Обработка информации. Интеллектуальная обработка информации. Искусственный интеллект. Основные вехи развития ии. Примеры практических задач
 Скачать 0.95 Mb. Скачать 0.95 Mb.
|

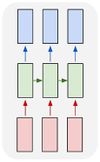
Интеллектуальная обработка информации. Искусственный интеллект. Основные вехи развития ИИ. Примеры практических задач.Интеллектуальная обработка информации — это автоматизированное решение (слабо)формализованных задач. Но автоматизированное не равно автоматическое! Искусственный интеллект – комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая самообучение и поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые как минимум с результатами интеллектуальной деятельности человека. Основные вехи развития искусственного интеллекта: 1943-1949 – Формализованное понятие ИИ/ИНС, первые аппаратные реализации 1958 – решение задач классификация с помощью однослойного перцептрона 1960 – реализация задач предсказания и адаптивного управления на термисторах 1969 – обнаружение ограниченности перцептрона, спад интереса к ИНС 1976-1982 – «период забвения», Al Winter 1982 – обучение без учителя (нейронная сеть Кохонена), развитие метода обратного распространения ошибки, взрывной рост интереса к ИНС 2007 – проявление методов глубокого обучение 2010 – первый opensource framework (torch) Примеры практических задач ТИОИ: Анализ мультимедиа-контента, оценка психофизического состояния человека (распознавание речи и тональности, определение дикторов, выявление признаков сгенерированного контента и пр.) Генерация мультимедиаконтента (замена диктора, генерация/модификация видеоряда и пр.) Семантический анализ текстов на естественном языке Прогнозирование распространения информации в СМИ и социально-ориентированных ресурсах сети Интернет, анализ и прогнозирование поведенческих данных людей, обнаружение аномалий Тест Тьюринга. Сильный и слабый ИИ: «китайская комната». Этическая проблема ИИ.Тест Тьюринга: Пусть А - компьютер. В - человек, С - тоже человек, который общается с А и В посредством только письменных сообщений. С знает, что один из них компьютер, а второй человек, но не знает, кто есть кто. Задача обоих (А и В) - убедить С, что всё наоборот, при этом А и В друг с другом не взаимодействуют. Тест Тьюринга считался пройденным, если компьютеру (А) удалось бы вводить собеседника (человека) С в заблуждение на протяжении хотя бы 30% суммарного времени. Тест Тьюринга был пройден «Женей Густманом» с результатом 33%. Сильный ИИ – теория, утверждающая возможность существования ИИ, обладающего когнитивными способностями, т.е. способного ощущать себя как личность. Слабый ИИ – теория, утверждающая отсутствие когнитивных способностей у ИИ. «Китайская комната»: человек находится в изолированной комнате и не знает ни одного китайского иероглифа. Перед ним находятся таблички с иероглифами и книга с точными и полными инструкциями по манипуляции иероглифами. Наблюдатель, знающий китайские иероглифы, передает в комнату иероглифы с вопросами и ожидает получить ответ. Человек ничего не понимает, но следует инструкциям и выдает адекватные ответы. Наблюдатель уверен, что внутри китаец. Таким образом, человек проходит тест Тьюринга, но от этого не начинает понимать китайский язык. Практическая польза ТИОИ: Построение модели без формализованного описания; Устойчивость к шумам входных данных и адаптация к изменениям – обобщения модели на несколько случаев; Быстродействие за счет возможности аппаратного ускорения – однотипные вычисления (ИНС); Забота об операторе: ручная обработка специфических материалов может привести к профессиональной деформации Этическая проблема ТИОИ – темная сторона: Дать или не дать кредит? Сколько будет стоить страховка? Продолжит ли человек работать по специальности и после учебы? Стоит ли его оставить или отчислить? Выживет ли человек после операции? Стоит ли пытаться его спасти? Станет ли подсудимый рецидивистом? Полезен ли данный человек для общества? База знаний, онтологии, примеры баз знаний. Форматы записи онтологий. Шаги по построению системы знаний.База знаний – база данных, содержащая правила вывода и информацию о человеческом опыта и знаниях в некоторой предметной области. В самообучающихся системах база знаний также содержит информацию, являющуюся результатом решения предыдущих задач. Онтология – иерархический способ представления в базе знаний набора понятий и их отношений. Таким образом, знания — это совокупность онтологий. Примеры баз знаний – симптомы, по которым ставится диагноз; параметры, по которым выдаётся кредит или нет (возраст, стаж работы, зарплата) Язык описания онтологий — формальный язык, используемый для кодирования онтологии. Существует несколько подобных языков (список неполон): OWL — Web Ontology Language, стандарт W3C, язык для семантических утверждений, разработанный как расширение RDF и RDFS; KIF (KnowledgeInterchangeFormat — формат обмена знаниями) — основанный на S-выражениях синтаксис для логики; Common Logic (CL) — преемник KIF (стандартизован — ISO/IEC 24707:2007). CycL — онтологический язык, использующийся в проекте Cyc. Основан на исчислении предикатов с некоторыми расширениями более высокого порядка. DAML OIL Agent Communications Language Шаги по построению систем знаний: Извлечений знаний Структурированное описание знаний в формализованном виде Дедупликация и снятие противоречий Хранение знаний в базе знаний Форматирование выводов Типы знаний, факты и правила. Виды знаний. Данные, модели представления знаний и инженерия знаний.Типы знаний: Факты (фактические знания) – знания типа «А эквивалентно А» Правила (знания для принятия решения) – знания типа «из А следует В» Метазнания (знания о знаниях) – знания, касающиеся способов использования знаний, и знания, касающиеся свойств знаний Виды знаний: Общедоступные знания – это факты, определения, теории, которые обычно изложены в учебниках и справочниках по данной области Эвристические знания – индивидуальные знания эксперта, которые основываются на его собственном опыте, накопленном в результате многолетней практики, и в значительной степени состоят из эмпирических правил. Эвристики не всегда в полной мере осознаются их обладателями, зато позволяют находить перспективные подходы к задачам и эффективно работать при зашумленных или неполных данных Данные – совокупность фактов и идей, представленных в формализованном виде. Модель представления знаний – задания знаний для хранения, удобного доступа и взаимодействия с ними, который подходит под задачу интеллектуальной системы. Инженерия знаний – раздел (дисциплина) инженерии, направленный на внедрение знаний в компьютерные системы для решения сложных задач, обычно требующих богатого человеческого опыта. Существуют 4 модели представления знаний: Продукционная Формально логическая Фреймовая Семантическая сеть В основе продукционной модели представления знаний находится следующая конструкция продукции (правила): IF <условие> THEN <действие>. Условия можно сочетать с помощью логических функций AND, OR. Условия и действия составленных правил формируются из атрибутов и значений. Продукционная модель представления знаний нашла широкое применение в АСУТП (автоматизированная система управления технологическом процессом). Порядок работы продукционной модели: В базе данных продукционной системы хранятся правила, истинность которых установлена заранее при решении определенной задачи Правило срабатывает, если при сопоставлении фактов, содержащихся в базе данных с условием правила, которое подвергается проверке, имеет место совпадение Результат работы правила заносится в базу данных Формально логическая модель: В основе лежит предикат первого порядка Существует конечное непустое множество объектов предметной области Р На множестве Р с помощью функций интерпретаторов установлены связи между объектами На основе этих связей строятся все закономерности и правила предметной области Если представление предметной области не правильное, то есть связи между объектами настроены не верно или не в полной мере, то правильная работоспособность системы будет под угрозой! Разница между формальной логический и продукционной моделями состоит в том, что в продукционной модели не определены никакие связи между хранимыми объектами предметной области, она оперирует условиями. Фреймовая модель: Фрейм – это образ, рамка, шаблон, которая описывает объект предметной области, с помощью слотов. Слот – это артибут объекта. Слот имеет имя, значение, тип хранимых данных, демон. Демон – процедура автоматически выполняющаяся при определенных условиях. Имя фрейма должно быть уникальным в пределах одной фреймовой модели. Имя слота должно быть уникальным в пределах одного фрейма. Слот может хранит другой фрейм, тогда фреймовая модель вырождается в сеть фреймов Пример фреймовой модели: 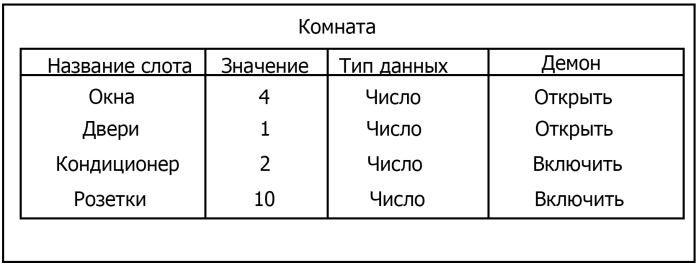 Семантическая сеть – модель представления знаний, имеет вид ориентированного графа. Вершины графа соответствуют объектам предметной области, а дуги задают отношения между ними. Объектами могут быть: понятия, события, свойства, процессы. Классификация семантических сетей: Однородные сети обладают только одним типом отношений (стрелок). В неоднородных сетях количество типов отношений больше одного. Примером таких сетей может быть семантическая сеть Википедии. Еще одна классификация семантических сетей: Сети с бинарными отношениями между понятиями – дуга связывает равно две вершины Сети с N-арными отношениями между понятиями – дуга связывает N вершин. Такая семантическая сеть описывается гиперграфом. Определение машинного обучения, признаки, модель, гипотеза. Регрессия и классификация.Пусть компьютерной программе поставлена задача обучаться: выполнять задание T (task) на примерах E (experience) с измеряемым параметром качества P (perfomance). Машинное обучение реализуется, если качество Р выполнения задания Т растет с увеличением опыта Е. Количество признаков обычно обозначают через n, а количество примеров для обучения через m. Признак — это критерий, по которому будет строиться гипотеза. Гипотеза — это прогнозируемая итоговая модель. Регрессия и классификация — это два метода, которые используются при разработке алгоритмов машинного обучения. И алгоритмы регрессионного машинного обучения, и алгоритмы классификационного машинного обучения относятся к сфере машинного обучения с учителем. Ключевое различие между классификацией и регрессией состоит в том, что классификация предсказывает дискретную метку, а регрессия предсказывает непрерывное количество или значение.  Масштабирование и обезразмеривание признаков. Понятие признаков и размерности признакового пространства.Что такое признаки (features) и для чего они нужны? Признак, он же «фича» (от англ feature) – это переменная (столбец в таблице), которая описывает отдельную характеристику объекта. Признаки являются краеугольным камнем задач машинного обучения в целом: именно на их основании мы строим предсказания в моделях. Признаки могут быть следующих видов: Бинарные, которые принимают только два значения. Например, [true, false], [0,1], [“да”, “нет”]. Категориальные (или же номинальные). Они имеют конечное количество уровней, например, признак «день недели» имеет 7 уровней: понедельник, вторник и т. д. до воскресенья. Упорядоченные. В некоторой степени похожи на категориальные признаки. Разница между ними в том, что данном случае существует четкое упорядочивание категорий. Например, «классы в школе» от 1 до 11. Сюда же можно отнести «время суток», которое имеет 24 уровня и является упорядоченным. Числовые (количественные). Это значения в диапазоне от минус бесконечности до плюс бесконечности, которые нельзя отнести к предыдущим трем типам признаков. Про масштабирование/обезразмеравание см. в следующем вопросе (выделено (одно гребаное предложение)). Линейная регрессия и многомерная линейная регрессия, матричное представление. Функция потерь для линейной регрессия.Пусть компьютерной программе поставлена задача обучаться: выполнять задание T (task) на примерах E (experience) с измеряемым параметром качества P (perfomance). Машинное обучение реализуется, если качество Р выполнения задания Т растет с увеличением опыта Е. Количество признаков обычно обозначают через n, а количество примеров для обучения через m. Признак – это критерий, по которому будет строиться гипотеза. Гипотеза – это прогнозируемая итоговая модель. Регрессия и классификация — это два метода, которые используются при разработке алгоритмов машинного обучения. И алгоритмы регрессионного машинного обучения, и алгоритмы классификационного машинного обучения относятся к сфере машинного обучения с учителем. Ключевое различие между классификацией и регрессией состоит в том, что классификация предсказывает дискретную метку, а регрессия предсказывает непрерывное количество или значение. Одномерная линейная регрессия – аппроксимация эмпирической зависимости y(x) прямой 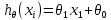 По факту это прямая y=kx+b. По факту это прямая y=kx+b. Многомерная линейная регрессия – это линейная регрессия в n-мерном пространстве (объекты и признаки являются n-мерными векторами). 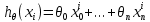 – классическое уравнение линейной регрессии в виде уравнения. – классическое уравнение линейной регрессии в виде уравнения.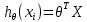 – уравнение линейной регрессии в матричном виде. – уравнение линейной регрессии в матричном виде.Размерность Х (признакового пространства) - (n+1*m). Размерность θ (пространства параметров) - (n+1*1). Так как на практике все признаки имеют различные размерности, для этого применяется масштабирование/обезразмеривание. Цель нормализации – уместить все примерно в интервале 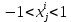 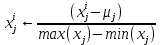 – средняя нормализация, где – средняя нормализация, где 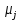 – среднее значение j-ого признака в обучающей выборке. – среднее значение j-ого признака в обучающей выборке.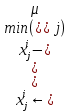 – min/max нормализация с обезразмериванием (0,1). – min/max нормализация с обезразмериванием (0,1).Для линейной регрессии функция потерь определяется следующим образом: 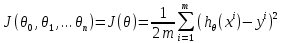 Минимизация функции потерь. Метод градиентного спуска и аналитическое решение для линейной регрессии.Метод градиентного спуска заключается в одновременном рассчете всех частных производных 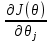 при фиксированных значениях при фиксированных значениях 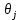 на величину на величину 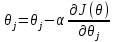 . .Аналитическое решение: по свойству минимума функции все частные производные равны нулю. Другими словами: 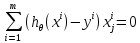 . Можно показать, что это эквивалентно: . Можно показать, что это эквивалентно: 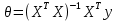 . .Регуляризация. Влияние регуляризации на процесс обучения.Если модель слишком хорошо описывает данные обучающей выборки – это тоже плохо. Так как признаки высших порядков имеют смысл возмущения, то чем выше порядок признака, тем меньше должен быть его вклад. Регуляризация – введение штрафов для высоких степеней признаков. С регуляризацией функция потерь будет записана в виде: 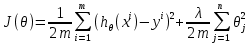
В отличие от обычной регрессии, в методе логистической регрессии не производится предсказание значения числовой переменной исходя из выборки исходных значений. Вместо этого, значением функции является вероятность того, что данное исходное значение принадлежит к определенному классу. 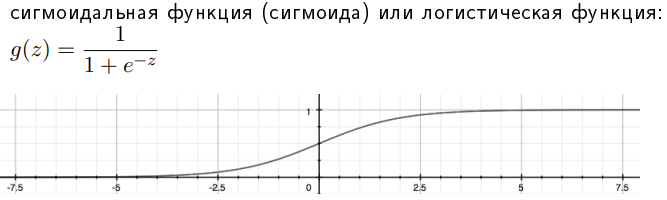    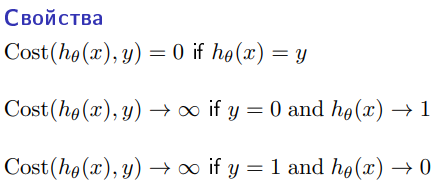   Всю имеющуюся выборку делят на: 1. Обучающую – 60-80% (минимизируется функция потерь) 2. Кросс-валидационную – 10-20% (подбираются гиперпараметры модели так, чтобы ошибка была минимальна) 3. Тестовую (контрольную) – 10-20% (оценивается ошибка для каждого набора параметров модели+гиперпатраметров) Смещение — это ошибка, возникающая в результате ошибочного предположения в алгоритме обучения. В результате большого смещения алгоритм может пропустить связь между признаками и выводом (недообучение). Дисперсия — это ошибка чувствительности к малым отклонениям в тренировочном наборе. При высокой дисперсии алгоритм может как-то трактовать случайный шум в тренировочном наборе, а не желаемый результат (переобучение).
Всю имеющуюся выборку делят на: Обучающую – 60-80% (минимизируется функция потерь) Кросс-валидационную – 10-20% (подбираются гиперпараметры модели так, чтобы ошибка была минимальна) Тестовую (контрольную) – 10-20% (оценивается ошибка для каждого набора параметров модели+гиперпатраметров) Смещение — это ошибка, возникающая в результате ошибочного предположения в алгоритме обучения. В результате большого смещения алгоритм может пропустить связь между признаками и выводом (недообучение). Дисперсия — это ошибка чувствительности к малым отклонениям в тренировочном наборе. При высокой дисперсии алгоритм может как-то трактовать случайный шум в тренировочном наборе, а не желаемый результат (переобучение). Биологический и формальный нейроны. Достоинства искусственных нейронных сетей. Входные, выходные и промежуточные нейроны. Прямое распространение в ИНС.Биологический нейрон – нервная клетка, которая обрабатывает информацию в нервных сетях. Состоит из тела, дендритов (принимают) и аксонов (передают сигнал), ядра (содержит информацию о наследственных свойствах) и плазмы. На окончаниях аксонов находятся синапсы, через которые передает электрический импульс. Сообщения передаются посредством частотно-импульсной модуляции. Искусственный нейрон – упрощенная модель биологического нейрона, представляет собой взвешенный сумматор с нелинейной функцией активацией. 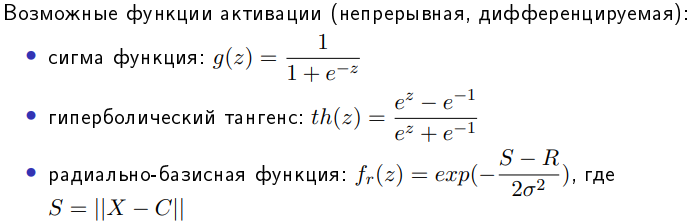 Использование нейросетей может существенно облегчить работу человека, потому что они: активно обучаются и могут находить оптимальные решения вместо человека; хорошо работают в связке «человек — нейронная сеть», увеличивают угол обзора для принятия решения и страхуют от серьёзных ошибок. Самыми распространенными применениями нейронных сетей является: Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд. Предсказание — возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке. Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое. Многослойный перцептрон — нейронная сеть, состоящая из слоев, каждый из которых состоит из элементов — нейронов (точнее их моделей). Эти элементы бывают трех типов: сенсорные (входные, S), ассоциативные (обучаемые «скрытые» слои, A) и реагирующие (выходные, R). Многослойным этот тип перцептронов называется не потому, что состоит из нескольких слоев, ведь входной и выходной слои можно вообще не оформлять в коде, а потому, что содержит несколько (обычно, не более двух — трех) обучаемых (A) слоев. Модель нейрона (будем называть его просто нейрон) — это элемент сети, который имеет несколько входов, каждый из которых имеет вес. Нейрон, получая сигнал, помножает сигналы на веса и суммирует получившиеся величины, после чего передает результат к другому нейрону или на выход сети. Здесь тоже многослойный перцептрон имеет отличия. Его функция — сигмоид, она выдает значения на промежутке от 0 до 1. К сигмоидам относится несколько функций, мы будем иметь ввиду логистическую функцию. Несколько слоев, которые могут обучаться (точнее, подстраиваться) позволяют аппроксимировать очень сложные нелинейные функции, то есть их область применения шире, нежели однослойных. Сети прямого распространения — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется. Функция активации используется для имитации работы биологического нейроона. Она применяется ко всем отдельным нейронам и на выходе получают выходное значение всего нейрона. После чего это значение сравнивается с пороговым значением и если значение функции превышает его, то это значение проходит дальше в следующие слои, иначе это воспринимается как шум (хотя в ИНС вроде как все значения проходят дальше в последующие слои). Обучение с подкреплением. Генеративно-состязательные нейронные сети. Генератор и дискриминатор. Особенности обучения генеративно-состязательных сетей. Примеры генеративно-состязательных сетей.Обучение с подкреплением (англ. reinforcement learning) — один из способов машинного обучения, в ходе которого испытуемая система (агент) обучается, взаимодействуя с некоторой средой. 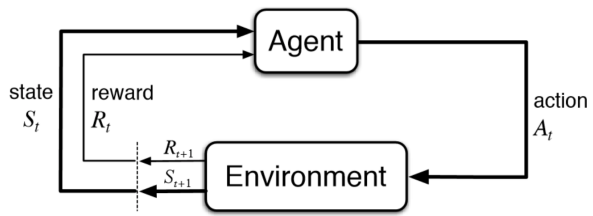 GAN – генеративно-состязательная нейросеть (Generative adversarial network, GAN) – один из алгоритмов классического машинного обучения, обучения без учителя. Суть идеи в комбинации двух нейросетей, при которой одновременно работает два алгоритма “генератор” и “дискриминатор”. Задача генератора – генерировать образы заданной категории. Задача дискриминатора – пытаться распознать созданный образ. 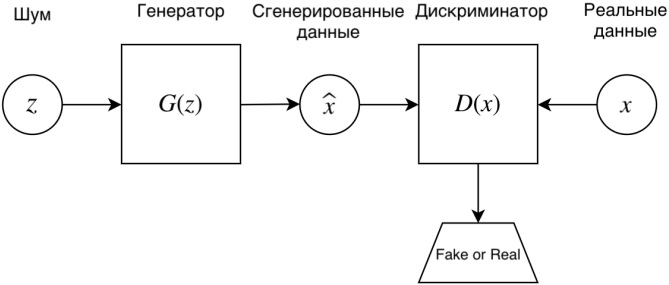 Задача GAN сгенерировать модель, обладающую максимальным правдоподобием. Алгоритм (само)обучение GAN:   Сложности при работе с GAN: Несходимость (non-convergance) Схлопывание мод распределения (mode collapse): генератор коллапсирует, т.е. выдает ограниченное количество разных образцов Исчезающий градиент (diminished gradient): дискриминатор мочит генератора Высокая чувствительность к гиперпараметрам Советы при работе с GAN: Нормализация данных [-1;1] Замена функции ошибки для G с min(log(1-D)) на max(logD) Batch normalization или layer normalization в G и D* Метки для данных, если они имеются, т.е. обучать дискриминатор еще и классифицировать образцы Примеры GAN: StackGan – порождающая состязательная сеть для генерации фотореалистичных изображений (256*256), исходя из текстового описания. LAPGAN – генеративная параметрическая модель, представленная пирамидой лапласианов с каскадом сверточных нейронных сетей внутри, которая генерирует изображения постепенно от исходного изображения с низким разрешением к изображению с высоким. PassGAN – генеративно-состязательная сеть для генерации паролей. Обучается на утекших выборках (RockYou, LinkedIn и др.)
Сonvolutional neural network (CNN, ConvNet), или Сверточная нейронная сеть — класс глубоких нейронных сетей, часто применяемый в анализе визуальных образов. Сверточные нейронные сети являются разновидностью многослойного перспептрона с использованием операций свёртки. Они нашли применение в распознавании изображений и видео, рекомендательных системах, классификации изображений, NLP (natural language processing) и анализе временных рядов. СНС состоит из разных видов слоев: сверточные (convolutional) слои, субдискретизирующие (subsampling, подвыборка) слои и слои «обычной» нейронной сети – персептрона, в соответствии с рисунком 1. 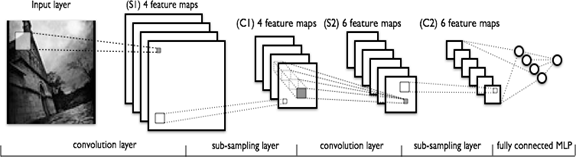 Первые два типа слоев (convolutional, subsampling), чередуясь между собой, формируют входной вектор признаков для многослойного персептрона. 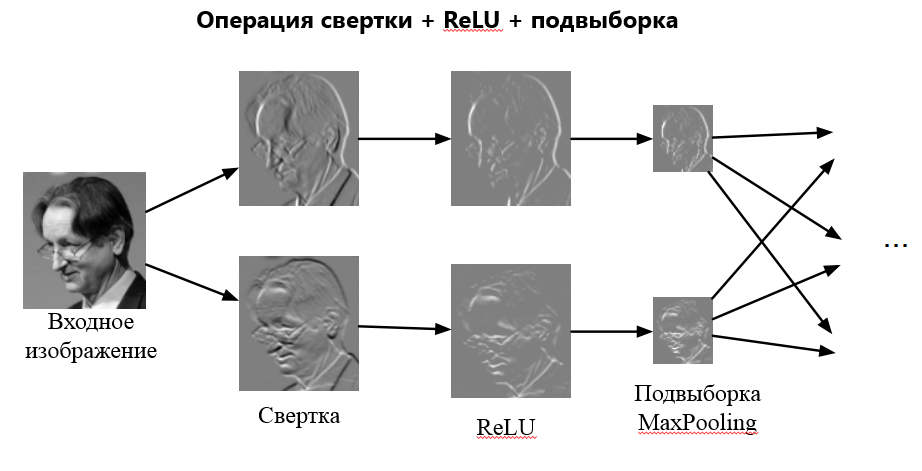 Сверточный слой представляет из себя набор карт (другое название – карты признаков, в обиходе это обычные матрицы), у каждой карты есть синаптическое ядро (в разных источниках его называют по-разному: сканирующее ядро или фильтр). Количество карт определяется требованиями к задаче, если взять большое количество карт, то повысится качество распознавания, но увеличится вычислительная сложность. Исходя из анализа научных статей, в большинстве случаев предлагается брать соотношение один к двум, то есть каждая карта предыдущего слоя (например, у первого сверточного слоя, предыдущим является входной) связана с двумя картами сверточного слоя, в соответствии с рисунком 3. Количество карт – 6. 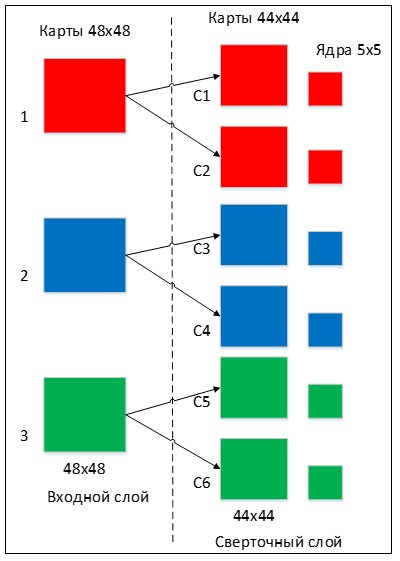 Размер у всех карт сверточного слоя – одинаковы и вычисляются по формуле:  Ядро представляет из себя фильтр или окно, которое скользит по всей области предыдущей карты и находит определенные признаки объектов. Например, если сеть обучали на множестве лиц, то одно из ядер могло бы в процессе обучения выдавать наибольший сигнал в области глаза, рта, брови или носа, другое ядро могло бы выявлять другие признаки. Размер ядра обычно берут в пределах от 3х3 до 7х7. Если размер ядра маленький, то оно не сможет выделить какие-либо признаки, если слишком большое, то увеличивается количество связей между нейронами. Также размер ядра выбирается таким, чтобы размер карт сверточного слоя был четным, это позволяет не терять информацию при уменьшении размерности в подвыборочном слое, описанном ниже. Ядро представляет собой систему разделяемых весов или синапсов, это одна из главных особенностей сверточной нейросети. В обычной многослойной сети очень много связей между нейронами, то есть синапсов, что весьма замедляет процесс детектирования. В сверточной сети – наоборот, общие веса позволяет сократить число связей и позволить находить один и тот же признак по всей области изображения. В сверточных нейронных сетях применяется ещё один слой, называемый слоем Pooling. Суть этого слоя заключается в уменьшении размерности карты признаков. Pooling имеет две разновидности: max-pooling и average-pooling. В большинстве случаев применяется max-pooling. Операция Pooling схожа с операцией свертки: Скользящее окно, обычно это окно (2,2), двигается по карте признаков. Из выбранного шаблона выбирается максимальное (max-pooling) или среднее (average-pooling) значение. Формируется уменьшенная в размере карта признаков На рисунке ниже показано, как из матрицы (4,4) получается выходная карта (2,2) после операции max-pooling и average-pooling. 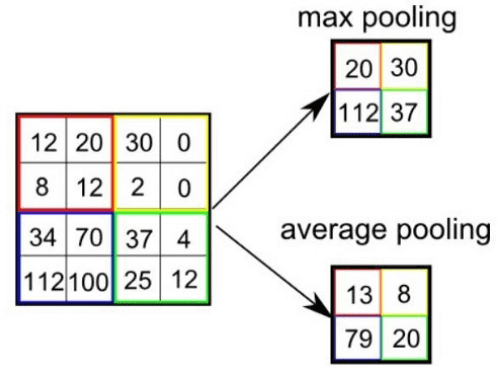 Зачем нужно уменьшать размерность с помощью Pooling? На это есть несколько причин: Для поддержания иерархичности. Архитектура сверточных нейронных сетей похожа на воронку, где все начинается с большой картины с последующим углублением в отдельные детали. Человеческий мозг устроен также: сначала он видит на улице кошку, а затем начинает разглядывать ее цвет, пятна, уши, глаза и т.д. Это является основой Deep learning — обучение на представлениях. Уменьшение размерности приводит к уменьшению количества обучаемых коэффициентов, поэтому это ещё и выигрыш в вычислительных ресурсах. Сверточные нейронные сети смогли завовоевать свою популярность благодаря соответствию иерархичности представлений, поскольку изучаются локальные шаблоны. У CNN есть несколько свойств: Полученные представления являются инвариантными по отношению к переносу. На изображении кошка может находиться в любом доступном месте, а сверточная сеть не запоминает её положения, CNN лишь знает о её представлениях (ушах, глазах и т.д.) Модель CNN является пространственно-иерархической. На первых слоях изучаются локальные шаблоны, а последующие изучают шаблоны, полученные из первых слоев. Можно заметить, что применение операции свертки уменьшает изображение. Также пиксели, которые находятся на границе изображения участвуют в меньшем количестве сверток, чем внутренние. В связи с этим в сверточных слоях используется дополнение изображения (англ. padding). Выходы с предыдущего слоя дополняются пикселями так, чтобы после свертки сохранился размер изображения. Такие свертки называют одинаковыми (англ. same convolution), а свертки без дополнения изображения называются правильными (англ. valid convolution). Среди способов, которыми можно заполнить новые пиксели, можно выделить следующие: zero shift: 00[ABC]00; border extension: AA[ABC]CC; mirror shift: BA[ABC]CB; cyclic shift: BC[ABC]AB. Еще одним параметром сверточного слоя является сдвиг (англ. stride). Хоть обычно свертка применяется подряд для каждого пикселя, иногда используется сдвиг, отличный от единицы — скалярное произведение считается не со всеми возможными положениями ядра, а только с положениями, кратными некоторому сдвигу s. Тогда, если если вход имел размерность w×h, а ядро свертки имело размерность kx×ky и использовался сдвиг s, то выход будет иметь размерность ⌊(w-kx)/s + 1⌋×⌊(h-ky)/s + 1⌋. Рекуррентные нейронные сети. Область применения и основные архитектуры. Процесс обучения рекуррентных ИHC (понятие backpropagation through time). Примеры использования рекуррентных нейронных сетей.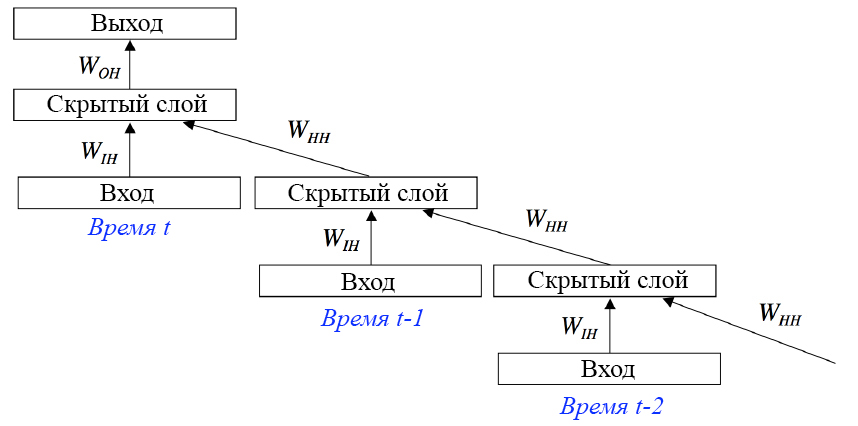 Рекуррентные нейронные сети — сети с циклами, которые хорошо подходят для обработки последовательностей. Очень часто их применяют для: обработки естественного человеческого языка, анализа написанного текста, машинного перевода текста, генерации текста, генерации чисел, и др. При работе с текстами они способны оценивать его грамматическую и семантическую корректность. Рекуррентные нейронные сети способны проанализировать какой-либо текст, а потом на основе этого анализа составить читабельный и похожий на проанализированный текст. Например, можно взять текст А. С. Пушкина, проанализировать его, а потом попробовать сгенерировать похожий текст. Рекуррентные нейронные сети способны будут сделать текст с похожим стилем. Обучение RNN аналогично обучению обычной нейронной сети. Мы также используем алгоритм обратного распространения ошибки (англ. Backpropagation), но с небольшим изменением. Поскольку одни и те же параметры используются на всех временных этапах в сети, градиент на каждом выходе зависит не только от расчетов текущего шага, но и от предыдущих временных шагов. Например, чтобы вычислить градиент для четвертого элемента последовательности, нам нужно было бы «распространить ошибку» на 3 шага и суммировать градиенты. Этот алгоритм называется «алгоритмом обратного распространения ошибки сквозь время» (англ. Backpropagation Through Time, BPTT). Используются, когда важно соблюдать последовательность, когда важен порядок поступающих объектов. Обработка текста на естественном языке: Анализ текста; Автоматический перевод; Обработка аудио: Автоматическое распознавание речи; Обработка видео: Прогнозирование следующего кадра на основе предыдущих; Распознавание эмоций; Обработка изображений: Прогнозирование следующего пикселя на основе окружения; Генерация описания изображении
Основные архитектуры: Полностью рекуррентная сеть Рекурсивная сеть Нейронная сеть Хопфилда Двунаправленная ассоциативная память (BAM) Сеть Элмана Сеть Джордана Эхо-сети Нейронный компрессор истории Сети долго-краткосрочной памяти Управляемые рекуррентные блоки Двунаправленные рекуррентные сети Seq-2-seq сети Рекуррентные нейронные сети применяются в следующих областях: Языковое моделирование и генерирование текста. Исследуется последовательность слов. На основе ее исследования нейросеть способна «предугадать» вероятность каждого последующего слова. Таким способом формируются тексты. Для того чтобы нейронная сеть сгенерировала какой-то текст, ей на вход нужно предоставить шаблон текста для генерирования. Машинный перевод. Эта сфера немного похожа на предыдущую, потому что в качестве входных данных используется последовательный текст. Вводится последовательный текст исходного языка, например, текст на русском. Потом вводится последовательный текст языка, на который нужно переводить, например, текст на английском. Нейронная сеть изучает оба текста и сопоставляет последовательность перевода слов. Распознавание человеческой речи. Для такого действия в качестве входных данных для обучения нейросети применяют последовательность акустических сигналов в виде аудиозаписей. Анализируя аудиозаписи, нейросеть будет способна предугадывать вероятную последовательность человеческой речи. Генерация изображений. В «чистом» виде рекуррентные нейронные сети не в состоянии генерировать изображения, но в тандеме со сверточными нейронными сетями делают это достаточно легко. |