Система управления интерфейсом
Эффективность и гибкость информационной технологии во многом зависят от характеристик интерфейса СППР. Интерфейс определяет: язык пользователя; язык сообщений компьютера, организующий диалог на экране дисплея; знания пользователя.
Язык пользователя
Это те действия, которые пользователь производит в отношении системы путем использования возможностей клавиатуры; электронных карандашей, пишущих на экране; джойстика; "мыши"; команд, подаваемых голосом, и т.п. Наиболее простой формой языка пользователя является создание форм входных и выходных документов. Получив входную форму (документ), пользователь заполняет его необходимыми данными и вводит в компьютер. Система поддержки принятия решений производит необходимый анализ и выдает результаты в виде выходного документа установленной формы.
Значительно возросла за последнее время популярность визуального интерфейса. С помощью манипулятора "мышь" пользователь выбирает представленные ему на экране в форме картинок объекты и команды, реализуя таким образом свои действия. В частности проводятся работы по созданию графического интерфейса с вмонтированной системой понимания и естественного языка с целью предоставить пользователю возможность вводить команды и вопросы обычным языком. При этом существенно, чтобы система имела способность автоматически выбирать наиболее подходящий решатель задачи на основании параметров входного запроса и математической природы модели (например, в зависимости от того, есть ли поставленная задача оптимизационной или нет). Это означает, что пользователю нужно вводить лишь характеристики задачи или предметной области, а СУБМ автоматически и интеллектуально (то есть самая распознает задачу) проведет выбор подходящего метода или инструмента.
В некоторых приложениях механизм интерактивного взаимодействия между пользователями СУБМ рассматривается с точки зрения объединения трех факторов: языка структурирования данных, запросов моделей и процессоров запросов естественным языком, в частности с ориентацией на ключевые слова процессора запросов для СУБМ, что интегрирует некоторые характеристики этих компонентов. Примером языка запросов для структурированных моделей может быть система, в которой три операции (выполнение, оптимизация и анализ чувствительности) образовывают критерий относительной полноты. Выполнение в этом контексте напоминает процедуры выбора первой проекции в управлении реляционной базой данных, поскольку оно ограничивает отношения между определенными записями и проблемной области.
Оптимизационный запрос идентифицирует подмножество входов (пространство решений), единый выход (целевая функция оптимизационной модели), любые необходимые ограничения на входе и выходе, и указывает на максимум или минимум. Анализ чувствительности применяется для определения степени изменения выхода модели относительно определенного входа.
Система на основе меню или структурированного процедурного языка является оптимальным вариантом в области интерфейсов с естественным языком (с учетом технологических ограничений относительно естественных языков в контексте компьютерной обработки информации). В варианте обработки структурированным естественным языком запрос вводится в произвольной форме, после чего он фильтруется с целью получения наборов ключевых слов. Система имеет определенные правила, в соответствии с которыми проводится описание пользователем, если полученная последовательность ключевых слов не совпадает с записанным в памяти образцом. Как и в любой другой системе, в границах естественного языка трудность при создании такого интерфейса состоит в том, чтобы бы обеспечить способность системы правильно обнаружить намерения пользователя и соответствующим образом на них среагировать.
Управление компьютером при помощи человеческого голоса - самая простая и поэтому самая желанная форма языка пользователя. Она еще недостаточно разработана и поэтому малопопулярна. Существующие разработки требуют от пользователя серьезных ограничений: определенного набора слов и выражений; специальной надстройки, учитывающей особенности голоса пользователя; управления в виде дискретных команд, а не в виде обычной гладкой речи. Технология этого подхода интенсивно совершенствуется, и в ближайшем будущем можно ожидать появления систем поддержки принятия решений, использующих речевой ввод информации.
Язык сообщений - это то, что пользователь видит на экране дисплея (символы, графика, цвет), данные, полученные на принтере, звуковые выходные сигналы и т.п. Важным измерителем эффективности используемого интерфейса является выбранная форма диалога между пользователем и системой. В настоящее время наиболее распространены следующие формы диалога: запросно-ответный режим, командный режим, режим меню, режим заполнения пропусков в выражениях, предлагаемых компьютером.
Каждая форма в зависимости от типа задачи, особенностей пользователя и принимаемого решения может иметь свои достоинства и недостатки.
Долгое время единственной реализацией языка сообщений был отпечатанный или выведенный на экран дисплея отчет или сообщение. Теперь появилась новая возможность представления выходных данных - машинная графика. Она дает возможность создавать на экране и бумаге цветные графические изображения в трехмерном виде. Использование машинной графики, значительно повышающее наглядность и интерпретируемость выходных данных, становится все более популярным в информационной технологии поддержки принятия решений.
За последние несколько лет наметилось новое направление, развивающее машинную графику, -мультипликация. Мультипликация оказывается особенно эффективной для интерпретации выходных данных систем поддержки принятия решений, связанных с моделированием физических систем и объектов.
Пример.
Система поддержки принятия решений, предназначенная для обслуживания клиентов в банке, с помощью мультипликационных моделей может реально просмотреть различные варианты организации обслуживания в зависимости от потока посетителей, допустимой длины очереди, количества пунктов обслуживания и т.п.
В ближайшие годы следует ожидать использования в качестве языка сообщений человеческого голоса. Сейчас эта форма применяется в системе поддержки принятия решений сферы финансов, где в процессе генерации чрезвычайных отчетов голосом поясняются причины исключительности той или иной позиции.
Знания пользователя -это то, что пользователь должен знать, работая с системой. К ним относятся не только план действий, находящийся в голове у пользователя, но и учебники, инструкции, справочные данные, выдаваемые компьютером.
Совершенствование интерфейса СППР определяется успехами в развитии каждого из трех указанных компонентов. Интерфейс должен обладать следующими возможностями.
Возможности интерфейса
Манипулировать различными формами диалога, изменяя их в процессе принятия решения по выбору пользователя;
Передавать данные системе различными способами;
Получать данные от различных устройств системы в различном формате;
Гибко поддерживать (оказывать помощь по запросу, подсказывать) знания пользователя.
|
Управление сообщениями. Электронная почта.
Электронная почта
Традиционно специалисты считали почтовую систему, даже электронную почту, дополнительной функцией СППР. То есть разработчики систем поддержки принятия решений понимали, что лицо, которое принимает решения, вероятно имеет системы доставки электронной почты, но такие системы игнорируются при проектировании и разработке СППР. Поэтому при использовании электронной почты пользователь сначала должен был бы прекратить работу с СППР. Даже когда появилась технология «работы с окнами» прикладных программ, разрешающей пользователю легко перемещаться в прикладную программу электронной почты, СППР и электронная почта существовали как все еще независимые программы. Пользователь не мог легко пересылать документы, графику или текст прямо из СППР или получать их, для применения внутри СППР.
В сегодняшней электронной среде имеется интеграция СППР с системой электронной почт и все большее количество менеджеров считают электронную почту продуктивно расширяющим инструментом. Интерфейс с системой электронной почты разрешает ОПР больший доступ к группам обсуждения, базам данных Интернет, другим электронным данным и инструментальным средствам для принятия решений. Эти ресурсы могут расширять диапазон доступной информации и могут, в некоторых случаях, обеспечить доступ к более новым данным. Использования электронной почты, может помогать пользователю связываться с коллегами, чтобы обсудить информацию и проведенные исследование, а также установить приемлемую перспективу решений. Это может, в свою очередь, улучшить связь менеджеров с подчиненными и сформировать поддержку выбора, который есть важными шагами в процессе принятия решений.
Общения среди ОПР обычно более сложное чем простые вопросы и ответы, которые могут быть реализованы на простом шаблоне почты. Часто, они должны формировать документы и исследование на основе анализа или связанных записей. Если электронная почта интегрирована в СППР, пользователи могут легко включать документы, электронные таблицы, и даже графики, обогащающие связь.
Дискуссионные группы
Использования электронной почты для ежедневной связи, которая традиционно проводится в форме встреч, телефонных звонков или почтового обслуживания, создает у людей привычку использовать это средство коммуникаций. По причине, которые не очевидные, большинство людей имеют тенденцию отвечать на электронную почту более легко и быстро, чем использовать какие-то другие типы связи. Так же, люди с удовлетворением используют электронную почту для передачи сообщений, которые иначе не могут быть переданы, в особенности вышестоящими лицам или лицам высшего ранга. Электронная почта обеспечивает связь между лицами, которые обычно не взаимодействуют между собой. Кроме этого, многие люди предоставляют своим сообщениям электронной почты более персональный характер чем записям. Кроме прямого использования электронной почты пользователи СППР могут использовать электронные дискуссионные группы чтобы получить информацию или понимание из расширенной группы коллег. Открытые дискуссионные группы доступные в Интернет почти на любую тему, которую только можно вообразить
Эти дискуссионные группы, большей частью, открытые для кого-нибудь, кто заинтересован темой. Пользователи преимущественно присылают свои вопросы через электронную почту. Вопрос, в свою очередь, рассылается всем абонентам дискуссионной группы. Когда абоненты знают ответ, ссылка ли, они могут ответить в дискуссионную группу или абоненту, который сделал запрос. Пользователи, конечно, зависят от других пользователей, чтобы проверять их электронную почту регулярно и быть способными ответить на вопрос. Много дискуссионных групп работают очень хорошо и люди находят много полезной информации. Лишь экспериментирования с системами может обеспечить точную информацию относительно того, какие дискуссионные группы будут разве что будут полезными.
Пользователи могут также инициировать дискуссионные группы, составленные из служащих их предприятия, отделов или проектных групп, или коллег с подобными интересами и обязанностями из других организаций. Так же дискуссионные группы могли бы использоваться для обсуждения процедурных или стратегических изменений и (или) для идентификации проблемы важности определенных клиентов или подчиненных. Пользователи в этих закрытых дискуссионных группах могут быть более приближены к информации и получать поддержку, так как они именно те, кто будет читать сообщение; они также не должны волноваться относительно открытия частной информации или стратегических планов корпорации. Кроме того, закрытые дискуссионные группы имеют общую цель и ответы на вопрос, могут помочь приблизиться к этой общей цели.
Еще один способ использования электронной почты осуществляется путем просмотра определенной среды, чтобы идентифицировать проблемы и возможности. Например, дискуссионные группы или группы новостей могут помочь аналитику обнаружить новые идеи. Например, вопрос, поставленные другими пользователями относительно новых методов или процедур, могут дойти к вниманию аналитиков, которые могут рассмотреть их как стратегические возможности ли использовать идеи для решения существующих проблем. Так же аналитики из межнациональных корпораций, или те, кто принимают участие в многонациональных переговорах, могут контролировать текущие события в специфических странах, искать изменения, которые могут требовать изменений в политике или планах. Точно так же и внутренние дискуссионные группы могли использоваться для индикации проблем или идей.
Дискуссионные группы не единый путь, которым аналитики могут использовать электронные коммуникации. Существует ряд информационных служб, на которые можно подписаться в Интернет, что обеспечивают, например, своевременные промышленные новости и технологически связаны. Из них аналитики могут получить ряд новостей, которые связанные с рассматриваемым выбором.
Чтобы быть полезной в среде СППР, система электронной почты требует дополнительных возможностей, которые облегчают или хотя бы не препятствуют использовать системы электронной почты для поддержки решений. Одна из таких возможностей — автоматическое сообщение системы пользователю о доступности электронной почты, независимо от того, выполняется ли какое-либо другое прибавление. Если автоматическое сообщение не обеспечивается, то пользователь вынужден остановить то, что он делает для того, чтобы проверить электронную почту. При этих условиях аналитики, вероятно не будут использовать электронную почту, или, по крайней мере, не будут использовать ее эффективно. Конечно, аналитики должны быть способные отключить функцию автоматического сообщения, когда они не хотят отрываться от текущих задач.
С этой возможностью связанная необходимость обеспечить систему фильтрации сообщений, поскольку автоматическое сообщение без механизма фильтрации может сделать систему электронной почты больше раздражающей, чем полезной. Ясно, что быстрое сообщение о несрочной информации не лучше, чем вообще не иметь сообщения.
Тем не менее, если система электронной почты сообщает пользователя только, тогда, когда сообщение получено от отдельных лиц или дискуссионных групп, это может быть полезной информацией. Так же, если фильтрующая система может читать тему сообщения и перерывать лишь если прибывшая электронная почта относительно определенной темы или перечня тем, то это будет полезно для аналитика.
Если система электронной почты способная определить источник сообщения электронной почты, сравнив его с определенным пользователем перечнем источников, и (или) определить тему сообщения и сравнить с определенным пользователем набором тем, то она будет «знать», какие сообщения важные для аналитика, и соответственно этому перерывать его работу. например, можно было бы разрешить фильтрацию таким образом:
разрешить прерывание для сообщений, в которых встречается любой из указанных критериев.
для любых сообщений от моего супервизора.
для любого ответа на мой запрос относительно желательного размещения предприятия.
для любого нового сообщения от супервизора предприятия.
регистрировать любые другие сообщения, но не присылать автоматическое прерывание на них.
|
Data Warehouse – хранилище данных - ХД - систем обработки данных
Автоматизация или компьютеризация предприятий, как правило, происходит исторически и «снизу вверх» (исключая случаи полной реорганизации). Определенные подразделения, которые заняты массовыми операциями по обработке данных (выписка счетов, учет производства, складской учет, работа с поставщиками и пр.), подвергаются процессу целевой автоматизации. Это означает, что массовые задачи будут производиться с помощью компьютеров, которые заменят работу с бумажными носителями информации (документы, бланки) на режим, в котором действия отражаются в БД, или (что чаще всего и происходит) информация будет дублироваться как на бумажных носителях, так и в БД.
В силу того, что компьютеризации (или отражению в БД) подвергается каждый раз небольшой фрагмент процессов предприятия, и это происходит не всегда согласованно, большинство БД плохо согласованы друг с другом, т.е. в различных БД одинаковые объекты реального мира могут быть отражены по–разному (например, Иванов И. И. при начислении заработной платы и Иванов Иван Иванович при получении материальных ценностей в подотчет). Эта проблема может решаться введением централизованных справочников и словарей уровня предприятия, что само по себе является нетривиальным техническим процессом.
Хранилище Данных
(Data Warehouse , DW , ХД, информационное хранилище, склад данных):
это централизованный фонд структурированного хранения и быстрого поиска информации при Off-Line анализе информации
это предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию и неизменяемый набор данных, предназначенный для поддержки принятия решений, и его пользователи — это высший и средний менеджмент, аналитики, представители подразделений бизнес-анализа и маркетинга
это среда, состоящая из одной или более БД, спроектированная для доставки соответствующего и согласованного бизнес-анализа (Business Intelligence, BI) во все бизнес-подразделения организации
это инструмент управления, благодаря которому руководство получает доступ к информации, необходимой для принятия обоснованных решений
это средство, которое помогает руководству принимать стратегические решения, производить анализ огромных объемов данных, открывать скрытые возможности и улучшать конкурентоспособность своего предприятия.
ХД собирает информацию из различных источников и рисует исчерпывающую картину бизнес деятельности организации. Такая система преобразуют данные в согласованный, легко доступный формат и распределяет их среди тех, кому они необходимы.
|
Причины возникновения, цели и задачи
Необходимость создания ХД на крупных предприятиях чаще всего определяется несовершенством существующих систем обработки транзакций.
Основные причины
Цели и задачи
|
Основные причины возникновения ХД
Крупной компании ХД может понадобиться для...
Назначение ХД
выполнения серверных/дисковых задач,
связанных с созданием запросов и отчетов на серверах/дисках, не используемых в системах обработки транзакций OLTP. Большинство фирм стремятся настроить системы обработки транзакций так, чтобы все операции выполнялись за приемлемое время. В связи с этим рекомендуется реализовывать архитектуру ХД, использующую отдельные серверы/диски для создания запросов/отчетов, что позволит добиться приемлемого времени обработки транзакций и будет разумно и с финансовой и с организационной точки зрения.
использования моделей данных и/или серверных технологий,
ускоряющих создание запросов и отчетов, но не предназначенных для обработки транзакций.
создания комфортной среды,
в которой написание и поддержка запросов и отчетов не требует больших знаний в области технологий БД. А также для обеспечения средств, позволяющих техническим специалистам ускорить процесс написания и поддержки запросов и отчетов, что сокращает количество бюрократических процедур.
создания репозитория "очищенных" данных системы обработки транзакций и последующего получения отчетов из этих данных без изменения самой OLTP-cистемы. ХД дает возможность очистки данных без изменения систем обра ботки транзакций.
упрощения формирования запросов и отчетов по данным из нескольких систем обработки транзакций, а также из внешних источников данных и/или по данным, которые хранятся только для отчетности. Долгое время для составления отчетов по данным из нескольких систем организации были вынуждены писать специальные процедуры извлечения данных и выполнять операции сортировки и объединения, а затем уже составлять отчеты по отсортированным (и/или объединенным) выборкам данных
создания репозитория данных для OLTP-системы,
содержащего долговременную информацию, хранение которой в системе обработки транзакций не эффективно. Чтобы не замедлять выполнение операций, старые данные часто удаляются из систем обработки транзакций. Однако для отчетности и составления запросов есть смысл держать эту информацию в ХД, где время отклика не так критично.
ограничения доступа к БД системы и программной логике ее управления лицам, использующим данные OLTP-систем исключительно для составления отчетов и запросов. В этом случае основная цель - защита информации.
развития систем управления взаимоотношениями с клиентами (CRM). Процесс выстраивания взаимоотношений с клиентами нацелен на сохранение старых и привлечение новых клиентов, что трудно осуществить без автоматизации продаж, маркетинга и совершенствования обслуживания
ликвидации разрозненности данных . Несмотря на то, что предприятия склонны к централизации всех систем автоматизации в рамках КИС, достичь этого удается далеко не всегда, поскольку неизбежно присутствуют разнородные источники информации.
|
Цели и задачи хранилищ данных
Кроме определенной выше глобальной цели – создание единой модели данных, можно выделить т.н. «краткосрочные цели», которые дают немедленный выигрыш пользователям на каждом этапе реализации ХД. Вот несколько примеров краткосрочных целей.
Краткосрочные цели
Улучшение качества данных
Поскольку обычным недостатком СППР являются "грязные данные", пользователь должен уделять внимание качеству своих данных на каждом этапе реализации ХД. Очистка данных представляет собой проблему в организации Хранилищ: с одной стороны, предполагается, что ХД обеспечит чистые, интегрированные, соответствующие и согласованные данные, извлеченные из множества источников; с другой стороны, есть расписание разработки, составленное в расчете на 6-12 месяцев. Практически невозможно достичь обеих целей одновременно, не идя на какие-либо компромиссы. Трудность в том, чтобы определиться с существом этих компромиссов.
Подготовка данных для СППР
Создание ХД позволяет произвести следующий этап автоматизации деятельности предприятия — подготовить данные для систем поддержки принятия решений. Основным отличием деятельности по принятию решений от исполнительской деятельности, с точки зрения используемых данных, является потребность во всестороннем видении процессов во всем многообразии параметров, от которых они зависят, за различные временные промежутки. Для создания систем поддержки принятия решений необходима полная, непротиворечивая, информация за различные временные промежутки, которая может быть как обобщена (просуммирована или агрегирована другим способом), так и детализирована.
Минимизация количества несовместимых отчетов
Другой распространенной проблемой сегодняшних сред СППР является несовместимость отчетов. Несовместимые отчеты в основном происходят от неправильного использования данных, и первопричиной этого является разногласия или непонимание значения или содержимого данных.
Захват и доступ к метаданным
Метаданные необходимы для совместного доступа к данным и навигации по ним. Сегодня к большинству данных нет совместного доступа по многим причинам, одной из которых является непонимание данных, а другой - недоверие к содержимому данных. Как только исходные данные очищены, преобразованы, агрегированы, просуммированы и рассечены несколькими различными способами, пользователи никогда снова не найдут их в ХД без помощи метаданных. Захват метаданных (то есть, определений данных, доменов, алгоритмов преобразования исходных данных, столбцы и таблицы, в которых находятся результирующие данные, и все другие технические компоненты) представляет собой возможное решение
Обеспечение возможности совместного доступа к данным
Если совместный доступ к данным является одной из задач ХД, то необходимо включить туда некоторую очистку данных, урегулирование разногласий по данным и компоненты средств доступа, основанные на метаданных в качестве инструментов достижения этой цели. Эти компоненты представляют собой предварительные условия совместного доступа к данным. Двумя другими существенными компонентами являются проектирование БД и организация доступа к ней.
Проектирование БД - Базы Данных
После того, как проанализированы требования, необходимые данные логически смоделированы и относящиеся к ним метаданные захвачены в репозиторий, следующим шагом является проект БД. Проектирование самостоятельной БД для одного бизнес-подразделения отличается от проектирования БД совместного доступа для множества бизнес-подразделений.
Интеграция данных из множества источников
Это существенная задача для всех ХД, поскольку это первостепенная проблема в различных СППР. Самостоятельные системы, имеющие одни и те же данные, идентифицируемые различными ключами, представляют собой одну из причин того, почему в большинстве компаний отсутствует интеграция данных. Некоторые другие причины заключаются в том, что содержимое данных в одном файле находится на отличном от другого файла уровне детализации или в том, что одни и те же данные модернизируются с разной периодичностью в различных файлах.
Соединение исторических данных с текущими данными
Типичной задачей ХД является сохранение истории. Эта задача сопровождается своими проблемами. Исторические данные редко хранятся в операционных системах, и даже если они там хранятся, трудно найти трехлетнюю или пятилетнюю историю в рамках одного файла
|
Концепция ХД - хранилища данных
Концепция определяет процесс сбора, отсеивания, предварительной обработки и накопления данных с целью долговременного хранения данных и предоставления результирующей информации пользователям в удобной форме для статистического анализа и создания аналитических отчетов. В основе концепции ХД для интеграции неоднородных источников данных принципиально отличается от подхода динамической интеграции разнородных БД, лежат две основополагающие идеи:
Интеграция
ранее разъединенных детализированных (описывающих некоторые конкретные факты, свойства, события и т.д.) данных в едином ХД : исторические архивы, данные из традиционных СОД, данные из внешних источников в едином ХД, их согласование и возможно агрегация. Интегрированность означает, что, например, данные, полученные из различных источников, хранятся согласованно и централизованно.
Разделение
наборов данных используемых для операционной обработки и наборов данных используемых для решения задач анализа, применяемых в системах поддержки принятия решений. Такое разделение возможно путем интеграции источников ранее разъединенных детализированных данных в едином ХД, их согласования и, возможно, агрегации. Организация информационного процесса при построении ХД представлена на рисунке.
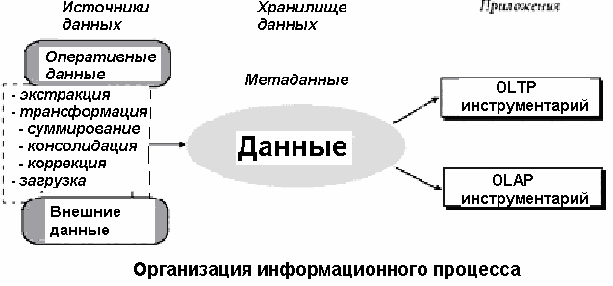
Цель концепции ХД
Цель концепции ХД - прояснить отличия в характеристиках данных в операционных и аналитических системах, определить требования к данным помещаемым в целевую БД ХД, определить общие принципы и этапы её построения, основные источники данных, дать рекомендации по решению потенциальных проблем возникающих при их выгрузке, очистке, согласовании, транспортировке и загрузке в целевую БД.
Для правильного понимания данной концепции необходимо понимание следующих принципиальных моментов, заключающихся в том, что концепция ХД:
это не концепция анализа данных, скорее это концепция подготовки данных для анализа.
не предопределяет архитектуру целевой аналитической системы. Она говорит о том, какие процессы должны выполняться в системе, но не о том, где конкретно и как эти процессы должны выполняться.
предполагает не просто единый логический взгляд на данные организации (как иногда это трактуется). Она предполагает реализацию единого интегрированного источника данных.
|
Единый источник даннх
СОД - системы обработки данных
Вопрос реализации единого интегрированного источника данных достаточно принципиален. Концепция ХД предполагает не просто единый логический взгляд на данные организации, а действительную реализацию единого интегрированного источника данных для систем обработки данных (СОД).
Сегодня, достаточно популярны решения, предполагающие интеграцию различных СОД на основе единого справочника метаданных ( поддерживающего единый логический взгляд данные организации ), но не единого интегрированного источника данных. При этом предполагается динамическая выгрузка, по каждому новому запросу, данных из различных операционных источников (СОД) их динамическое согласование, агрегация и транспортировка к пользователю. Очевидно, что для определённых классов приложений, это решение вполне корректно. Но следует заранее понимать все ограничения им накладываемые.
Кроме единого справочника метаданных, средств выгрузки, агрегации и согласования данных, концепция ХД, как отмечалось ранее, подразумевает: интегрированность, не изменчивость, поддержку хронологии и согласованность данных . И если, два первых свойства ( интегрированность и не изменчивость ) влияют на режимы анализа данных (как будет показано ниже, без интегрированной БД, в которой используются специализированные методы хранения и доступа, по крайней мере, сегодня, трудно говорить о реализации интерактивного динамического анализа), то последние два ( поддержка хронологии и согласованность ), существенно сужают список решаемых аналитических задач.
Структура хранилища данных
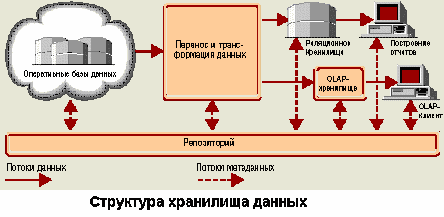
Компоненты типичного ХД
Компоненты, входящие в типичное ХД, представлены на рисунке. Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное ХД. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном ХД. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Без поддержки хронологии (наличия исторических данных) нельзя говорить о решении задач прогнозирования и анализа тенденций. Но наиболее критичными и болезненными, оказываются вопросы, связанные с согласованием данных.
Основным требованием аналитика, является даже не столько оперативность, сколько достоверность ответа. Но достоверность, в конечном счете, и определяется согласованностью. Пока не проведена работа по взаимному согласованию значений данных из различных источников, сложно говорить об их достоверности.
Практически в любой организации, вопрос о согласованности данных в различных информационных системах стоит чрезвычайно остро. И, нередко, менеджер сталкивается с ситуацией, когда на один и тот же вопрос, различные системы могут дать и обычно дают различный ответ. Это может быть связано как с не синхронностью моментов модификации данных, отличиями в трактовке одних и тех же событий, понятий и данных, изменением семантики данных в процессе развития предметной области, элементарными ошибками при вводе и обработке, частичной утратой отдельных фрагментов архивов и т.д. Очевидно, что учесть и заранее определить алгоритмы разрешения всех возможных коллизий мало реально. Тем более, это нереально сделать в оперативном режиме, динамически, непосредственно в процессе формирования ответа на запрос.
|
Свойства данных
Билла Инмона (W. Inmon ), считающийся основателем нового направления развития технологии БД, дал классическое определение информационного хранилища в 1990 г . Он охарактеризовал его как специальным образом администрируемую БД, в которой содержатся данные, обладающие описанными ниже свойствами:
Данные предметно-ориентированны
ХД должно разрабатываться с учетом специфики предметной области (клиенты, товары, продажи), а не прикладных областей деятельности (выписка счетов, контроль запасов, продажа товаров). В отличие от БД в традиционных OLTP-системах, где данные подобраны в соответствии с конкретными приложениями, информация в ХД предназначена для решения задачи поддержки принятия решений. Для СППР требуются "исторические" данные - факты за определенные интервалы времени. Хорошо спроектированные структуры данных ХД отражают развитие всех направлений бизнес-процесса компании во времени.
Интегрированы и внутренне непротиворечивы
Поскольку данные в ХД поступают из разных источников (OLTP-системы, архивы и пр.), где они могут иметь разные имена, атрибуты, единицы измерения и способы кодировки, необходимо привести их к единому формату (для даты: 5 января, 5.01). С этого момента они представляются пользователю в виде единого информационного пространства. В процессе загрузки хранилища должна быть обеспечена, очистка и согласованность данных - если в четырех разных приложениях пол клиента кодировался четырьмя различными способами, то в информационном ХД будет использована единая для всех данных схема кодировки.
Данные инвариантны во времени (неизменчивы)
В OLTP-системах истинность данных гарантирована только в момент чтения, поскольку уже в следующее мгновение они могут измениться в результате очередной транзакции. Важным отличием ХД от OLTP-систем является то, что данные в них сохраняют свою истинность в любой момент процесса чтения, в оперативном режиме они не обновляются (при загрузке проводится их очистка от избыточности), а лишь регулярно пополняются из систем оперативной обработки по заданной дисциплине.
Поддерживающие хронологию (стабильность информации)
В OLTP-системах записи могут регулярно добавляться, удаляться и редактироваться. В ХД-системах, как следует из требования временной инвариантности, однажды загруженные данные теоретически никогда не меняются. По отношению к ним возможны только две операции: начальная загрузка и чтение (доступ). Это и определяет специфику проектирования структуры БД для ХД.
Полнота и достоверность хранимых данных
( минимизация избыточности информации) - наборы данных, организованные с целью поддержки управления», призванные выступать в роли «единого и единственного источника истины», обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и поддержки принятия решений.
|
Структура ИС на основе ХД
Примерная структура ИАС
Примерная структура ИАС, построенной на основе ХД, показана на рисунке.
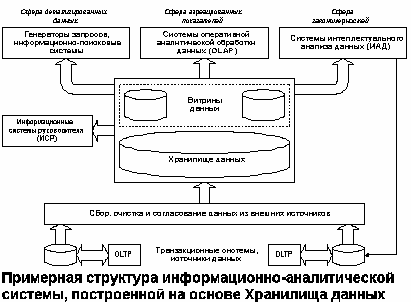
В конкретных реализациях отдельные компоненты этой схемы могут отсутствовать. При такой организации ИАС ХД функционирует по следующему сценарию: по заданному регламенту в него собираются данные из различных источников – БД систем оперативной обработки. В ХД поддерживается хронология: наравне с текущими хранятся исторические данные с указанием времени, к которому они относятся. В результате необходимые доступные данные об объекте управления собираются в одном месте, приводятся к единому формату, согласовываются и, в ряде случаев, агрегируются до минимально требуемого уровня обобщения.
Несмотря на то, что ХД содержат заведомо избыточную информацию, которая и так имеется в базах или файлах оперативных систем, появление концепции ХД вызвано тем, анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется:
разрозненностью данных (OLTP-системы, текстовые отчеты, xls-файлы);
хранением их в форматах различных СУБД и в разных узлах корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах
сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Можно констатировать, что практически в любой организации сложилась парадоксальная ситуация: - информация вроде бы, где-то и есть, её даже слишком много, но она неструктурированна, несогласованна, разрознена, не всегда достоверна, её практически невозможно найти и получить. В результате можно говорить об отсутствие информации при ее наличии и даже избыточности..
Для того, чтобы извлекать полезную информацию из данных, они должны быть организованы способом, отличным от принятого в OLTP-системах потому что:
в OLTP-системах используются нормализованные таблицы БД. Нормализация эффективна, если отношения часто перестраиваются (вставка), но дает отрицательный эффект в случае операции выборки (особенно в случае сложных запросов). А в DSS-системах только операции выборки, и данные редко меняются, поэтому данные целесообразно хранить в виде слабо нормализованных отношений, содержащих заранее вычисленные основные итоговые данные. Большая избыточность и связанные с ней проблемы тут не страшны, т.к. обновление происходит только в момент загрузки новой порции данных. При этом происходит как добавление новых данных, так и пересчет итогов.
выполнение некоторых аналитических запросов требует хронологической упорядоченности данных. Реляционная модель не предполагает существования порядка записей в таблицах.
в случае аналитических запросов чаще используются не детальные, а обобщенные (агрегированные данные).
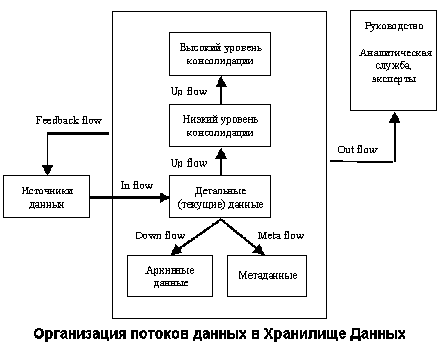
Организация потоков данных
Организация потоков данных в ХД показана на рисунке
|
Методы организации ХД
Так как ХД носит предметно-ориентированный характер, его организация нацелена на содержательный анализ информации, а не на автоматизацию бизнес-процессов. Это свойство определяет архитектуру построения хранилища и принципы проектирования модели данных, отличные от тех, что применяются в оперативных системах. Методика построения ХД из простой теоретической дисциплины превратилась в сложную науку, полную вариаций и направлений.
На сегодняшний день существует следующие подходы к архитектуре ХД.
Подходы к архитектуре хранилищ данных - ХД
корпоративная информационная фабрика ( CIF , Corporate Information Factory ) Билла Инмона,
ХД с архитектурой шины ( Data Warehouse Bus , BUS) Ральфа Кимболла (Ralph Kimball)
распределенное ХД (Distributed Data Warehouse/Distributed Data Mart, DDW/DDM),
объединенное ХД (Federated Data Warehouse/Federated Data Mart, FDW\FDM).
Выбрать оптимальную систему из этого набора архитектурных решений не такая простая задача.
|
Data Mart - Витрины данных
Киоск, секция, лавка, рынок, ВД
Облегченным вариантом корпоративного ХД является Витрина Данных (киоск, секция, лавка, рынок, ВД) - это набор тематически связанных БД, содержащие информацию, относящуюся к отдельным аспектам деятельности организации. По сути дела, ВД - это облегченный вариант ХД, существенно меньше по объему, чем корпоративный ХД, и для его реализации не требуется особо мощная вычислительная техника.
Концепция ВД была предложена Forrester Research в 1991 году. При этом главная идея заключалась в том, что ВД максимально приближены к конечному пользователю и содержат только тематические подмножества заранее агрегированных данных, по размерам гораздо меньшие, чем общекорпоративное ХД, и, следовательно, требующие менее производительной техники для поддержания. Концепция ВД ориентирована исключительно на хранение, а не на обработку корпоративных данных. Она не предопределяет архитектуру целевых аналитических систем, а только создает поле деятельности для их функционирования, концентрируясь на требованиях к данным. Таким образом, она оставляет свободу выбора во всем, что касается способов представления данных в целевом ХД (реляционный, многомерный) и режимов анализа данных хранилища.
В большинстве случае ВД (витрина данных) - это аналитическая структура, которая обычно поддерживает область работы одного приложения, бизнес-процесса или отдела. Сотрудники отдела обобщают требования к информации и приспосабливают каждую витрину к своим нуждам. Затем они обеспечивают персонал, работающий с информацией, средствами интерактивной отчетности (например, инструментами OLAP, средствами формирования незапланированных запросов или параметризованных отчетов). Эти средства позволяют сотрудникам углубляться в данные и исследовать их пространственную структуру "вдоль и поперек", чтобы выявить тренды и получить более детальную картину событий, являющихся движущими силами тех процессов или задач, которыми эти сотрудники управляют.
| |
 Скачать 2.04 Mb.
Скачать 2.04 Mb.