Подготовка к ревью на junior java dev. Книга Уорбэртон Функциональное программирование в массы java8
 Скачать 483.96 Kb. Скачать 483.96 Kb.
|

Можно ли заменить каждый анонимный класс выражением лямбда?Ответ - нет. Вы можете создать анонимный класс для не заключительных классов и интерфейсов. Не то же самое для лямбда-выражений. Они могут использоваться только там, где ожидается интерфейс SAM, т.е. Интерфейсы только с одним абстрактным методом (до Java 8 каждый метод интерфейса был абстрактным, но поскольку интерфейсы Java 8 могут также иметь стандартные и статические методы, которые не являются абстрактными, поскольку они имеют реализацию). Итак, какие анонимные классы можно заменить выражением лямбда?Только анонимные классы, которые являются реализациями интерфейса SAM (например, Runnable, ActionListener, Comparator, Predicate), могут быть заменены выражением лямбда. DefaultConsumer не может быть лямбда-мишенью, потому что это даже не интерфейс. А как насчет потребителя?Несмотря на то, что Consumer является интерфейсом, он не является интерфейсом SAM, потому что он содержит более одного абстрактного метода, t и лямбда-мишень.Расскажите про Comparator и Comparable? https://metanit.com/java/tutorial/5.6.php Что такое ленивая инициализация стрима? - Ленивая инициализация-это концепция отсрочки создания объекта до тех пор, пока объект не будет фактически впервые использован. При правильном использовании это может привести к значительному повышению производительности. Все промежуточные операции выполняются только тогда, когда есть терминальная операция. Две терминальные операции в одном выражении? - нет Что возвращают промежуточные операции над стримом? - Промежуточные операции возвращают трансформированный поток. Например, выше в примере метод filter принимал поток чисел и возвращал уже преобразованный поток, в котором только числа больше 0. ... Конечные или терминальные операции возвращают конкретный результат. Для чего нужны параллельные стримы? - Распараллеливание потоков позволяет задействовать несколько ядер процессора (если целевая машина многоядерная) и тем самым может повысить производительность и ускорить вычисления. В то же время говорить, что применение параллельных потоков на многоядерных машинах однозначно повысит производительность - не совсем корректно. В каждом конкретном случае надо проверять и тестировать. Чтобы сделать обычный последовательный поток параллельным, надо вызвать у объекта Stream метод parallel. Кроме того, можно также использовать метод parallelStream() интерфейса Collection для создания параллельного потока из коллекции. В то же время если рабочая машина не является многоядерной, то поток будет выполняться как последовательный. Какой аннотацией помечается функциональный интерфейс? - Аннотация @FunctionalInterface не является чем-то сверхсложным и важным, так как её предназначение — сообщить компилятору, что данный интерфейс функциональный и должен содержать не более одного метода. Если же в интерфейсе с данной аннотацией более одного не реализованного (абстрактного) метода, компилятор не пропустит данный интерфейс, так как будет воспринимать его как ошибочный код. Интерфейсы и без данной аннотации могут считаться функциональными и будут работать, а @FunctionalInterface является не более чем дополнительной страховкой. Где находятся функциональные интерфейсы? Что они принимают и что возвращают? - Многие функциональные интерфейсы, предоставляемые Java 8, находятся в пакете java. util. function (что возвращают и какие есть – в статьях выше) Какие есть способы инстанцировать функциональные интерфейсы? - создать экземпляр анонимного или именованного класса, реализующего интерфейс Function; воспользоваться ссылкой на метод; написать лямбда-выражение К каким переменным и как можно обращаться в теле лямбда-выражений? - Изнутри лямбда-выражения можно не только обращаться ко всем «видимым» переменным, но и вызывать те методы, к которым есть доступ. Чем является Stream в контексте Java? - Stream API — это новый способ работать со структурами данных в функциональном стиле. Stream (поток) API (описание способов, которыми одна компьютерная программа может взаимодействовать с другой программой) — это по своей сути поток данных. Сам термин "поток" довольно размыт в программировании в целом и в Java в частности. В каком пакете находится Stream? - Вся основная функциональность данного API сосредоточена в пакете java. util. stream. Чем Stream отличается от итератора? – порядок в обходе от итератора может быть задан и заранее определен. Стоимость (затраты мощностей процессора) доступа к элементам в стримах гораздо ниже Протокол Iterator принципиально менее эффективен. Для получения каждого элемента требуется вызов двух методов. Кроме того, поскольку итераторы должны быть устойчивы к таким вещам, как вызов next() без hasNext() или hasNext() несколько раз без next(), оба этих метода обычно должны выполнять некоторую защитную кодировку ( и, как правило, больше состояния и ветвления), что увеличивает неэффективность. Сравнение стримов с коллекцией? - Разница между коллекцией(Collection) данных и потоком(Stream) из новой JDK8 в том что коллекции позволяют работать с элементами по-отдельности, тогда как поток(Stream) не позволяет. Например, с использованием коллекций, вы можете добавлять элементы, удалять, и вставлять в середину. В каком случае нужно закрывать стрим? - Только потоки, источником которых является канал ввода-вывода, например Files.lines(Path, Charset) должны быть закрыты. Остальные реализуют AutoClosable Разница методов. list() и walk()? Что такое саплайер-поставщик? - Files.list() возвращает массив файлов в указанной директории Files.walk() возвращает поток файлов в указанной директории и субдиректориях. Интерфейс Supplier используется тогда, когда на вход не передаются значения, но необходимо вернуть результат. Как получить стрим диапазона чисел? - IntStream.range(0, 10) .collect(Collectors.toList()); В чем разница методов range и rangeClosed? Можно ли конкатенировать стримы? если да то каким методом? Можно ли получить пустой стрим? Первый этап работы со стримом? Какой второй этап работы со стримом? Что такое коллекторы? Что такое метод референс? Может ли лямбда-выражение быть в несколько строк? Может ли функциональный интерфейс содержать что-то кроме абстрактного метода? Может ли стрим использоваться повторно? Приведи пример терминальной и промежуточной операции над стримом? Stream Stream Stream Stream Stream Stream Stream Stream Stream Object[] toArray(): возвращает массив из элементов потока. Терминальная операция. boolean allMatch(Predicate predicate): возвращает true, если все элементы потока удовлетворяют условию в предикате. Терминальная операция boolean anyMatch(Predicate predicate): возвращает true, если хоть один элемент потока удовлетворяют условию в предикате. Терминальная операция boolean noneMatch(Predicate predicate): возвращает true, если ни один из элементов в потоке не удовлетворяет условию в предикате. Терминальная операция Optional Optional long count(): возвращает количество элементов в потоке. Терминальная операция. Optional Optional void forEach(Consumer action): для каждого элемента выполняется действие action. Терминальная операция PreProject - Работа с БД. JDBC и Hibernate: Вопросы для самопроверки: Полностью работа git через intllij idea: https://javarush.ru/groups/posts/2683-nachalo-rabotih-s-git-podrobnihy-gayd-dlja-novichkov https://javarush.ru/groups/posts/2818-podruzhim-git-s-intellij-idea - ознакомиться https://habr.com/ru/post/161009/ https://javarush.ru/groups/posts/2693-komandnaja-rabota-bez-putanicih-razbiraem-strategii-vetvlenija-v-gite https://www.youtube.com/watch?v=J29YZoLAZqA&ab_channel=SoftDev push - ctrl + shift + k — это команда для создания пуша изменений на удаленный репозиторий. Все коммиты, которые были созданы локально и еще не находятся на удаленном, будут предложены для пуша commit - ctrl + k — сделать коммит/посмотреть все изменения, которые есть на данный момент. Сюда входят и untracked, и modified файлы Обновить проект (update) - pull - ctrl + t — получить последние изменения с удаленного репозитория / merge branches(ветки) - Git reset - alt + ctrl + z — откатить в конкретном файле изменения до состояния последнего созданного коммита в локальном репозитории. Если в левом верхнем углу выделить весь проект, то можно будет откатить изменения всех файлов. Что такое Maven? Для чего он нужен? Как добавлять в проект библиотеки без него? https://jsehelper.blogspot.com/2016/05/maven-1.html - 2 части, читать внимательно https://www.youtube.com/watch?v=FIs-vN3hcUE&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Java Если Вы не используете систему сборки (Maven, etc), качаете JAR файл: parboiled-java-1.1.4 потом его зависимости: asm-all-4.1 parboiled-core-1.1.4 В Intellj Idea открываете Project Settings и в вкладке Libraries добавляете эти JAR файлы к проекту. Что такое JDBC? Какие классы/интерфейсы относятся к JDBC? Для чего нужен DriverManager? Какие преимущества в использовании PreparedStatement над Statement? Какие существуют различные типы JDBC ResultSet? JDBC (англ. Java DataBase Connectivity — соединение с базами данных на Java) — платформенно независимый промышленный стандарт взаимодействия Java-приложений с различными СУБД (Система управления базами данных), реализованный в виде пакета java.sql, входящего в состав Java SE. JDBC основан на концепции так называемых драйверов, позволяющих получать соединение с базой данных по специально описанному URL. Драйверы могут загружаться динамически (во время работы программы). Загрузившись, драйвер сам регистрирует себя и вызывается автоматически, когда программа требует URL, содержащий протокол, за который драйвер отвечает. https://russianblogs.com/article/95231107553/ - посмотри таблицу только вначале, чтобы понимать концепцию, она заключается в использование драйверов на любые базы данных https://proselyte.net/tutorials/jdbc/introduction/ - прочитать все 14 глав справа о том, что это такое и зачем используется 4. Какие различия между execute, executeQuery, executeUpdate? https://metanit.com/java/database/2.3.php Существует несколько способов выполнять SQL-запросы в зависимости от типа этого запроса. Для этого у интерфейса Statement существует три различных метода: executeQuery(), executeUpdate(), а так же execute(). Рассмотрим их отдельно. executeQuery() необходим для запросов, результатом которых является один единственный набор значений, таких как у запросов SELECT. Возвращает ResultSet, который не может быть null даже если у результата запроса не было найдено значений. execute() используется, когда операторы SQL возвращают более одного набора данных, более одного счетчика обновлений или и то, и другое. Метод возвращает true, если результатом является ResultSet, как у запроса SELECT. Вернет false, если ResultSet отсутствует, например, при запросах вида Insert, Update. С помощью методов getResultSet() мы можем получить ResultSet, а getUpdateCount() — количество обновленных записей. executeUpdate() используется для выполнения операторов INSERT, UPDATE или DELETE, а также для операторов DDL (Data Definition Language — язык определения данных), например, CREATE TABLE и DROP TABLE. Результатом оператора INSERT, UPDATE, или DELETE является модификация одной или более колонок в нуле или более строках таблицы. Метод executeUpdate() возвращает целое число, показывающее, сколько строк было модифицировано. Для выражений типа CREATE TABLE и DROP TABLE, которые не оперируют над строками, возвращаемое методом executeUpdate() значение всегда равно нулю. Все методы выполнения SQL-запросов закрывают предыдущий набор результатов (result set) у данного объекта Statement. Это означает, что перед тем как выполнять следующий запрос над тем же объектом Statement, надо завершить обработку результатов предыдущего (ResultSet). 5. Как установить NULL значения в JDBC PreparedStatement?Используя метод setNull() для установки null переменной в качестве параметра. Этот метод принимает индекс и SQL тип в качестве аргументов: s.setNull(10, java.sql.Types.INTEGER); 6. Как используется метод getGeneratedKeys() в Statement?Если в таблице используется автоматическая генерация ключей, то для их получения используется метод Statement getGeneratedKeys(), который вернет сгенерированный ключ. Возвращает ResultSet. 7. Какие преимущества в использовании PreparedStatement над Statement?PreparedStatement позволяет предотвратить атаки типа SQL injection, т.к. он автоматически экранирует специальные символы. PreparedStatement позволяет использовать динамические запросы с внедрением параметров. PreparedStatement быстрее Statement. Это особенно заметно при частом использовании PreparedStatement или при использовании для вызова группы запросов. PreparedStatement позволяет писать объектно ориентированный код с использованием сеттеров\геттеров. В то время при использовании Statement необходимо использовать конкатенацию строк для создания запроса. Для больших запросов конкатенация выглядит, как минимум, большой, а также несет в себе большой риск ошибки в запросе. 8. Что такое sql-injection? https://www.youtube.com/watch?v=Y2sRuCUpJ78&ab_channel=alishev 9. Рассказать про паттерн DAO.Для чего нужен DAO Java? https://www.youtube.com/watch?v=cNHr5lvN-Hw&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Javahttps://www.youtube.com/watch?v=D58pIymCew4&ab_channel=alishevДля чего нужен DAO Java? 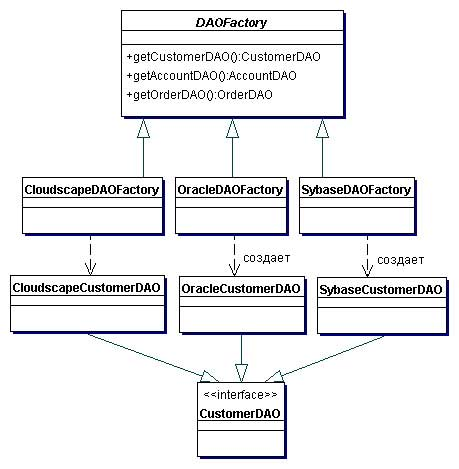 Используйте Data Access Object (DAO) для абстрагирования и инкапсулирования доступа к источнику данных. DAO управляет соединением с источником данных для получения и записи данных. DAO реализует необходимый для работы с источником данных механизм доступа. 10. Что такое JPA?JPA (Java Persistence API) это спецификация Java EE и Java SE, описывающая систему управления сохранением java объектов в таблицы реляционных баз данных в удобном виде. Сама Java не содержит реализации JPA, однако есть существует много реализаций данной спецификации от разных компаний (открытых и нет). Это не единственный способ сохранения java объектов в базы данных (ORM систем), но один из самых популярных в Java мире. https://java-master.com/%D1%80%D0%B0%D0%B7%D0%BD%D0%B8%D1%86%D0%B0-%D0%BC%D0%B5%D0%B6%D0%B4%D1%83-jdbc-jpa-hibernate-spring-data-jpa/ 11. Что такое ORM? ORM (Object-Relational Mapping, объектно-реляционное отображение) — технология благодаря этой технологии разработчики могут использовать язык программирования, с которым им удобно работать с базой данных, вместо написания операторов SQL или хранимых процедур. Это может значительно ускорить разработку приложений, особенно на начальном этапе. ORM также позволяет переключать приложение между различными реляционными базами данных. Например, приложение может быть переключено с MySQL на PostgreSQL с минимальными изменениями кода. https://www.youtube.com/watch?v=kjBBPkjrsJY&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Java 12. Что такое Hibernate? В чем разница между JPA и Hibernate? Как связаны все эти понятия? Это библиотека, которая предназначена для задач объектно-реляционного отображения. Примерно такое описание будет в википедии. Если простыми словами — hibernate позволяет разработчику работать с базой данных не напрямую, как мы это делали с помощью библиотеки JDBC в статье Работа с базой данных, а с помощью представления таблиц баз данных в виде классов java. JPA — спецификация, которая дает возможность сохранять в удобном виде Java-объекты в базе данных. Hibernate — это одна из самых популярных реализаций этой спецификации. Вот такая вот драма. Данные термины даны только в ознакомительных целях так как очень часто запутывают и пугают начинающих разработчиков. 13. Какие классы/интерфейсы относятся к JPA/Hibernate? https://easyjava.ru/data/jpa/ - читтать все статьи (JPA) https://proselyte.net/tutorials/hibernate-tutorial/introduction/ - читать все статьи (Hibernate) Hibernate интерфейсы и описание: https://javarush.ru/groups/posts/1502-voprosih-na-sobesedovanie-hibernate 14. Основные аннотации Hibernate, рассказать. https://proselyte.net/tutorials/hibernate-tutorial/annotations/ - с примерами 15. Чем HQL отличается от SQL? Отличие между HQL и SQL состоит в том, что SQL работает с таблицами в базе данных (далее – БД) и их столбацами, а HQL – с сохраняемыми объектами (Persistent Objects) и их полями (аттрибутами класса). Hibernate трнаслирует HQL – запросы в понятные для БД SQL – запросы, которые и выполняют необходимые нам действия в БД. HQL (Hibernate Query Language) – это объекто-ориентированный язык запросов, который очень похож на SQL. Главное различие языков HQL и SQL связано с тем, что SQL формирует запросы из наименований таблиц в базе данных и их столбцов, а HQL работает с сущностями (классами) и их полями (аттрибутами класса). примеры SQL/HQL: (всё смотреть внимательно) https://easyjava.ru/data/hibernate/hibernate-query-language/ - примеры SQL/HQL https://www.youtube.com/watch?v=fgGSOoLT6BY&ab_channel=%D0%98%D0%B7%D1%83%D1%87%D0%B0%D0%B5%D0%BCJava https://www.youtube.com/watch?v=qN-luGIbz2I&ab_channel=%D0%98%D0%B7%D1%83%D1%87%D0%B0%D0%B5%D0%BCJava https://www.youtube.com/watch?v=4ivjZEW5RcE&ab_channel=%D0%98%D0%B7%D1%83%D1%87%D0%B0%D0%B5%D0%BCJava 16. Что такое Query? Как передать в объект Query параметры? Query - Интерфейс, используемый для управления выполнением запроса. Integer id = 1; Query query = session.createQuery("from Employee e where e.idEmployee=:id"); query.setParameter("id", id); 17. Какие можно устанавливать параметры в hbm2ddl, рассказать про каждый из них. https://russianblogs.com/article/8493483296/ 18. Требования JPA к Entity-классам? Не менее пяти. 1) Entity класс должен быть отмечен аннотацией Entity или описан в XML файле конфигурации JPA, 2) Entity класс должен содержать public или protected конструктор без аргументов (он также может иметь конструкторы с аргументами), 3) Entity класс должен быть классом верхнего уровня (top-level class), 4) Entity класс не может быть enum или интерфейсом, 5) Entity класс не может быть финальным классом (final class), 6) Entity класс не может содержать финальные поля или методы, если они участвуют в маппинге (persistent final methods or persistent final instance variables), 7) Если объект Entity класса будет передаваться по значению как отдельный объект (detached object), например через удаленный интерфейс (through a remote interface), он так же должен реализовывать Serializable интерфейс, 8) Поля Entity класс должны быть напрямую доступны только методам самого Entity класса и не должны быть напрямую доступны другим классам, использующим этот Entity. Такие классы должны обращаться только к методам (getter/setter методам или другим методам бизнес-логики в Entity классе), 9) Enity класс должен содержать первичный ключ, то есть атрибут или группу атрибутов которые уникально определяют запись этого Enity класса в базе данных 19. Жизненный цикл Entity в Hibernate? Рассказать. https://easyjava.ru/data/jpa/jpa-entitymanager-upravlyaem-sushhnostyami/ У Entity объекта существует четыре статуса жизненного цикла: new, managed, detached, или removed. Их описание 1) new — объект создан, но при этом ещё не имеет сгенерированных первичных ключей и пока ещё не сохранен в базе данных (это простой обычный Java объект) 2) managed — объект создан, управляется JPA, имеет сгенерированные первичные ключи (это уже Java объект под управлением Hibernate например, т.е. можно добавлять в таблицу, удалить и т.д.) 3) detached — объект был создан, но не управляется (или больше не управляется) JPA, 4) removed — объект создан, управляется JPA, но будет удален после commit'a транзакции. 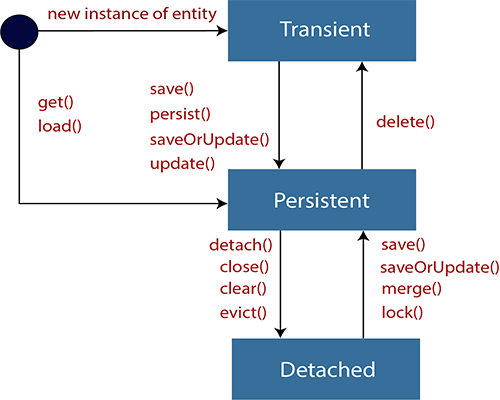 https://www.youtube.com/watch?v=ZLeTFBvegfY&ab_channel=Telusko 20. Транзакция, что это, для чего она нужна, какие виды и проблемы они решают (сложно) – Транзакция — это набор операций по работе с базой данных (БД), объединенных в одну атомарную пачку. Транзакционные базы данных (базы, работающие через транзакции) выполняют требования ACID, которые обеспечивают безопасность данных. В том числе финансовых данных =) Поэтому разработчики их и выбирают. https://www.youtube.com/watch?v=NUfMe40y0BY&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Java https://www.youtube.com/watch?v=5Z2iFX3OeTo&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Java https://java-online.ru/jdbc-transaction.xhtml Транзакция — это набор операций по работе с базой данных (БД), объединенных в одну атомарную пачку. Транзакционные базы данных (базы, работающие через транзакции) выполняют требования ACID, которые обеспечивают безопасность данных. В том числе финансовых данных =) Поэтому разработчики их и выбирают. 21. Разобраться в чем разница между реляционной системой и ORM – ORM - это техника (в абстрактном смысле) отображения классов и объектов в реляционные таблицы. Например, без ORM, если вы выполните SQL-запрос, вы получите набор результатов, содержащий строки таблицы и внутри этих столбцов. Формат набора результатов всегда один и тот же, независимо от того, запрашиваете ли вы автомобили или персонал. С помощью ORM ваша программа получает экземпляры класса Car или Person, готовые к использованию. Помимо маппинга сущностей (связывания классов java и базы данных), также у реляционных баз низкий уровень абстракции, мы не можем читать больше 1 драйвера, у нас есть интерфейс-хранилище" в орм, который поддерживает различные механизмы сохранения данных (не только в базы данных). ORM помогает абстрагироваться от понятия базы данных, мы просто работаем с объектами, а как они там пишутся в базу и какую уже не наша проблема http://internetka.in.ua/orm-intro/ 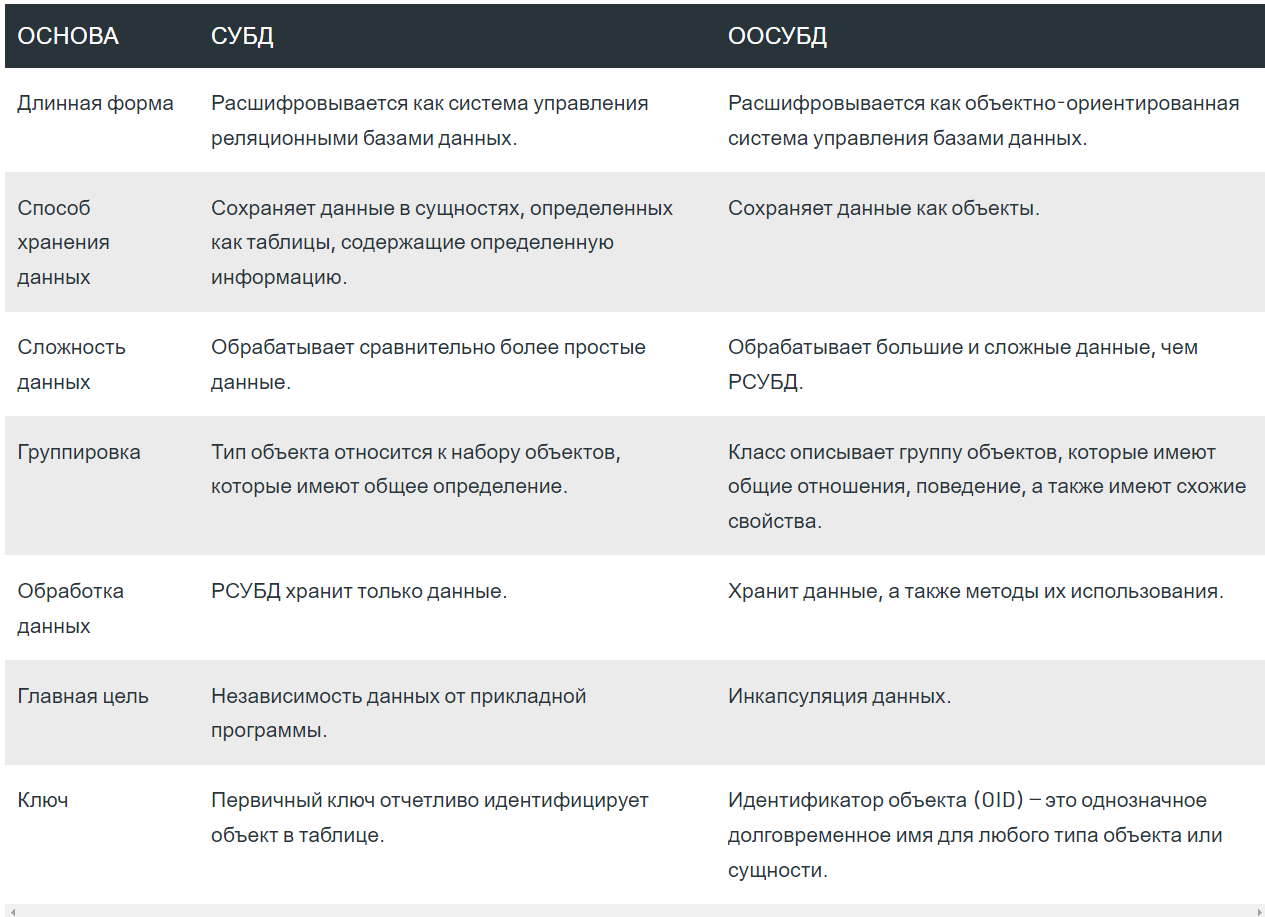 22. Виды PK (primary key)? Как работает генерация PK (primary key) in Hibernate? https://easyjava.ru/data/hibernate/pervichnye-klyuchi-v-hibernate/ 23. 3-ёх слонйная или n-слойная архитектура что это? https://www.youtube.com/watch?v=Usv6zV3w4uY&ab_channel=SergeyNemchinskiy https://qastart.by/class-2/60-klient-servernaya-arkhitektura https://zametkinapolyah.ru/servera-i-protokoly/o-modeli-vzaimodejstviya-klient-server-prostymi-slovami-arxitektura-klient-server-s-primerami.html PreProject - ORM (Hibernate) и MVC 2 блок: 1. Что такое бин? Бин (bean) — это самый обычный объект. Разница лишь в том, что бинами принято называть те объекты, которые управляются Spring-ом и живут внутри его DI (Dependency Injection)-контейнера. Бином является почти все в Spring — сервисы, контроллеры, репозитории, по сути все приложение состоит из набора бинов. 2. Виды бинов? https://www.youtube.com/watch?v=IcwWPjeBpFU&ab_channel=alishev https://proselyte.net/tutorials/spring-tutorial-full-version/bean-scope/ 3. Чем бин отличается от POJO-класса? Все JavaBeans - это POJO, но не все POJO - это JavaBeans. JavaBean: класс JavaBean должен реализовывать либо Serializable, либо Externalizable; класс JavaBean должен иметь открытый конструктор no-arg (без аргументов); все свойства JavaBean должны иметь общедоступные методы setter и getter (в зависимости от ситуации); все переменные экземпляра JavaBean должны быть private Pojo - Обычный объект Java Класс pojo - «старый добрый Java-объект», простой Java-объект, не унаследованный от какого-то специфического объекта и не реализующий никаких служебных интерфейсов сверх тех, которые нужны для бизнес-модели. 4. Что такое Inversion of Control и как Spring реализует этот принцип? Инверсия контроля (inversion of control, IoC) – принцип проектирования, по которому контроль над потоком управления передается фреймворку. Управляющий и прикладной код разделяются. Inversion of Control (IoC), также известное как Dependency Injection (DI), является процессом, согласно которому объекты сами определяют свои зависимости, т.е. объекты, с которыми они работают, через аргументы конструктора/фабричного метода или свойства, которые были установлены или возвращены фабричным методом. https://www.youtube.com/watch?v=Ns0IxBXDbWw&ab_channel=alishev 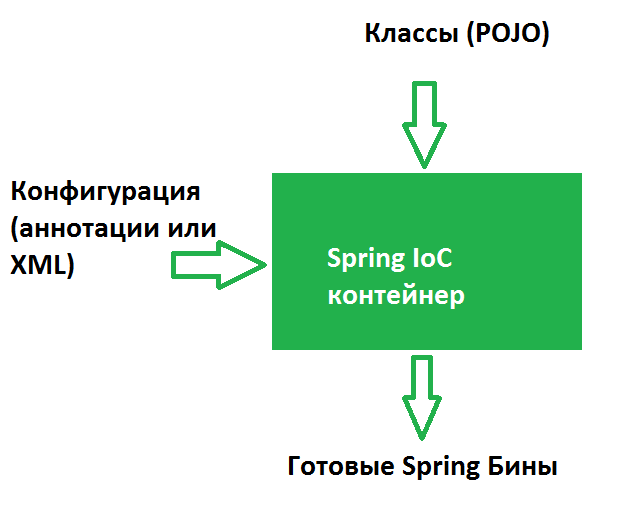 В общем на вход контейнер Spring принимает: Наши обычные классы (которые впоследствии будут бинами). Конфигурацию (неважно как именно ее задавать – либо в специальном файле XML, либо с помощью специальных аннотаций). А на выходе он производит объекты – бины. То есть экземпляры классов, созданные в соответствии с конфигурацией и внедренные куда нужно (в другие бины). После этого никакие операторы new нам не понадобятся, мы будем работать в классе-бине с его полями-бинами так, будто они уже инициированы. Конечно, не со всеми полями, а только с теми, которые сконфигурированы как бины. Остальные инициализируются как обычно, в том числе с помощью оператора new. 5. Для чего существует такое количество ApplicationContext? https://otus.ru/nest/post/529/ 6. Как можно связать бины? https://www.youtube.com/watch?v=KvyD2Vg4b1Q&ab_channel=alishev https://www.youtube.com/watch?v=MVbBLoZrT2A Через приватное поле, через сеттер, через конструктор. Можно связывать или через Java код или через XML-конфигурацию 7. Что такое Dependency Injection? Внедрение зависимостей (Dependency Injection, DI) – одна из реализаций IoC. При взаимодействии с другими модулями, программа оперирует высокоуровневыми абстракциями, тогда как конкретная её реализация поставляется фреймворком. Стандартная реализация DI – фреймворк инстанциирует все сервисы, и складывает их в IoC-контейнер. При этом специальная сущность, Service Locator, занимается поиском соответствия реализаций абстракциям и их внедрением. https://www.youtube.com/watch?v=MjnVZgMnTT0&ab_channel=alishev https://www.youtube.com/watch?v=dBxRmUH3Af8&ab_channel=alishev Внедрение зависимости — это и есть инициализация полей бинов другими бинами (зависимостями). 8. Какие бины будут использоваться для настройки приложения? Bean Configuration Читать: https://proselyte.net/tutorials/spring-tutorial-full-version/introduction/ Смотреть: https://www.youtube.com/watch?v=pDTzRsuGrDU https://www.youtube.com/watch?v=pDTzRsuGrDU&ab_channel=alishev https://www.youtube.com/watch?v=IcwWPjeBpFU Чем контроллер отличается от сервлета? Spring @Controller это надстройка над Servlet-ами. Spring устанавливает свой Servlet, который работает для всех url и перенаправляет запрос к конкретному контролёру. Spring предоставляет DispatcherServlet, чтобы гарантировать, что входящий запрос будет отправлен вашим контроллерам. Паттерн Front Controller используется для обеспечения централизованного механизма обработки запросов, так что все запросы обрабатываются одним обработчиком. Этот обработчик может выполнить аутентификацию, авторизацию, регистрацию или отслеживание запроса, а затем передать запрос соответствующему контроллеру. https://www.youtube.com/watch?v=g--XIu4p7Yc&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Java – паттерн FrontCtroller, по которому написан условно ДиспатчерСервлет. Т.е. это единый обработчик запросов, а контроллеры их выполняют. 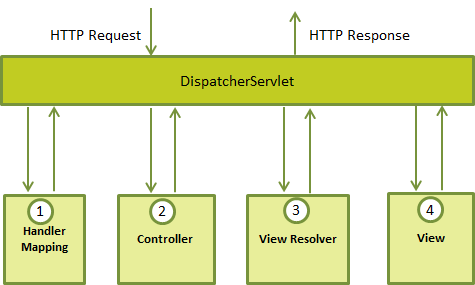 В чём отличие артефакта war от war exploded? объясняется тут: https://www.youtube.com/watch?v=25HcpCHgQ70&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Java – что такое WAR файл (запакованный архив) War-Exploded (разобранный - распакованный) – распакованный архив в разобранном виде означает, что вместо развертывания WAR/EARфайла на сервере приложений для тестирования приложения вы указываете серверу приложений папку , содержащую разархивированное (в разобранном виде) содержимое того, что будет внутри файла WAR/EAR. Это ускоряет разработку, так как большинство серверов приложений поддерживают горячее развертывание , где вы можете изменить код/JSP и т. д., и эти изменения будут отражены почти сразу в работающем приложении. Разница между аннотациями @Component, @Repository и @Service? https://russianblogs.com/article/6456830225/ https://itsobes.ru/JavaSobes/kakie-otlichiia-mezhdu-component-service-repository-i-controller/ |