Криптография Отчет. Исследование методов полиалфавитной подстановки
 Скачать 239.26 Kb. Скачать 239.26 Kb.
|

|
Частное образовательное учреждение высшего образования «Казанский инновационный университет имени В.Г. Тимирясова (ИЭУП)» Факультет менеджмента и инженерного бизнеса Кафедра информационных технологий и безопасности Лабораторная работа № 1 На тему: ИССЛЕДОВАНИЕ МЕТОДОВ ПОЛИАЛФАВИТНОЙ ПОДСТАНОВКИ По направлению 09.03.03 Прикладная информатика Выполнил: Обучающийся гр. 1081 очной формы обучения Галеев Рустем Галимянович Преподаватель Баязитова Василя Идиаловна Казань – 2021 Содержание 1. Цель работы: 3 2. Задание: 3 3. Анализ задания: 3 4. Алгоритм преобразования: 3 5. Программа на алгоритмическом языке: 4 6. Тестовые запуски и статистический анализ: 7 9. Выводы по работе: 7 1. Цель работы: Изучение принципов построения моноалфавитных и полиалфавитных шифров замены. Исследование свойств подстановочных шифров. 2. Задание: Модуль для шифрования текста по алгоритму Виженера, ключ – числовая последовательность 3. Анализ задания: Математически шифр Виженера можно описать следующими формулами: Encrypt(mn) = (Q + mn + kn) % Q; Decrypt(cn) = (Q + cn - kn) % Q. где mn - позиция символа открытого текста, kn - позиция символа ключа шифрования, Q - количество символов в алфавите, cn - позиция символа зашифрованного текста. Идея его заключается в том, что мы даже одной и той же букве можем поставить в соответствие разные буквы. Величина смещения каждой буквы в конкретной позиции определяется с помощью ключа. Таким образом, шифр Виженера является более защищённым, чем шифр Цезаря, за счет того, что мы всегда смещаем буквы на разное количество символов. 4. Алгоритм преобразования: Моноалфавитные шифры замены имели существенный недостаток – они легко поддавались частотному криптоанализу. Возникла потребность в разработке более устойчивых методов шифрования. Так на смену моноалфавитным шифрам пришли шифры полиалфавитные. Метод Виженера относится к числу полиалфавитных шифров замены. Берется небольшое целое число m и алфавит после каждой символьной подстановки сдвигается на m символов. Например, если ключом будет слово мышь (смотри левую вертикальную колонку символов), тогда m = 4, при этом получаем следующую таблицу: абвгдеёжзийклмнопрстуфхцчшщъыьэюя 1 мнопрстуфхцчшщъыьэюяабвгдеёжзийкл 2 ыьэюяабвгдеёжзийклмнопрстуфхцчшщъ 3 шщъыьэюяабвгдеёжзийклмнопрстуфхцч 4 ьэюяабвгдеёжзийклмнопрстуфхцчшщъы Исходный текст разбивается на группы по m символов (в рассмотренном случае – по 4). Для каждой группы первый символ заменяется соответствующей буквой из первого алфавита, второй – из второго и т.д. Например, фраза «от улыбки каждый день светлей» будет преобразована следующим образом: отул ыбки кажд ыйде ньсв етле й ынлз зьге чыяа зеьб ъчйю сндб ц Алфавит не ограничивается только лишь буквами, в него можно добавить и другие символы – пробел, цифры, знаки препинания. Такая модификация позволит избежать двусмысленности при чтении текста после расшифровки на приёмной стороне (например, проблема простановки запятой во фразе «казнить нельзя помиловать»). 5. Программа на алгоритмическом языке: def form_dict(): d = {} iter = 0 for i in range(1040,1103): d[iter] = chr(i) iter = iter +1 return d def encode_val(word): list_code = [] lent = len(word) d = form_dict() for w in range(lent): for value in d: if word[w] == d[value]: list_code.append(value) return list_code def comparator(value, key): len_key = len(key) dic = {} iter = 0 full = 0 for i in value: dic[full] = [i,key[iter]] full = full + 1 iter = iter +1 if (iter >= len_key): iter = 0 return dic def full_encode(value, key): dic = comparator(value, key) # print ('Compare full encode', dic) lis = [] d = form_dict() for v in dic: go = (dic[v][0]+dic[v][1]) % len(d) lis.append(go) return lis def decode_val(list_in): list_code = [] lent = len(list_in) d = form_dict() for i in range(lent): for value in d: if list_in[i] == value: list_code.append(d[value]) return list_code def full_decode(value, key): dic = comparator(value, key) # print ('Deshifre=', dic) d = form_dict() lis =[] for v in dic: go = (dic[v][0]-dic[v][1]+len(d)) % len(d) lis.append(go) return lis if __name__ == "__main__": word = input("Введите сообщение: ") key = input("Введите ключ: ") key_encoded = encode_val(key) value_encoded = encode_val(word) # print ('Value= ',value_encoded) # print ('Key= ', key_encoded) shifre = full_encode(value_encoded, key_encoded) print ('Шифр=', ''.join(decode_val(shifre))) decoded = full_decode(shifre, key_encoded) # print ('Decode list=', decoded) decode_word_list = decode_val(decoded) print ('Фраза=',''.join(decode_word_list) ) 6. Тестовые запуски и статистический анализ: 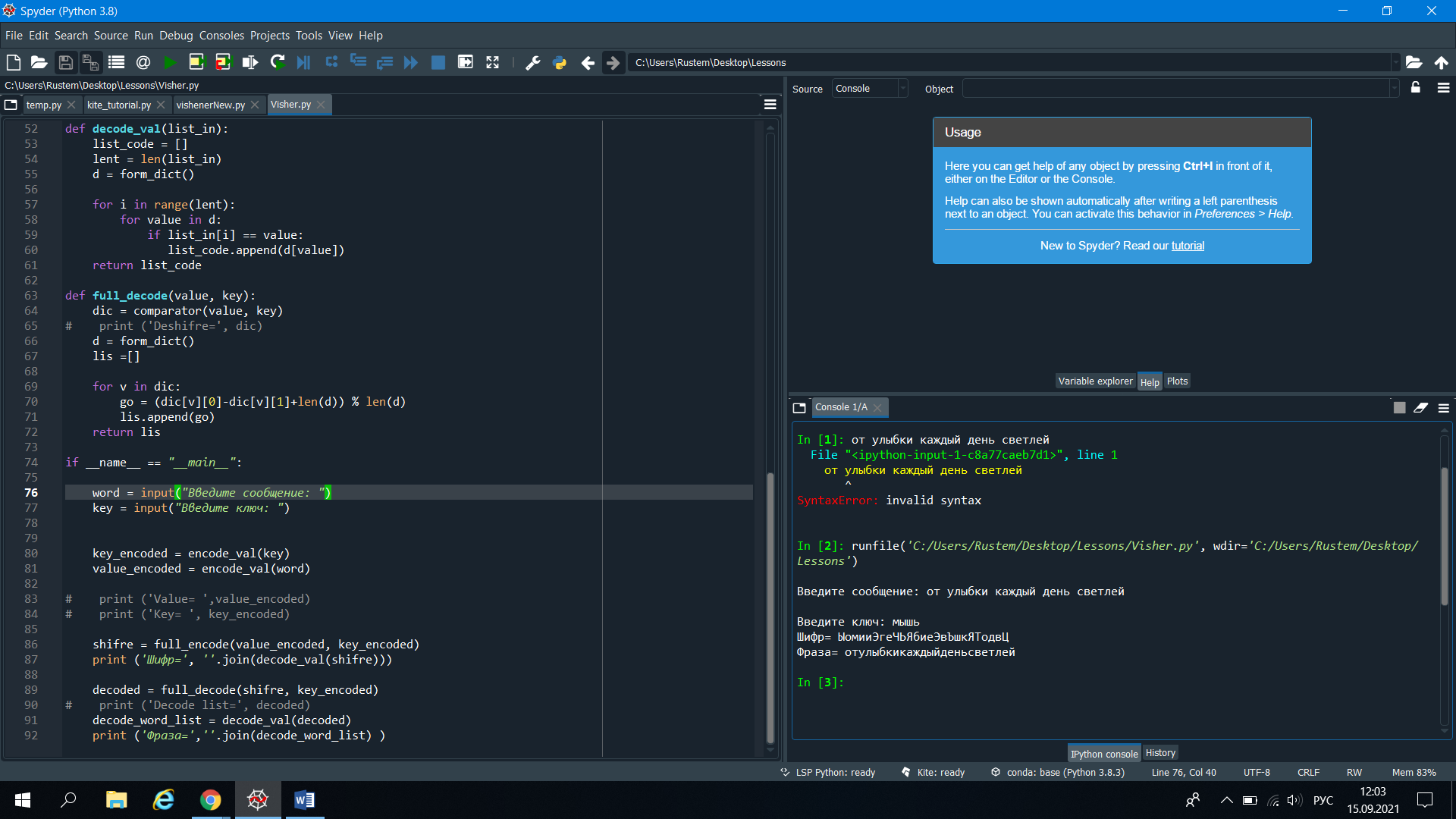 9. Выводы по работе: Были изучены принципов построения моноалфавитных, полиалфавитных шифров замены и шифра Виженера. |