Арсланова_Г_А_и_др_Essential_English_for_Biology_Students (1). Kazan federal university
 Скачать 7.01 Mb. Скачать 7.01 Mb.
|

|
The inheritance of two characteristics Dihybrid inheritance is the inheritance of two characteristics, each controlled by a different gene at a different locus. In one experiment Mendel studied dihybrid inheritance by crossing plants from two pure-breeding strains: one tall with purple flowers, the other dwarf with white flowers. All the offspring in the F1 generation were tall with purple flowers, these being the dominant characteristics. The F1 generation were self-crossed, producing the following phenotypes and ratios in the F2 generation: 9 tall purple-flowered 3 tall white-flowered 3 dwarf purple-flowered 1 dwarf white-flowered. Mendel observed that two phenotypes resembled one or other of the parents, and two phenotypes had combined the characteristics of both parents. He also observed that the ratio of tall plants to dwarf plants was 3:1, and that the ratio of purple-flowered plants to white-flowered plants was 3:1. This was the same ratio that occurred in the monohybrid crosses. He concluded from these results that the two pairs of characteristics behave quite independently of each other. This led him to formulate his law of independent assortment, which states that any one of a pair of characteristics may combine with any one of another pair. Interpreting the results of a dihybrid cross  Mendel's results can be explained in terms of alleles and the behaviour of chromosomes during meiosis. Notice that the two alleles for one gene are always written together (for example, TtPp, not TPtp). This makes it easier to interpret the crosses. The pure-breeding adult plants, being diploid, have two alleles for each gene. The genes for height and flower colour are carried on separate chromosomes. During gamete formation, meiosis occurs, producing gametes containing one allele for each gene. In the F1 generation, the only possible genotype is TtPp. When these plants are self-crossed, there are four possible combinations of alleles in both the female and male gametes: TP, Tp, tP, and tp. Assuming fertilisation is random, any male gamete can fuse with any female gamete, so there are 16 possible combinations for the offspring, as shown in the Punnett square. These combinations can produce four different phenotypes from nine genotypes. The only genotype that can be worked out simply by looking at the plants is that of the dwarf white-flowered plants. Genotypes of the other plants can be established by test crosses. Recombination As already stated, two of the phenotypes in the F2 resemble the original parents (tall purple-flowered and short white-flowered), and two show new combinations of characteristics (tall white-flowered and dwarf purple-flowered). This process that results in new combinations of characteristics is called recombination, and the individuals that have the new combinations are known as recombinants. Recombination is an important source of genetic variation, contributing to the differences between individuals in a natural population. Quick check: 1. What are recombinants? 2. Give a genetic explanation of Mendelian dihybrid inheritance. 3. Explain the significance of recombination. 4. Explain the use of test crosses to determine unknown genotypes in studies of dihybrid inheritance 5. Divide the text into an introduction, principal part and conclusion. 6. Express the main idea of each part. 7. Give a title to each paragraph of the text. 8. Summarize the text in brief. ■ Text 5. Sex Determination O  ne of the most fascinating marine animals is the slipper limpet, a mollusc with the intriguing scientific name of Crepidula fornicate. It was given this name because it has the surprising ability to change its sex. The limpets are immobile for most of their lives, growing in chains. The sex of each limpet depends on its size and its position in the chain. The young, small individuals are males, with long tapering penises which fertilise females lower in the chain. In due course, when a male has grown and has been settled on by another smaller limpet, the male loses its penis and grows into a female. Thus large females occur at the base of the chain, with animals changing sex above them, and males at the apex. In this way, the limpets have been able to combine immobility with internal fertilisation. Sex chromosomes There have been many weird and wonderful ideas about sex determination in humans. Some Ancient Greeks thought that the sex of a baby was determined by which testicle the sperm came from. Apparently, this belief was adopted by some European kings who tied off or removed their left testicle to ensure a male heir to the throne. Other people believed that the sex of a baby could be controlled by conceiving when the Moon was in a particular phase, when the wind was blowing in a certain direction, or whilst speaking certain words. We now know that human sex is determined by a pair of sex chromosomes called X and Y. Because these chromosomes do not look alike, they are sometimes called heterosomes. All other chromosomes are called autosomes. Females have two X chromosomes (XX). Males have one X and one Y chromosome (XY). Although the sex chromosomes determine the sex of an individual, it is important to realise that they do not carry all the genes responsible for the development of sexual characteristics. During meiosis, the sex chromosomes pair up and segregate into the daughter cells. Males are called the heterogametic sex because they produce different sperm: approximately 50% contain an X chromosome and 50% have a Y chromosome. Females are called the homogametic sex because (usually) all of their eggs contain an X chromosome. This arrangement applies to all mammals and some insects (including Drosophila, the fruit fly commonly used in genetic experiments). However, in birds, moths, and butterflies, females are the heterogametic sex with the XY genotype (or XO, meaning the second sex chromosome may be absent). In some species, sex determination depends on a complex interaction between sex chromosomes and autosomes, or between inherited factors and environmental ones. The sex of some turtles, for example, depends on the temperature of the sand in which eggs are laid: those laid in sand warmed by the Sun develop into females; those laid in cool sand in the shade develop into males. In humans, the father's sperm determines the sex of the baby: if a baby inherits a Y chromosome from its father it will be a boy; if it inherits an X chromosome from its father it will be a girl. So the sex of a baby depends on which sperm fertilises the egg cell: a sperm with an X chromosome or one with a Y chromosome. However, there are cases where having a Y chromosome does not necessarily mean that an embryo will become a boy. The SRY gene I 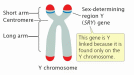 n the early stages of development, human embryos have no external genitalia. Whether they develop testes or ovaries depends on the presence and activity of a particular gene on the Y chromosome. This gene, called the sex related Y gene (SRY gene), was discovered in 1990 when geneticists were studying some interesting people: men who had two X chromosomes and women who had one X and one Y chromosome. Microscopical examination of the sex chromosomes of these people revealed that the XX males had a very small piece of Y chromosome in their X chromosomes, whereas this piece was missing from the Y chromosome of the XY females. The geneticists found the SRY gene within this small piece of Y chromosome. The SRY gene codes for a protein called testis determining factor. This switches on other genes, causing the embryo to develop male structures. The testes develop and androgens (hormones which promote the development of male sexual organs and secondary sexual characteristics) are secreted. At about 16 weeks, an embryo with the SRY gene begins to produce immature sperm. In addition to stimulating male structures to grow, SRY suppresses the development of female structures by activating a gene on chromosome 19. This activation leads to the production of a protein called Mullerian- inhibiting substance, which destroys female structures early in their development. Lack of testis determining factor results in the development of female genital organs. Therefore, all embryos are female unless active testis determining factor makes them male. Sex testing The governing bodies of all-female sports sometimes use sex tests to make sure participants in their sports are female. The first attempts at gender verification were by the International Amateur Athletic Federation, whose sex test included parading naked female athletes before a panel of male doctors. In 1968 this rather dubious procedure was dropped, and the International Olympic Committee adopted the Barr test. This test uses the presence of stainable particles called Barr bodies as sex indicators. Barr bodies occur in epithelial cells in the mouth (buccal epithelial cells), and are thought to be derived from inactive X chromosomes. Females therefore usually have one Barr body in their buccal epithelial cells and males usually have none. At the 1992 Barcelona Olympics, the Barr test was replaced by the polymerase reaction test. In this test, the polymerase chain reaction. Sex testing is complicated by the fact that, on rare occasions, sex chromosomes fail to segregate at meiosis. This phenomenon, known as non-disjunction, can result in a sperm cell either having both an X and a Y chromosome or having no sex chromosome, and an egg cell either having two X chromosomes or having no sex chromosome. Non-disjunction can lead to unusual genotypes. Sex testing is confused even further by the occurrence of chimaeras. A chimaera is any animal or plant consisting of some cells with one genetic constitution and some with another. Very rarely, chimaera formation can occur during the early stages of embryonic development when chromosomes in mitotically dividing cells fail to segregate properly (for example, some cells can have the genotype XXX, others XO, while the majority are XX!). Quick check: 1. Why are males called the heterogametic sex? 2. Explain why an embryo with an XY genotyper may develop female sexual organs. 3. Explain why a person may have buccal epithelial cells with two Barr bodies. Discuss the role of the sex related Y gene in determining sex. 4. Describe how non-disjunction can affect the distribution of sex chromosomes in gametes and offspring. 5. Explain how sex is determined in humans. 6. Divide the text into an introduction, principal part and conclusion. 7. Express the main idea of each part. 8. Give a title to each paragraph of the text. 9. Summarize the text in brief. ■ Text 6. DNA Replication D  NA replication is a very complex process during which mistakes happen. Uncorrected mistakes may lead to harmful mutations. In the living cell, errors are kept to a very low frequency (about one in 109) by a number of repair mechanisms. One such mechanism is mismatch repair. This is carried out by the enzyme DNA polymerase which 'proofreads' newly formed DNA against its template as soon as it is added to the strand. If it finds an incorrectly paired nucleotide, the polymerase reverses its direction of movement, removes the incorrect nucleotide, and replaces it before replication continues. The process is similar to correcting a typing error by going back a space, deleting the error, and typing in the correct letter before continuing. A possible mechanism for replication A chemical that carries inherited information must be able to copy itself exactly. Complementary base pairing between adenine and thymine and between cytosine and guanine makes this possible. Watson and Cricks description of DNA suggested that, during replication, the hydrogen bonds connecting base pairs are disrupted allowing the two polynucleotide chains to unwind from one another. Each chain then acts as a template for the synthesis of a new complementary polynucleotide chain. It was suggested that the DNA molecule 'unzips' from one end and new nucleotides already present in the nucleus bind with their complementary bases in each exposed chain. This therefore forms two identical molecules of DNA from the single parent molecule. Experimental evidence Arthur Korrnberg and his colleagues were the first to successfully replicate DNA in a test tube. They used the following ingredients: intact DNA (to act as a template) a mixture containing all four nucleotides DNA polymerase (an enzyme which catalyses the synthesis of DNA) ATP (as a source of energy). New DNA molecules were formed, which contained the same proportions of the four bases as the original parent DNA. This was a strong indication that DNA can copy itself by complementary base pairing. Semiconservative replication The idea that DNA unzips before replication is an attractively simple one. This mechanism is called semiconservative replication, because each new molecule of DNA (daughter DNA) contains one intact strand from the original DNA (parental DNA) and one newly synthesised strand. However, semiconservative replication is not the only means by which DNA might replicate by complementary base pairing (figure 1). Meselsohn and Stahl In 1958, two American biochemists, Matthew Meselsohn and Franklin Stahl, conducted a neat experiment which gave strong support for the theory of semiconservative replication. First, they grew Escherichia coli bacteria for many generations in a medium containing 15N, a heavy isotope of nitrogen. The bacteria incorporated the 15N into their DNA. This made the DNA denser than normal ('heavy' DNA). A control culture of bacteria was grown in a medium with 14N, the normal, lighter isotope of nitrogen. These bacteria had normal 'light' DNA. The bacteria grown in 15N were then transferred to a 14N medium and left for periods of time that corresponded to the generation time of E.. coli (about 50 minutes at 36° C). Samples of bacteria were taken at intervals to analyse the parental, first-generation, and second-generation DNA. The composition of the DNA was analysed using density gradient centrifugation. The mixture of the three DNA types was suspended in a solution of caesium chloride and spun at high speed in a centrifuge. The DNA separated according to its density: heavy DNA (which contained 15N) formed a band lower down the tube than the light DNA (which contained 14N). The bands became visible when the tubes were exposed to ultraviolet light. The results gave overwhelming support to the semiconservative hypothesis. In the first generation, all the DNA had a density midway between that of heavy DNA and light DNA. Thus it contained equal amounts of each. In the second generation, two sorts of DNA were detected: one was light DNA; the other containing equal amounts of 14N and 15N (i.e. it was like the DNA in the first-generation bacteria). Throughout the investigation, DNA from the control culture produced only light bands, indicating that it contained only 14N. The enzymes involved in replication DNA replication is a complex process involving several different enzymes: Helicases separate the two DNA strands. Their action uses energy from ATP. DNA binding proteins keep the strands separate during replication. DNA polymerases catalyse the polymerisation of nucleotides to form a polynucleotide chain in the 5' to Уdirection. This allows one strand to be replicated continuously. The other strand is not replicated continuously but in small sections. The pieces of polynucleotide chain are joined together by an enzyme called DNA ligase. DNA is a long molecule. DNA replication would take a long time if it started at one end and proceeded nucleotide by nucleotide along the entire length of the molecule. In fact, the double helix opens up and replicates simultaneously at a number of different sites, known as replication forks. DNA ligases then join the segments of DNA together, completing the synthesis of new DNA strands. Quick check: 1. List the ingredients Kornberg used to make DNA in the test tube. 2. During DNA replication, what is the function of: a) helicases b) DNA binding proteins c) DNA polymerase d) DNA ligase? 3. Suppose DNA replication were conservative. What results would Meselsohn and Stahl have obtained in the first generation? 4. Describe how DNA can be made in the laboratory. 5. Interpret Meselsohn and Stahl’s experiment on semiconservative replication. 6. Describe how semiconservative replication takes place. 7. Divide the text into an introduction, principal part and conclusion. 8. Express the main idea of each part. 9. Give a title to each paragraph of the text. 10. Summarize the text in brief. ■ Text 7. The Chemical Nature Of Genes A 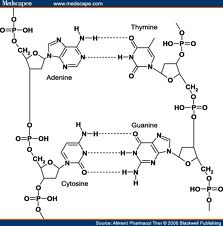 capsule is an outer coat covering a bacterial cell. Unlike a slime layer, it is not easily washed off. Although capsules are not essential for bacterial growth and reproduction in laboratory conditions, they can make the difference between life and death in natural situations. For example, Streptococcus pneumoniae (a member of the pneumococci, the group of pneumonia-causing bacteria used in Griffith's experiment; see text) has non-capsulated and capsulated strains. Those lacking a capsule are easily destroyed by the host and do not cause disease. However, the capsulated strain kills mice quickly. The capsule helps the bacterium resist phagocytosis by host cells. It contains a great deal of water, protecting the bacterium from desiccation; it keeps out detergents which could destroy the cell surface membrane; and it helps bacteria attach to host cells. capsule is an outer coat covering a bacterial cell. Unlike a slime layer, it is not easily washed off. Although capsules are not essential for bacterial growth and reproduction in laboratory conditions, they can make the difference between life and death in natural situations. For example, Streptococcus pneumoniae (a member of the pneumococci, the group of pneumonia-causing bacteria used in Griffith's experiment; see text) has non-capsulated and capsulated strains. Those lacking a capsule are easily destroyed by the host and do not cause disease. However, the capsulated strain kills mice quickly. The capsule helps the bacterium resist phagocytosis by host cells. It contains a great deal of water, protecting the bacterium from desiccation; it keeps out detergents which could destroy the cell surface membrane; and it helps bacteria attach to host cells.We know today that DNA is the chemical in which information is from parent to offspring. This spread looks at how researchers established this link between DNA and inheritance. In the 1860s, nearly 100 years before Watson and Crick's work on the structure of DNA, Gregor Mendel established that inheritance depends on factors that are transmitted from parents to offspring. In 1909 it was found that patterns of inheritance were reflected in the behaviour of chromosomes. Wilhelm Johannsen referred to these factors as genes. Genes were assumed to be located on the chromosomes because genes that are inherited together (linked genes) were found to be carried on the same chromosome. However, the chemical composition of genes was not known. Protein or DNA: which is the genetic material? Chromosomes were known to contain both protein and DNA. Most biologists assumed that proteins, with their highly complex and infinitely variable structure, were the inherited material. The nucleic acids were thought to be too simple to carry complex genetic information. This view was reinforced by the work of Phoebus Aaron Levene. Levene made major contributions to the chemistry of nucleic acids but believed, mistakenly, that DNA was a very small molecule, probably only four nucleotides long. In 1928 Fred Griffith, an English medical bacteriologist, published a paper describing experiments on pneumococci. His results set the stage for the research that finally showed that DNA is the genetic material. Griffith's experiment: transformation of pneumococci. P 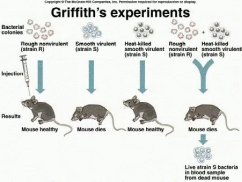 neumococci are bacteria that cause pneumonia. They occur in two strains: a disease-causing smooth strain (strain S), and a harmless rough strain (strain R). Strain S has a capsule on its cell surface; this capsule is absent from the harmless strain R (see Fact of life). Griffith found that mice injected with live strain S soon died, but those injected with live strain R survived. Mice injected with dead strain S bacteria (killed by heat) аll survived. The results of this series of experiments were as expected. However, the results of Griffith's next series of experiments were thoroughly baffling: mice injected with a mixture of heat-killed strain S and live strain R died. Moreover, Griffith recovered live strain-S bacteria from the dead mice. After many careful experiments, Griffith concluded that hereditary material had passed from the dead bacteria to the live bacteria. This changed harmless strain R bacteria into virulent strain S pathogens. This process is called transformation. Avery's experiment: DNA was the transforming agent. I  n the 1940s, Oswald T. Avery, Colin MacLeod, and Maclyn McCarty showed that DNA was responsible for transformation. n the 1940s, Oswald T. Avery, Colin MacLeod, and Maclyn McCarty showed that DNA was responsible for transformation.They used enzymes that hydrolysed polysaccharide, DNA, RNA, and protein on samples of the disease-causing strain-S pneumococci. Different samples had different parts of their cells destroyed by these enzymes. The researchers then exposed strain-R pneumococci to the treated samples of strain S. The transformation of strain R to strain S was blocked only when the DNA in the sample was destroyed. These results provided strong evidence that DNA carried genetic information for transformation. However, many scientists remained unconvinced. Hershey and Chase: the role of DNA on the T2 phage life cycle I  n 1952, Alfred D. Hershey and Martha Chase performed several experiments with T2 bacteriophage, a virus that infects bacteria. Their results convinced even the sceptics that DNA, and not protein, was the genetic material. n 1952, Alfred D. Hershey and Martha Chase performed several experiments with T2 bacteriophage, a virus that infects bacteria. Their results convinced even the sceptics that DNA, and not protein, was the genetic material.Electron micrographs indicate that T2 bacteriophage infects Escherichia coli by injecting its DNA into the bacterium while leaving its protein coat on the outside. The phage takes over the genetic machinery of the host cell to make new phages. Eventually, the bacterial cell bursts (a process called lysis), releasing new phages to infect other bacteria (figure 1). Hershey and Chase wanted to test the hypothesis that only the viral DNA entered the bacterium. They made use of the fact that DNA contains phosphorus but not sulphur, whereas protein contains sulphur but not phosphorus. With some T2 phages, they labelled the viral DNA with a radioactive isotope of phosphorus (32P). With other T2 phages, they labelled the viral protein coat with a radioactive isotope of sulphur (35S). They added the viruses to a culture of E. coli and gave them enough time to infect their host cells (but not enough time to reproduce). The viral coats were then separated from the infected bacteria by shaking the mixture vigorously in a blender. When E. coli was infected with a T2 phage containing 35S (labelled Protein), little radioactivity occurred within the bacterial cells. With a T2 phage containing 32P (labelled DNA), the bacterial cells were radioactive. Moreover, when the bacterial cells burst open, the new viruses that emerged were radioactively labelled with 32P. When the protein was labelled, new viruses were only slightly radioactive. Quick check: 1. How can the harmless rough strain of pneumococcus be transformed into the pathogenic smooth strain? 2. How can the DNA in the disease-causing smooth strain of bacteria bt extracted from RNA and proteins? 3. Describe the distribution of protein and DNA in T2 bacteriophage. 4. Explain how they can each be labelled. 5. Explain the significance of Griffith’s work on Pneumococcus. 6. Describe how Avery and other workers analysed the transforming factor. 7. Describe Hershey and Chase’s experiment. 8. Express the main idea of each paragraph in a single sentence in English. 9. Suggest a suitable title for each paragraph of the text. 10. Divide the text into an introduction, principal part and conclusion. ■ Text 8. The One Gene One Polypeptide Hypothesis Phenylketonuria (PKU) occurs in about one in 10 000 live births among white Europeans. If untreated, a patient may have an IQ (intelligence quotient) of less than 20 (the average IQ is 100). T 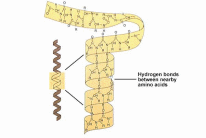 he disorder is treated by reducing the intake of phenylalanine in the diet to an absolute minimum. A child with PKU must avoid products that are rich in phenylalanine such as drinks and confectionery that are sweetened with aspartame. (Aspartame contains a mixture of two amino acids: aspartic acid and phenylalanine.) High blood levels of phenylalanine are not damaging in adulthood (presumably because brain growth is complete), so except while pregnant or breast feeding, adults with PKU can eat a normal diet. In the 1940s and early 1950s, researchers established that genes are made of DNA. At the same time, other researchers wanted, to know how genes determine inherited characteristics. Clues came from research carried out in the early 1900s by Sir Archibald Garrod. He observed that two human inherited diseases - alkaptonuria and phenylketonuria (PKU) - were each caused by absence of a specific enzyme. (He called these diseases 'inborn errors of metabolism'.) Alkaptonuria People suffering from alkaptonuria lack an enzyme called homogenistic acid oxidase. This enzyme breaks down the amino acids tyrosine and phenylalanine. When the enzyme is absent, an intermediate product known as homogenistic acid accumulates. This causes a dark brown discoloration of the skin and eyes, and progressive damage to the joints, especially the spine. Phenylketonuria Normally, phenylalanine is converted into another amino acid by a transferase (an enzyme which helps transfer a chemical group from one organic molecule to another). This enzyme is absent from people with PKU. This means that phenylalanine accumulates in the blood. High concentrations of phenylalanine damage the nervous system, leading to severe mental retardation. Nowadays, routine postnatal screening detects the condition early enough that the diet can be modified to prevent brain damage (see Fact of life). Garrod's observations indicated that genes probably exert their effects through enzymes, but the evidence was only circumstantial. Scientists wanted more direct proof that genes brought about their effects by determining which enzymes were made in cells. This proof came with the work of George Beadle and Edward Tatum on Neurospora crassa. B  eadle and Tatum: the one gene - one enzyme hypothesis eadle and Tatum: the one gene - one enzyme hypothesisNeurospora crassa is a common pink mould (a fungus) which is a particularly damaging pest in bakeries because it can turn bread mouldy. It reproduces by spores and grows in the bread as a mycelium (a mass of threads). It has several features which make it suitable for genetic research . One of the most important is its ability to produce haploid spores asexually. These spores are identical, and have only one set of chromosomes. They therefore have only one allele for each characteristic (spread 19.3). This means that a recessive mutation is not masked by a dominant allele; it is always expressed in the haploid organism. Neurospora can grow on a culture medium called minimal medium. This contains sugar, a source of nitrogen, mineral ions, and the vitamin biotin. The fungus can synthesise all the other carbohydrates, fats, proteins, and nucleic acids it needs using enzymes produced by its cells. Beadle and Tatum grew Neurospora on minimal medium and exposed the culture to a dosage of X-rays that caused the formation of mutations. Occasionally a mutant spore was produced that was unable to grow on minimal medium. However, it would grow and reproduce if provided with all 20 amino acids. After isolating a mutant Neurospora, Beadle and Tatum attempted to grow it on 20 different minimal media, each of which was supplemented with a different single amino acid. They discovered that the mutant that could not grow on the minimal medium needed only one particular amino acid in order to grow and reproduce normally. They concluded that the mutant lacked the enzyme required to synthesise that particular amino acid. Further experiments indicated that other mutants lacked different enzymes, each of which was dictated by a particular gene. In each case, Beadle and Tatum found that the inability to synthesise a specific enzyme was inherited in a normal Mendelian manner. They concluded that each gene in an organism coded for the production of one enzyme. This became known as the one gene-one enzyme hypothesis. The hypothesis was soon extended to a one gene-one protein hypothesis when it was shown that proteins other than enzymes could also be determined by specific genes. Refining the theory The hypothesis was modified into the one gene-one polypeptide hypothesis when it was realised that proteins could consist of more than one polypeptide chain, each determind by the action of a different gene. For example, haemoglobin has four polypeptide chains, two identical alpha and two identical beta chains. These two different types of polypeptide are determined by two separate genes. Sickle-cell anaemia is caused by a mutation in a single gene which results in just one amino acid being changed in the beta chain of haemoglobin. Quick check: 1. How does phenylketonuria indicate that genes exert their effects through the production of specific enzymes? 2. How does Beadle and Tatum`s experiment on neurospora support the one gene-one protein hypothesis? 3. Explain why the one gene-one protein hypothesis needed to be modified in the light of conditions such as sickle-cell anaemia. 4. Describe Beadle and Tatum’s experiment on Neurospora which led to the onegene-one enzyme hypothesis. 5. Explain how certain inherited metabolic disorders indicate that genes exert their effects through enzymes. 6. Discuss why the one gene-one enzyme hypothesis had to be modified. 7. Divide the text into an introduction, principal part and conclusion. 8. Express the main idea of each part. 9. Give a title to each part of the text and summarize the text in brief. ■Text 9. The Gene Code P 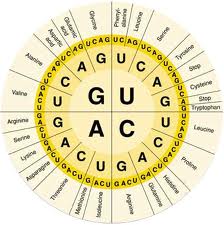 rokaryotes and eukaryotes share the same 'language of life'. Comparisons of DNA sequences with the corresponding protein sequences reveal that (with a few exceptions) an identical genetic code is used in both prokaryotes and eukaryotes. This means that bacteria can be genetically engineered to make human proteins. The universal nature of the code suggests that all living things are descended from a single pool of primitive cells which first evolved this code. rokaryotes and eukaryotes share the same 'language of life'. Comparisons of DNA sequences with the corresponding protein sequences reveal that (with a few exceptions) an identical genetic code is used in both prokaryotes and eukaryotes. This means that bacteria can be genetically engineered to make human proteins. The universal nature of the code suggests that all living things are descended from a single pool of primitive cells which first evolved this code.One of the most remarkable facts of life is that each cell in an organism contains all the information required to determine all the characteristics of that whole organism. This information is stored in DNA, and is known as the genetic code. Deciphering that code has been one of the major scientific breakthroughs of the twentieth century. It has given us anunderstanding of how genes function, and it has opened the way for most of the recent developments in genetic engineering and biotechnology. Transcribing the genetic code from DNA to mRNA The genetic code is held in the order of bases along the DNA molecule. Sections of DNA called cistrons (commonly referred to as genes) contain the information needed to make a particular polypeptide. However, DNA does not carry out polypeptide synthesis directly. When the DNA in а cistron is activated, the information is transferred to a molecule of ribonucleic acid (RNA) called messenger RNA (mRNA), which acts as a template for the synthesis of the polypeptide. The central dogma of biology The relationship between DNA, mRNA, and polypeptides in a eukaryotic I cell is often called the central dogma of biology. mRNA is made on a DNA template in the nucleus, in a process called 1 transcription. The mRNA then moves into the cytoplasm, where it combines with ribosomes to direct protein synthesis by a process called translation. When the information in a cistron is used to make a functional polypeptide chain by transcription and translation, gene expression is said to have taken place. mRNA is made from the DNA template mRNA is a large polynucleotide polymer, chemically similar to DNA but differing in that: mRNA consists of only one chain of nucleotides, not two mRNA contains the sugar ribose instead of deoxyribose mRNA contains the base uracil instead of thymine. During transcription, DNA acts as a template for making mRNA by complementary base pairing. Thus a particular short sequence of DNA may be transcribed as follows: DNA base sequence: TAGGCTTGATCG mRNA base sequence: AUCCGAACUAGC The triplet code: frame-shift experiments Twenty amino acids make all the proteins in living organisms. If a code consisted of one base for one amino acid, only four combinations would be provided (there are four bases). If two bases coded for one amino acid there would be 16 (42) possible combinations. A three-base (triplet) code provides 64 (43) possible combinations, more than enough for all 20 amino acids. Francis Crick and his co-workers confirmed that the genetic code is a triplet code. Using enzymes, they added or deleted nucleotide bases in the DNA of a virus that infects bacteria. They found that when one or two bases were added or deleted, the viruses were unable to infect the bacteria. But when three bases were added or deleted, the virus was able to infect the bacteria. They concluded that adding or removing one or two bases caused a frame shift which inactivated the gene. However, adding or removing three bases only partially affected the gene. Thus the sequence of bases shown above would contain the following sequences of DNA base triplets and mRNA codons: DNA base triplet sequence: TAG GCT TGA TCG mRNA codon sequence: AUC CGA ACU AGC If one base (for example, guanine) is added to the DNA the frame shifts and the sequence of triplets and codons is changed: DNA base triplet sequence: GTA GGT TTG АТС G mRNA codon sequence: CAU CCG AAC UAG С The results of the frame-shift experiments also showed that the code is non-overlapping: Each triplet in DNA specifies one amino acid. Each base is part of only one triplet, and is therefore involved in specifying only one amino acid. A non-overlapping code requires a longer sequence of bases than an overlapping code (see box): however, replacing one base for another has a small or no effect. Cracking the genetic code To crack the genetic code, scientists had to work out which of the 64 codons determined each amino acid. To do this, they made mRNA molecules with a known sequence of bases. This mRNA was added to a cell-free system that contained isolated ribosomes, radioactively labelled amino acids, and all the enzymes needed for polypeptide synthesis. The polypeptides that were synthesised were then analysed to determine their amino acid sequence. The first synthetic mRNA molecule made was a chain of uracil bases and was called poly-U. The polypeptide chain synthesised from it contained only phenylalanine. It was therefore concluded that the codon UUU codes for phenylalanine. The complete genetic code was confusion finally deciphered in 1966. Quick check: 1. What is the “central dogma” of biology? 2. What is the name given to the result of adding one or two nucleotide bases to a DNA sequence? 3. Describe the relationship between DNA, messenger RNA, and proteins. 4. Explain how frame-shift experiments support the triplet code hypothesis. 5. Discuss the main features of the genetic code. 6. Divide the text into an introduction, principal part and conclusion. 7. Express the main idea of each part. |