Хочешь, хорошо работать пользуйся Спрингом. Хочешь, чтобы работало хорошо знай его кишки. Навигация
 Скачать 4.45 Mb. Скачать 4.45 Mb.
|

|
|
| 16. Как устроена (ApplicationEvent) обработка событий в ApplicationContext? |
| ApplicationContext, управляет жизненным циклом бинов. В процессе своей работы он вызывает целый ряд, событий (ContextStoppedEvent, ContextStartedEvent и т.д.). Обработка этих событий обеспечивается классом ApplicationEvent и интерфейсом ApplicationListener. И когда бин имплементирует интерфейс ApplicationListener, то каждый раз, когда вызывается то или иное событие, бин получает об этом информацию. Существует целый ряд стандартных событий в Spring Framework: 1) ContextStartedEvent — Это событие публикуется, когда ApplicationContext запущен через метод start() интерфейса ConfigurableApplicationContext. После получения этого события мы можем выполнить необходимые нам действия (например, записать то-то в базу данных и т.д.). 2) ContextRefreshedEvent — Это событие публикуется, когда ApplicationContext обновлён или инициализирован. Оно может быть вызвано использованием метода refresh() интерфейса ConfigurableApplicationContext. 3) ContextStoppedEvent — Это событие публикуется, когда ApplicationContext остановлен методом stop() интерфейса ConfigurableApplicationContext. Мы также можем дать команду выполнить определённую работу после получения этого события. 4) ContextClosedEvent — Публикуется, когда ApplicationContext закрыт методом close() интерфейса ConfigurableApplicationContext. Закрытие контекста – это конец файла. После этого он не может быть перезапущен или обновлен. 5) RequestHandledEvent — Это специальное событие, которое информирует нас о том, что все бины HTTP-запроса были обслужены (ориентирован на веб). Бонусом служит то, что Spring позволяет нам создавать свои собственные события и обрабатывать их.  Обработка событий в Spring однопоточна, а значит, если событие опубликовано, то все процессы будут блокированы, пока все адресаты не получат сообщение. Обработка событий в Spring однопоточна, а значит, если событие опубликовано, то все процессы будут блокированы, пока все адресаты не получат сообщение. |
| 17. Что такое ApplicationContext? (Это главный интерфейс во фреймворке Spring) |
| ApplicationContext — это главный интерфейс в Spring-приложении, который предоставляет информацию о конфигурации приложения. Он доступен только для чтения во время выполнения, но может быть перезагружен. Число классов, реализующих ApplicationContext интерфейс, доступны для различных параметров конфигурации и типов приложений. ApplicationContext предоставляет: 1) Фабричные методы бина для доступа к компонентам приложения; 2) Возможность загружать файловые ресурсы в общем виде; 3) Возможность публиковать события и регистрировать обработчики на них; 4) Возможность работать с сообщениями с поддержкой интернационализации; 5) Наследование от родительского контекста. Допустим, для нашей программы надо использовать 3 объекта: котика, собачку и попугайчика. И у нас есть куча классов с кучей методов, где иногда нам нужен для метода котик, а для другого метода — собачка, а иногда у нас будут методы, где нужен котик и попугайчик (например метод для кормёжки котика, хе-хе). Мы можем в main-е сначала создать эти три объекта, а потом их передавать в наши классы, а уже изнутри классов — в нужные нам методы... И так по всей программе. А если ещё и представить, что периодически мы захотим менять список принимаемых параметров для наших методов (ну решили переписать что-то или добавить функциональности) — то нам придется делать довольно много правок по коду если надо будет что-то поменять. А теперь если представить, что таких объектов у нас не 3, а 300? Для этого в Spring существует ApplicationContext. ApplicationContext – это обёртка над мапой (которая хранит объекты), где сделаны методы, чтобы в каких-то случаях доставать объекты по их имени (ключ), а в других случаях — по классу (значение). ApplicationContext — содержит набор бинов (объектов). Обращаясь к нему — мы можем получить нужный нам бин (объект) по его имени, или по его типу, или ещё как-то. Кроме того, мы можем попросить Spring самого сходить поискать в своём ApplicationContext нужный нам бин и передать его в наш метод(Dependency Injection). Н  апример, если у нас был такой метод: апример, если у нас был такой метод:Spring когда вызывал этот метод — передавал в него объект нашего котика из своего контекста. Теперь мы решаем, что нашему методу кроме котика нужен ещё и попугайчик. Т  еперь, когда будет вызывать метод — Spring сам поймет, что сюда надо передать котика и попугайчика, сходит к себе в контекст, достанет эти два объекта и передаст их в наш метод. еперь, когда будет вызывать метод — Spring сам поймет, что сюда надо передать котика и попугайчика, сходит к себе в контекст, достанет эти два объекта и передаст их в наш метод.Передав спрингу бразды правления нашей программой (Inversion of Control) — мы так же переложили на него ответственность за создание Java объектов (аналог new) и передачу их в наши методы (Dependency Injection), которые он будет вызывать. Мы можем создавать сразу несколько контекстов в нашем приложении, никаких ограничений на их количество нет. Мы так же можем указывать контекстам родственные связи между другими контекстами. В данном примере у нас два контекста. Первый контекст является родителем второго контекста. Второй контекст имеет все бины, которые лежат в первом контексте + может иметь свои бины, которых нет в первом контексте. |
| 18. Для чего существует такое количество реализаций ApplicationContext? (конфигурация приложения) |
| Для того чтобы Spring создал контекст с экземплярами классов, ему нужно предоставить дополнительную информацию — метаданные, из каких классов/объектов состоит ваше приложение, как они создаются, какие у них есть зависимости и т. д. Spring Context + метаданные = работающее приложение. Существует три способа конфигурации приложения (указания спрингу какие именно объекты нам нужны для работы). Они отличаются друг от друга именно тем, каким способом задаются метаданные и где хранится эта конфигурация: 1) При помощи xml файлов/конфигов; - самый низкоприоритетный способ. — ClassPathXmlApplicationContext — метаданные конфигурируются XML-файлом(-ами) и они лежат в classpath, т. е. в ресурсах модуля; — FileSystemXmlApplicationContext — метаданные тоже конфигурируются XML-файлом(-ами), но они находятся где-то в файловой системе, например, /etc/yourapp/spring-context.xml; — GenericGroovyApplicationContext — когда конфигурация представляет собой файл с кодом Groovy 2) При помощи java-конфигов; - если при помощи АК нет возможности правильно настроить все возможные бины. —  AnnotationConfigApplicationContext(JavaConfig.class) — конфигурация через аннотации с указанием класса (или массива классов), помеченного аннотацией @Configuration AnnotationConfigApplicationContext(JavaConfig.class) — конфигурация через аннотации с указанием класса (или массива классов), помеченного аннотацией @Configuration3) Автоматическая конфигурация(АК). - наиболее приоритетный способ, которому стоит отдавать предпочтение. Можно использовать внутри кода аннотации @Component, @Service, @Repository, @Controller для указания классов в качестве спринг бинов. — AnnotationConfigApplicationContext(”package.name”) — с указанием пакета для сканирования — метаданные конфигурируются с помощью аннотаций прямо на классах. — StaticApplicationContext. |
| 19. Что такое интерфейс BeanPostProcessor? |
| BeanPostProcessor - позволяет настраивать наши бины до того, как они попадают в контейнер (напомню, что контейнер — это, по сути, простая HashMap коллекция). У этого интерфейса 2 метода: • Object postProcessBeforeInitialization(Object bean, String beanName) • Object postProcessAfterInitialization(Object bean, String beanName) А между ними вызывается init метод. |
| 20. Что такое интерфейс BeanFactoryPostProcessor? |
| BeanFactoryPostProcessor - позволяет настраивать BeanDefinitions, до того, как будут созданы эти бины. Этот интерфейс имеет один единственный метод: • postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) Этот метод запустится на этапе, когда другие бины ещё не созданы, и есть только BeanDefinitions. Spring поставляет несколько полезных реализаций BeanFactoryPostProcessor, например, читающий property-файлы и получающий из них свойства бинов. Также можно написать собственную реализацию BFPP. |
| 21. Что такое BeanDefinitions? |
| BeanDefinitions – это объект, который хранит в себе информацию о конфигурационных метаданных бина. |
| 22. Что такое интерфейс ClassPathBeanDefinitionScanner? |
| ClassPathBeanDefinitionScanner - не является ни BeanPostProcessor-ом, ни BeanFactoryPostProcessor-ом • Он ResourceLoaderAware • Создаёт BeanDefinitions из всех классов, над которыми стоит @Component, или другая аннотация, включающая @Component |
| BEANS В НАЧАЛО ДОКУМЕНТА |
| 1. Что такое бин? Как они создаются? |
| Б  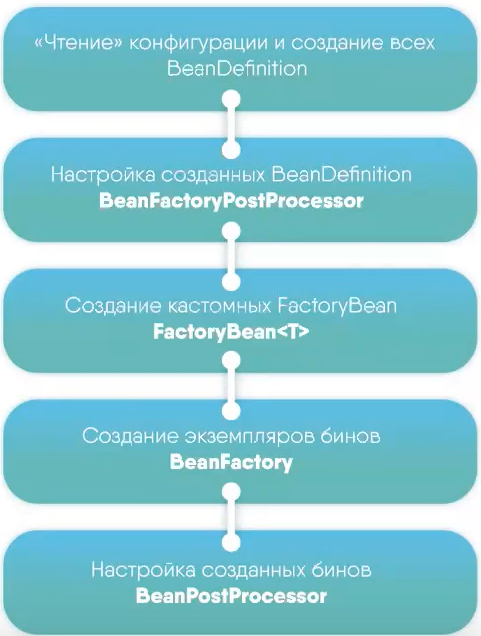 ин (bean) — это обычный объект какого-то класса. Разница в том, что бинами принято называть объекты, которые управляются Spring-ом и живут внутри его Dependency Injection -контейнере ин (bean) — это обычный объект какого-то класса. Разница в том, что бинами принято называть объекты, которые управляются Spring-ом и живут внутри его Dependency Injection -контейнере - Как создать бин; - Информацию о жизненном цикле бина; - Зависимости бина. Бином является почти всё в Spring — сервисы, контроллеры, репозитории, по сути всё приложение состоит из набора бинов. Их можно регистрировать, получать в качестве зависимостей, проксировать, мокать и т.п. Для получения экземпляра бина используется ApplicationContext. IoC контейнер управляет жизненным циклом Spring бина, областью видимости и внедрением. Singleton-бины обычно создаются сразу при сканировании. Prototype-бины обычно создаются только после запроса. Чтобы указать способ инициализации, можно использовать аннотацию @Lazy. Она ставится на @Bean-методы, на @Configuration-классы, или на @Component-классы. В зависимости от параметра(true или false), который принимает аннотация, инициализация будет или ленивая, или произойдет сразу. По умолчанию(т.е. без указания параметра) используется true. |
| 2. Свойства определяющие бин? |
| 1) class – Этот атрибут является обязательным и указывает конкретный класс Java-приложения, который будет использоваться для создания бина. 2) name – Уникальный идентификатор бина. В случае конфигурации с помощью xml-файла, вы можете использовать свойство “id” и/или “name” для идентификации бина. 3) scope – Это свойство определяет область видимости создаваемых объектов. 4) constructor-arg – Определяет конструктор, использующийся для внедрения зависимости в XML-файле. 5) properties – Определяет свойства внедрения зависимости в XML-файле. 6) initialization method – Здесь определяется метод инициализации бина. 7) destruction method – Метод уничтожения бина, который будет использоваться при уничтожении контейнера, содержащего бин. 8) autowiring mode – Определяет режим автоматического связывания при внедрении зависимости. 9) lazy-initialization mode – Режим ленивой инициализации даёт IoC контейнеру команду создавать экземпляр бина при первом запросе, а не при запуске приложения. |
| 3. Виды бинов EJB? |
| 1) Entity Bean – бин, цель которого — хранить некоторые данные. В логику такого бина встроен механизм сохранения себя и своих полей в базу данных. Такой объект может быть уничтожен, а потом воссоздан из базы заново. Но кроме хранения данных у него нет никакой логики. 2) Session Bean – это функциональный бин. У каждого Session Bean есть своя функция. Один делает одно, другой другое. Такие бины работают с другими объектами и бинами, а не со своими данными. Session Beans делятся на две категории. - Stateless Session Bean – это бин, который не хранит во внутренних переменных важных данных, нужных для его работы. Такой бин можно уничтожить, а затем заново создать, и он будет выполнять свою функцию, как и раньше. - Statefull Session Bean – это бин, который хранит у себя внутри данные, которые использует при работе. Если мы вызываем методы этого бина, то в каждом следующем вызове он может использовать часть данных, переданных ему в предыдущих. И всё равно этот бин – это не то же самое, что обычный объект. |
| 4. Является ли Bean потокобезопасным? |
| По умолчанию бин задаётся как синглтон в Spring. Таким образом все публичные переменные класса могут быть изменены одновременно из разных мест. Так что - нет, не является. Однако поменяв область действия бина на request, prototype, session он станет потокобезопасным, но это скажется на производительности. |
| 5. Как получить бин? |
| Для извлечения бина из контекста используется следующий подход: |
| 6. Что такое жизненный цикл Bean? |
| Ж 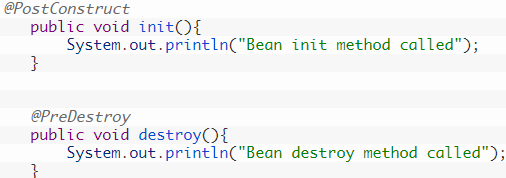 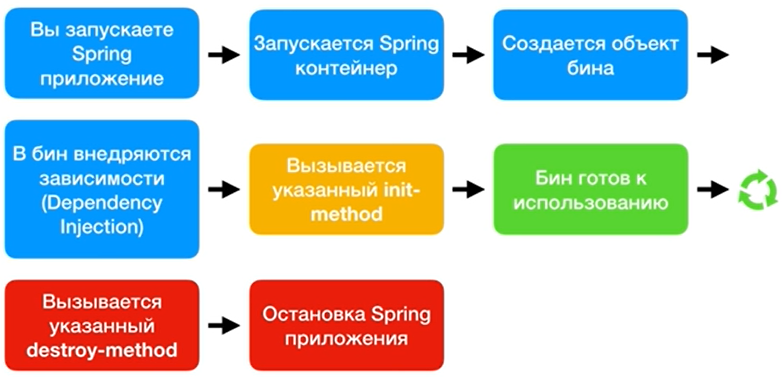 изненный цикл Spring бина – время существования класса. Spring бины инициализируются при инициализации Spring контейнера и происходит внедрение всех зависимостей. Когда контейнер уничтожается, то уничтожается и всё содержимое. Если нам необходимо задать какое-либо действие при инициализации и уничтожении бина, то нужно воспользоваться методами init() и destroy(). Для этого можно использовать аннотации @PostConstruct и @PreDestroy(). изненный цикл Spring бина – время существования класса. Spring бины инициализируются при инициализации Spring контейнера и происходит внедрение всех зависимостей. Когда контейнер уничтожается, то уничтожается и всё содержимое. Если нам необходимо задать какое-либо действие при инициализации и уничтожении бина, то нужно воспользоваться методами init() и destroy(). Для этого можно использовать аннотации @PostConstruct и @PreDestroy().Spring не управляет полным жизненным циклом bean-компонента со Scope prototype. Контейнер создаёт, настраивает и иным образом собирает объект-prototype и передаёт его клиенту без дальнейшей записи этого экземпляра-prototype. То есть нам необходимо самостоятельно вызывать метод destroy() после того, как бин prototype выполнил свои функции. Иначе это приведёт к дорогостоящим потерям ресурсов. В некоторых отношениях роль IoC контейнера Spring в отношении bean-объекта с прототипом является заменой new оператора Java. Все управление жизненным циклом после этой точки должно выполняться клиентом. |
| 7. Наследование бинов? |
| Определение бина может содержать множество различных конфигураций (конструктор, методы инициализации и уничтожения и т.д.). - Наследованием (когда мы говорим о бинах) называется ситуация, когда “бин-потомок” перенимает (наследует) конфигурационные данные от своего “бина-родителя”. Бин-наследник может переопределять (override) некоторые унаследованные свойства и добавлять свои собственные, если это потребуется. - При этом важно учитывать тот факт, что наследование бинов в Spring не имеет ничего общего с наследованием классов в Java. Сам принцип наследования, тем не менее, остаётся тем же. - Другими словами, Вы можете определить некий шаблонный бин и, наследуясь от него, добавлять необходимый функционал в “бины-потомки”. |
| 8. Чем отличается Spring Bean, JavaBean и POJO классы? |
| P  OJO (plain-old-Java-object) – это класс запущенный с базовым JDK, без поддержки других сторонних библиотек. OJO (plain-old-Java-object) – это класс запущенный с базовым JDK, без поддержки других сторонних библиотек.Все JavaBeans — это POJO, но не все POJO — это JavaBeans. POJO не имеет строгого определения. Пример класса POJO. JavaBean— это объект Java, который удовлетворяет определенным соглашениям программирования: 1) Класс JavaBean должны реализовать Serializable или externalizable; 2) Класс JavaBean должен иметь публичный конструктор (без аргументов); 3) Все свойства JavaBean должны иметь публичные методы setter и getter (соответственно); 4  ) Все переменные экземпляра JavaBean должны быть приватными. ) Все переменные экземпляра JavaBean должны быть приватными.Spring bean – это объект, который создаётся, настраивается и управляется контейнером Spring Framework. Компоненты Spring определяются в файлах конфигурации Spring (или, в последнее время, с аннотациями), создаются экземплярами контейнеров Spring и затем вводятся в приложения. Spring Beans не всегда являются JavaBeans. Spring beans может не реализовывать интерфейс java.io.Serializable, и может иметь аргументы в своих конструкторах и т. д. Это основное различие между JavaBeans и Spring Beans. |
| 9. Что такое DTO? (Data Transfer Object) |
| DTO объект - Java объект, который не содержит методы. Он может содержать только поля, геттеры/сеттеры, и конструкторы. Его цель: пересылать данные между процессами для уменьшения количества вызовов методов. Data Transfer Object - объект, передающий данные. Данные - это и есть поля в классе. Реальный пример - игра шашки. У вас есть объект Checker(шашка). У него не должно быть методов, только поля. Если у Checker есть методы(переопределенный equals и compare(к примеру)), но это методы из Object и он всё ещё может считаться DTO объектом, т.к. он сделан только для того, что бы хранить данные(координаты шашки). |
| 10. Что такое связывание бинов? Какие подходы к связыванию бинов? |
| Когда запускается программное приложение, совместно работают сразу несколько объектов (бинов). Также они могут использоваться независимо от других объектов. Чтобы заставить бины работать вместе, их связывают через введение зависимостей в Spring (привязки). Когда запускается приложение на основе Spring, контекст приложения загружает определения компонентов или объектов из файла конфигурации и связывает их вместе. Существует два подхода к привязке bean-компонентов в среде Spring: - Привязка через XML. constructor-arg – Определяет конструктор, использующийся для внедрения зависимости в XML-файле. properties – Определяет свойства внедрения зависимости в XML-файле. - Привязка через классы Java. (@Autowired) См. далее. |
| 11. Какие есть способы связывания бинов? |
| Существует два способа привязки bean-компонентов в среде Spring: 1) Вручную, объявив bean-компоненты с помощью Dependency Injection (DI). 2) Позволить контейнеру Spring самостоятельно связать необходимые компоненты. Последний способ известен как автоматическая привязка. При этом контейнеру Spring нужно указать, как он должен их связывать: 1) autowirebyName – автоматическое связывание по имени бина. Контейнер Spring ищет в XML файле бин с указанным именем. И если находит бин с таким же именем – производит автоматическое связывание. 2) autowirebyType – автоматическое связывание по типу. В этом случае контейнер Spring ищет совпадение по типу. В случае, если он находит – происходит автоматическое связывание. Если в XML-файле определены несколько бинов с таким типом, то мы получаем исключение (exception). 3) autowirebyconstructor – здесь всё происходит так же, как и при использовании режима ‘byType’, с тем отличием, что поиск идёт по аргументам конструктора. Если в XML-файле находится несколько таких бинов – мы получаем ошибку (error). 4) autodetect– в этом режиме сначала происходит связывание в режиме ‘constructor’, а затем (если автосвязывание не произошло) в режиме ‘byType’. |
| |