ПиРВ Лабораторная работа 8. Гистограмма
 Скачать 100.66 Kb. Скачать 100.66 Kb.
|

|
Министерство цифрового развития, связи и массовых коммуникаций Российской Федерации Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение высшего образования «Московский технический университет связи и информатики» Кафедра «Системное программирование» Лабораторная работа №8 «Гистограмма» Выполнил: студент группы БИБ2001 Поляков М. В. Проверил: Клешнин Н. Г. Москва 2021 г. Оглавление Введение 3Ход работы 4Листинг 1 4Результаты лабораторной работы 7Заключение 8Ответы на вопросы 9Введение Данная лабораторная работа предназначена для разработки алгоритма, который будет строить гистограмму – способ представления табличных данных в виде столбчатой диаграммы. Программа должна строить гистограмму для входящего целочисленного массива, с заданным диапазоном. Ход работы Вначале, я создал проект CUDA в программе Visual Studio, затем я воспользовался готовым шаблоном кода, который надо было отредактировать так, чтобы он выполнял необходимые функции, такие как запуск ядра CUDA, копирование результата на хост и так далее. Результатом этого является код программы, представленный на листинге 1. Листинг 1 #include "cuda_runtime.h" #include "device_launch_parameters.h" #include #include #include #include "wb.h" using namespace std; #define NUM_BINS 128 static unsigned int* generate_data(size_t n, unsigned int num_bins) { unsigned int* data = (unsigned int*)malloc(sizeof(unsigned int) * n); for (unsigned int i = 0; i < n; i++) { data[i] = rand() % num_bins; } return data; } __global__ void histo_kernel(unsigned int* buffer, unsigned int* histo, unsigned int size, unsigned num_bins) { for (int i = 0; i < num_bins; i++) histo[i] = 0; int i = 0; while (i < size) { histo[buffer[i]]++; i++; } } #define CUDA_CHECK(ans) \ { gpuAssert((ans), __FILE__, __LINE__); } inline void gpuAssert(cudaError_t code, const char* file, int line, bool abort = true) { if (code != cudaSuccess) { fprintf(stderr, "GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line); if (abort) exit(code); } } int main(int argc, char* argv[]) { setlocale(LC_ALL, "Russian"); cout << "Введите длину массива" << endl; int inputLength; unsigned int* hostInput; unsigned int* hostBins; unsigned int* deviceInput; unsigned int* deviceBins; srand(time(0)); cin >> inputLength; wbTime_start(Generic, "Importing data and creating memory on host"); hostInput = generate_data(inputLength, NUM_BINS); for (int i = 0; i < inputLength;) { for (int j = 0; i < inputLength && j < 20; i++, j++) cout << hostInput[i] << " "; cout << endl; } cout << endl << endl; hostBins = (unsigned int*)malloc(128 * sizeof(unsigned int)); wbTime_stop(Generic, "Importing data and creating memory on host"); wbTime_start(GPU, "Allocating GPU memory."); cudaMalloc((void**)&deviceInput, inputLength * sizeof(unsigned int)); cudaMalloc((void**)&deviceBins, NUM_BINS * sizeof(unsigned int)); cudaDeviceSynchronize(); wbTime_stop(GPU, "Allocating GPU memory."); wbTime_start(GPU, "Copying input memory to the GPU."); cudaMemcpy(deviceInput, hostInput, inputLength * sizeof(unsigned int), cudaMemcpyHostToDevice); cudaDeviceSynchronize(); wbTime_stop(GPU, "Copying input memory to the GPU."); dim3 blockDim(1), gridDim(1);; wbTime_start(Compute, "Performing CUDA computation"); histo_kernel <<< gridDim, blockDim, NUM_BINS * sizeof(unsigned int) >> >(deviceInput, deviceBins, inputLength, NUM_BINS); cudaGetLastError(); cudaDeviceSynchronize(); wbTime_stop(Compute, "Performing CUDA computation"); wbTime_start(Copy, "Copying output memory to the CPU"); cudaMemcpy(hostBins, deviceBins, NUM_BINS * sizeof(unsigned int), cudaMemcpyDeviceToHost); cudaDeviceSynchronize(); wbTime_stop(Copy, "Copying output memory to the CPU"); wbTime_start(GPU, "Freeing GPU Memory"); cudaFree(deviceInput); cudaFree(deviceBins); wbTime_stop(GPU, "Freeing GPU Memory"); for (int i = 0; i < NUM_BINS;) { for (int j = 0; j < 8 && i < NUM_BINS; j++, i++) { cout << " \t'" << i << "'" << " - " << hostBins[i]; } cout << endl; } free(hostBins); free(hostInput); return 0; } Результат лабораторной работы Результатом лабораторной работы является вывод в окно отладки гистограммы для массива целых чисел с задаваемой пользователем длиной. Результат работы программы представлен на рисунке 1. 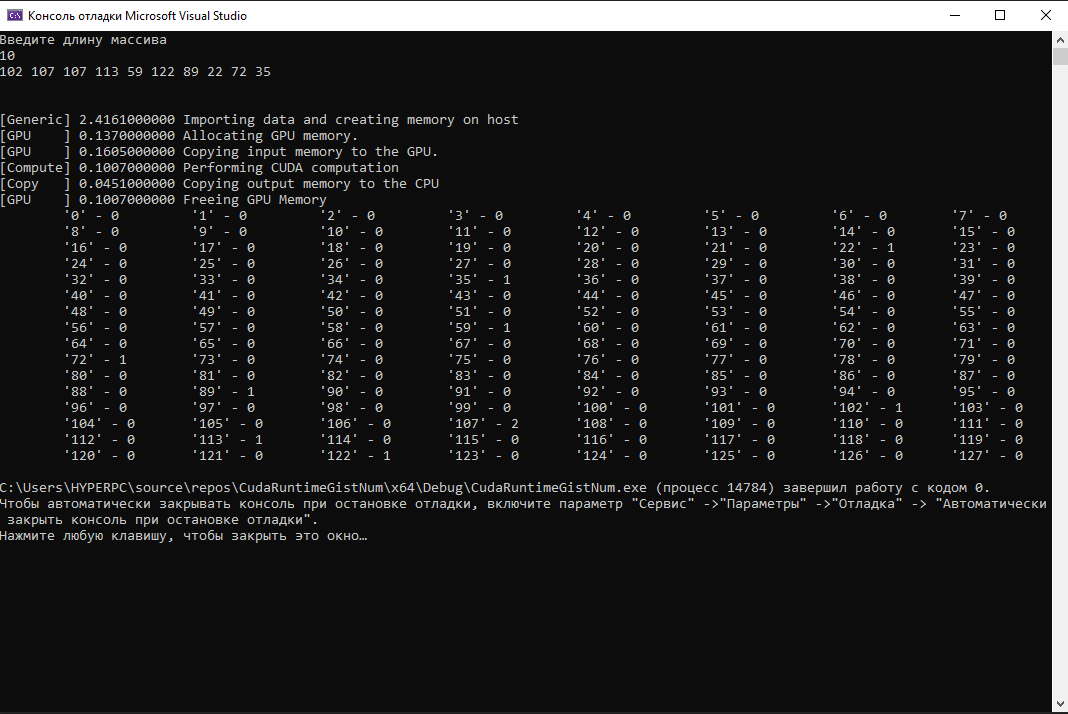 Рисунок 1 – Результат работы программы Заключение Таким образом, с помощью языка программирования CUDA я научился создавать программу, которая строит гистограмму для массива целых чисел. Ответы на вопросы Какая оптимизация дала наибольший прирост производительности? Ответ: Один из методов оптимизации: приватизация совместно используемой памяти. Этот метод оптимизации обеспечивает значительное повышение производительности. Сколько атомарных операций выполнит выше ядро вычисления гистограммы? Ответ: Одна атомарная операция для каждого элемента ввода в общую память, затем атомная операция NUM \\ BINS для каждого блока потока для накопления результатов в глобальных ячейках. |