Подготовка к ревью на junior java dev. Книга Уорбэртон Функциональное программирование в массы java8
 Скачать 483.96 Kb. Скачать 483.96 Kb.
|

|
| add(Object o) | Добавление элемента в коллекцию, если он отсутствует. Возвращает true, если элемент добавлен. |
| addAll(Collection c) | Добавление элементов коллекции, если они отсутствуют. |
| clear() | Очистка коллекции. |
| contains(Object o) | Проверка присутствия элемента в наборе. Возвращает true, если элемент найден. |
| containsAll(Collection c) | Проверка присутсвия коллекции в наборе. Возвращает true, если все элементы содержатся в наборе. |
| equals(Object o) | Проверка на равенство. |
| hashCode() | Получение hashCode набора. |
| isEmpty() | Проверка наличия элементов. Возвращает true если в коллекции нет ни одного элемента. |
| iterator() | Функция получения итератора коллекции. |
| remove(Object o) | Удаление элемента из набора. |
| removeAll(Collection c) | Удаление из набора всех элементов переданной коллекции. |
| retainAll(Collection c) | Удаление элементов, не принадлежащих переданной коллекции. |
| size() | Количество элементов коллекции |
| toArray() | Преобразование набора в массив элементов. |
| toArray(T[] a) | Преобразование набора в массив элементов. В отличии от предыдущего метода, который возвращает массив объектов типа Object, данный метод возвращает массив объектов типа, переданного в параметре. |
Как работает HashSet? Почему в HashSet вместо value не null а new Object?
Класс HashSet реализует интерфейс Set, основан на хэш-таблице, а также поддерживается с помощью экземпляра HashMap. В HashSet элементы не упорядочены, нет никаких гарантий, что элементы будут в том же порядке спустя какое-то время. Операции добавления, удаления и поиска будут выполняться за константное время при условии, что хэш-функция правильно распределяет элементы по «корзинам», о чем будет рассказано далее.
Т.к. класс реализует интерфейс Set, он может хранить только уникальные значения;
Может хранить NULL – значения;
Порядок добавления элементов вычисляется с помощью хэш-кода;
HashSet также реализует интерфейсы Serializable и Cloneable.
Хеш используется для быстрого поиска нужного объекта. Согласитесь, что быстрее сравнить два целочисленных значения (особенно, если они еще и как-то отсортированы), чем сравнивать все поля объекта. Но т.к. разные объекты могут дать один и тот же хеш, то при нахождении объекта с нужным хешем затем еще и проводится проверка на равенство этих объектов.
HashSet хранит new Object(), потому что в контракте указывается метод remove() который возвращает true, если указанный объект существовал и был удален. Для этого он использует обёртку, HashMap#remove() который возвращает удаленное значение. Если бы вы сохранили null вместо объекта, то вызов HashMap#remove() вернул бы бы null, что было бы неотличимо от результата попытки удалить несуществующий объект, и контракт HashSet.remove() не мог бы быть выполнен.
Как работает HashMap? Расскажите подробно, как работает метод put? Что происходит при коллизии? Как работает метод get в HashMap? Метод put в HashMap? Почему Map не входит в Collection? Может ли null быть ключём в HashMap? Как расширяется HashMap? Как обойти HashMap через for-each?
http://opensourceforgeeks.blogspot.com/2015/02/understanding-how-hashmap-and-hashset.html
https://javarush.ru/groups/posts/2496-podrobnihy-razbor-klassa-hashmap
https://www.youtube.com/watch?v=kk_9md24Ttk
Что такое бинарное дерево? Условия перестраивания HashMap в красно-чёрное дерево? https://youtu.be/HBMlhZAOhoI
https://youtu.be/n7Y2karbxF4
https://www.cs.usfca.edu/galles/visualization/RedBlack.html
Как работает метод contains в ArrayList, LinkedList, HashSet?
В чём разница между Iterable и Iterator?
listIterator - что это, в чём отличие от обычного?
Что такое даймонд оператор? Что такое raw type? К чему приводит использование raw type? Стирание типов? Что такое стирание и сырые типы? - Основная цель diamoind оператора упростить использование универсальных шаблонов при создании объекта . Это позволяет избежать непроверенных предупреждений в программе и делает программу более читаемой.
Raw Types (сырые типы) – Это имя универсального класса или интерфейса без каких-либо аргументов типа. их нужно избегать. Пример сырого типа List <> list = new ArrayList<>; Пример нормального типа List
Стирание типов - во время компиляции компилятор имеет полную информацию о типе, но эта информация обычно намеренно отбрасывается при создании байтового кода в процессе, известном как стирание типов . Это делается таким образом из-за проблем совместимости: целью разработчиков языка было обеспечение полной совместимости исходного кода и полной совместимости байтового кода между версиями платформы. Если бы он был реализован по-другому, вам пришлось бы перекомпилировать устаревшие приложения при переходе на более новые версии платформы.
Параметр vs Аргумент. (в дженериках)?
Параметр – это тип данных, которыми оперируют классы, интерфейсы указанные в дженериках
Null в TreeSet?
Что было до дженериков?
Если поле типизировано дженериком как в байт коде будет представлен этот тип?
Зачем в итераторе метод remove?
Какой механизм обеспечивает обратную совместимость сырых типов и дженериков?
Какие структуры данных вы знаете?
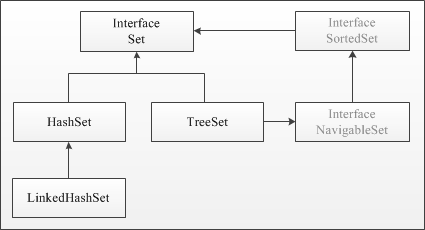
Расскажи про иерархию коллекций?
Почему последняя строчка не скомпилируется? List
- arrayList = new ArrayList
Скорость ставки элемента в начало середину и конец у ArrayList vs LinkedList?
На чём основаны основные реализации коллекций. Например, ArrayList построен на Object[ ]?
В чем отличие в записях в параметре метода: (Collection collection) и ((Collection collection)?
Как работает метод contains в ArrayList, LinkedList, HashSet?
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
Метод contains в Arraylist использует метод indexOf (), который использует в свою очередь метод indexOfRange (). Там совершается обход элементов в цикле и если элемент не null, то вызывается стандартный метод equals (сравнение ссылок). Тоже самое для LinkedList.
В методе contains HashSet используются «корзины» и поиск объекта происходит сначала по hashcode, а только потом по equals. В реализации:
Метод contains вызывает (косвенно) getEntry из HashMap, где ключ - это Object, для которого вы хотите узнать, находится ли он в HashSet.
Как вы можете видеть ниже, два объекта могут быть сохранены в HashMap/HashSet, даже если их ключ сопоставляется с тем же значением с помощью хэш-функции. Метод выполняет итерацию по всем ключам, которые имеют одно и то же значение хэша, и выполняет equals на каждом из них, чтобы найти соответствующий ключ.
final Entry
int hash = (key == null) ? 0 : hash(key.hashCode());
for (Entry
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
Как работает HashMap? Расскажите подробно, как работает метод put? Что происходит при коллизии?
Внутри Hashmap имеет вложенный класс Node в котором хранятся пары ключ значения:
static class Node
final int hash;
final K key;
V value;
Node
Node(int hash, K key, V value, Node
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
Далее внутри HashMap есть массив объектов типа Node
transient Node
Это и есть массив bucket.
Если возникает коллизия (т.е. hashcode вычисленный) объектов равны, то создается связанный список node в каждой ячейке массива node, где объекты ссылаются друг на друга
Как работает HashMap.
HashMap состоит из «корзин» (bucket`ов). «Корзины» — это элементы массива, которые хранят ссылки на списки элементов. При добавлении новой пары ключ-значение вычисляет хеш-код ключа, на основании которого вычисляется номер bucket’a(номер ячейки массива), в которую попадёт новый элемент.
Если bucket пуст, то в него сохраняется ссылка на вновь добавляемый элемент, если же там уже есть элемент, то происходит последовательный переход по ссылкам между элементами в цепочке, в поисках последнего элемента, от которого и ставится ссылка на вновь добавленный элемент. Если в списке был найден элемент с таким же ключом, то он заменяется.
Добавление, поиск и удаление элементов выполняется за константное время. Вроде все здорово, с одной оговоркой, хеш-функций должна равномерно распределять элементы по корзинам, в этом случае временная сложность для этих 3 операций будет не ниже lg N, а в среднем случае как раз константное время.
Как работает метод put.
Вычисляется хеш-значение ключа введенного объекта. Хэш ключа вычисляет метод static final int hash(Object key), который уже обращается к известному методу hashCode() ключа. Для этого используется либо переопределенный метод hashCode(), либо его реализация по умолчанию.
Почему бы просто не вычислить с помощью hashCode()? Это сделано из-за того, что hashCode() можно реализовать так, что только нижние биты int'a будут заполнены. Например, для Integer, Float – если мы в HashMap кладем маленькие значения, то у них и биты хеш-кодов будут заполнены только нижние. В таком случае ключи в Hash Map будут иметь тенденцию скапливаться в нижних ячейках, а верхние будут оставаться пустыми, что не очень эффективно. На то, в какой бакет попадёт новая запись, влияют только младшие биты хеша. Поэтому и придумали различными манипуляциями подмешивать старшие биты хеша в младшие, чтобы улучшить распределение по бакетам (чтобы старшие биты родного хеша объекта начали вносить коррективы в то, в какой бакет попадёт объект) и, как следствие, производительность. Потому и придумана дополнительная функция hash внутри HashMap.
Вычисляем индекс бакета (ячейки массива), в который будет добавлен наш элемент: i = (n - 1) & hash где n – длина массива. & - побитовое умножение (количество бакетов (16-1) приводится в битовый эквивалент, над ними производится побитовое умножение.
Создается объект Node (включает хеш, ключ, значение, ссылка на следующий элемент, (либо null, если его нет)).
Теперь, зная индекс в массиве, мы получаем список (цепочку) элементов, привязанных к этой ячейке. Если в бакете пусто, тогда просто размещаем в нем элемент. Иначе хэш и ключ нового элемента поочередно сравниваются с хешами и ключами элементов из списка и, при совпадении этих параметров, значение элемента перезаписывается. Если совпадений не найдено, элемент добавляется в конец списка.
Ревью: Функциональные Интерфейсы. Streams
Stream API в видео (11 часов) - https://www.youtube.com/playlist?list=PLtNPgSbW9TX5IQAKzgrJnaayjaDoCjkio
https://www.youtube.com/watch?v=FCT2jbAs_uA (2 часа) - стримы.
Использование лямбда выражений – https://www.youtube.com/watch?v=ztraQ9chIUE&feature=youtu.be&ab_channel=SoftwareArchitectAlexKorolev
https://www.youtube.com/watch?v=k7PlG32BzI8&ab_channel=%D0%A3%D1%80%D0%BE%D0%BA%D0%B8Java - class Optional
Java8 - https://github.com/timmson/java-interview/blob/master/006-java8.md
полное руководство по Stream API - https://annimon.com/article/2778
http://javatutor.net/articles/anonymyous-classes-in-java - анонимные классы.
https://metanit.com/java/tutorial/9.1.php - лямбды
https://habr.com/ru/company/luxoft/blog/270383/ - Stream API
Функциональное программирование- плюсы минусы, где применяется –
Функциональное программирование помогает сделать код более понятным, предсказуемым и легким для чтения. Использование принципов функционального программирования помогает избавиться от ненужных абстракций с непредсказуемым поведением, поэтому сделать программу более предсказуемой и уменьшить количество возможных ошибок.
ООП-подход подразумевает написание базовых классов и расширение существующих путем добавления к ним методов. Данные хранятся в экземпляре класса вместе с методами, которые ими оперируют. Функции в ООП зависят от внешних данных (например, содержат внутри себя ссылки на глобальные переменные) или коммуницируют с внешним миром (ввод-вывод).
В отличие от ООП, функциональное программирование характеризуется слабой связью функции с данными, которыми она оперирует. Это позволяет избежать побочных эффектов при выполнении функций — например чтения и изменения глобальных переменных, операций ввода-вывода и так далее. Детерминированные функции ФП возвращают один и тот же результат для одних и тех же аргументов.
Самое большое преимущество функционального программирования-краткость, потому что код может быть более кратким. Функциональная программа не создает переменную итератора в качестве центра цикла, поэтому этот и другие виды накладных расходов исключаются из вашего кода.
Другим важным преимуществом является параллелизм, что легче сделать с функциональным программированием, поскольку компилятор заботится о большинстве операций, которые раньше требовали ручной настройки переменных состояния (например, итератора в цикле).
анонимные классы, как создать, где применяются, особенно как создать экземпляр - https://ru.hexlet.io/courses/java_101/lessons/anonymous/theory_unit
императивный vs декларативный подход - Декларативные компьютерные языки часто не полны по Тьюрингу, так как теоретически не всегда возможно порождение исполняемого кода по декларативному описанию.
Императивное программирование — это парадигма программирования, в которой задаётся последовательность действий, необходимых для получения результата.
Декларативный стиль
Такой стиль, в котором вы описываете, какой именно результат вам нужен. И получатель такого сообщения уже сам разбирается, какие шаги для этого надо предпринять.
https://www.youtube.com/watch?v=MYbPJj2BFUw
https://www.youtube.com/watch?v=oC2p0t2R9ZQ