МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ государственное БЮДЖЕТНОЕ
образовательное учреждение
высшего образования
«НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
____________________________________________________________________
Кафедра Вычислительной техники

ОТЧЁТ
по лабораторной работе № 1
«Введение в R. Методы первичного разведочного анализа данных в R»
по дисциплине: «Компьютерные технологии анализа и обработки данных»
Выполнил:Проверил:
Студент гр. «АММ2-21», «АВТФ» «к.т.н., доцент»
«Абдрашитов Д.Ш.» «Альсова О.К.»
«25» сентября 2021г.«25» сентября 2021 г.
_________________ _________________
(подпись) (подпись)
Новосибирск
2021
Цель лабораторной работы
получить базовые навыки работы в среде R;
изучить средства R для проведения первичного разведочного анализа данных (методы визуализации, описательной статистики, корреляционного анализа данных) на примере решения конкретной задачи ИАД (интеллектуального анализа данных).
2. Расчет основных статистических характеристик
1. Установим рабочую директорию командой setwd. Загрузим файл с данными, соответствующий 7 варианту (рис. 1).

Рис. 1 — Результат загрузки файла.
2. С помощью функции View() посмотрим загруженные данные(рис.2).

Рис. 2 — Визуализация загруженных данных.
3. Данные столбцов: пол, группа, участие в интернет опросах, степень удовлетворенности услугами качественная оценка определим как фактор. Рассчитаем основные статистические характеристики по количественным данным с помощью функции summary.
X.п.п группа пол возраст количество.покупок..за.год
Min. : 1.00 1:100 1:100 Min. :14.00 Min. :10.00
1st Qu.: 50.75 2:100 2:100 1st Qu.:20.00 1st Qu.:16.00
Median :100.50 Median :25.50 Median :18.00
Mean :100.50 Mean :27.59 Mean :18.73
3rd Qu.:150.25 3rd Qu.:35.00 3rd Qu.:22.00
Max. :200.00 Max. :46.00 Max. :27.00
средняя.стоимость..покупок.за.год среднее.число.страниц...просмотренных.за.визит
Min. :237.0 Min. : 1.500
1st Qu.:406.8 1st Qu.: 4.600
Median :543.5 Median : 6.150
Mean :530.2 Mean : 6.083
3rd Qu.:638.8 3rd Qu.: 7.425
Max. :837.0 Max. :12.200
количество.обращений.в.службу.поддержки.за.год участие.в..Интернет.опросах.
Min. : 7.00 1:31
1st Qu.:12.00 2:68
Median :15.00 3:68
Mean :17.07 4:33
3rd Qu.:22.00
Max. :29.00
степень..удовлетворенности.услугами..балльная.оценка.
Min. : 22.00
1st Qu.: 64.00
Median : 74.00
Mean : 73.61
3rd Qu.: 84.00
Max. :100.00
степень..удовлетворенности.услугами..качественная.оценка.
высокая:99
низкая :53
средняя:48
Как мы видим функция позволяет выводить полезные статистические данные такие как, минимальное, максимальное, среднее значение, стандартное отклонение, первая и третья квартили, медиана, мода, асимметрия, эксцесс. По этим данным легко проводить статистический анализ например, минимальный возраст опрошенных равен 14, тогда как максимальный равен 46 и т.д.
3. Графический разведовательный анализ
Построим диаграмму рассеяния по двум количественным признакам возраст и количество покупок за год.(рис.4)

Рис. 4 — Диаграмма рассеяния по двум количественным признакам.
По диаграмме на рисунке 4 можно сделать вывод что, количество покупок за год тем больше чем меньше возраст.
Построим радиальную диаграмму по качественному признаку степень удовлетворенности услугами.(рис.5)

Рис. 5 — Радиальная диаграмма по качественному признаку
По радиальной диаграмме на рисунке 5 можно сделать вывод что доминирует высокая удовлетворенность услугами, в то время как низкая и средняя оценка находятся примерно в равном соотношении.
Построим категориальную радиальную диаграмму по качественному признаку степень удовлетворенности услугами в зависимости от принадлежности к полу.(рис.6)

Рис. 6 — Радиальная диаграмма
На диаграммах видно что несмотря на пол на высокая степень удовлетворенности наблюдается во всех группах не зависимо от пола. Среди групп у женщин можно говорить об одинаковом соотношение степени удовлетворенности, однако среди групп мужчин наблюдается сильное различие в средней и низкой оценкой.
Построим диаграмму размаха
Р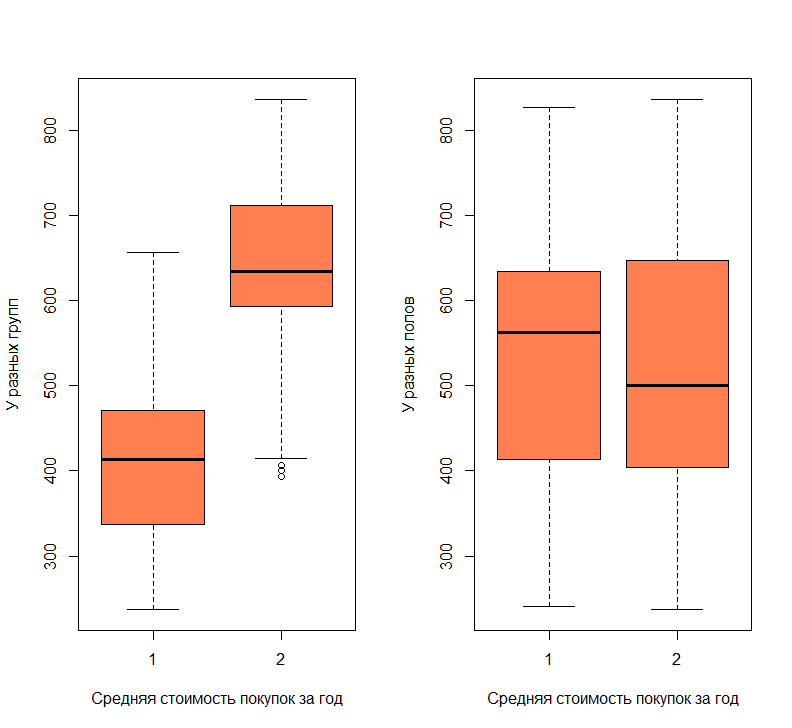 ис. 7 — Диаграмма размаха. ис. 7 — Диаграмма размаха.
- гистограммы для количественных признаков на одном графике;
Р ис. 8 — Гистограммы для количественных признаков. ис. 8 — Гистограммы для количественных признаков.
- матричный график по количественным переменным.
Р ис. 9 — Матричный график. ис. 9 — Матричный график.
На основе проведенного анализа сделайте выводы о структуре данных, о характере распределения данных в терминах решаемой задачи.
4. Корреляционный анализ данных.
5.1. Оцените степень взаимосвязи между качественными переменными на основе критериев Chi-квадрат и Фишера. Сделайте выводы о силе и направлении связи в терминах решаемой задачи.
Chi-квадрат:
Pearson's Chi-squared test with Yates' continuity correction
data: table(data$группа, data$пол)
X-squared = 1.62, df = 1, p-value = 0.2031
> chisq.test(table(data$группа,data$участие.в..Интернет.опросах.))
Pearson's Chi-squared test
data: table(data$группа, data$участие.в..Интернет.опросах.)
X-squared = 1.3662, df = 3, p-value = 0.7135
> chisq.test(table(data$группа,data$степень..удовлетворенности.услугами..качественная.оценка.))
Pearson's Chi-squared test
data: table(data$группа, data$степень..удовлетворенности.услугами..качественная.оценка.)
X-squared = 5.8135, df = 2, p-value = 0.05465
> chisq.test(table(data$пол,data$участие.в..Интернет.опросах.))
Pearson's Chi-squared test
data: table(data$пол, data$участие.в..Интернет.опросах.)
X-squared = 65.471, df = 3, p-value = 3.978e-14
> chisq.test(table(data$пол,data$степень..удовлетворенности.услугами..качественная.оценка.))
Pearson's Chi-squared test
data: table(data$пол, data$степень..удовлетворенности.услугами..качественная.оценка.)
X-squared = 2.8076, df = 2, p-value = 0.2457
> chisq.test(table(data$участие.в..Интернет.опросах.,data$степень..удовлетворенности.услугами..качественная.оценка.))
Pearson's Chi-squared test
data: table(data$участие.в..Интернет.опросах., data$степень..удовлетворенности.услугами..качественная.оценка.)
X-squared = 5.6449, df = 6, p-value = 0.4641
Фишер:
fisher.test(table(data$группа,data$пол))
Fisher's Exact Test for Count Data
data: table(data$группа, data$пол)
p-value = 0.203
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.3690955 1.2131081
sample estimates:
odds ratio
0.6707924
> fisher.test(table(data$группа,data$участие.в..Интернет.опросах.))
Fisher's Exact Test for Count Data
data: table(data$группа, data$участие.в..Интернет.опросах.)
p-value = 0.7246
alternative hypothesis: two.sided
> fisher.test(table(data$группа,data$степень..удовлетворенности.услугами..качественная.оценка.))
Fisher's Exact Test for Count Data
data: table(data$группа, data$степень..удовлетворенности.услугами..качественная.оценка.)
p-value = 0.05548
alternative hypothesis: two.sided
> fisher.test(table(data$пол,data$участие.в..Интернет.опросах.))
Fisher's Exact Test for Count Data
data: table(data$пол, data$участие.в..Интернет.опросах.)
p-value < 2.2e-16
alternative hypothesis: two.sided
> fisher.test(table(data$пол,data$степень..удовлетворенности.услугами..качественная.оценка.))
Fisher's Exact Test for Count Data
data: table(data$пол, data$степень..удовлетворенности.услугами..качественная.оценка.)
p-value = 0.2584
alternative hypothesis: two.sided
> fisher.test(table(data$участие.в..Интернет.опросах.,data$степень..удовлетворенности.услугами..качественная.оценка.))
Fisher's Exact Test for Count Data
data: table(data$участие.в..Интернет.опросах., data$степень..удовлетворенности.услугами..качественная.оценка.)
p-value = 0.4595
alternative hypothesis: two.sided
5.2. Оцените степень взаимосвязи между количественными переменными на основе расчета коэффициентов корреляции Пирсона, Спирмена, Кендалла.
5.3. Оцените степень взаимосвязи между двумя количественными переменными (для которых коэффициент корреляции Пирсона максимален по модулю) на основе расчета частного коэффициента корреляции.
> pcor(c(2,6,1,3,4,5,7),cov(M))
[1] 0.6107709
5.4. Графически представьте матрицы коэффициентов корреляции. Оцените статистическую значимость связи. Сделайте выводы о силе и направлении связи в терминах решаемой задачи.

5. Вывод
Приложение 1
Листинг программы
#Вариант 7
setwd("C:\\newr")
data<-read.table("7.csv", header = TRUE, sep=";")
View(data)
#3 пункт
data$пол<-as.factor(data$пол)
data$группа<-as.factor(data$группа)
data$участие.в..Интернет.опросах.<-as.factor(data$участие.в..Интернет.опросах.)
data$степень..удовлетворенности.услугами..качественная.оценка.<-as.factor(data$степень..удовлетворенности.услугами..качественная.оценка.)
summary(data)
#4 пункт
plot(data.frame(data$возраст,data$количество.покупок..за.год))
x<-c(summary(data$степень..удовлетворенности.услугами..качественная.оценка.))
piepercent<-round(100*x/sum(x),1)
pie(x,piepercent,radius=1,main = "Радиальная диаграмма",xlab="Степень удовлетворенности услугами",col = c("red","blue","yellow"),clockwise = TRUE)
legend("topright", c("высокая","низкая","средняя"),cex = 0.8, fill = c("red","blue","yellow"))
x1<-c(summary(data$степень..удовлетворенности.услугами..качественная.оценка.[data$группа=="1"&data$пол=="1"]))
x2<-c(summary(data$степень..удовлетворенности.услугами..качественная.оценка.[data$группа=="2"&data$пол=="1"]))
x3<-c(summary(data$степень..удовлетворенности.услугами..качественная.оценка.[data$группа=="1"&data$пол=="2"]))
x4<-c(summary(data$степень..удовлетворенности.услугами..качественная.оценка.[data$группа=="2"&data$пол=="2"]))
piepercent1<-round(100*x1/200,1)
piepercent2<-round(100*x2/200,1)
piepercent3<-round(100*x3/200,1)
piepercent4<-round(100*x4/200,1)
par(mfrow=c(2,2))
pie(x1, piepercent1, radius = 1, main = "Радиальная диаграмма", xlab="Группа=1", ylab="Пол=М",col=c("red","blue","yellow","green"),clockwise=TRUE)
pie(x2, piepercent2, radius = 1, main = "Радиальная диаграмма", xlab="Группа=2", ylab="Пол=м",col=c("red","blue","yellow","green"),clockwise=TRUE)
pie(x3, piepercent3, radius = 1, main = "Радиальная диаграмма", xlab="Группа=1", ylab="Пол=ж",col=c("red","blue","yellow","green"),clockwise=TRUE)
pie(x4, piepercent4, radius = 1, main = "Радиальная диаграмма", xlab="Группа=2", ylab="Пол=ж",col=c("red","blue","yellow","green"),clockwise=TRUE)
par(mfrow=c(2,2))
barplot(table(data$количество.покупок..за.год[data$группа=="1"&data$пол=="1"]),col=c("blue"),main="Муж",xlab="Кол-во покупок за год", ylab="Количество в 1 группе")
barplot(table(data$количество.покупок..за.год[data$группа=="2"&data$пол=="1"]),col=c("blue"),main="Муж",xlab="Кол-во покупок за год", ylab="Количество во 2 группе")
barplot(table(data$количество.покупок..за.год[data$группа=="1"&data$пол=="2"]),col=c("red"),main="Жен",xlab="Кол-во покупок за год", ylab="Количество в 1 группе")
barplot(table(data$количество.покупок..за.год[data$группа=="2"&data$пол=="2"]),col=c("red"),main="Жен",xlab="Кол-во покупок за год", ylab="Количество во 2 группе")
par(mfrow=c(1,2))
boxplot(data$средняя.стоимость..покупок.за.годdata$группа,xlab="Средняя стоимость покупок за год", ylab="У разных групп", col="coral", data=data)
boxplot(data$средняя.стоимость..покупок.за.год
data$пол,xlab="Средняя стоимость покупок за год", ylab="У разных полов", col="coral", data=data)
par(mfrow=c(2,3))
hist(data$возраст,freq=FALSE,breaks=12,col="blue",xlab="Возраст",main="Гистограмма")
lines(density(data$возраст))
hist(data$количество.покупок..за.год,freq=FALSE,breaks=12,col="blue",xlab="Кол-во покупок за год",main="Гистограмма")
lines(density(data$количество.покупок..за.год))
hist(data$средняя.стоимость..покупок.за.год,freq=FALSE,breaks=12,col="blue",xlab="Средняя стоимость покупок за год",main="Гистограмма")
lines(density(data$средняя.стоимость..покупок.за.год))
hist(data$среднее.число.страниц...просмотренных.за.визит,freq=FALSE,breaks=12,col="blue",xlab="Среднее число страниц за визит",main="Гистограмма")
lines(density(data$среднее.число.страниц...просмотренных.за.визит))
hist(data$количество.обращений.в.службу.поддержки.за.год,freq=FALSE,breaks=12,col="blue",xlab="Количество обращений в службу поддержки за год",main="Гистограмма")
lines(density(data$количество.обращений.в.службу.поддержки.за.год))
hist(data$степень..удовлетворенности.услугами..балльная.оценка.,freq=FALSE,breaks=12,col="blue",xlab="Cтепень удовлетворенности услугами балльная оценка",main="Гистограмма")
lines(density(data$степень..удовлетворенности.услугами..балльная.оценка.))
pairs(
data$возраст+data$количество.покупок..за.год+data$средняя.стоимость..покупок.за.год+data$среднее.число.страниц...просмотренных.за.визит+data$количество.обращений.в.службу.поддержки.за.год+data$степень..удовлетворенности.услугами..балльная.оценка., data=data, main="Матричный график")
#5 пункт
#5.1
#Хи квадрат
chisq.test(table(data$группа,data$пол))
chisq.test(table(data$группа,data$участие.в..Интернет.опросах.))
chisq.test(table(data$группа,data$степень..удовлетворенности.услугами..качественная.оценка.))
chisq.test(table(data$пол,data$участие.в..Интернет.опросах.))
chisq.test(table(data$пол,data$степень..удовлетворенности.услугами..качественная.оценка.))
chisq.test(table(data$участие.в..Интернет.опросах.,data$степень..удовлетворенности.услугами..качественная.оценка.))
#Фишера
fisher.test(table(data$группа,data$пол))
fisher.test(table(data$группа,data$участие.в..Интернет.опросах.))
fisher.test(table(data$группа,data$степень..удовлетворенности.услугами..качественная.оценка.))
fisher.test(table(data$пол,data$участие.в..Интернет.опросах.))
fisher.test(table(data$пол,data$степень..удовлетворенности.услугами..качественная.оценка.))
fisher.test(table(data$участие.в..Интернет.опросах.,data$степень..удовлетворенности.услугами..качественная.оценка.))
#5.2
M<-data[,unlist(lapply(data, is.numeric))]
N1<-cor(M,use="pairwise.complete.obs")
N2<-cor(M,use="pairwise.complete.obs",method="spearman")
N3<-cor(M,use="pairwise.complete.obs",method="kendall")
#5.3
install.packages("ggm")
library(ggm)
pcor(c(2,6,1,3,4,5,7),cov(M))
#5.4
install.packages("corrplot")
library(corrplot)
col<-colorRampPalette(c("#BB4444","#EE9988","#FFFFFF","#77AADD","#4477AA"))
corrplot(N1,method="color",col=NULL,type="upper",order="hclust",addCoef.col="black", tl.col="black", tl.srt=45,sig.level=0.01,insig="blank",diag=FALSE) |
 Скачать 124.37 Kb.
Скачать 124.37 Kb.