Хочешь, хорошо работать пользуйся Спрингом. Хочешь, чтобы работало хорошо знай его кишки. Навигация
 Скачать 4.45 Mb. Скачать 4.45 Mb.
|

|
1) Catalina Фактически Catalina — это контейнер сервлетов внутри Tomcat. Catalina реализует спецификацию Servlet API — основную веб-технологию в web-программировании на Java. 2) Jasper Позволяет использовать технологию JSP. Это как HTML-файлы, только в них встроен Java-код, который может исполняться в момент отправки страницы пользователю. Это позволяет динамически встраивать в страницу любые данные. Jasper превращает Java код в HTML, и отслеживает изменения автоматически обновляя их. 3) Coyote Прослушивает HTTP-запросы от клиента на определенном порту, предоставляет эти данные для обработки в приложении, а также возвращает пользователям ответы. То есть Coyote реализует функционал HTTP-сервера. Хорошая статья на эту тему! | ||
| 3. Файлы servlet-api.jar, web.xml и index.jsp, что зачем и почему? | ||
| Чтобы создать свой первый сервлет, нужно использовать библиотеку servlet-api.jar, который поставляется вместе с Tomcat (можно найти в папке lib). В src, как всегда — исходники, а в папке web сгенерированы web.xml и index.jsp. web.xml — это инструкция для Tomcat, где искать обработчики запросов и прочая информация. web.xml, «расскажет» Tomcat о том, как пользоваться нашим сервлетом. index.jsp — главная страница веб-приложения, куда пользователь должен попасть в первую очередь (речь идет о конфигурации по умолчанию). 1  ) Тег web-app является корневым тэгом. Он может содержать дополнительные атрибуты, но нам они в данный момент не нужны. Все остальные тэги находятся внутри него. ) Тег web-app является корневым тэгом. Он может содержать дополнительные атрибуты, но нам они в данный момент не нужны. Все остальные тэги находятся внутри него.2) Тег servlet определяет имя сервлета и указывает путь к классу-сервлету, который будет обрабатывать запросы. В нашем случае мы поместили наш класс в пакет students.web и полное имя класса будет students.web.HelloWorldServlet. 3) Тег servlet-mapping. Здесь мы определяем URL, который пользователь будет запрашивать для получения данных от нашего сервлета. Мы определяем какой сервлет будет обрабатывать введённый URL. Т  ег — welcome-file-list — указывает файл, который будет вызван при переходе на url /. Нужно настраивать, если существует потребность изменить файл по-умолчанию. ег — welcome-file-list — указывает файл, который будет вызван при переходе на url /. Нужно настраивать, если существует потребность изменить файл по-умолчанию.Посмотри сюда! | ||
| 4. Возможно ли запустить Java-приложение без main-метода? (Нет, нельзя.) | ||
| При использовании Tomcat нам не нужен main метод. У Tomcat есть собственный метод main, который вызывается при запуске сервера. | ||
| 5. Что такое Artifacts? Отличие war от war exploded? | ||
| Артефакты - в широком смысле это некие объекты создаваемые в ходе разработки ПО, например схемы классов, объектные коды, документация, инструкции, иконки, картинки и проч. всё что сопровождает процесс разработки. В узком смысле - в Intellij IDEA это некая выходная сборка вашего проекта. В общем случае их может быть несколько: jar для десктопа и .war для веба ну и т.д. Для каждого артефакта можно определить правила сборки, развёртывания, запуска и т.д. Есть ещё артефакты в Maven — это всё тот же архив, но предназначенный для деплоймента на репозиторий maven. В самом, Java нет понятия артефакта - артефакт продукт среды/средства разработки. П  ри установке Tomcat мы нажимаем кнопку Fix и выбираем war exploded: это значит, что после пересборки проекта, артефакт будет автоматически помещаться в контейнер сервлетов. ри установке Tomcat мы нажимаем кнопку Fix и выбираем war exploded: это значит, что после пересборки проекта, артефакт будет автоматически помещаться в контейнер сервлетов.war отличается от war exploded — тем, что war создаст только один файл war (который является архивом), а вариант с exploded — это просто «распакованный» war. И именно такой вариант удобен, так как позволяет быстрее деплоить мелкие изменения на сервер. По сути, артефакт — это и есть наш проект, только уже скомпилированный, и в котором изменена структура папок так, чтобы его можно было выкладывать уже напрямую на томкат. | ||
| Транзакции В НАЧАЛО ДОКУМЕНТА | ||
| 1. Что такое транзакции и CRUD приложение? | ||
| Когда мы работаем с БД, то чаще всего нам нужно выполнить одно из 4 действий: создать, прочитать, изменить или удалить (для этого набора действий существует аббревиатура CRUD – Create Read Update Delete). Если мы хотим выполнить одно из таких действий нам нужно выполнить транзакцию. Когда мы говорим о транзакциях в контексте БД, то мы имеем в виду последовательность действий с конечным количеством операций для достижения определённой цели, которая рассматривается как единое целое. Другими словами, если одна из операций в последовательности не выполнена, то вся последовательность считается не выполненной. Управление транзакциями является важной частью любой системы управления базой данных (СУБД), оно обеспечивает целостность и однозначность данных. | ||
| 2. Основные концепции транзакций (ACID)? | ||
| Основные концепции транзакции описываются аббревиатурой ACID – Atomicity, Consistency, Isolation, Durability (Атомарность, Согласованность, Изолированность, Долговечность). В реальной жизни любая качественная СУБД поддерживает все эти 4 концепции для каждой транзакции. 1) Атомарность - Атомарность гарантирует, что любая транзакция будет зафиксирована только целиком (полностью). Если одна из операций в последовательности не будет выполнена, то вся транзакция будет отменена. Тут вводится понятие “отката” (rollback). Т.е. внутри последовательности будут происходить определённые изменения, но по итогу все они будут отменены (“откачены”) и по итогу пользователь не увидит никаких изменений. 2) Согласованность — Это означает, что любая завершённая транзакция (транзакция, которая достигла завершения транзакции) фиксирует только допустимые результаты. Например, при переводе денег с одного счёта на другой, в случае если деньги ушли с одного счёта, они должны прийти на другой (это и есть согласованность системы). Списание и зачисление – это две разные транзакции, поэтому первая транзакция пройдёт без ошибок, а второй просто не будет. Именно поэтому крайне важно учитывать это свойство и поддерживать баланс системы. 3) Изолированность - Каждая транзакция должна быть изолирована от других, т.е. её результат не должен зависеть от выполнения других параллельных транзакций. На практике, изолированность крайне труднодостижимая вещь, поэтому здесь вводится понятие “уровни изолированности” (транзакция изолируется не полностью). 4) Долговечность - Эта концепция гарантирует, что если мы получили подтверждение о выполнении транзакции, то изменения, вызванные этой транзакцией, не должны быть отменены из-за сбоя системы (например, отключение электропитания). | ||
| 3. Виды управления транзакциями в Spring? (2 вида) | ||
| 1) Программный – способ управления транзакциями с помощью программирования. Этот способ более сложный для чтения и поддержки, чем декларативный, но даёт большую гибкость. 2) Декларативный – в случае декларативного управления транзакциями мы отделяем бизнес-логику от управления транзакциями. Мы используем либо аннотации, либо XML-файл для конфигурации управления транзакциями. Чаще всего используется декларативный метод управления транзакциями. Хоть этот метод и менее гибкий, чем программный, он может быть модульным. Декларативный метод реализован с помощью модуля АОП Spring является альтернативой EJB, который требует сервер для запуска приложения, в то время как управление транзакциями в Spring может быть реализовано без сервера приложения. | ||
| 4. Какие интерфейсы отвечают за транзакции в Spring и их методы? (3 интерфейса, 13 методов) | ||
| 1) Главные абстракции транзакций в Spring определены в интерфейсе PlatformTransactionManager, который находится в пакете org.springframework.transaction. В нём указаны 3 метода: - TransactionStatus getTransaction(TransactionDefinition definition) – Этот метод возвращает текущую активную транзакцию, либо создаёт новую в соответствии с определением. - void commit(TransactionStatus status); – Этот метод выполняет транзакцию в соответствии с её статусом. - void rollback(TransactionStatus status); – Этот метод выполняет откат транзакции. 2) Интерфейс TransactionDefinition включает в себя 5 методов: - int getPropagationBehavior() – Возвращает метод распространения. - int getIsolationLevel() – Возвращает уровень изолирования. - String getName() – Возвращает имя транзакции. - int getTimeout() – Возвращает время в секундах, в течение которого транзакция должна быть завершена. - boolean isReadOnly() – метод возвращает (true или false) доступен ли файл исключительно для чтения. 3) TransactionStatus, обеспечивает простой способ контроля за статусом выполнения транзакции. 5 методов: - boolean hasSavepoint() – Этот метод возвращает логическое значение, имеет ли данная транзакция точку сохранения. - boolean isCompleted() – Возвращает логическое значение завершена ли данная транзакция (успешно завершена, либо выполнен откат). - boolean isNewTransaction() – Возвращает логическое значение, является ли текущая транзакция новой. - boolean isRollbackOnly() – Возвращает логическое значение, была ли эта транзакция отмечена, как rollback-only. - void setRollbackOnly() – Этот метод устанавливает параметр транзакции rollback-only. | ||
| HTTP, REST, Прокси В НАЧАЛО ДОКУМЕНТА | ||
| 1. Что такое HTTP и HTTPS? (HyperText Transfer Protocol) | ||
| HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам). Задача, которая решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины. Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS. Н 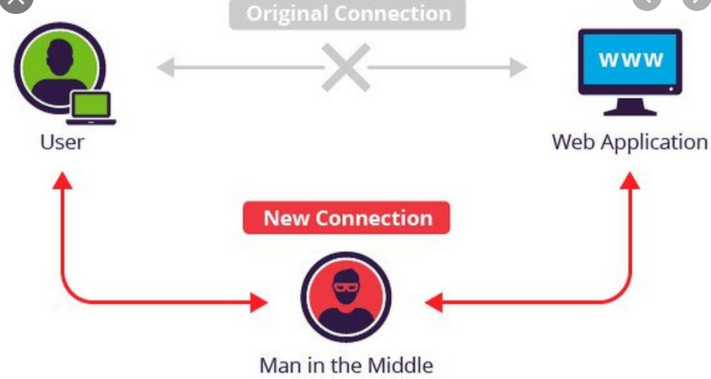 азвание этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника. азвание этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.На данный момент HTTPS поддерживается всеми популярными веб-браузерами. Подробнее тут! | ||
| 2. Какие методы есть в HTTP? (GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, TRACE, PATCH) | ||
| GET - Метод используется для получения информации от сервера по заданному URI. Запросы с использованием этого метода могут только извлекать данные. HEAD - такой же, как и GET, но в ответ сервер посылает только заголовки и строку запроса без тела HTTP ответа. POST - используется для отправки данных на сервер, например, из HTML форм, заполняемых посетителем сайта. PUT - заменяет все текущие представления ресурса данными в запросе. DELETE - удаляет указанный URI ресурс. CONNECT - устанавливает "туннель" к серверу, определённому по ресурсу. OPTIONS - используется для получения параметров, текущего HTTP соединения с ресурсом. TRACE - выполняет вызов возвращаемого тестового сообщения с ресурса. Благодаря этому клиент может увидеть, что происходит с сообщением на всех узлах передачи. PATCH - используется для частичного изменения ресурса. | ||
| 3. Какие из методов HTTP являются идемпотентными? Что такое безопасность методов? | ||
| И 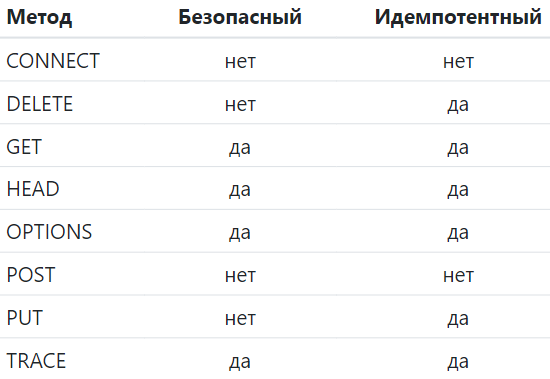 демпотентность — это свойство объекта или операции при повторном применении операции к объекту давать тот же результат, что и при первом. демпотентность — это свойство объекта или операции при повторном применении операции к объекту давать тот же результат, что и при первом. С точки зрения RESTful-сервиса, операция (или вызов сервиса) идемпотентна тогда, когда клиенты могут делать один и тот же вызов неоднократно при одном и том же результате, работая как "сеттер" в языке программирования. Другими словами, создание большого количества идентичных запросов имеет такой же эффект, как и один запрос. Заметьте, что в то время, как идемпотентные операции производят один и тот же результат на сервере, ответ может не быть тем же самым (состояние ресурса может измениться между запросами). Методы PUT и DELETE по определению идемпотентны. Тем не менее, есть один нюанс с методом DELETE. Проблема в том, что успешный DELETE-запрос возвращает статус 200 (OK) или 204 (No Content), но для последующих запросов будет всё время возвращать 404 (Not Found), если только сервис не сконфигурирован так, чтобы "помечать" ресурс как удалённый без его фактического удаления. Как бы то ни было, когда сервис на самом деле удаляет ресурс, следующий вызов не найдет этот ресурс и вернет 404. Состояние на сервере после каждого вызова DELETE то же самое, но ответы разные. Методы GET, HEAD, OPTIONS и TRACE определены как безопасные, что также делает их идемпотентными. Эти методы предназначены только для получения информации и не должны изменять состояние сервера. Они не должны иметь побочных эффектов, за исключением безобидных, таких как: логирование, кеширование, показ баннерной рекламы или увеличение веб-счётчика, то есть не модифицируют ресурсы. Если использовать эти методы не по назначению и позволять им менять состояние сервера, то они перестают быть безопасными (логично да). Не выполнение этого свойства может вызвать проблемы для веб-кеширования, поисковых систем и других автоматизированных агентов, которые непреднамеренно будут изменять состояние сервера. По определению, безопасные операции идемпотентны, так как они приводят к одному и тому же результату на сервере. Безопасные методы реализованы как операции только для чтения. Однако безопасность не означает, что сервер должен возвращать тот же самый результат каждый раз. | ||
| 4. Что такое REST? (набор правил). Что такое REST сервер и REST клиент? Почему он используется в HTTP? | ||
| П  роблема в том, что, мы можем использовать методы HTTP по своему усмотрению. Например, удалять данные методом GET, или получать их с сервера методом POST. Для сервера разницы нет. Ему по барабану, он исполняет заложенную логику в контроллерах. По сути, мы можем использовать методы GET и POST для всех операций, остальные являются не обязательными. Такой подход написания кода чреват большими проблемами в будущем, будет очень сложно ориентироваться в методах контроллера. Одним словом “ЖОПА”. Здесь на сцену выходит REST который задаёт правила использования HTTP методов и всё это как-то стандартизирует. роблема в том, что, мы можем использовать методы HTTP по своему усмотрению. Например, удалять данные методом GET, или получать их с сервера методом POST. Для сервера разницы нет. Ему по барабану, он исполняет заложенную логику в контроллерах. По сути, мы можем использовать методы GET и POST для всех операций, остальные являются не обязательными. Такой подход написания кода чреват большими проблемами в будущем, будет очень сложно ориентироваться в методах контроллера. Одним словом “ЖОПА”. Здесь на сцену выходит REST который задаёт правила использования HTTP методов и всё это как-то стандартизирует.REST — это просто набор соглашений о том, как красиво использовать HTTP и его методы. Representational State Transfer — передача состояния представления. Архитектурный стиль взаимодействия компонентов распределённой системы в компьютерной сети. Проще говоря, REST определяет стиль взаимодействия (обмена данными) между разными компонентами системы, каждая из которых может физически располагаться в разных местах. Компоненту, которая отправляет запрос называют клиентом; компоненту, которая обрабатывает запрос и отправляет клиенту ответ, называют сервером. Запросы и ответы, чаще всего, отправляются по протоколу HTTP. Как правило сервер — это некое веб-приложение. Клиентом же может быть что угодно. Например: 1) Мобильное приложение, которое запрашивает у сервера данные. 2) Браузер, который отправляет запросы с веб-страницы на сервер для загрузки данных. 3) Вообще другой сервер, который получил запрос от клиента, но по каким-либо причинам не может обработать его самостоятельно, поэтому сам становится клиентом обращаясь к ещё одному серверу в надежде получить ответ. Яркий пример DNS серверы. Попробуйте перейти на Американский сайт Стэнфордского университета, если отследить цепочку обращений, там будет задействовано сразу несколько серверов клиентов. Про DNS смотрите самостоятельно. Однако не каждая система, чьи компоненты обмениваются данными посредством запросов-ответов, является REST (или же RESTfull) системой. Чтобы система считалась RESTfull, она должна “вписываться” в шесть REST ограничений: | ||
| 5. Ограничения REST? | ||
| 1) Client-Server. Отделяя пользовательский интерфейс от хранилища данных, мы улучшаем переносимость пользовательского интерфейса на другие платформы и улучшаем масштабируемость серверных компонент засчёт их упрощения. 2) Stateless (без состояния). Каждый запрос от клиента к серверу должен содержать в себе всю необходимую информацию и не может полагаться на какое-либо состояние, хранящееся на стороне сервера. Таким образом, информация о текущей сессии должна целиком храниться у клиента. 3) Cacheable (кэшируемость). Это ограничение требует, чтобы для данных в ответе на запрос явно было указано -- можно их кэшировать или нет. Если ответ поддерживает кэширование, то клиент имеет право повторно использовать данные в последующих эквивалентных запросов без обращения на сервер. 4) Uniform interface (единообразие интерфейса). Если применить к системе инженерный принцип общности/единообразия, то архитектура всего приложения станет проще, а взаимодействие станет прозрачнее и понятнее. Для выполнения этого принципа необходимо придерживаться нескольких архитектурных ограничений. REST накладывает на интерфейс четыре ограничения: 1) идентичность ресурсов; 2) манипуляция над ресурсами через представление; 3) исчерпывающие, понятные человеку сообщения; 4) гипермедиа (hypermedia) как движок для состояния приложения (HATEOAS) -- ссылки на другие ресурсы внутри приложения. 5) Layered system (многоуровневая система). Многоуровневость достигается за счёт ограничения поведения компонентов таким образом, что компоненты "не видят" другие компоненты, кроме расположенных на ближайших уровнях, с которыми они взаимодействуют. 6) Code on demand (код по мере необходимости, не обязательное ограничение). REST позволяет наращивать функциональность клиентского приложения по мере необходимости при помощи скачивания и исполнения кода в виде апплетов или скриптов. Это упрощает клиентские приложения, уменьшая количество заранее написанных возможностей. Написано довольно непонятно. Лучше посмотрите тут и вот тут. | ||
| 6. Есть ограничения, а какие преимущества они дают в REST? | ||
| У приложений, которые соблюдают все вышеперечисленные ограничения, есть такие преимущества: - надёжность (не нужно сохранять информацию о состоянии клиента, которая может быть утеряна); - производительность (за счёт использования кэша); - масштабируемость; - прозрачность системы взаимодействия; - простота интерфейсов; - портативность компонентов; - лёгкость внесения изменений; - способность эволюционировать, приспосабливаясь к новым требованиям. | ||
| 7. Возникают ли какие-нибудь проблемы при использовании REST в приложении? | ||
| Да, есть небольшая проблема с применением REST на практике. Проблема эта называется HTML. PUT/DELETE запросы можно отправлять через XMLHttpRequest, посредством обращения к серверу «вручную» (через curl или через telnet), но нельзя сделать HTML-форму, отправляющую полноценный PUT/DELETE-запрос. Дело в том, что спецификация HTML не позволяет создавать формы, отправляющие данные иначе, чем через GET или POST. Поэтому для нормальной работы с другими методами приходится имитировать их искусственно, и к сожалению, этим мы не занимались в наших задачах. | ||
| Что ещё можно рассказать про REST? (расшифровка акронима, ресурс, безопасность) | ||
| REST это передача состояний ресурса между сервером и клиентом. Representational — ресурсы в REST могут быть представлены в любой форме — JSON, XML, текст, или даже HTML — зависит от того, какие данные больше подходят потребителю. State — при работе с REST вы должны быть сконцентрированы на состоянии ресурса, а не на действиях с ресурсом Transfer — REST включает в себя передачу ресурсных данных, в любой представленной форме, от одного приложения другому. Информация о клиенте не должна хранится на стороне сервера, а должна передаваться каждый раз туда, где она нужна. Вот что значит ST в REST, State Transfer. Вы передаёте состояние, а не храните его на сервере. Ресурс в REST — это всё, что может быть передано между клиентом и сервером. Ресурсом является всё у чего есть имя. Пользователь, изображение, предмет, майка, голодная собака. REST безопасен? Как вы можете защитить его? – По умолчанию REST не защищен. Можно настроить безопасность с помощью Basic Auth, JWT, OAuth2. Об этом читаем ниже в Security. | ||
| 8. Что такое URI, URL, URN, какая нафиг разница? | ||
| U  RL - Uniform Resource Locator (унифицированный определитель местонахождения ресурса) RL - Uniform Resource Locator (унифицированный определитель местонахождения ресурса)http://example.com/mypage.html ftp://example.com/download.zip URN - Unifrorm Resource Name (унифицированное имя ресурса). Всегда начинается с префикса urn: urn:isbn:0451450523 для идентификации книги по её ISBN номеру. urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66 глобальный уникальный идентификатор URI - Uniform Resource Identifier (унифицированный идентификатор ресурса). Абстракция концепции идентификации. Т.е. мы можем считать, что: URI = URL или URI = URN или URI = URL + URN. Короче если везде говорить URI, будешь выглядеть умнее и точно не ошибёшься. | ||
| 9. Из чего состоят Запрос и Ответ? | ||
| Клиентские запросы практически всегда сделаны по протоколу HTTP. HTTP запрос состоит из трёх частей: - Строка запроса – указывает метод передачи, URL-адрес, к которому нужно обратиться и версию протокола HTTP, так же может содержать параметры, следующие после вопросительного знака ?key1=value1&key2=value2. - Заголовки – описывают тело сообщений, передают различные параметры, сведения и информацию. (  например Content-type": "application/json), например Content-type": "application/json),- Тело сообщения — это сами данные, которые передаются в запросе. Тело сообщения – это необязательный параметр и может отсутствовать. Серверные ответы также состоят из трёх частей: - Код состояния/ответа, - Заголовки (пример — Content-Type: text/html), в целом заголовки ответов мало чем отличаются от заголовков запросов. К тому же, некоторые заголовки используются и в ответах, и в запросах. - Тело ответа – так же не является обязательным. Почитай вот тут. Большая статья. | ||
| 10. Свои заголовки можно создавать? Чем отличается Content-type от Accept в заголовке? | ||
| С  вои заголовки можно создавать. Как мы это делали в задаче с JS Fetch, прописывая их в headers, указывали метод отправки, можно указать cookie, формат отправки тела запроса, определить ход загрузки документа и т.д. вои заголовки можно создавать. Как мы это делали в задаче с JS Fetch, прописывая их в headers, указывали метод отправки, можно указать cookie, формат отправки тела запроса, определить ход загрузки документа и т.д.Content-type для указания формата данных при отправке в контроллер. Accept для формата ответа. | ||
| 11. Как Get и Post отправляют данные на сервер? | ||
| И Get и Post отправляют данные на сервер. Get передаёт данные отображая их в адресной строке, что, во-первых, не безопасно, во-вторых, данные могут быть слишком длинные и не поместиться в URL из-за ограничений браузеров. Многие формы используются для получения информации с сервера, без изменения содержимого в БД. Для таких форм поиска идеально подходит метод GET. POST же передаёт их без указания содержимого в адресной строке что обеспечивает больший уровень безопасности личных данных и лучше подходит для работы с большими объёмами данных. При отправке данных используется URL-кодирование Name=Jonathan+Doe&Age=23.
Если у вас спросят, можно ли отправлять GET и POST запросы через URL, то ответ – можно и POST тоже можно. Но не через адресную строку браузера (она всегда отправляет GET запросы), а через программу POSTMAN (Рекомендую протестировать). | ||
| 12. Какие существуют коды состояния/ответа запросов HTTP? Их очень много. | ||
| Код состояния HTTP — это часть строки заголовка, ответа веб сервера на запрос клиента, информирующая о результате запроса и о том, что клиент(пользователь) должен предпринять далее. 100 коды являются информационными. Например, 102 ответ говорит о том, что запрос принят, но на его обработку понадобится длительное время. 200 сигнализируют об успешном выполнении. 300 связаны с перенаправлениями. Например, 307 ответ говорит о том, что запрашиваемый ресурс на короткое время доступен по-другому URI, или 301 Ресурс перемещен постоянно, или 302 Ресурс перемещен временно. 400 коды сигнализируют об ошибке клиента(пользователя). Например, 400 — это неправильно составленный запрос, который возможно имеет неверный формат, или же широко известный код 404 Not Found, который может возникнуть, когда клиент запрашивает несуществующий ресурс. 401 Несанкционированный доступ — у пользователя нет прав для доступа к запрошенному документу. 402 Ресурс доступен за плату. 408 Тайм-аут запроса. 500 коды говорят о внутренней ошибке сервера — ошибка помешала НТТР - серверу обработать запрос. Весь список кодов тут | ||
| 13. Что такое MIME? (расшифровывается как многоцелевые расширения интернет-почты) | ||
| Тип MIME состоит из двух частей: типа и подтипа. Они разделены косой чертой (/). например, тип MIME для файлов Microsoft Word— это приложение, а подтип-msword. Вместе полный тип MIME — это application/msword. Тип MIME — это метка, используемая для идентификации типа данных. Он используется для того, чтобы программное обеспечение могло знать, как обрабатывать данные. Поэтому, если сервер говорит: "это text/html" то клиент понимает "Ах, это документ HTML", а если сервер говорит: "это application/pdf" то клиент понимает "Ах, мне нужно запустить плагин PDF Reader, который пользователь установил и который зарегистрировался как обработчик приложения/pdf." Ч  аще всего их можно найти в заголовках сообщений HTTP (для описания содержимого, на которое отвечает сервер HTTP, или форматирования данных, которые используются в запросе POST) и в заголовках email (для описания формата сообщения и вложений). аще всего их можно найти в заголовках сообщений HTTP (для описания содержимого, на которое отвечает сервер HTTP, или форматирования данных, которые используются в запросе POST) и в заголовках email (для описания формата сообщения и вложений).- text/plain - обычный неформатированный текст (MIME-тип по умолчанию); - text/html - гипертекст; - image/jpg - JPEG-изображения; - audio/mp3 - MP3-аудиозаписи; - multipart/mixed - текст с разнообразными вложениями. Если интересно какие ещё бывают типы MIME. Подробнее про заголовки, MIME, URI можно почитать тут! | ||
| 14. Какая разница между Хешированием и Шифрованием? | ||
| Хеширование — это преобразование входных данных в уникальную последовательность символов, из которой невозможно получить исходное значение. Сюда входят md5, bCrypt, SHA и т.д. Применяется "соль". Хеширование – идеальный способ сохранить пароли, поскольку значения хеша, односторонние и имеют фиксированную длину. Шифрование преобразует какие-либо данные в серию нечитабельных людскому глазу знаков, которые не имеют фиксированной длины. Смысл шифрования — сделать исходное сообщение нечитаемым для любого, кто не владеет ключом. Основное отличие между шифрованием и хешированием – то, что зашифрованные последовательности могут быть повернуты назад в их оригинальную расшифрованную форму, если конечно соответствующий ключ имеется. А вот хешируемые уже никак не повернёшь назад. | ||
| 15. Что такое прокси? | ||
| Прокси-сервер — это дополнительное звено между вами и интернетом. Некий посредник, который отделяет человека от посещаемого сайта. Создаёт условия, при которых сайт думает, что прокси — это и есть реальный человек. Прокси обычно используется для: - Для обеспечения конфиденциальности. Чтобы сайты не знали, кто именно их посещает. - Для повышения уровня безопасности при выходе в сеть. Базовые атаки будут направлены именно на прокси. - Ещё он нужен, чтобы получать доступ к контенту, который существует только в определенной локации. - Чтобы ускорить доступ к некоторым ресурсам в интернете. - Ну и для того, чтобы получить доступ к заблокированным страницам. Сайтам, мессенджерам и так далее. | ||
| 16. Типы прокси-серверов? | ||
| 1) Прозрачные – Такой прокси-сервер не утаивает от посещаемого сайта никакой информации. Во-первых, он честно сообщит ему о том, что является прокси, а во-вторых, передаст сайту IP-адрес пользователя по ту сторону сервера. С подобным типом можно встретиться в публичных заведениях, школах. 2) Анонимные – Более востребованный тип прокси. В отличие от первого, он тоже заявляет посещаемому ресурсу о своей proxy-сущности, но личные данные клиента не передаёт. То есть будет предоставлять обезличенную информацию для обеих сторон. Правда, неизвестно, как поведёт себя сайт, который на 100% знает, что общается с proxy. 3) Искажающие – Такие прокси тоже идентифицируют себя честно, но вместо реальных пользовательских данных передают подставные. В таком случае сайты подумают, что это вполне себе реальный человек, и будут вести себя соответствующе. Например, предоставлять контент, доступный только в конкретном регионе. 4) Приватные – Вариант для параноиков. Такие прокси регулярно меняют IP-адреса, постоянно выдают фальшивые данные и заметно сокращают шансы веб-ресурсов отследить трафик и как-то связать его с клиентом. | ||
| 17. Что такое межсайтовая подделка запроса CSRF? | ||
| По умолчанию Spring Security защищает любой входящий запрос POST (или PUT / DELETE / PATCH) с помощью действительного токена CSRF. C  SRF (англ. cross-site request forgery — «межсайтовая подделка запроса», также известна как XSRF) — вид атак на посетителей веб-сайтов, использующий недостатки протокола HTTP. Если жертва заходит на сайт, созданный злоумышленником, от её лица тайно отправляется запрос на другой сервер (например, на сервер платёжной системы), осуществляющий некую вредоносную операцию (например, перевод денег на счёт злоумышленника). Для осуществления данной атаки жертва должна быть аутентифицирована на том сервере, на который отправляется запрос, и этот запрос не должен требовать какого-либо подтверждения со стороны пользователя. SRF (англ. cross-site request forgery — «межсайтовая подделка запроса», также известна как XSRF) — вид атак на посетителей веб-сайтов, использующий недостатки протокола HTTP. Если жертва заходит на сайт, созданный злоумышленником, от её лица тайно отправляется запрос на другой сервер (например, на сервер платёжной системы), осуществляющий некую вредоносную операцию (например, перевод денег на счёт злоумышленника). Для осуществления данной атаки жертва должна быть аутентифицирована на том сервере, на который отправляется запрос, и этот запрос не должен требовать какого-либо подтверждения со стороны пользователя.Атака осуществляется путём размещения на веб-странице ссылки или скрипта, пытающегося получить доступ к сайту, на котором атакуемый пользователь заведомо (или предположительно) уже аутентифицирован. Например, пользователь Алиса может просматривать форум, где другой пользователь, Боб, разместил сообщение. Пусть Боб создал тег Подробнее тут! | ||
| 18. Что такое Кликджекинг? | ||
| К  ликджекинг (буквально, «угон кликов») – это очередной мошеннический интернет-прием, при котором пользователь, сам того не зная, делает то, чего не собирался. Это реализовано благодаря невидимым элементам, расположенным поверх кнопок, на которые пользователь захочет кликнуть. Таким образом, переходя по интересной ссылке или пытаясь включить видео, вы поневоле нажимаете на другой элемент, выполняющий принципиально иные действия. Это могут быть относительно безобидные лайки в Фейсбуке, о которых вы никогда и не узнаете, но возможны и варианты, что, совершив такой клик вы оставите свои персональные данные, которыми воспользуется недобросовестный владелец сайта. И хорошо, если он просто вычислит ваш номер и позвонит, пытаясь продать свой товар, но персональную информацию можно использовать и в куда более корыстных целях, когда вы останетесь в минусе. ликджекинг (буквально, «угон кликов») – это очередной мошеннический интернет-прием, при котором пользователь, сам того не зная, делает то, чего не собирался. Это реализовано благодаря невидимым элементам, расположенным поверх кнопок, на которые пользователь захочет кликнуть. Таким образом, переходя по интересной ссылке или пытаясь включить видео, вы поневоле нажимаете на другой элемент, выполняющий принципиально иные действия. Это могут быть относительно безобидные лайки в Фейсбуке, о которых вы никогда и не узнаете, но возможны и варианты, что, совершив такой клик вы оставите свои персональные данные, которыми воспользуется недобросовестный владелец сайта. И хорошо, если он просто вычислит ваш номер и позвонит, пытаясь продать свой товар, но персональную информацию можно использовать и в куда более корыстных целях, когда вы останетесь в минусе. | ||
| Spring Security В НАЧАЛО ДОКУМЕНТА | ||
| 1. Что такое Spring Security? | ||
| Spring Security — это фреймворк, набор фильтров сервлетов, которые помогают добавить аутентификацию, авторизацию и защиту от распространённых атак в ваше веб-приложение. Благодаря поддержке как императивных, так и реактивных приложений, это де-факто стандарт защиты приложений на основе Spring. Spring Security может быть дополнен нужным функционалом. Модуль Spring Security позволяет нам внедрять права доступа, а также контролировать их исполнение без ручных проверок. Spring Security базируется на 2х интерфейсах, которые определяют связь сущностей с секьюрностью: UserDetails и GrantedAuthority. UserDetails - то, что будет интерпретироваться системой как пользователь. GrantedAuthority - сущность, описывающая права юзера. Аутентификация и авторизация должны выполняться до того, как запрос попадёт в ваши @Controllers. | ||
| 2. Как подключить Spring Security к проекту? | ||
| Самым фундаментальным объектом является SecurityContextHolder. В нём хранится информация о текущем контексте безопасности приложения, который включает в себя подробную информацию о пользователе (принципале), работающим с приложением. Spring Security использует объект Authentication, пользователя авторизованной сессии. Д   ля начала создаём проект с применением Maven (фреймворк для автоматизации сборки проектов). Потом добавляем зависимости в pom файл, Такие как на скриншоте + сервлеты, коннектор к базе данных и т.д. Если приложении на Spring Boot, то добавляем spring-boot-starter-security и spring-boot-starter-webmvc. После настройки зависимостей, начинаем настраивать контроллер и конфигурационные классы секьюрити. ля начала создаём проект с применением Maven (фреймворк для автоматизации сборки проектов). Потом добавляем зависимости в pom файл, Такие как на скриншоте + сервлеты, коннектор к базе данных и т.д. Если приложении на Spring Boot, то добавляем spring-boot-starter-security и spring-boot-starter-webmvc. После настройки зависимостей, начинаем настраивать контроллер и конфигурационные классы секьюрити. Класс SecurityConfig содержит аннотацию @EnableWebMvcSecurity для включения поддержки безопасности Spring Security и Spring MVC интеграцию. Он также расширяет WebSecurityConfigurerAdapter и переопределяет пару методов для установки некоторых настроек безопасности. Метод configure(HttpSecurity) определяет, какие URL пути должны быть защищены авторизацией, а какие нет. Ко всем остальным путям должна быть произведена аутентификация. Когда пользователь успешно войдёт в систему, он будет перенаправлен на предыдущую запрашиваемую страницу, требующую авторизацию. Для того чтобы обеспечить секьюрность проекту, нам нужно: 1) «Пользователь» – это просто Object. Для того, чтобы в дальнейшим использовать класс User в Spring Security, он должен реализовывать интерфейс UserDetails, потом переопределяем getAuthorities() - он возвращает список ролей пользователя. UserDetails можно представить, как адаптер между БД пользователей и тем что требуется Spring Security внутри SecurityContextHolder. 2) Role. Этот класс должен реализовывать интерфейс GrantedAuthority, в котором необходимо переопределить только один метод getAuthority() (возвращает имя роли). Имя роли должно соответствовать шаблону: «ROLE_ИМЯ», например, ROLE_USER. Кроме конструктора по умолчанию необходимо добавить ещё пару публичных конструкторов: первый принимает только id, второй id и name. UserService. Содержит методы для бизнес-логики приложения. Этот класс реализует интерфейс UserDetailsService (необходим для Spring Security), в котором нужно переопределить один метод loadUserByUsername(). | ||
| 3. Что такое аутентификация и двухфакторная аутентификация? | ||
| А  утентификация — это то, как мы проверяем личность того, кто пытается получить доступ к определенному ресурсу. Обычный способ аутентификации пользователей - требовать от пользователя ввода имени и пароля. После выполнения аутентификации мы узнаём личность и можем выполнить авторизацию. утентификация — это то, как мы проверяем личность того, кто пытается получить доступ к определенному ресурсу. Обычный способ аутентификации пользователей - требовать от пользователя ввода имени и пароля. После выполнения аутентификации мы узнаём личность и можем выполнить авторизацию.- Президент: «Я президент США. Мой username is: potus!» - Ваше веб-приложение: "Конечно, а какой у вас password, господин президент?" - Президент: «Мой пароль: th3don4ld». - Ваше веб-приложение: "Верно. Добро пожаловать, сэр!" Примеры двухфакторной аутентификации — авторизация Google. Когда пользователь заходит с нового устройства, помимо аутентификации по логину-паролю его просят ввести шестизначный (Google) код подтверждения. Абонент может получить его по SMS или с помощью голосового звонка на его телефон. В простых приложениях аутентификации может быть достаточно: как только пользователь аутентифицируется, он может получить доступ ко всем частям приложения. Смотри тут! | ||
| 4. Как происходит аутентификация в Spring Security. Варианты хранения информации о пользователях? | ||
| Когда дело доходит до аутентификации и Spring Security, у вас есть примерно три сценария: 1) По умолчанию : вы можете получить доступ к (хешированному) паролю пользователя, потому что у вас есть его данные (имя пользователя, пароль), сохранённые, например, в таблице БД. 2) Реже : вы не можете получить доступ к (хешированному) паролю пользователя. Это тот случай, если ваши пользователи и пароли хранятся где - то ещё, например, в стороннем продукте управления идентификацией, предлагающем услуги REST для аутентификации. 3) Популярно : вы хотите использовать OAuth2 или «Войти через Google / Twitter и т.д». (OpenID), скорее всего, в сочетании с JWT. Тогда ничего из следующего не применимо, и вам следует сразу перейти к изучению OAuth2. В зависимости от выбора сценария вам необходимо указать разные @Beans, чтобы Spring Security работал, иначе вы получите довольно запутанные исключения (например, NullPointerException, если вы забыли указать PasswordEncoder). Запомни. Давайте посмотрим на два основных сценария (1)UserDetailsService и (2)AuthenticationProvider. | ||
| 5. Что такое UserDetailsService? (есть доступ к паролю пользователя) | ||
| Представьте, что у вас есть таблица базы данных, в которой вы храните своих пользователей. В нём есть пара столбцов, но, что наиболее важно, в нём есть столбец с именем пользователя и паролем, в котором вы храните хешированный (!) Пароль пользователя. В  этом случае Spring Security необходимо определить два bean-компонента для запуска и запуска аутентификации. этом случае Spring Security необходимо определить два bean-компонента для запуска и запуска аутентификации.1) UserDetailsService. 2) PasswordEncoder - Кодировщик паролей. Указать UserDetailsService очень просто: UserDetailsServiceImpl реализует UserDetailsService, очень простой интерфейс, который состоит из одного метода, возвращающего объект UserDetails: 1 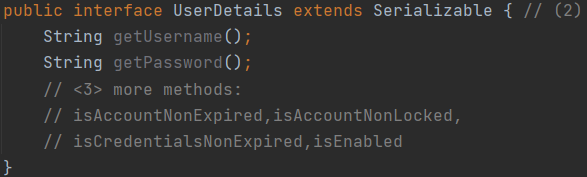 ) UserDetailsService загружает UserDetails через имя пользователя. Обратите внимание, что loadUserByUsername принимает только один параметр: имя пользователя (не пароль). ) UserDetailsService загружает UserDetails через имя пользователя. Обратите внимание, что loadUserByUsername принимает только один параметр: имя пользователя (не пароль).2) Интерфейс UserDetails имеет методы для получения (хешированного!) Пароля и один для получения имени пользователя. 3) UserDetails имеет еще больше методов, например, активна или заблокирована учетная запись, срок действия учётных данных истёк или какие разрешения есть у пользователя, но мы не будем их здесь рассматривать. Эти интерфейсы можно реализовать самостоятельно, как мы сделали выше, или использовать (настроить/расширить/переопределить.) существующие реализации, которые предоставляет Spring Security, например: 1) JdbcUserDetailsManager, который представляет собой UserDetailsService на основе JDBC (базы данных). Вы можете настроить его в соответствии с вашей пользовательской структурой таблицы/столбца. 2) InMemoryUserDetailsManager, хранит все пользовательские данные в памяти и отлично подходит для тестирования. 3) org.springframework.security.core.userdetail.User, является разумной реализацией UserDetails по умолчанию. Это означало бы возможное отображение/копирование между вашими объектами/таблицами БД и этим пользовательским классом. В качестве альтернативы вы можете просто заставить свои сущности реализовывать интерфейс UserDetails. |