что существенно упростит прогнози- рование поведения данного модуля. Прочность(связность) модуля − это мера его внутренних связей. Чем выше прочность модуля, тем больше связей он может спрятать от внешней по отношению к нему части программы и, следовательно, тем больший вклад в упрощение программы он может внести. Для оценки степени прочности модуля Майерс предлагает упорядоченный по степени прочности набор из семи классов модулей. Функциональнопрочныймодуль − это модуль, выполняющий (реализую- щий)одну какую-либо определенную функцию.При реализации этой функции такой модуль может использовать и другие модули. Такой класс программных модулей рекомендуется для использования. Информационнопрочныймодуль − это модуль, выполняющий (реализую- щий)несколько операций(функций)над одной и той же структурой данных (информационным объектом), которая считается неизвестной вне этого модуля. Для каждой из этих операций в таком модуле имеется свой вход со своей фор- мой обращения к нему. Такой класс следует рассматривать как класс программ- ных модулей с высшей степенью прочности. Информационно прочный модуль может реализовывать, например, абстрактный тип данных Характеристики программного модуля по методологии SADTМетодологияSADT предлагает несколько другую классификацию связ- ности. Различают по крайней мере семь типов связывания (таблица 1): Таблица 1 – Типы связанности |

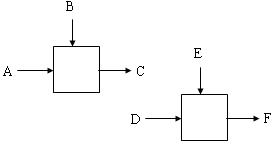
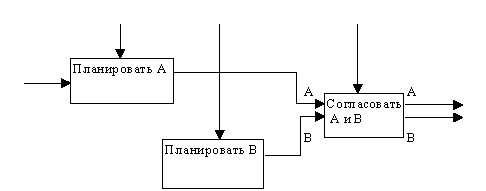
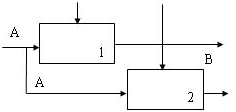
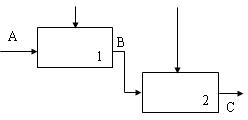
| Аббревиатура | Тип |
| NCНормально | е управление |
| NDНормальны | е данные |
| NCDНормальн | ое управление/данные |
| TCВременное | управление |
| TDВременные | данные |
| TCDВременно | е управление/данные |
Все действия помечаются как нормальные данные. Эти данные являются событиями, которые ИС воспринимает непосредственно, например, изменение адреса клиента, которое должно быть сразу зарегистрировано. Они появляются в DFD в качестве содержимого потоков данных.
Матрица списка событий имеет следующий вид:
 1Клиент желает стать членом биб- лиотеки
1Клиент желает стать членом биб- лиотеки2Клиент сообщает об изменении ад- реса
3Клиент запрашивает аренду филь- ма
NDРегистрация клиента в каче- стве члена библиотеки
NDРегистрация измененного адреса клиента
NDРассмотрение запроса
4Клиент возвращает фильмNDРегистрация воз
5Руководство предоставляет полно- мочия новому поставщику 6Поставщик сообщает об изменении
адреса
NDРегистрация поставщика
NDРегистрация измененного адреса поставщика
| 7По | ставщик направляет фильм в библиотеку | NDПо | лучение нового фильма |
| 8Ру | ководство запрашивает новый отчет | NDФо | рмирование требуемого отчета для руководства |
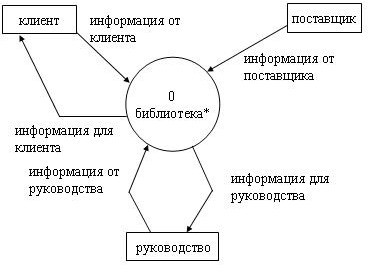
Для завершения анализа функционального аспекта поведения системы строится полная контекстная диаграмма, включающая диаграмму нулевого уровня. При этом процесс "библиотека" декомпозируется на 4 процесса, отра- жающие основные виды административной деятельности библиотеки.Суще- ствующие "абстрактные" потоки данных между терминаторами и процессами трансформируются в потоки, представляющие обмен данными на более кон- кретном уровне. Список событий показывает, какие потоки существуют на этом уровне: каждое событие из списка должно формировать некоторый поток (событие формирует входной поток, реакция - выходной поток). Один "аб- страктный" поток может быть разделен на более чем один "конкретный" поток.
| Потоки на диаграмме верхнего уровня | Потоки на диаграмме нулевого уровня |
| Информация от клиента | Данные о клиенте, Запрос об аренде |
| Информация для клиента | Членская карточка, Ответ на запрос об аренде |
| Информация от руководства | Запрос отчета о новых членах, Новый по- ставщик, Запрос отчета о поставщиках, Запрос отчета об аренде, Запрос отчета о фильмах |
| Информация для руководства | Отчет о новых членах, Отчет о поставщи- ках, Отчет об аренде, Отчет о фильмах |
| Информация от поставщика | Данные о поставщике, Новые фильмы |
На приведенной DFD (рисунок 23) накопитель данных "библиотека" яв- ляется глобальным или абстрактным представлением хранилища данных.
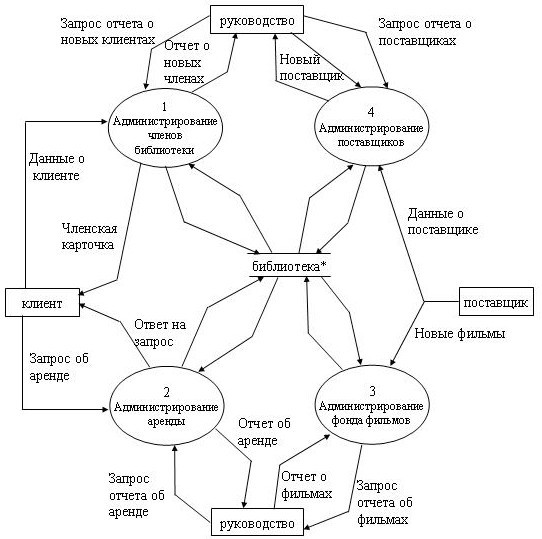
Рисунок 23 - Контекстная диаграмма
Анализ функционального аспекта поведения системы дает представление об обмене и преобразовании данных в системе. Взаимосвязь между "абстракт- ными" потоками данных и "конкретными" потоками данных на диаграмме ну- левого уровня выражается в диаграммах структур данных (рисунок 24).
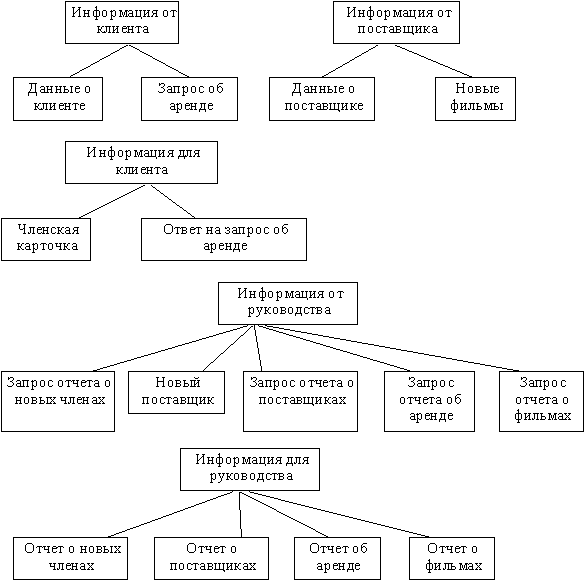
Рисунок 24 - Диаграмма структур данных
На фазе анализа строится глобальная модель данных, представляемая в виде диаграммы "сущность-связь" (рисунок 25).
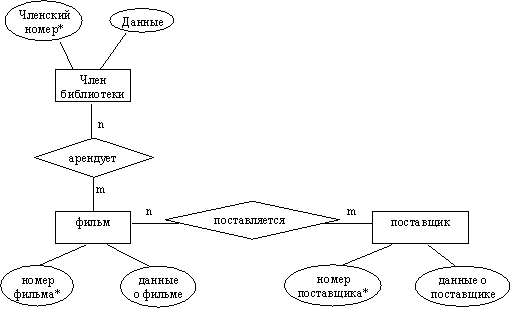
Рисунок 25 - Диаграмма "сущность-связь"
зи:
Между различными типами диаграмм существуют следующие взаимосвя-
ELM-DFD: события - входные потоки, реакции - выходные потоки
−DFD-DSD: потоки данных - структуры данных верхнего уровня
−DFD-ERD: накопители данных - ER-диаграммы
DSD-ERD: структуры данных нижнего уровня - атрибуты сущностей На фазе проектирования архитектуры строится предметная модель. Про-
цесс построения предметной модели включает в себя:
−детальное описание функционирования системы;
дальнейший анализ используемых данных и построение логической модели данных для последующего проектирования базы данных;
определение структуры пользовательского интерфейса, спецификации форм и порядка их появления;
уточнение диаграмм потоков данных и списка событий, выделение среди процессов нижнего уровня интерактивных и не интерактивных, определение для них мини-спецификаций.
Результатами проектирования архитектуры являются:
модель процессов (диаграммы архитектуры системы (SAD) и мини- спецификации на структурированном языке);
модель данных (ERD и подсхемы ERD);
модель пользовательского интерфейса(классификация процессов на интерактивные и не интерактивные функции, диаграмма последова- тельности форм (FSD – Form Sequence Diagram), показывающая, какие формы появляются в приложении и в каком порядке. На FSD фиксиру- ется набор и структура вызовов экранных форм. Диаграммы FSD обра- зуют иерархию, на вершине которой находится главная форма прило- жения, реализующего подсистему. На втором уровне находятся фор- мы, реализующие процессы нижнего уровня функциональной структу- ры, зафиксированной на диаграммах SAD.
На фазе детального проектирования строится модульная модель. Под мо- дульной моделью понимается реальная модель проектируемой прикладной си- стемы. Процесс ее построения включает в себя:
−уточнение модели базы данных для последующей генерации SQL-
предложений;
−уточнение структуры пользовательского интерфейса;
−построение структурных схем, отражающих логику работы пользова- тельского интерфейса и модель бизнес-логики (Structure Charts Diagram – SCD) и привязка их к формам.
Результатами детального проектирования являются:
−модель процессов (структурные схемы интерактивных и не интерактив- ных функций);
−модель данных (определение в ERD всех необходимых параметров для приложений);
−модель пользовательского интерфейса (диаграмма последовательности форм (FSD), показывающая, какие формы появляются в приложении, и в каком
порядке, взаимосвязь между каждой формой и определенной структурной схе- мой, взаимосвязь между каждой формой и одной или более сущностями в ERD).
На фазе реализации строится реализационная модель. Процесс ее по- строения включает в себя:
−генерацию SQL-предложений, определяющих структуру целевой БД (та-
блицы, индексы, ограничения целостности);
−уточнение структурных схем (SCD) и диаграмм последовательности форм (FSD) с последующей генерацией кода приложений.
На основе анализа потоков данных и взаимодействия процессов с храни- лищами данных осуществляется окончательное выделение подсистем (предва- рительное должно было быть сделано и зафиксировано на этапе формулировки требований в техническом задании).При выделении подсистем необходимо ру- ководствоваться принципом функциональной связанности и принципом мини- мизации информационной зависимости. Необходимо учитывать, что на основа- нии таких элементов подсистемы как процессы и данные на этапе разработки должно быть создано приложение, способное функционировать самостоятель- но. С другой стороны при группировке процессов и данных в подсистемы необ- ходимо учитывать требования к конфигурированию продукта, если они были сформулированы на этапе анализа.