ТИДЗ ЛР9. ИСТ-112ДерендяевК.С.ЛР9. Кафедра информационных управляющих систем Лабораторная работа 9 Исследование методов классификации изображений рукописных цифр с помощью полносвязной нейронной сети
 Скачать 0.59 Mb. Скачать 0.59 Mb.
|

|
МИНИСТЕРСТВО ЦИФРОВОГО РАЗВИТИЯ, СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ «САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ ИМ. ПРОФ. М.А. БОНЧ-БРУЕВИЧА» (СПбГУТ) Кафедра информационных управляющих систем Лабораторная работа № 9 «Исследование методов классификации изображений рукописных цифр с помощью полносвязной нейронной сети» Вариант 1 Работу выполнили студенты гр. ИСТ-112: Агарков В.А., Дерендяев К.С., Мельников М.А. Проверил: Эль Сабаяр Шевченко Н. Санкт-Петербург 2023 Цель работы – исследование принципов разработки нейронной сети на примере задачи классификации изображений помощью GPU. Формулировка задания 1. Исследовать нейронную сеть при заданных начальных параметрах (см. таблицу). 2. Исследовать зависимость точности распознавания от количества нейронов в скрытом слое, количества слоев, метода активации. 3. Замерьте время вычисления 100 эпох на CPU и на GPU. Какое ускорение вы наблюдаете? 4. Постройте на одном графике loss для train и test. Имеется ли переобучение сети?  Ход работы 1. Импортируем необходимые библиотеки и проведём инициализацию random seed. 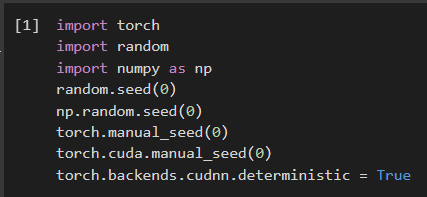 2. Импортируем датасет MNIST, на котором нейронная сеть будет обучаться  3. Обозначим одномерные и многомерные тензоры, изменим их тип данных и размерность  4. Создадим нейронную сеть MNISTNet с заданным количеством нейронов в скрытом слое. 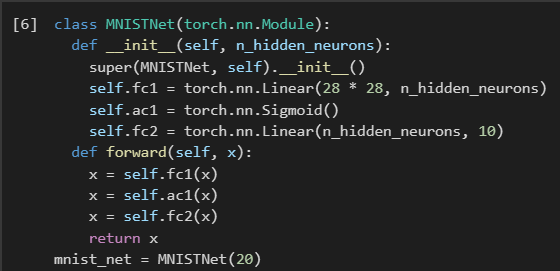 5. Запустим процесс обучения (стохастический градиентный спуск) на 100 эпох, используя заданные параметры. 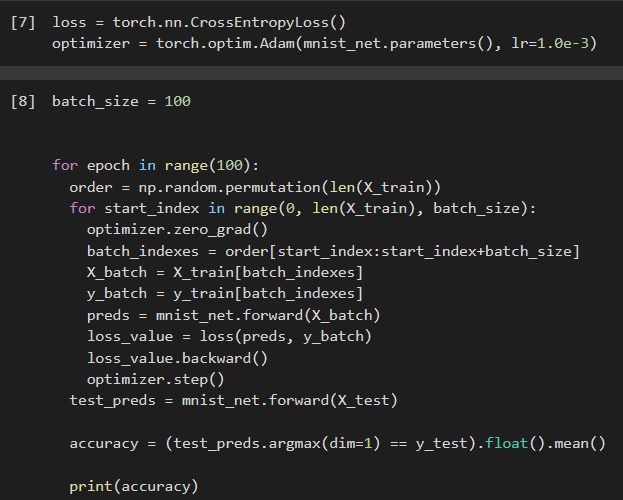  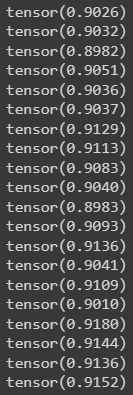 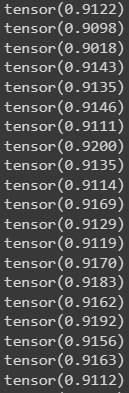 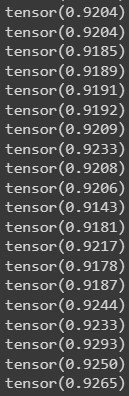 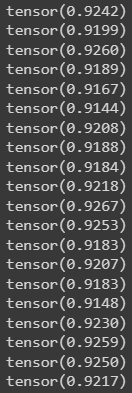 Из результатов можно сказать, что нейронная сеть обучается довольно медленно, эпоха вычисляется за несколько секунд, но уже сразу после обучения первых эпох получаем accuracy больше 90%. Ближе к концу видно, что точность в какой-то момент перестаёт увеличиваться и остаётся на одном уровне. Всё обучение заняло 90 секунд. 6. Проведём обучение, переместив вычисления на GPU.  Обучение прошло быстрее и заняло всего 81 секунду, что на 11% быстрее, чем с использованием CPU. Ниже представлен график точности (оранжевый) и ошибок (синий). 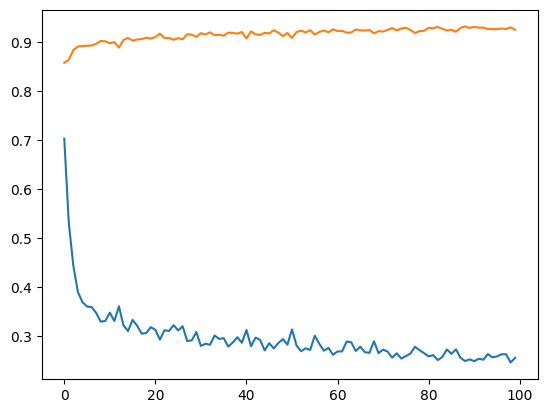 7. При увеличении кол-ва нейронов в скрытом слое вдвое (40) можно заметить увеличение точности и уменьшение ошибки 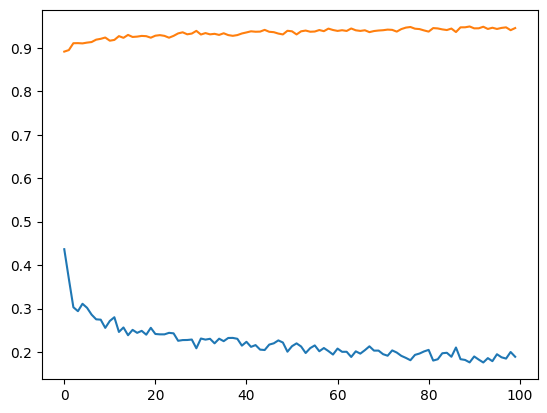 При уменьшении кол-ва нейронов вдвое (10) результат абсолютно противоположный, точность стала меньше, а ошибка увеличилась, при этом время обучения уменьшилось. 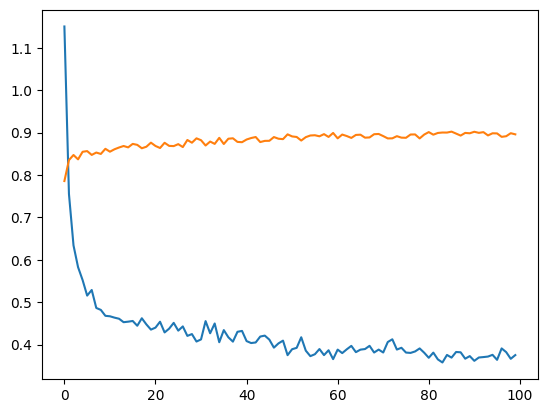 8. Увеличение кол-ва скрытых слоёв до трёх не оказалось эффективным для обучения нашей нейронной сети. Возможно, это будет правильным решением для более сложных задач, но не в данном случае.  9. При смене метода оптимизации с ADAM на SGD можно заметить, что время обучения немного уменьшилось. Также видно, что нейросеть обучилась немного хуже. График даёт понять, что нейросеть с данным методом оптимизации вначале допускает гораздо большее количество ошибок, чем при использовании ADAM. Можно сделать вывод, что метод оптимизации ADAM является более предпочтительным, так как показывает лучшие результаты. 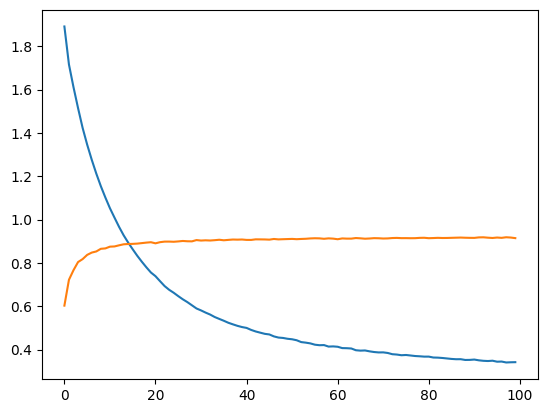 10. На данном графике можно увидеть ошибки нейросети при обучении и при проходе тестовой части датасета. Можно заметить, что график train (зелёный) сильно скачет, в то время как test (синий) более равномерный. Из этого можно сделать вывод, что нейросеть, скорее всего, переобучилась. 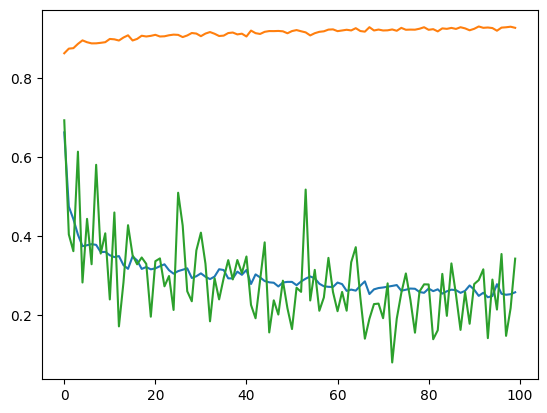 Вывод: В ходе выполнения работы были исследованы принципы разработки нейронной сети на примере задачи классификации изображений с помощью CPU и GPU. Была исследована нейронная сеть при заданных начальных параметрах, исследована зависимость точности распознавания от количества нейронов в скрытом слое, количества слоев, метода активации. Были построены на одном графике loss для train и test. Выяснили, что имеется переобучение сети. |