отчет по лабораторной работе. Кодирование+(1). Кодировка это соответствие между визуальными символами и числами
 Скачать 174.67 Kb. Скачать 174.67 Kb.
|

|
Кодировки Кодировка — это соответствие между визуальными символами и числами. Кодировки необходимы, так как компьютеры созданы для работы с числами и не понимают текст. До 1990-х годов не существовало единой кодировки, это приводило к тому, что текст, написанный в одной кодировке, становится совершенно нечитаемым на других. Unicode — единый стандарт кодирования символов. Развитие интернета и необходимость обмена большим количеством текстовой информации приводило к тому, что сейчас все пользуются этим стандартом. UTF-8, UTF-16, UTF-32 и т.п. — это варианты кодировок, основанные на Unicode. Отличаются они тем, что по-разному хранят информацию. UTF-8 — самая популярная кодировка. Особенность её в том, что самые популярные символы кодируются 1-2 байтами, а редко встречающиеся занимают 3-4 байта. Это приводит к существенной экономии памяти, например, при работе с английским текстом. Текст ASCII ASCII — American Standard Code for Information Interchange. ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились. Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ. Таблица ASCII 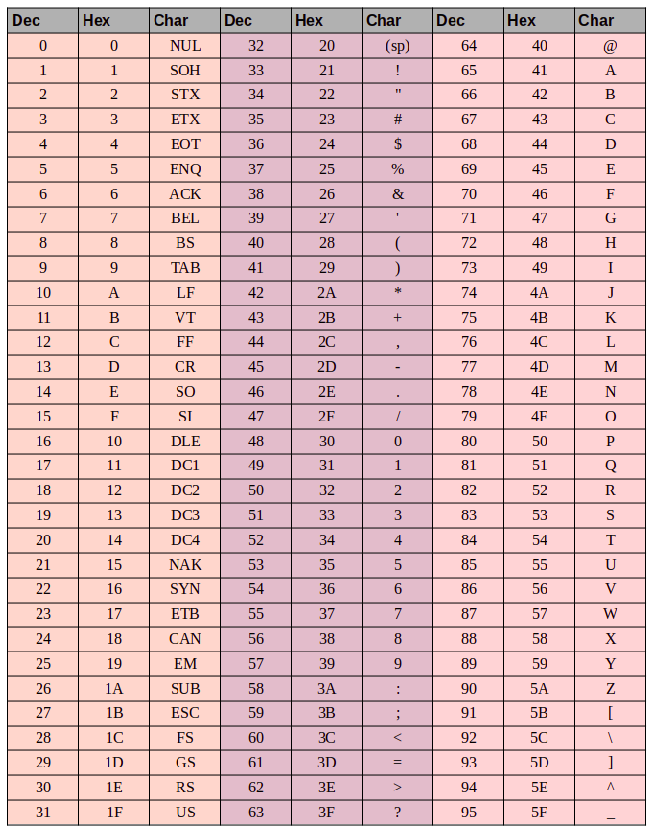 Тут имеем 3 колонки: Тут имеем 3 колонки:номер символа в десятичном формате номер символа в шестнадцатиричном формате представление самого символа. Текст UTF UTF-8 – кодировка символов юникод в двоичном виде. Использует от 1 до 4 байт. Так как наиболее часто используемые символы занимают 1 байт (в частности, аски-символы), то UTF-8 оптимальна для английского текста, но не для азиатского. Base64 – способ кодирования произвольных двоичных данных в ASCII текст. По своей сути кодирование очень простое. Каждые шесть бит на входе кодируется в один из символов 64-буквенного алфавита. “Стандартный” алфавит, который для этого используется – это A-Z, a-z, 0-9,+,/ и = в качестве заполняющего символа в конце. Таким образом, на каждые 3 байта данных приходится 4 символа. 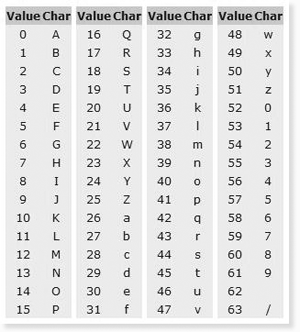 Man is distinguished, not only by his reason, but by this singular passion from other animals, which is a lust of the mind, that by a perseverance of delight in the continued and indefatigable generation of knowledge, exceeds the short vehemence of any carnal pleasure. будучи перекодированной из ASCII в Base64, выглядит следующим образом: TWFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5IGhpcyByZWFzb24sIGJ1dCBieSB0 aGlzIHNpbmd1bGFyIHBhc3Npb24gZnJvbSBvdGhlciBhbmltYWxzLCB3aGljaCBpcyBhIGx1 c3Qgb2YgdGhlIG1pbmQsIHRoYXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2YgZGVsaWdodCBpbiB0 aGUgY29udGludWVkIGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVyYXRpb24gb2Yga25vd2xlZGdl LCBleGNlZWRzIHRoZSBzaG9ydCB2ZWhlbWVuY2Ugb2YgYW55IGNhcm5hbCBwbGVhc3VyZS4= В примере, слово Man закодировано как TWFu. Процесс преобразования можно представить в виде следующей таблицы:
Схема соответствия «символ — значение» в Base64[
Шестнадцатеричная система счисления (HEX) – это позиционная система счисления по целочисленному основанию 16. В качестве шестнадцатеричных чисел используются цифры от 0 до 9 и латинские буквы от A до F. Значения чисел от 0 до 9 обычны, как и в десятичной системе, далее, от 10 до 16 используются буквы A-F, т.е. буква F = 16, далее 11 = 17, 12 = 18 и т.д и т.п. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||