|
|
Вопросы ЮР (1). Классификация эвм. Области применения эвм. Обобщенная структура эвм
goto. Рекомендации к использованию.
Оператор перехода goto
Использование оператора безусловного перехода goto в практике программирования C++ настоятельно не рекомендуется, так как он затрудняет понимание программы и возможность их модификации. Формат оператора следующий: goto имя_метки; . . . имя_метки: оператор; Оператор goto передаёт управление на оператор, помеченный меткой имя_метки. Помеченный оператор должен находится в той же функции, что и оператор goto, а используемая метка должна быть уникальной, т.е. одно имя_метки не может быть использовано для разных операторов программы.
Причина, по которой следует избегать использования goto
Оператор goto дает возможность перейти к любой части программы, но делает программу сложной и запутанной.
В современном программировании оператор goto считается вредной конструкцией и плохой практикой программирования. Оператор goto можно заменить в большинстве программ на C++ с помощью операторов break и continue.
Условная функция
Условные конструкции направляют ход программы по одному из возможных путей в зависимости от условия.
Конструкция if
Конструкция if проверяет истинность условия, и, если оно истинно, выполняет блок инструкций.
В качестве условия использоваться условное выражение, которое возвращает true или false. Если условие возвращает true, то выполняются последующие инструкции, которые входят в блок if. Если условие возвращает false, то последующие инструкции не выполняются. Блок инструкций заключается в фигурные скобки.
Также мы можем использовать полную форму конструкции if, которая включает оператор else.
После оператора else мы можем определить набор инструкций, которые выполняются, если условие в операторе if возвращает false. То есть если условие истинно, выполняются инструкции после оператора if, а если это выражение ложно, то выполняются инструкции после оператора else.
Вычислительные комплексы и сети.
Вычислительная сеть (информационно-вычислительная сеть) – это совокупность узлов, соединенных с помощью каналов связи в единую систему.

Структура вычислительной сети
Узел – это любое устройство, непосредственно подключенное к передающей среде сети. Узлами могут быть не только ЭВМ, но и сетевые периферийные устройства, например, принтеры.
Каждый узел в сети имеет минимум два адреса: физический, используемый оборудованием, и логический, используемый пользователями и приложениями.
Узлы обмениваются сообщениями. Здесь сообщение – это целостная последовательность данных, передаваемых по сети.
Отдельные части сети называются сегментами.
Передающая среда сети (канал связи) определяет, как будут передаваться сообщения по сети. Примерами передающих сред являются кабельные, радио-, спутниковые каналы.
Вычислительные сети имеют следующие характеристики.
1. Производительность – это среднее количество запросов пользователей сети, исполняемых за единицу времени. Производительность зависит от времени реакции системы на запрос пользователя. Это время складывается из трех составляющих:
- времени передачи запроса от пользователя к узлу сети, ответственному за его исполнение;
- времени выполнения запроса в этом узле;
- времени передачи ответа на запрос пользователю.
2. Пропускная способность – это объем данных, передаваемых через сеть ее сегмент за единицу времени (трафик).
3. Надежность – это среднее время наработки на отказ.
4. Безопасность – это способность сети обеспечить защиту информации от несанкционированного доступа.
5. Масштабируемость – это возможность расширения сети без заметного снижения ее производительности.
6. Универсальность сети – это возможность подключения к сети разнообразного технического оборудования и программного обеспечения от разных производителей.
Вычислительные сети используются в следующих целях:
1) предоставление доступа к программам, оборудованию и данным для любого пользователя сети; эта цель называется совместным использованием ресурсов;
2) обеспечение высокой надежности хранения источников информации; хранение данных в нескольких местах позволяет избежать их потерю, в случае их удаления в одном из мест;
3) обработка данных, хранящихся в сети;
4) передача данных между удаленными друг от друга пользователями.
По виду технологии передачи вычислительные сети делятся на следующие типы:
- широковещательные сети обладают общим каналом связи, совместно используемым всеми узлами; сообщения передаются всем узлам; примером широковещательной сети является телевидение;
- последовательные сети, в которых сообщению необходимо пройти несколько узлов, чтобы добраться до узла назначения; сообщение передается только одному узлу; примером такой технологии передачи является электронная почта.
Небольшие сети обычно используют широковещательную передачу, тогда как в крупных сетях применяется передача от узла к узлу.
По размеру сети можно подразделить на следующие типы:
- локальные сети размещаются в одном здании или на территории одного предприятия; примером локальной сети является локальная сеть в учебном классе;
- региональные сети объединяют несколько предприятий или город; примером сетей такого типа является сеть кабельного телевидения;
- глобальные сети охватывают значительную территорию, часто целую страну или континент и представляют собой объединение сетей меньшего размера; примером глобальной сети является сеть Интернет.
По принципу построения сети делятся на следующие типы:
- одноранговые сети объединяют равноправные узлы; такие сети объединяют не более 10 узлов;
- сети на основе выделенного сервера имеют специальный узел – вычислительную машину (сервер), предназначенную для хранения основных данных сети и предоставления этих данных узлам (клиентам) по запросу.
Многомашинный вычислительный комплекс — это группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и выполняющих совместно единый информационно-вычислительный процесс. Такие комплексы являются локальными, так как ЭВМ, обычно, установлены в одном помещении и не требуют для взаимосвязи специального оборудования и каналов связи.
Многомашинный вычислительный комплекс отличается от компьютерной сети тремя параметрами:
• размерность. В состав многомашинного комплекса обычно входит 2-3 ЭВМ, расположенные, преимущественно, в одном помещении. А вычислительная сеть может состоять из десятков или сотен компьютеров, расположенных на значительном расстоянии друг от друга;
• разделение функций между ЭВМ. В многомашинном комплексе функции обработки, передачи данных и управления системой могут быть реализованы в одной ЭВМ, а в вычислительных сетях эти функции распределены между различными компьютерами;
• задача маршрутизации сообщений, которая возникает в многомашинном вычислительном комплексе, так как объединение в один комплекс разного вида техники и аппаратуры предъявляет повышенные требования со стороны каждого элемента. А в сети сообщение от одного компьютера к другому может быть передано по различным маршрутам в зависимости от состояния каналов связи, соединяющих компьютеры друг с другом.
Организация программ с разветвленной структурой. Примеры.
Операционные системы ЭВМ. Назначение и основные функции.
Операционная система (ОС) представляет собой комплекс системных и служебных программных средств. С одной стороны, она опирается на базовое ПО, входящее в его систему BIOS, с другой стороны, она сама является основой для ПО более высоких уровней – прикладных и большинства служебных приложений. Приложениями ОС принято называть программы, предназначенные для работы под управлением данной системы.
Основная функция всех ОС – посредническая. Она заключается в обеспечении нескольких видов взаимодействия:
- взаимодействие между пользователем с одной стороны и программным и аппаратным обеспечением ЭВМ с другой стороны, называемое интерфейсом пользователя;
- взаимодействие между программным и аппаратным обеспечением, называемое аппаратно-программным интерфейсом;
- взаимодействие между программным обеспечением разного уровня, называемое программным интерфейсом.
ОС появились и развивались в процессе совершенствования аппаратного обеспечения компьютеров, поэтому эти события исторически тесно связаны. Развитие компьютеров привело к появлению огромного количества различных ОС, из которых далеко не все широко известны. Для одной и той же аппаратной платформы существует несколько ОС. Различия между ними рассматриваются в двух категориях: внутренние и внешние. Внутренние различия характеризуются методами реализации основных функций. Внешние различия определяются наличием и доступностью приложений данной системы, необходимых для удовлетворения технических требований, предъявляемых к конкретному рабочему месту.
ОС можно подразделить по типу аппаратного обеспечения, на котором ОС работают.
Серверные ОС одновременно обслуживают множество пользователей и позволяют им делить между собой программно-аппаратные ресурсы сервера. Серверы также предоставляют возможность работы с печатающими устройствами, файлами или сетью Интернет. У Интернет-провайдеров обычно работают несколько серверов для того, чтобы поддерживать одновременный доступ к сети множества клиентов. На серверах хранятся страницы веб-сайтов и обрабатываются входящие запросы. Unix и специальная серверная версия ОС Windows являются примерами серверных ОС. Теперь для этой цели стала использоваться и ОС Linux.
Следующую категорию составляют ОС для персональных компьютеров. Их работа заключается в предоставлении удобного интерфейса для одного пользователя. Такие системы широко используются и повседневной работе. Основными ОС в этой категории являются Windows XP / Vista / 7, Apple MacOS и Linux.
Другим видом ОС являются системы реального времени. Главным параметром таких систем является время. Например, в системах управления производством компьютеры, работающие в режиме реального времени, собирают данные о промышленном процессе и используют их для управления оборудованием. Такие процессы должны удовлетворять жестким временным требованиям. Если по конвейеру передвигается автомобиль, то каждое действие должно быть осуществлено в строго определенный момент времени. Если сварочный робот сварит шов слишком рано или слишком поздно, то нанесет непоправимый вред изделию. Системы VxWorks и QNX являются ОС реального времени.
Встроенные ОС используются в смартфонах, карманных компьютерах и бытовой технике. Карманный компьютер – это маленький компьютер, помещающийся в кармане и выполняющий небольшой набор функции, например, телефонной книжки и блокнота. Смартфон – это мобильный телефон, обладающий многими возможностями карманного компьютера. Встроенные микропроцессорные системы, управляющие работой устройств бытовой техники, не считаются компьютерами, но обладают теми же характеристиками, что и системы реального времени, и при этом имеют малые размер и память и ограничения мощности, что выделяет их в отдельный класс. Примерами таких ОС являются Google Andrоid и Apple iOS.
Самые маленькие ОС работают на смарт-картах, представляющих собой устройство размером с кредитную карту и содержащих центральный процессор. На такие ОС накладываются очень жесткие ограничения по мощности процессора и памяти.
Некоторые из них могут управлять только одной операцией, например электронным платежом, но другие ОС выполняют более сложные функции.
Основными функциями ОС являются:
1) распределение ресурсов ЭВМ между процессами – выделение процессам ресурсов ЭВМ в зависимости от их приоритета;
2) поддержание файловой системы – организация хранения и поиска программ и данных на внешних носителях;
3) обеспечение интерфейса пользователя – прием и выполнение команд пользователя.
Циклический вычислительный процесс.
Экономическая эффективность применения ЭВМ различных классов.
Операторы цикла с предусловием while и с постусловием do while, назначение, принцип действия.
Обмен информацией между процессами на удаленных ЭВМ.
Оператор цикла for: структура оператора, блоки инициализации, проверки условия и модификации.
Структура вычислительных сетей. Локальные сети.
Вычислительные машины, объединенные в локальную сеть, физически могут располагаться различным образом. Однако порядок их подсоединения к сети определяется топологией – усредненной геометрической схемой соединений узлов сети.
Наиболее распространенными топологиями локальных сетей, в которых передающей средой является кабель, являются кольцо, шина, звезда.
Топология кольцо предусматривает соединение узлов сети замкнутым контуром и используется для построения сетей, занимающих сравнительно небольшое пространство. Выход одного узла сети соединяется с входом другого. Информация по кольцу передаются от узла к узлу в одном направлении. Каждый промежуточный узел ретранслирует посланное сообщение. Принимающий узел распознает и получает только адресованное ему послание.
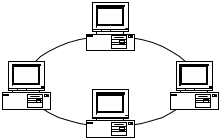
Топология кольцо
Последовательная организация обслуживания узлов сети снижает ее быстродействие, а выход из строя одного из узлов приводит к нарушению функционирования кольца.
Топология шина представляет собой последовательное соединение узлов между собой. Данные распространяются по шине в обе стороны. В каждый момент времени передачу может вести только один узел, поэтому производительность сети зависит только от количества узлов в сети. Сообщение поступает на все узлы, но принимает его только тот узел, которому оно адресовано. Узлы не перемещают сообщение, поэтому выход из строя одного узла не приводит к нарушению функционирования сети.
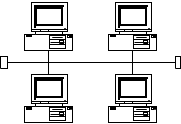
Топология шина
Топология звезда базируется на концепции центрального узла, через который вся информация ретранслирует, переключает, маршрутизирует (находит путь от источника к приемнику) информационные потоки в сети.
В качестве центрального узла выступает концентратор (хаб, hub). Концентраторы выполняются в виде отдельных устройств с 8, 16, 24 или 48 портами, к которым подключаются ЭВМ. При получении пакета в одном из портов концентратор широковещательно передает его на все остальные порты. Узлы анализируют адрес получателя пакета и, если он предназначен им, то получают его, иначе игнорируют его.
Концентраторы могут быть трех типов:
1) пассивные: только соединяющие сегменты сети;
2) активные: это пассивные концентраторы, усиливающие сигналы, увеличивая расстояние между узлами;
3) интеллектуальные: это активные концентраторы, выполняющие маршрутизацию.
Также центральным узлом сети может быть коммутатор (switch). В отличие от концентратора, это телекоммуникационное устройство пересылает принятый пакет не широковещательно на все порты, а адресату. Адресат определяется по адресу, содержащемуся в пакете. В результате такой передачи повышается общая пропускная способность сети.
Данная топология значительно упрощает взаимодействие узлов сети друг с другом. В то же время работоспособность локальной вычислительной сети зависит от центрального узла.
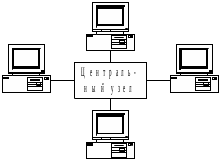
Топология звезда
При построении локальных сетей используются данные топологии или их сочетания.
Двоичное представление чисел в разрядной сетке.
Сетевые протоколы. Доменные имена.
Протоколы – это соглашение о формате и правилах передачи данных по сети. Протоколы обладают следующими свойствами:
- протоколы работают на разных уровнях модели OSI, поэтому функции протокола определяются уровнем, на котором он работает;
- несколько протоколов могут работать совместно, в этом случае они образуют стек или набор протоколов разных уровней модель OSI.
Передача данных по сети разбита на несколько шагов, каждому из которых соответствует протокол. Узел-отправитель выполняет следующие шаги:
- разбивает данные на пакеты;
- добавляет к пакетам служебную информацию: адрес получателя и информацию для проверки правильности и восстановления в случае возникновения ошибок при передаче;
- передает пакеты в сеть через сетевой адаптер.
Узел-получатель выполняет шаги в обратной последовательности:
- принимает пакеты из сети через сетевой адаптер;
- проверяет правильность передачи данных и удаляет служебную информацию из пакетов;
- объединяет пакеты в исходный блок данных.
Пример программ с циклической структурой
Базы данных. Типы баз данных.
Одной из задач информационных систем является хранение данных из определенной предметной области. Предметная область – это часть реального мира, объединяющая схожие или связанные понятия. Чтобы необходимые данные можно было легко найти и выдать пользователю в любой момент времени, данные о предметной области должны храниться структурировано.
База данных – совокупность связанных данных, организованным по определенному правилам, предусматривающим общие принципы описания, хранения и манипулирования независимо от прикладных программ.
По технологии решения задач, решаемых СУБД, БД подразделяют на два вида:
- централизованная БД хранится целиком на ВЗУ одной вычислительной системы; если система входит в состав сети, то возможен доступ к этой БД других систем;
- распределенная БД состоит из нескольких, иногда пересекающихся или дублирующих друг друга БД, хранящихся на ВЗУ разных узлов сети.
СУБД предоставляет доступ к данным БД двумя способами:
- локальный доступ предполагает, что СУБД обрабатывает БД, которая хранится на ВЗУ той же ЭВМ;
- удаленный доступ – это обращение к БД, которая хранится на одном из узлов сети; удаленный доступ может быть выполнен по технологии файл-сервер или клиент-сервер.
Классификация СУБД по типу модели данных:
Дореляционные
Инвертированные списки (файлы)
Иерархические
Сетевые
Реляционные
Постреляционные
Объектно-реляционные
Объектно-ориентированные
Многомерные
Прочие (NoSQL)
Сдвиг битов влево (<<) и вправо (>>), отрицание ( ).
Структура базы данных.
Одной из задач информационных систем является хранение данных из определенной предметной области. Предметная область – это часть реального мира, объединяющая схожие или связанные понятия. Чтобы необходимые данные можно было легко найти и выдать пользователю в любой момент времени, данные о предметной области должны храниться структурировано.
База данных – совокупность связанных данных, организованным по определенному правилам, предусматривающим общие принципы описания, хранения и манипулирования независимо от прикладных программ.
Состав СУБД:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти;
- процессор языка базы данных, обеспечивающий оптимизацию запросов и создания машинно-независимого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс;
- сервисные программы (внешние утилиты), обеспечивающие дополнительные возможности по обслуживанию информационной системы.
По технологии решения задач, решаемых СУБД, БД подразделяют на два вида:
- централизованная БД хранится целиком на ВЗУ одной вычислительной системы; если система входит в состав сети, то возможен доступ к этой БД других систем;
- распределенная БД состоит из нескольких, иногда пересекающихся или дублирующих друг друга БД, хранящихся на ВЗУ разных узлов сети.
СУБД предоставляет доступ к данным БД двумя способами:
- локальный доступ предполагает, что СУБД обрабатывает БД, которая хранится на ВЗУ той же ЭВМ;
- удаленный доступ – это обращение к БД, которая хранится на одном из узлов сети; удаленный доступ может быть выполнен по технологии файл-сервер или клиент-сервер.
Технология файл-сервер предполагает выделение одной из вычислительных систем, называемой сервером, для хранения БД. Все остальные компьютеры сети (клиенты) исполняют роль рабочих станций, которые копируют требуемую часть централизованной БД в свою память, где и происходит обработка.
Технология клиент-сервер предполагает, что сервер, выделенный для хранения централизованной БД, дополнительно производит обработку запросов клиентских рабочих станций. Клиент посылает запрос серверу. Сервер пересылает клиенту данные, являющиеся результатом поиска в БД по ее запросу.
Классификация СУБД по типу модели данных:
Дореляционные
Инвертированные списки (файлы)
Иерархические
Сетевые
Реляционные
Постреляционные
Объектно-реляционные
Объектно-ориентированные
Многомерные
Прочие (NoSQL)
Рассмотрим реляционную модель данных, в которой данные хранятся в виде двумерных таблиц.
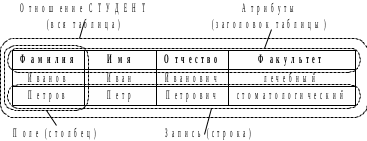
Структура данных реляционной модели данных
Таблицы обладают следующими свойствами:
- каждая ячейка таблицы является одним элементом данных;
- каждый столбец содержит данные одного типа (числа, текст и т. п.);
- каждый столбец имеет уникальное имя;
- таблицы организуются так, чтобы одинаковые строки отсутствовали;
- порядок следования строк и столбцов произвольный.
Каждая таблица представляет собой отношение, описываемое атрибутами:
СТУДЕНТ = (ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО, ФАКУЛЬТЕТ).
Для идентификации записей выделяют следующие виды ключей – полей, определяющих запись:
- первичный: однозначно определяет запись;
- вторичный: выполняет роль поисковых и группировочных признаков и позволяет найти несколько записей.
Ключ может быть простым, если он включает одно поле, или составным, если включает два и более полей. Если в отношении СТУДЕНТ нет однофамильцев, то первичным будет простой ключ – поле ФАМИЛИЯ. Иначе первичным будет составной ключ ФАМИЛИЯ + ИМЯ + ОТЧЕСТВО.
Первичный ключ должен обладать следующими свойствами:
- уникальность: не должно существовать двух или более записей, имеющих одинаковые значения полей, входящих в первичный ключ;
- не избыточность: первичный ключ не должен содержать поля, удаление которых из ключа не нарушит его уникальность.
Поразрядные операции И (&), ИЛИ (|), исключающее ИЛИ (^).
Системы управления базами данных.
Система управления базами данных (СУБД) – приложение, обеспечивающее создание, хранения, обновление и поиск информации в базах данных. СУБД осуществляют взаимодействие между базой данных и пользователями системы, а также между базой данных и прикладными программами, реализующими определенные функции обработки данных.
К основным функциям СУБД относятся:
- непосредственность управления данными во внешней и оперативной памяти;
- поддержание целостности данных и управление транзакциями;
- обеспечение безопасности данных;
- обеспечение параллельного доступа к данным нескольких пользователей.
Состав СУБД:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти;
- процессор языка базы данных, обеспечивающий оптимизацию запросов и создания машинно-независимого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс;
- сервисные программы (внешние утилиты), обеспечивающие дополнительные возможности по обслуживанию информационной системы.
По технологии решения задач, решаемых СУБД, БД подразделяют на два вида:
- централизованная БД хранится целиком на ВЗУ одной вычислительной системы; если система входит в состав сети, то возможен доступ к этой БД других систем;
- распределенная БД состоит из нескольких, иногда пересекающихся или дублирующих друг друга БД, хранящихся на ВЗУ разных узлов сети.
СУБД предоставляет доступ к данным БД двумя способами:
- локальный доступ предполагает, что СУБД обрабатывает БД, которая хранится на ВЗУ той же ЭВМ;
- удаленный доступ – это обращение к БД, которая хранится на одном из узлов сети; удаленный доступ может быть выполнен по технологии файл-сервер или клиент-сервер.
Технология файл-сервер предполагает выделение одной из вычислительных систем, называемой сервером, для хранения БД. Все остальные компьютеры сети (клиенты) исполняют роль рабочих станций, которые копируют требуемую часть централизованной БД в свою память, где и происходит обработка.
Технология клиент-сервер предполагает, что сервер, выделенный для хранения централизованной БД, дополнительно производит обработку запросов клиентских рабочих станций. Клиент посылает запрос серверу. Сервер пересылает клиенту данные, являющиеся результатом поиска в БД по ее запросу.
Примеры использования поразрядных операций.
Поразрядные логические операции
К этой группе операций относятся:
· - побитовое отрицание (побитовое НЕ) - унарная операция;
· & - побитовая конъюнкция (побитовое И) - бинарная операция;
· | - побитовая дизъюнкция (побитовое ИЛИ) - бинарная операция;
· ^ - побитовое исключающее ИЛИ - бинарная операция.
Операндами этих операций целочисленных типов данных. Результат также целочисленный.
Операция побитовое отрицание () осуществляет инвертирование всех байтов двоичного представления своего операнда. Например:
int a = 14, r;
r = a;
cout << r << endl; //На экран выведено-15
Иллюстрация:
Номер разряда: 31 30 … 8 7 6 5 4 3 2 1 0
Значение a: 0 0 … 0 0 0 0 0 1 1 1 0 = 14
Значение r = a: 1 1 … 1 1 1 1 1 0 0 0 1 = -15
Остальные операции выполняют соответствующую логическую операцию над каждой парой соответствующих разрядов первого и второго операндов, интерпретируя значения двоичных разрядов как логические значения (1 - true; 0 - false). Например:
int a = 14, b = 7, r;
r = a & b;
cout << r << endl; //На экран выведено6
r = a | b;
cout << r << endl; //На экран выведено15
r = a ^ b;
cout << r << endl; //На экран выведено9
Иллюстрация:
Номер разряда: 31 30 … 8 7 6 5 4 3 2 1 0
Значение a: 0 0 … 0 0 0 0 0 1 1 1 0 = 14
Значение b: 0 0 … 0 0 0 0 0 0 1 1 1 = 7
Операция: a & b
Значение r: 0 0 … 0 0 0 0 0 0 1 1 0 = 6
Операция: a | b
Значение r: 0 0 … 0 0 0 0 0 1 1 1 1 = 15
Операция: a ^ b
Значение r: 0 0 … 0 0 0 0 0 1 0 0 1 = 9
Использование побитовых операций
Как уже говорилось, побитовые операции используются для обработки отдельных двоичных разрядов памяти. Для манипулирования отдельным битом необходимо научиться делать следующее:
· определять значение заданного бита;
· устанавливать значение заданного бита в значение 0 или 1;
· инвертировать значение заданного бита.
Это можно сделать так:
unsigned a = 1234; // Целое значение, битами которого мы будем управлять
unsigned short n = 4;// Номер необходимого бита (от 0 до 31)
bool r; // Значение результата (0 или 1)
/* Узнаем, чему равен n-й бит (двоичный разряд) значения a. Результат поместим в переменную r */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение1
/* Установим n-й бит (двоичный разряд) значения aв0. Результат поместим в переменную а */
a = a & ( (1U << n))
cout << "Значение а равно " << a << endl; //значение1218
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение0
/* Возвращаем n-й бит (двоичный разряд) значения a в 1. Результат поместим в переменную а*/
a = a | (1U << n);
cout << "Значение а равно " << a << endl; //значение1234
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение1
/* Инвертируем n-й бит (двоичный разряд) значения a. Результат поместим в переменную а *
a = a ^ (1U << n);
cout << "Значение а равно " << a << endl; //значение1218
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение0
/* Еще раз инвертируем n-й бит (двоичный разряд) значения a. Результат поместим в переменную а */
a = a ^ (1U << n);
cout << "Значение а равно " << a << endl; //значение1234
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение1
Изменяя значение переменной n в диапазоне от 0 до 31 можно выполнить все эти действия над любым битом переменной a какое бы значение она не содержала.
Таким образом, для того, чтобы узнать, чему равен двоичный разряд с номером n в значении переменной a, мы воспользовались выражением
a & (1U << n).
Иллюстрация вычисления этого выражения:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
a & (1U << n): 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0 = 16
Результатом вычисления этого выражения является целое значение не равное 0. Операция присваивания этого значения логической переменной r автоматически преобразует целое значение 16 в логическое значение true (т.е. 1).
Если бы значение a имело бы разряд с номером 4 равным 0, то результатом вычисления этого выражения было бы значение 0. При выполнении операции присваивания это значение было бы преобразовано в логическое значение false (т.е. 0).
Для установки значения разряда с номером n в переменной a в значение 0 используется выражение
a & ( (1U << n)).
Иллюстрация вычисления этого выражения:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
(1U << n): 1 1 … 1 1 1 1 1 1 1 0 1 1 1 1
Значение a: 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
a & (1U << n): 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
Для установки значения разряда с номером n в переменной a в значение 1 используется выражение
a | (1U << n).
Иллюстрация вычисления этого выражения:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
a | (1U << n): 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
Для инвертирования значения разряда с номером n в переменной a используется выражение
a ^ (1U << n).
Иллюстрация вычисления этого выражения при a = 1218:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
a ^ (1U << n): 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
Но, если a = 1234, то:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
a ^ (1U << n): 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
Требования к базам данных. Реляционные модели данных.
Составление таблиц значений функций.
Основные функции СУБД.
Система управления базами данных (СУБД) – приложение, обеспечивающее создание, хранения, обновление и поиск информации в базах данных. СУБД осуществляют взаимодействие между базой данных и пользователями системы, а также между базой данных и прикладными программами, реализующими определенные функции обработки данных.
К основным функциям СУБД относятся:
- непосредственность управления данными во внешней и оперативной памяти;
- поддержание целостности данных и управление транзакциями;
- обеспечение безопасности данных;
- обеспечение параллельного доступа к данным нескольких пользователей.
Вычисление суммы бесконечного ряда с заданной погрешностью.
Характерным примером итерационных циклов является задача вычисления суммы бесконечного ряда:
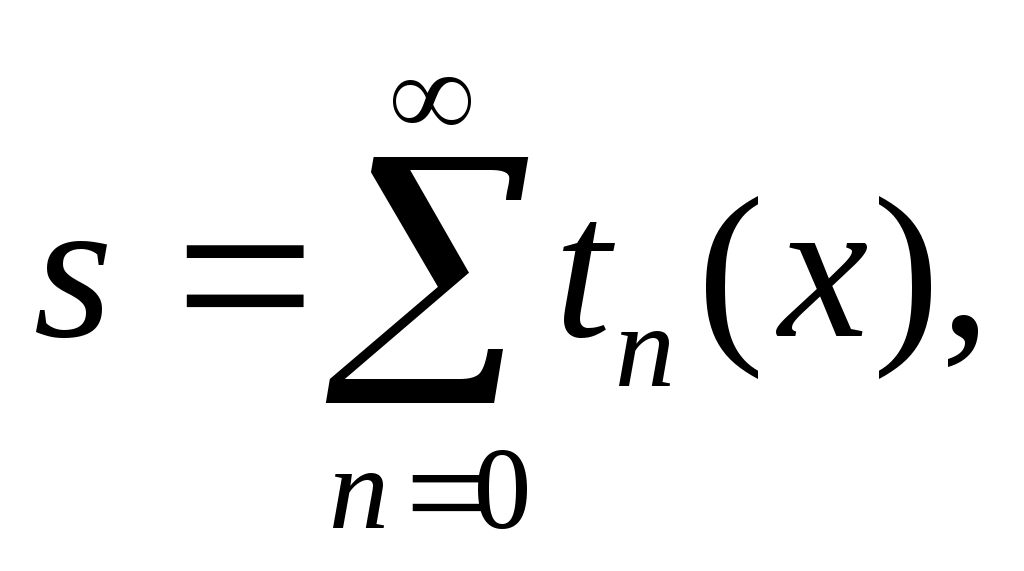
где tn(x) – слагаемое, зависящее от параметра x (в общем случае) и номера n. Вычисляемая последовательность
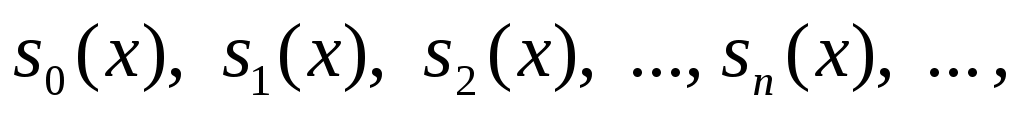
где 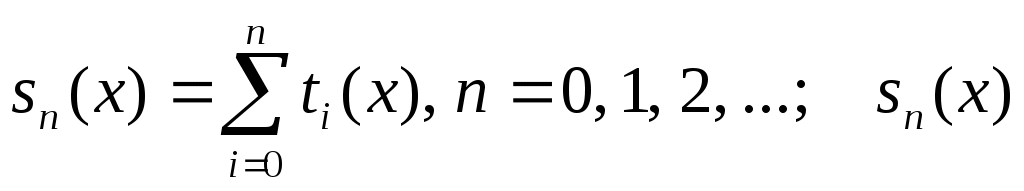 – частная сумма. – частная сумма.
Для контроля погрешности можно использовать последовательность
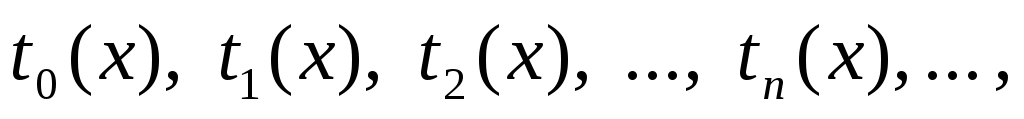
где tn(x) = sn(x) – sn-1(x) – слагаемые ряда n.
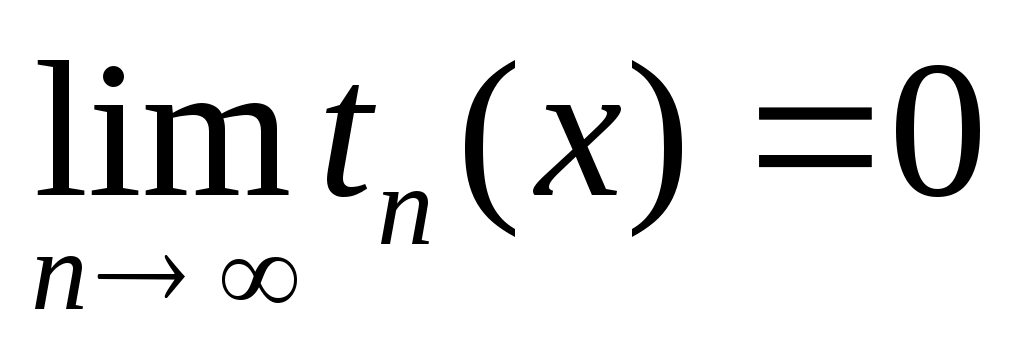 . .
Условие выхода из итерационного цикла (справедливо при знакопеременном ряде {tn(x)}):
| tn ( x ) | < .
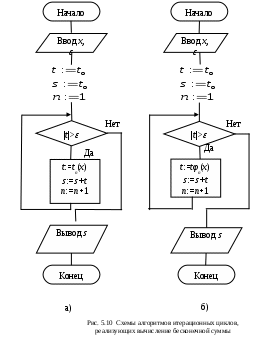
Алгоритм вычисления бесконечной суммы является модификацией одного из алгоритмов вычисления конечной суммы. Если применение рекуррентных формул нецелесообразно, то вычисления будут наиболее эффективными, если каждое слагаемое определять по общей формуле и полученные значения накапливать в некоторой переменной. Общий вид схемы алгоритма, реализующего вычисление бесконечной суммы с погрешностью с помощью цикла с предусловием, показан на рис. 5.10, а.
Если для вычисления слагаемых используются рекуррентные соотношения
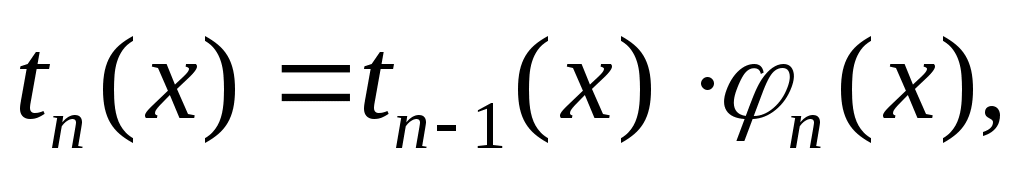
то общая схема итерационного алгоритма для вычисления бесконечной суммы показана на рис. 5.10, б.
Например, тригонометрическая функция sin(x) может быть представлена в виде бесконечной суммы

В данном случае
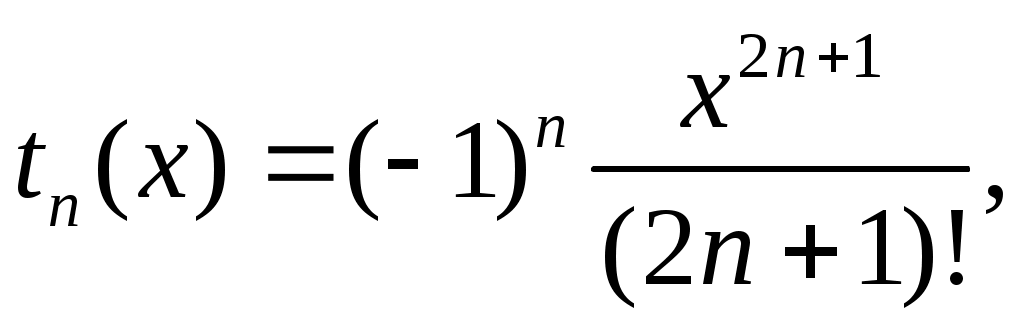
тогда
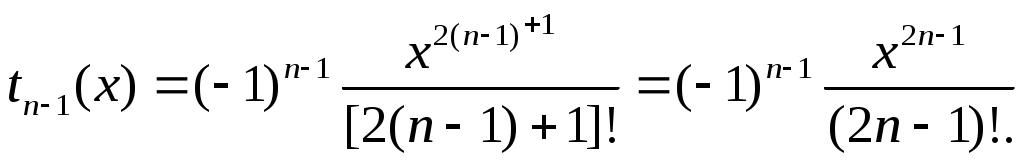
Теперь можно определить
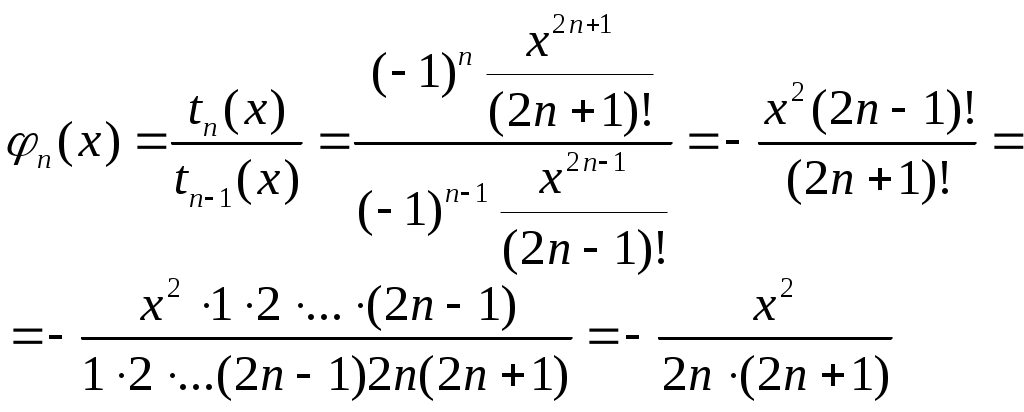
Начальное значение слагаемого находим по формуле
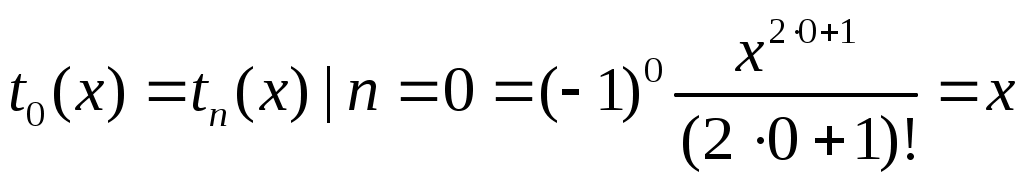 
Алфавит языка С, константы, переменные. Понятие типа данных, его связь с представлением данных в ЭВМ.
Множество символов языка C включает:
прописные буквы латинского алфавита;
строчные буквы латинского алфавита;
арабские цифры;
разделители: , . ; : ? ! ' " | / \ _ ^ ( ) { } [ ] < > # % & - = + *
Остальные символы могут быть использованы только в символьных строках, символьных константах и комментариях. Язык C++ различает большие и маленькие буквы, таким образом, name и Name – разные идентификаторы.
Литералы в языке C++ могут быть целые, вещественные, символьные и строковые.
Целые (можно испрользовать апостроф как разделитель групп разрядов):
десятичные: 10, 132, -32179, 2'147'483'647;
двоичные (предваряются символами «0b»): 0b11, 0b1010b, 0b1111'0011;
восьмеричные (предваряются символом «0»): 010, 0204, -076663;
шестнадцатеричные (предваряются символами «0х»): 0хА, 0x84, 0x7db3.
Вещественные: 15.75, 1.575e1, .75, -.125
Символьные: 'a', 'e', '.', '?', '2'.
Строковые: "строка".
Комментарий – это последовательность символов, которая игнорируется компилятором языка C++. Комментарий имеет следующий вид: /*<символы>*/. Комментарии могут занимать несколько строк, но не могут быть вложенными. Кроме того, часть строки, следующая за символами //, также рассматривается как комментарий.
Разумное использование комментариев (и согласованное употребление отступов) может сделать чтение и понимание программы более приятным занятием. При неправильном использовании комментариев читабельность программы может, напротив, серьёзно пострадать. Компилятор не понимает смысл комментариев, поэтому не существует способа проверить, что комментарий:
содержателен;
имеет какое-то отношение к программе;
не устарел.
Удачно подобранный и написанный набор комментариев является существенной частью хорошей программы. Написание «правильных» комментариев может оказаться не менее сложной задачей, чем написание самой программы.
На уровне библиотек/программ/функций комментарии отвечают на вопрос «ЧТО?»: «Что делают эти библиотеки/программы/функции?». Например: // Эта функция использует метод Ньютона для вычисления корня функции. Такие комментарии позволяют понять, что делает программа, без необходимости смотреть на исходный код.
Внутри библиотек/программ/функций комментарии отвечают на вопрос «КАК?»: «Как код выполняет задание?». Например: // Чтобы получить случайный элемент, мы делаем следующее: …
На уровне однострочного кода комментарии отвечают на вопрос «ПОЧЕМУ?»: «Почему код выполняет задание именно так, а не иначе?». Плохой комментарий на уровне операторов объясняет, что делает код. Если вы когда-нибудь писали код, который был настолько сложным, что нужен был комментарий, который бы объяснял, что он делает, то вам нужно было бы не писать комментарий, а переписывать этот код.
Имя
|
Размер
|
Представляемые значения
|
Диапазон
|
bool
|
1 байт
|
логические
|
false, true
|
(signed) char
|
1 байт
|
символы
целые числа
|
от –128 до 127
|
wchar_t
|
2 байта
|
символы Unicode
|
от 0 до 65535
|
(signed) short int
|
2 байта
|
целые числа
|
от -32768 до 32767
|
(signed) int
|
зависит от реализации
(в последних компиляторах обычно 4 байта)
|
целые числа
|
|
(signed) long int
|
4 байта
|
целые числа
|
от -2147483648 до 2147483647
|
(signed) long long int
(signed) __int64 (MS)
|
8 байт
|
целые числа
|
от –9,223,372,036,854,775,808 до 9,223,372,036,854,775,807
|
unsigned char
|
1 байт
|
символы
целые числа
|
от 0 до 255
|
unsigned short int
|
2 байта
|
целые числа
|
0 до 65535
|
unsigned int
|
зависит от реализации
(в последних компиляторах обычно 4 байта)
|
целые числа
|
|
unsigned long int
|
4 байта
|
целые числа
|
от 0 до 4294967295
|
(unsigned) long long int
(unsigned) __int64 (MS)
|
8 байт
|
целые числа
|
от 0 до 18,446,744,073,709,551,615
|
float
|
4 байта
|
вещественные числа
|
от 1.175494351e–38
до 3.402823466e+38
|
double
|
8 байт
|
вещественные числа
|
от 2.2250738585072014e–308
до 1.7976931348623158e+308
|
long double
|
зависит от реализации
|
вещественные числа
|
| |
|
|
 Скачать 0.7 Mb.
Скачать 0.7 Mb.