Ответы на вопросы по языкам программирования. Вопросы к экзамену. Инф Вопросы для подготовки к экзамену (3 курс) Метод нисходящего проектирования программы
 Скачать 0.64 Mb. Скачать 0.64 Mb.
|

|
Задача. Реализовать в виде модуля набор подпрограмм для выполнения следующих операций над обыкновенными дробями вида P/Q (P — целое, Q — натуральное): 1) сложение; 2) вычитание; 3) умножение; 4) деление; 5) сокращение дроби; 6) возведение дроби в степень N (N — натуральное); 7) функции, реализующие операции отношения (равно, не равно, больше или равно, меньше или равно, больше, меньше). Дробь представить следующим типом: Type Frac = Record P : Integer; Q : 1.. High(LongInt) End; Используя этот модуль, решить задачи: 1. Дан массив A — массив обыкновенных дробей. Найти сумму всех дробей, ответ представить в виде несократимой дроби. Вычислить среднее арифметическое всех дробей, ответ представить в виде несократимой дроби. 2. Дан массив A — массив обыкновенных дробей. Отсортировать его в порядке возрастания. Unit Droby; Interface Type Natur = 1..High(LongInt); Frac = Record P : LongInt; {Числитель дроби} Q : Natur {Знаменатель дроби} End; Procedure Sokr(Var A : Frac); Procedure Summa(A, B : Frac; Var C : Frac); Procedure Raznost(A, B : Frac; Var C : Frac); Procedure Proizvedenie(A, B : Frac; Var C : Frac); Procedure Chastnoe(A, B : Frac; Var C : Frac); Procedure Stepen(A : Frac; N : Natur; Var C : Frac); Function Menshe(A, B : Frac) : Boolean; Function Bolshe(A, B : Frac) : Boolean; Function Ravno(A, B : Frac) : Boolean; Function MensheRavno(A, B : Frac) : Boolean; Function BolsheRavno(A, B : Frac) : Boolean; Function NeRavno(A, B : Frac) : Boolean; {Раздел реализации модуля} Implementation {Наибольший общий делитель двух чисел - вспомогательная функция, ранее не объявленная} Function NodEvklid(A, B : Natur) : Natur; Begin While A <> B Do If A > B Then If A Mod B <> 0 Then A := A Mod B Else A := B Else If B Mod A <> 0 Then B := B Mod A Else B := A; NodEvklid := A End; Procedure Sokr; {Сокращение дроби} Var M, N : Natur; Begin If A.P <> 0 Then Begin If A.P < 0 Then M := Abs(A.P) Else M := A.P; {Совмещение типов, т.к. A.P - LongInt} N := NodEvklid(M, A.Q); A.P := A.P Div N; A.Q := A.Q Div N End End; Procedure Summa; {Сумма дробей} Begin {Знаменатель дроби} C.Q := (A.Q * B.Q) Div NodEvklid(A.Q, B.Q); {Числитель дроби} C.P := A.P * C.Q Div A.Q + B.P * C.Q Div B.Q; Sokr(C) End; Procedure Raznost; {Разность дробей} Begin {Знаменатель дроби} C.Q := (A.Q * B.Q) Div NodEvklid(A.Q, B.Q); {Числитель дроби} C.P := A.P * C.Q Div A.Q - B.P * C.Q Div B.Q; Sokr(C) End; Procedure Proizvedenie; Begin {Знаменатель дроби} C.Q := A.Q * B.Q; {Числитель дроби} C.P := A.P * B.P; Sokr(C) End; Procedure Chastnoe; Begin {Знаменатель дроби} C.Q := A.Q * B.P; {Числитель дроби} C.P := A.P * B.Q; Sokr(C) End; Procedure Stepen; {Степень} Var I : Natur; Begin C.Q := 1; C.P := 1; Sokr(A); For I := 1 To N Do Proizvedenie(A, C, C) End; Function Menshe; Begin Menshe := A.P * B.Q < A.Q * B.P End; Function Bolshe; Begin Bolshe := A.P * B.Q > A.Q * B.P End; Function Ravno; Begin Ravno := A.P * B.Q = A.Q * B.P End; Function BolsheRavno; Begin BolsheRavno := Bolshe(A, B) Or Ravno(A, B) End; Function MensheRavno; Begin MensheRavno := Menshe(A, B) Or Ravno(A, B) End; Function NeRavno; Begin NeRavno := Not Ravno(A, B) End; {Раздел инициализации модуля} Begin End. Дадим некоторые рекомендации по разработке модулей: 1) спроектировать модуль, т.е. выделить основные и вспомогательные подпрограммы, другие ресурсы; 2) каждую подпрограмму целесообразно отладить отдельно, после чего «вклеить» в текст модуля. Сохраним текст разработанной программы в файле DROBY.PAS и откомпилируем наш модуль. Для этого можно воспользоваться внешним компилятором, поставляемым вместе с Turbo Pascal. Команда будет выглядеть так: TPC DROBY.PAS. Если в тексте нет синтаксических ошибок, получим файл DROBY.TPU, иначе будет соответствующее сообщение с указанием строки, содержащей ошибку. Другой способ компиляции модуля — в среде программирования Turbo Pascal выбрать в пункте меню Run подпункты Make или Build (при этом должна быть включена компиляция на диск). Теперь можно подключить модуль к программе, где планируется его использование. Для примера решим задачу суммирования массива дробей. Program Sum; Uses Droby; Var A : Array[1..100] Of Frac; I, N : Integer; S : Frac; Begin Write('Введите количество элементов массива: '); ReadLn(N); S.P := 0; S.Q := 1; {Первоначально сумма равна нулю} For I := 1 To N Do {Вводим и суммируем дроби} Begin Write('Введите числитель ', I, '-й дроби: '); ReadLn(A[I].P); Write('Введите знаменатель ', I, '-й дроби: '); ReadLn(A[I].Q); Summa(A[I], S, S); End; WriteLn('Ответ: ', S.P, '/', S.Q) End. Вторую задачу предлагаем решить читателю самостоятельно. Как видно из примера, для подключения модуля используется служебное слово USES, после чего указывается имя модуля и происходит это сразу же после заголовка программы. Если необходимо подключить несколько модулей, они перечисляются через запятую. При использовании ресурсов модуля совсем не нужно знать, как работают его подпрограммы. Достаточно обладать информацией, как выглядят их заголовки и какое действие эти подпрограммы выполняют. По такому принципу осуществляется работа со всеми стандартными модулями. Поэтому, если программист разрабатывает модули не только для личного пользования, ему необходимо сделать полное описание всех доступных при подключении ресурсов. В таком случае возможна полноценная работа с таким продуктом. Ещё несколько слов о видимости объектов модуля. Если в программе, использующей модуль, имеются идентификаторы, совпадающие с точностью до символа с идентификаторами модуля, то они «перекрывают» соответствующие ресурсы модуля. Тем не менее, даже в такой ситуации доступ к этим ресурсам модуля может быть получен таким образом: <имя модуля>.<имя ресурса>. Модуль для работа с экраном и клавиатурой. Модуль - это подключаемая к программе библиотека ресурсов. Он может содержать описания типов, констант, переменных и подпрограмм. В модуль обычно объединяют связанные между собой ресурсы: например, в составе оболочки есть модуль Graph для работы с экраном в графическом режиме. Модули применяются либо как библиотеки, которые могут использоваться различными программами, либо для разбиения сложной программы на составные части. Использование модулей позволяет преодолеть ограничение в один сегмент на объем кода исполняемой программы, поскольку код каждого подключаемого к программе модуля содержится в отдельном сегменте. Модули можно разделить на стандартные, которые входят в состав системы программирования, и пользовательские, то есть создаваемые программистом. Чтобы подключить модуль к программе, его требуется предварительно скомпилировать. Результат компиляции каждого модуля хранится на диске в отдельном файле с расширением .tpu. Описание модулей Исходный текст каждого модуля хранится в отдельном файле с расширением .pas. Общая структура модуля: unit имя; { заголовок модуля } interface { интерфейсная секция модуля } { описание глобальных элементов модуля (видимых извне) } implementation { секция реализации модуля } { описание локальных (внутренних) элементов модуля } begin { секция инициализации } { может отсутствовать } end. ВНИМАНИЕ Имя файла, в котором хранится модуль, должно совпадать с именем, заданным после ключевого слова unit. Модуль может использовать другие модули, для этого их надо перечислить в операторе uses, который может находиться только непосредственно после ключевых слов interface илиimplementation. В интерфейсной секции модуля определяют константы, типы данных, переменные, а также заголовки процедур и функций. В секции реализации описываются подпрограммы, заголовки которых приведены в интерфейсной части. Заголовок подпрограммы должен быть или идентичным указанному в секции интерфейса, или состоять только из ключевого слова procedure или function и имени подпрограммы. Для функции также указывается ее тип. Кроме того, в этой секции можно определять константы, типы данных, переменные и внутренние подпрограммы. Секция инициализации предназначена для присваивания начальных значений переменным, которые используются в модуле. Операторы, расположенные в секции инициализации модуля, выполняются перед операторами основной программы. Для сохранения скомпилированного модуля на диске требуется установить значение пункта Destination меню Compile в значение Disk. Компилятор создаст файл с расширением .tpu. Использование модулей Для использования в программе величин, описанных в интерфейсной части модуля, имя модуля указывается в разделе uses. Можно записать несколько имен модулей через запятую, например: program example; uses Average, Graph, Crt; Поиск модулей выполняется сначала в библиотеке исполняющей системы, затем в текущем каталоге, а после этого - в каталогах, заданных в диалоговом окне Options/Directories. Если в программе описана величина с тем же именем, что и в модуле, для обращения к величине из модуля требуется перед ее именем указать через точку имя модуля. Стандартные модули Паскаля В Паскале имеется ряд стандартных модулей, в которых описано большое количество встроенных констант, типов, переменных и подпрограмм. Каждый модуль содержит связанные между собой ресурсы. Модуль System Модуль содержит базовые средства языка, которые поддерживают ввод-вывод, работу со строками, операции с плавающей точкой и динамическое распределение памяти. Этот модуль автоматически используется во всех программах, и его не требуется указывать в операторе uses. Он содержит все стандартные и встроенные процедуры, функции, константы и переменные Паскаля. Модуль Crt Модуль предназначен для организации эффективной работы с экраном, клавиатурой и встроенным динамиком. При подключении модуля Crt выводимая информация посылается в базовую систему ввода-вывода (ВIОS) или непосредственно в видеопамять. В текстовом режиме экран представляется как совокупность строк и столбцов. Каждый символ располагается на так называемом знакоместе на пересечении строки и столбца. Символы хранятся в специальной части оперативной памяти, называемой видеопамятью. Ее содержимое отображается на экране. Под каждый символ отводится два байта: один байт занимает ASCII-код символа, другой байт хранит атрибуты символа: его цвет, цвет фона и признак мерцания. Можно получить восемь различных цветов фона и 16 цветов символов. Модуль Crt позволяет: выполнять вывод в заданное место экрана заданным цветом символа и фона; открывать на экране окна прямоугольной формы и выполнять вывод в пределах этих окон; очищать экран, окно, строку и ее часть; обрабатывать ввод с клавиатуры; управлять встроенным динамиком. Работа с экраном Текущие цвета символа и фона задаются с помощью процедур TextColor и TextBackGround и действуют на следующие за ними процедуры вывода. Вывод выполняется в текущую позицию курсора. Для ее изменения служит процедура GotoXY. Окно определяется с помощью процедуры Window. Оно задается координатами левого верхнего и правого нижнего угла. Очистка текущего окна выполняется с помощью процедуры ClrScr, которая заполняет его пробелами с текущим цветом фона и устанавливает курсор в левый верхний угол. Работа с клавиатурой Модуль Crt позволяет работать с управляющими клавишами и комбинациями клавиш. Нажатие каждой клавиши преобразуется либо в ее ASCII-код, либо в так называемый расширенный код (scan-код) и записывается в буфер клавиатуры, из которого затем и выбирается процедурами ввода. Под каждый код отводится два байта. Если нажатие клавиш соответствует символу из набора ASCII, в первый байт заносится код символа. Если нажата, к примеру, клавиша курсора, функциональная клавиша или комбинация клавиш с CTRL или ALT, то первый байт равен нулю, а во втором находится расширенный код, соответствующий этой комбинации. Для работы с клавиатурой модуль Crt содержит функции ReadKey и KeyPressed. Модули Dos и WinDos Модули Dos и WinDos содержат подпрограммы, реализующие возможности операционной системы MS-DOS - например, переименование, поиск и удаление файлов, получение и установку системного времени, выполнение программных прерываний и так далее. Эти подпрограммы в стандартном Паскале не определены. Для поддержки подпрограмм в модулях определены константы и типы данных. Модуль Dos использует строки Паскаля, а WinDos - строки с завершающим нулем. Модуль Graph Модуль обеспечивает работу с экраном в графическом режиме. Экран в графическом режиме представляется в виде совокупности точек - пикселов. Цвет каждого пиксела можно задавать отдельно. Начало координат находится в левом верхнем углу экрана и имеет координаты (0, 0). Количество точек по горизонтали и вертикали (разрешение экрана) и количество доступных цветов зависят от графического режима. Графический режим устанавливается с помощью служебной программы - графического драйвера. В состав оболочки входит несколько драйверов, каждый из может работать в нескольких режимах. Режим устанавливается при инициализации графики либо автоматически, либо программистом. Модуль Graph обеспечивает: вывод линий и геометрических фигур заданным цветом и стилем; закрашивание областей заданным цветом и шаблоном; вывод текста различным шрифтом, заданного размера и направления; определение окон и отсечение по их границе; использование графических спрайтов и работу с графическими страницами. В отличие от текстового режима, в графическом курсор невидим. Перед выводом изображения необходимо определить его стиль, то есть задать цвет фона, цвет линий и контуров, тип линий, шаблон заполнения, вид и размер шрифта, и так далее. Эти параметры устанавливаются с помощью соответствующих процедур. Возможные значения параметров определены в модуле Graph в виде многочисленных констант. Структура графической программы Программа, использующая графический режим, должна содержать следующие действия: подключение модуля Graph; перевод экрана в графический режим; установку параметров изображения; вывод изображения; возврат в текстовый режим. Графическая библиотека подключается в операторе 1. В графический режим экран переводится в операторе 2 вызовом процедуры InitGraph. Ей надо передать три параметра: номер графического драйвера (grDriver), его режим grMode и путь к каталогу, в котором находятся драйверы. Если параметр grDriver равен константе Detect, заданной в модуле Graph, выбор режима выполняется автоматически. Если графический режим выбирался автоматически, для позиционирования изображений на экране необходимо получить доступное количество точек по X и по Y с помощью функцийGetMaxX и GetMaxY (оператор 4). В данной программе с помощью этих функций формируются координаты центра экрана. В цикле (оператор 5) выводится серия линий с небольшой задержкой. Цвет линий изменяется случайным образом через каждые 10 итераций. Следующий фрагмент программы демонстрирует работу с графическими спрайтами, которые применяются для вывода движущихся изображений. Для увеличения скорости отрисовки изображение формируется один раз, после чего заносится в память с помощью процедуры GetImage (оператор 9). Объем памяти, необходимый для размещения спрайта, определяется с помощью процедуры ImageSize, выделение памяти выполняет процедура GetMem (оператор 8). При формировании изображения использована процедура установки стиля закраскиSetFillStyle (оператор 6). Он используется процедурой рисования закрашенного эллипсаFillEllipse. Стиль линии, задающий повышенную толщину линии, устанавливается процедурой SetLineStyle (оператор 7). Этот стиль действует при выводе отрезка (Line) и дуги (Arc). Для вывода спрайта используется процедура PutImage. Ее четвертый параметр задает способ сочетания выводимого изображения и фона. Операция исключающего ИЛИ (она задается константой XorPut), примененная дважды, позволяет оставить неизменным фон, по которому движется изображение (цикл 10). Перед выводом текста устанавливается его стиль (оператор 11). Стиль текста состоит из имени шрифта, его расположения (горизонтальное или вертикальное) и масштаба. В модуле Graph имеется один растровый шрифт и несколько векторных. Каждый символ растрового шрифта определяется точечной матрицей 8 х 8, символ векторного шрифта задается набором кривых. В конце программы восстанавливается исходный режим экрана (оператор 12). Модуль Strings Модуль предназначен для работы со строками, заканчивающимися нуль-символом, то есть символом с кодом 0 (их часто называют ASCIIZ-строки). Модуль содержит функции копирования, сравнения, слияния строк, преобразования их в строки типа string, поиска подстрок и символов. В модуле System определен тип pChar, представляющий собой указатель на символ (^Char). Этот тип можно использовать для работы со строками, заканчивающимися #0. Эти строки располагаются в динамической памяти, и программист должен сам заниматься ее распределением. Кроме того, для хранения ASCIIZ-строк используются массивы символов с нулевой базой, например: var str : array[0 .. 4000] of char; p: pChar; Массивы символов с нулевой базой и указатели на символы совместимы. Графические возможности языка. графический язык это тот тип общения, который использует графику, изображения и математические выражения для выражения и передачи мыслей или идей. Рисунок, в частности наскальные рисунки верхнего палеолита, подчеркивает как одну из первых попыток человека преодолеть этот тип языка. Таким образом, с момента своего создания графический язык был тесно связан с развитием цивилизации. Его использовали для выражения красоты и чувств в великих ренессансных картинах. Он также задал тон для объяснения новых идей, теорий и открытий с помощью математических формул, теорем и диаграмм.. За последние 300 лет он стал незаменимым для человеческой расы, иногда выше устной и письменной речи. С развитием вычислительной техники и кибернетики этот тип языка стал интерфейсом для приложений видеоигр и других компьютерных специальностей.. 1 Характеристики графического языка 1.1 Легкость и скорость 1.2 Универсальность 1.3 Высокий удар 1.4 Одновременность 1.5 Более высокие затраты 2 типа 2.1 Иллюстративный 2.2 Художественный 2.3 Графический дизайн 2.4 Типографский 2.5 Фотографический 3 примера 3.1 Иллюстративный 3.2 Художественный 3.3 Графический дизайн 3.4 Типографский 3.5 Фотографический 4 Ссылки Пользовательские модули. Модули в Паскале по отношению к основной части программы напоминают подпрограммы (процедуры и функции). Но по определению они являются самостоятельными программами, ресурсы которых могут быть задействованы в других программах. Кроме того описание модулей происходит вне вызывающего приложения, а в отдельном файле, поэтому модуль – это отдельно компилируемая программа. Файл скомпилированного модуля (именно такой нужен для использования) будет иметь расширение предусмотренное средой программирования (например, .tpu, .ppu, .pcu). Модули создаются, как правило, для обеспечения компактности кода, о чем приходиться заботиться крупным проектам. Стоит также отметить, что использование модулей в каком-то смысле снимает ограничение на сегментацию памяти, так как код каждого модуля располагается в отдельном сегменте. Структура модуля выглядит так: Unit <имя модуля>; Interface <интерфейсная часть> Implementation <исполняемая часть> Begin <инициализация> End. Понятие статических и динамических переменных. 1) Статические переменные хранения обычно назначаются единицам хранения во время определения переменной и остаются неизменными до конца всей программы. Статические переменные, глобальные динамические переменные являются статическим хранилищем 2) Динамическая переменная памяти выделяется во время выполнения программы, единица хранения используется, когда она используется, и она освобождается сразу после использования 3) Статические переменные хранения существуют постоянно, в то время как динамические переменные хранения время от времени исчезают. Обычно характеристики из-за различных методов хранения переменных называются временем жизни переменных 4) Статическое хранилище будет инициализировано только один раз Описание и представление динамических переменных. Динами́ческая переме́нная — переменная в программе, место в оперативной памяти под которую выделяется во время выполнения программы. По сути, она является участком памяти, выделенным системой программе для конкретных целей во время работы программы. Этим она отличается от глобальной статической переменной - участка памяти, выделенного системой программе для конкретных целей перед началом работы программы. Динамическая переменная — один из классов памяти переменной. Так как динамическая переменная создаётся во время выполнения программы, во многих языках программирования у неё нет собственного идентификатора. Работа с динамической переменной ведётся косвенно, через указатель. Создание такой переменной заключается в выделении участка памяти с помощью специальной функции. Эта функция возвращает адрес в памяти, который назначается указателю. Процесс доступа к памяти через указатель называется разыменованием. После окончания работы с динамической переменной выделенную под неё память необходимо освободить — для этого тоже есть специальная функция. Пример создания динамической переменной с помощью указателя в языке Pascal: type tMyArray = array [1..3] of real; var pMyArray = ^tMyArray; begin new (pMyArray); {выделение памяти под массив из трех чисел} pMyArray^[1] := 1.23456; pMyArray^[2] := 2.71828; pMyArray^[3] := 3.14159; ...... В языках программирования относительно низкого уровня указатели используются явно, что чревато серьёзными ошибками. В языках более высокого уровня динамические типы данных могут быть оформлены как динамические массивы. Пример создания динамического массива в языке Delphi: var MyArray = array of real; begin SetLength(MyArray,3); {выделение памяти под массив из трех чисел} MyArray[0] := 1.23456; {в Delphi динамические массивы нумеруются в си-образном стиле: от 0 до n-1} MyArray[1] := 2.71828; MyArray[2] := 3.14159; ...... В языках высокого уровня динамические типы данных могут быть оформлены и другим способом - как классы, а процессы выделения и освобождения памяти описаны в конструкторе и деструкторе каждого класса. Структура "линейный однонаправленный список". Способы создания. Одной из наиболее простых операций со всеми типами списков является их прохождение, т.е. поочерёдное получение доступа ко всем элементам. Приведём процедуру, реализующую эту операцию для просмотра списка (другие варианты использования прохождения – поиск данных и сохранение списка в файл). В случае перемещения по 2-связному списку в "прямом" направлении эта процедура является одинаковой для 1- и 2-связного линейных списков.
Поиск по списку. Поиск в списке является вариантом операции просмотра и отличается тем, что: 1. вместо операции вывода на экран (cout< 2. если искомые данные найдены, нет необходимости перемещаться по списку дальше. Поиск в односвязных списках имеет следующую особенность. Если он выполняется в сочетании с удалением, то результатом поиска может (или должно) быть не то звено, в котором содержатся искомые данные, а предшествующее ему. В итоге для поиска в списке могут потребоваться либо две различные процедуры – "обычная" и находящая предыдущее звено, либо одна универсальная, позволяющая найти оба звена – с искомыми данными и предшествующее ему. Рассмотрим в качестве примера именно этот вариант
Ведущее (или заглавное) звено. Все приведённые выше примеры на языке Си++ подразумевают наличие в списке ведущего звена. Создаваться это звено может либо отдельной процедурой, либо следующим набором операторов (эти же операторы и будут находиться в процедуре): Link1 *L1 = new Link1; // Выделение памяти под звено L1->next = NULL; // Ведущее звено одновременно является последним Вставка звена в список (частный и общий случаи). Процедуры добавления и удаления звеньев являются критическими с точки зрения сохранения целостности списка. При неправильном выполнении этих процедур (т.е. при неправильной очерёдности выполнения операций присваивания) возможны 2 ошибочные ситуации: 1. Список "рвётся" по месту вставки или удаления звена, и звено, оказавшее последним, замыкается либо само на себя (чаще всего) (т.е. указатель next или аналогичный ему в этом звене получает значение адреса этого же звена), либо на одно из предшествующих звеньев (в зависимости от неправильной реализации операций вставки или удаления звена). При попытке просмотра списка процедура просмотра зацикливается и бесконечно выводит содержимое одного и того же звена (или нескольких звеньев). 2. Список так же "рвётся" по месту вставки или удаления звена, но указатель в звене, ставшем последним, получает какое-то произвольное значение, которое трактуется как адрес следующего звена (реально не существующего), у которого также есть указатель next, содержащий какой-то адрес, и так далее, до тех пор, пока случайно не попадётся блок данных, для которого указатель next не будер равен нулю. При попытке просмотра списка на дисплей сначала выводятся правильные данные, а затем случайный набор символов. В обоих случаях к звеньям в "оторвавшейся" части ("хвосте") списка больше нет доступа, и хранящиеся в них данные можно считать потерянными. Для предовращения возникновения таких ошибок следует соблюдать правильный порядок проведения связей (т.е. присваивания указателей) при вставке нового звена и удалении существующего (очерёдность операций указана):
Удаление звена из списка (частный и общий случаи). Удаление звена из любого места списка за ведущим звеном: void Delete1(Link1* link) // link - звено, предшествующее удаляемому { Link1* q; if (link->next) // Проверка на наличие звена, следующего за link { q = link->next // 1 Запоминание удаляемого звена для операции delete link->next = q->next; // 2 Проведение новой связи в обход удаляемого звена delete q; // 3 Очистка памяти } } Кольцевой однонаправленный список. Особенности обработки кольцевых списков. Если значение указателя последнего звена линейного односвязного списка заменить с nil (или NULL) на адрес ведущего звена, то линейный список превратится в односвязный кольцевой список. Для двусвязного списка, кроме того, нужно заменить с nil на адрес последнего звена значение второго указателя в ведущем звене. Получится двусвязный кольцевой (циклический) список. В односвязном кольцевом списке можно переходить от последнего звена к заглавному, а в двусвязном - еще и от заглавного к последнему. Односвязный кольцевой список выглядит так:  Рис. 9.4 - Кольцевой односвязный список Кольцевой список, как и линейный, идентифицируется как единый программный объект указателем, например L1, значением которого является адрес заглавного звена. Возможен другой вариант организации кольцевого списка:  Рис. 9.5 - Кольцевой односвязный список. Второй вариант Оба варианта сопоставимы по сложности. Для первого варианта проще выполняется вставка нового элемента как в начало списка (после заглавного звена), так и в конец - так как вставка звена в конец кольцевого списка эквивалентна вставке перед заглавным звеном, но каждый раз при циклической обработке списка нужно проверять, не является ли текущее звено заглавным (или нс совпадает ли текущее звено с точкой начала обработки). Рассмотрим операции с кольцевыми списками. Отсутствие «последнего» звена приводит к ещё большему упрощению операций добавления и удаления, по сравнению с одно- и двусвязным линейным списком. Например, для односвязного кольцевого списка в процедуре удаления отсутствует оператор if - проверка на существование звена, следующего за заданным (в кольцевом списке такое звено всегда есть). Такие же операторы отсутствуют в процедурах добавления и удаления звеньев для двусвязного кольцевого списка. При циклической обработке кольцевого списка нужно учесть, что формально последнего звена нет. Процедуры и программа работы с двусвязным кольцевым списком на языке Паскаль. Туре ге!2 = Ле1ет2; elem2 = record next: rel 1; prev: re!2; data: <Тип хранимых данных> end; list2 - re!2; procedure insert2(pred: re!2; info: <Тип>); var q: re!2; begin new(q); (* Создание нового звена *) qA.data := info; qA.next := predA.next; qA.prev := predA.nextA.prev; predA.next.prev := q; predA.next := q end; При вставке в начало списка (после заглавного звена) нужно указать в качестве аргумента pred адрес заглавного звена, то есть указатель на список L2. procedure delete2(del: re!2); begin delA.nextA.prev := delA.prev; delA.prevA.next := delA.next; dispose(del); end; function search2(list: re!2; info: <Тип>; var point: re!2): boolean; var p,q: rel2; b: boolean; begin b := false; point := nil; p := list; q := pA.next; while (p <> q) and (not b) do begin if qA.data = info then begin b := true; point := q end; q := qA.next end; search? := b end; var 12: list2; r: rel2; begin (* Создание заглавного звена *) new(r); rA.next := r; rA.pred := r; 12 := r; end. Структура доступа к данным "стек". Принцип LIFO. Стек (stack) — это структура данных, представляющая собой специализированным образом организованный список элементов. Доступ к элементам стека осуществляется по принципу LIFO (Last In First Out) — последним пришел, первым вышел. Принцип работы данной структуры данных схож с магазином автоматического огнестрельного оружия. Патроны помещаются в магазин сверху вниз, а используется всегда только верхний патрон. Давайте рассмотрим пример реализации стека на языке C#. На рисунке ниже представлена схематичная структура стека. 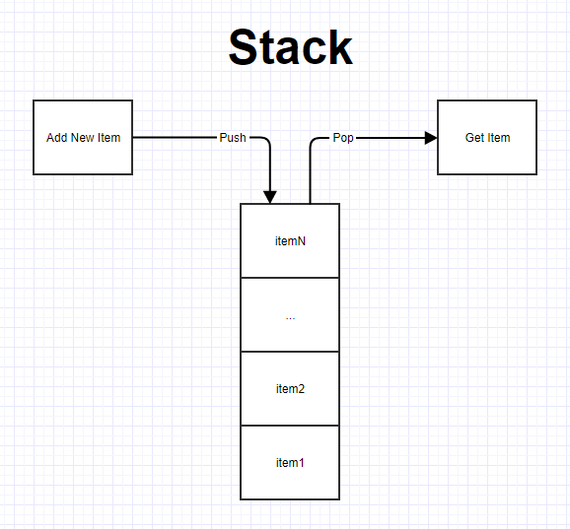 У стека есть верхний элемент, с которым и выполняются все три основные манипуляции: Push — добавить новый элемент в стек. При этом этот элемент станет верхним. Pop — удалить верхний элемент из стека сохранив в переменную. При этом верхним станет элемент расположенный ниже удаленного. Peek — прочитать верхний элемент стека, без удаления. При этом верхний элемент останется неизменным. Теперь приступим к реализации данного класса. Мы будем использовать обобщенный класс. Для хранения данных воспользуемся списком. Данная реализация является весьма примитивной, но позволяет разобраться со структурой и алгоритмом работы данного типа данных. Класс стека 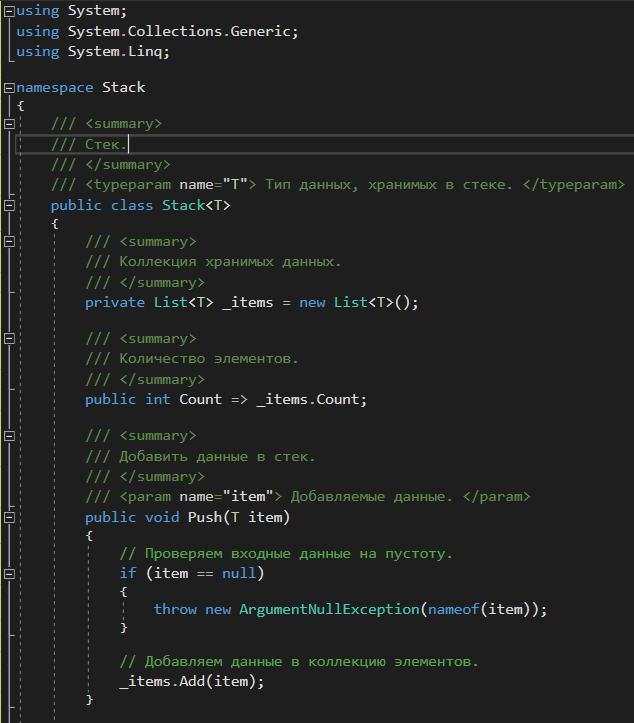 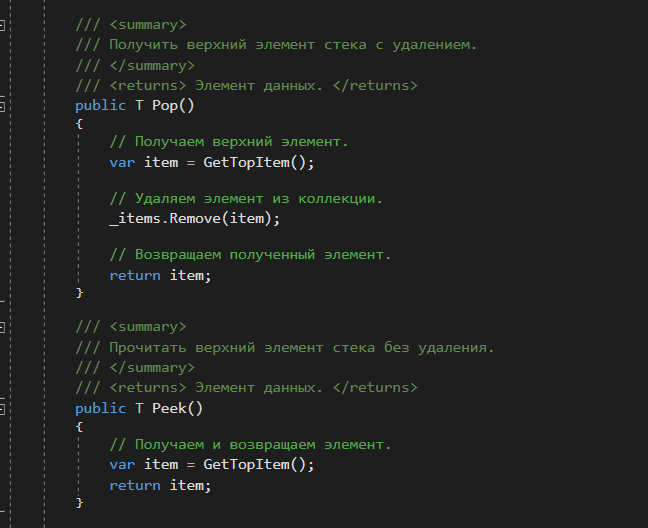 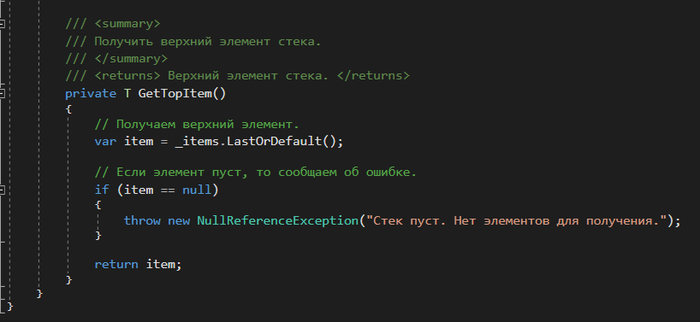 Работа со стеком  Результат работы приложения 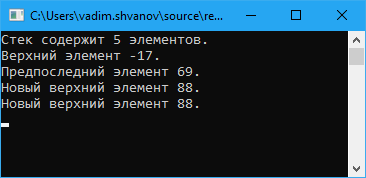 Заключение На платформе .NET уже есть готовая реализация данной структуры данных. Она содержится в пространстве имен System.Collections и называется аналогично Stack. Я не претендую на правильность, оптимальность и красоту реализации. Единственная цель, которую я преследую, поделиться полезной информацией о программировании, которая может кому-то пригодиться. В данном примере просто показана идея такой структуры данных как стек. Структура доступа к данным "очередь". Принцип FIFO. Очередь (англ. queue) — это структура данных, добавление и удаление элементов в которой происходит путём операций pushpush и poppop соответственно. Притом первым из очереди удаляется элемент, который был помещен туда первым, то есть в очереди реализуется принцип «первым вошел — первым вышел» (англ. first-in, first-out — FIFO). У очереди имеется голова (англ. head) и хвост (англ. tail). Когда элемент ставится в очередь, он занимает место в её хвосте. Из очереди всегда выводится элемент, который находится в ее голове. Очередь поддерживает следующие операции: emptyempty — проверка очереди на наличие в ней элементов, pushpush (запись в очередь) — операция вставки нового элемента, poppop (снятие с очереди) — операция удаления нового элемента, sizesize — операция получения количества элементов в очереди. Очередь, способную вместить не более nn элементов, можно реализовать с помощью массива elements[0…n−1]elements[0…n−1]. Она будет обладать следующими полями: headhead — голова очереди, tailtail — хвост очереди. |