лекции. Конспект лекций профессионального модуля пм. 02 Разработка и администрирование баз данных междисциплинарного курса
 Скачать 0.63 Mb. Скачать 0.63 Mb.
|

2.5. Физическая модель данныхФизическая модель данных – это логическая модель данных, учитывающая особенности специфической целевой СУБД, такой как, например, Oracle или Informix. Существует два способа создания физической модели: ее можно создать с нуля или из существующей реляционной модели данных. Для всех таблиц модели необходимо определить типы данных. Индексы в базе данных используются в следующих основных случаях: Ускорение выполнения запросов. Обеспечение уникальности значений в полях. Ограничение первичного ключа требует, чтобы во всей таблице не нашлось двух одинаковых значений полей, входящих в первичный ключ. Чтобы выполнить это условие, необходимо при каждой вставке новой записи производить поиск такого же значения, которое будет вставлено. Для поиска записей используется уникальный индекс. Обеспечение ссылочной целостности. Ограничения внешних ключей используются для проверки того, чтобы вставляемые в таблицу значения обязательно существовали в другой таблице. При создании внешнего ключа индекс применяется для проверки условий внешнего ключа. 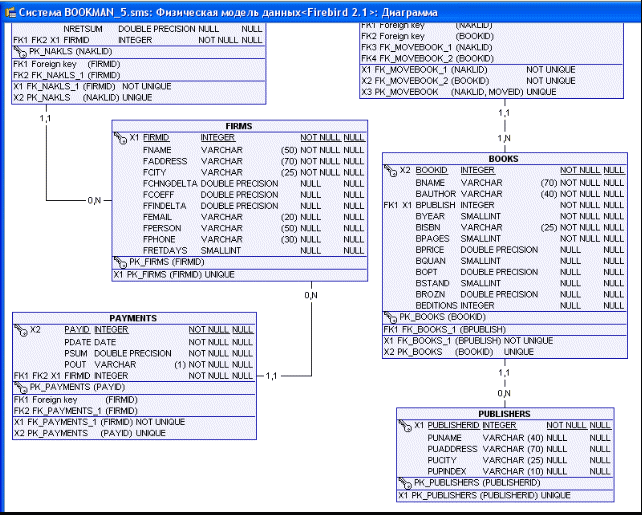 Рис. 4 Физическая модель данных Типы данных - это базовые элементы любого сервера СУБД. Когда мы говорим, что в БД хранится какая-то информация, то должны осознавать, что эта информация не может быть свалена в одну большую кучу; наоборот, данные должны быть рассортированы по полям таблицы в БД. Типы данных определяют, что можно хранить в данном поле, что нельзя. Каждый тип данных имеет набор операций, которые можно выполнять над значениями этого типа. Поэтому необходимо правильно выбрать тип данных при проектировании БД, что поможет избежать многих проблем при разработке приложений. В Firebird существует 12 типов данных, которые удобно подразделять на 6 следующих групп: - для хранения целых чисел – Integer и Smallint; - для хранения вещественных чисел – Float и Double Precision; - для чисел с фиксированной точностью; - для хранения даты, времени и даты / времени – Date, Time и Timestamp; - для хранения символов – Character (сокращенно Char) и Varying Character (сокращенно Varchar); - для хранения большого массива данных – BLOB (Binary Large Objects). Также возможно определять массивы значений всех перечисленных типов, кроме BLOB. Массивы могут иметь несколько размерностей. К ним относятся Smallint и Integer. Smallint имеет длину 2 байта, Integer – 4 байта. Область применения целочисленных типов - они нужны для полей, содержащих только целые числа (для хранения счетчиков, количества деталей и пр.). Обычно тип Integer имеют также поля, содержащие первичные ключи. Это типы для чисел с плавающей точкой – Float и Double Precision. Тип Float имеет недостаточную точность для хранения большинства дробных значений. Не рекомендуется хранить в нем денежные величины – в переменных этого типа очень быстро нарастают ошибки округления, что может сильно удивить бухгалтера при подведении итогов. Лучшим выбором поэтому для хранения чисел в бухгалтерских системах или в системах для научных расчетов будет тип Double Precision. К ним относятся типы Numeric и Decimal. Оба эти типа имеют одинаковую разрядность (от 1 до 18 знаков) и одинаковую точность. Разрядность – это общее число цифр в числе, точность – число знаков после запятой. Существует два типа – CHAR и VARCHAR. Полные их названия CHARACTER и VARYIGN CHARACTER. Чтобы определить поле или переменную символьного типа, необходимо в скобках после имени типа либо указать число символов для определяемого объекта, либо опустить число символов, и при этом будет создано поле с длиной один символ. Типы CHAR и VARCHAR во много сходны: оба могут содержать до 32768 символов. Однако есть и отличия. При выборке данных из поля типа CHAR возвращаемое значение дополняется пробелами до полной длины поля. Для поля типа VARCHAR выбираются только занесенные в него символы. В любом случае рекомендуется использовать символьный тип VARCHAR. (Загрузка сети выше при использовании CHAR.) Одной из важнейших характеристик символьного типа является его набор символов - CHARACTER SET. Если набор символов определен для всей базы данных, то он используется по умолчанию для всех символьных полей, если не переопределяется явно при создании поля. Существует три типа для хранения даты и времени (диалект 3) – 1 – это DATE, TIME и TIMESTAMP. Тип DATE хранит даты с точностью до дня. Диапазон возможных значений от 1 января 100 года до 29 февраля 32768 года. Тип TIME хранит данные о времени с точностью до десятитысячной доли секунды. Диапазон возможных значений – от 00:00:00 до 23:59:9999. Тип TIMESTAMP представляет собой комбинацию типов DATE и TIME. Если надо вырезать из полной даты только год или месяц, используется функция EXTRACT. EXTRACT(MONTH FROM DATE_FIELD), где DATE_FIELD – имя поля, EXTRACT(MONTH FROM DATE_FIELD) Этот тип предназначен для хранения большого количества данных переменного размера. Он позволяет хранить данные, которые не могут быть помещены в поля других типов. Например, картинки, музыкальные файлы, видеофрагменты и т.д. У типа BLOB имеется возможность определять набор нескольких подтипов и специальных процедур, называемых фильтрами (BLOB filters), для работы с этими подтипами. В InterBase имеются подтипы: subtype 0 - данные неопределенного типа, subtype 1 - текст, subtype 2 – BLR(Binary Language Representation) - это двоичное представление хранимых процедур, триггеров, запросов к серверу. Объем неограничен. СУБД Firebird была одной из первых, в которой появились массивы. Поддержка массивов в базе данных является расширением традиционной реляционной модели. Массивы могут быть одномерными и многомерными. Массивы реализованы на базе полей типа BLOB. Они предоставляют удобный механизм для хранения однотипных объектов. Однако в большинстве случаев вместо массивов разработчики предпочитают держать множественные данные в подчиненных таблицах (master/Detail). Единственным средством общения и администраторов баз данных, и проектировщиков, и разработчиков, и пользователей с реляционной базой данных является структурированный язык запросов SQL (Structured Query Language). SQL есть полнофункциональный язык манипулирования данными в реляционных базах данных. В настоящее время он является общепризнанным, стандартным интерфейсом для реляционных баз данных, таких как Oracle, Interbase, Firebird, MS SQL Server и ряда других (стандарты ANSI и ISO). SQL — непроцедурный язык, который предназначен для обработки множеств, состоящих из строк и колонок таблиц реляционной базы данных. Проектировщики баз данных используют SQL для создания всех физических объектов реляционной базы данных. В настоящем курсе лекций предполагается, что используется СУБД Firebird. Теоретические основы SQL были заложены в известной статье Кодда, положившей начало развитию теории реляционных БД. Первая практическая реализации была выполнена в исследовательских лабораториях фирмы IBM Chamberlin D.D. и Royce R.F. Промышленное применение SQL было впервые реализовано в СУБД Ingres. По сути дела, реляционная СУБД - это программное обеспечение, которое управляет работой реляционной базы данных. Первый международный стандарт языка SQL был принят в 1989 г. (SQL-89). В конце 1992 г. был принят новый международный стандарт SQL-92. Последний стандарт также называется стандартом ANSI. В настоящее время большинство производителей реляционных СУБД используют его в качестве базового. Однако работы по стандартизации языка SQL далеки от завершения и уже разработан проект стандарта SQL-99, который вводит в обиход языка понятие объекта и разрешает на него ссылаться в операторах SQL. В исходном варианте SQL не было команд управления потоком данных, они появились в недавно принятом стандарте ISO/IEC 9075-5: 1996 дополнительной части SQL. Каждой конкретной СУБД соответствует своя собственная реализация SQL, в целом поддерживающая определенный стандарт, но имеющая свои особенности. Эти реализации называются диалектами. Так, стандарт ISO/IEC 9075-5 предусматривает объекты, называемые постоянно хранимыми модулями или PSM-модулями (Persistent Stored Modules). Язык SQL Firebird близко соответствует стандартам SQL-92. Firebird вводит множество возможностей в соответствии с более поздним релизом стандарта SQL-99. Хотя SQL в Firebird соответствует стандартам, существуют небольшие отличия. SQL состоит из набора команд манипулирования данными в реляционной базе данных, которые позволяют создавать объекты реляционной базы данных, модифицировать данные в таблицах (вставлять, удалять, исправлять), изменять схемы отношений базы данных, выполнять вычисления над данными, делать выборки из базы данных, поддерживать безопасность и целостность данных. Весь набор команд SQL можно разбить на следующие группы: команды определения данных (DDL - Data Defininion Language); команды манипулирования данными (DML - Data Manipulation Language); команды выборки данных (DQL - Data Query Language); команды управления транзакциями; команды управления данными. При выполнении каждая команда SQL проходит четыре фазы обработки: фаза синтаксического разбора, которая включает проверку синтаксиса команды, проверку имен таблиц и колонок в базе данных, а также подготовку исходных данных для оптимизатора; фаза оптимизации, которая включает подстановку действительных имен таблиц и колонок базы данных в представление, идентификацию возможных вариантов выполнения команды, определение стоимости выполнения каждого варианта, выбор наилучшего варианта на основе внутренней статистики; фаза генерации исполняемого кода, которая включает построение выполняемого кода команды; фаза выполнения команды, которая включает выполнение кода команды. В настоящее время оптимизатор является составной частью любой промышленной реализации SQL. Работа оптимизатора основана на сборе статистики о выполняемых командах и выполнении эквивалентных алгебраических преобразований с отношениями базы данных. Такая статистика сохраняется в системном каталоге базы данных. Системный каталог является словарем данных для каждой базы данных и содержит информацию о таблицах, представлениях, индексах, колонках, пользователях и их привилегиях доступа. Каждая база данных имеет свой системный каталог, который представляет совокупность предопределенных таблиц базы данных. Команда на языке SQL называется запросом. Все SQL запросы можно условно разделить на два вида: статический SQL запрос, включается в код приложения во время его разработки и не изменяется во время выполнения приложения, динамический SQL запрос, создается и изменяется в ходе выполнения приложения. Все операторы и команды языка SQL можно разделить на три группы: операторы определения данных, предназначенные для создания, удаления и изменения структуры данных. CREATE TABLE – для создания таблицы базы данных ALTER TABLE – изменяет таблицу DROP TABLE – удаляет таблицу CREATE NDEX – создает индекс DROP INDEX – удаляет индекс операторы управления данными предназначены для управления привилегиями доступа к данным: GRANT – назначает привилегии пользователям REVOKE – удаляет привилегии пользователей операторы манипулирования данными предназначены для работы с записями таблиц: SELECT – для выборки записей по определенному формату: UPDATE – для изменения записей INSERT – вставляет новые записи в таблицу DELETE – удаляет записи из таблицы Результатом выполнения запроса является набор данных, который называется результирующим набором данных. Для обеспечения эффективного доступа к данным в реляционных СУБД поддерживаются такие объекты как индекс и функция. Таблица 3 содержит список команд SQL в соответствии с принятым стандартом, за исключением некоторых практически не используемых в диалекте СУБД Firebird команд. Таблица 3. Список команд языка SQL
Набор команд SQL, перечисленный в таблице, не является полным. Этот список приведен, чтобы составить представление о возможностях SQL в целом. Для получения полного списка команд следует обратиться к соответствующему руководству для конкретной СУБД. Следует помнить, что SQL является единственным средством общения всех категорий пользователей с реляционными базами данных. Таблица 4 содержит список внутренних функций SQL, доступных в Firebird. Таблица 4. Внутренние функции SQL
Основным оператором является оператор SELECT. Он используется для отбора данных, соответствующих сложным условиям. SELECT [DISTINCT] <список полей> или * FROM <список таблиц> [WHERE <условия выбора записей>] [ORDER BY <список полей сортировки>] [GROUP BY <список полей группировки>] [HAVING <условия группировки полей>] [UNION <присоединяемый оператор SELECT>] DISTINCT: если присутствует в операторе SELECT, то повторяющиеся записи будут исключены из набора данных. Если в список полей входят поля нескольких таблиц, то для указания принадлежности поля к той или иной таблице используют составной оператор, включающий имя таблицы и через точку имя поля — <имя таблицы>.<имя поля>. Примеры: Выборка таблицы целиком SELECT * FROM MYTABLE Выборка заданного списка полей таблицы SELECT Number, Surname, Telephone FROM MYTABLE SELECT * FROM MYTABLE ORDER BY NAME SELECT RDNUMB, RDNAME FROM TREADER where RDNUMB > '1300' ORDER BY 2 Выборка из нескольких таблиц SELECT * FROM MYTABLE1, MYTABLE2 Выборка только различных строк SELECT DISTINCT Surname FROM MYTABLE Выборка записей с условием SELECT Name, Surname FROM MYTABLE WHERE (Number>1) AND (Number<100) Выборка записей с условием SELECT Name FROM MYTABLE WHERE Surname = ‘Иванов’ Выборка записей с условием SELECT Name, Surname FROM MYTABLE WHERE Surname Like ‘H%’ Выборка с упорядочением SELECT RDNUMB, RDNAME FROM TREADER ORDER BY RDNAME Выборка с параметром SELECT UNIKEY BOOKNM from TBOOK where UNIKEY = :KEY Выборка с использованием псевдонимов таблиц SELECT E.FIRST_NAME, E.LAST_NAME, D.DEPARTMENT FROM EMPLOYEE E, DEPARTMENT D where D.DEPT_NO > 4 and E.DEPT_NO = D.DEPT_NO ORDER BY E.LAST_NAME Выборка с параметром SELECT * FROM EMPLOYEE WHERE DEPT_NO = : DEPT_NO Оператор UPDATE служит для изменения значений полей в группе записей: UPDATE <Имя таблицы> SET <Имя поля> = <Выражение>, <Имя поля> = <Выражение>, .... WHERE <условия выбора> Пример: UPDATE MYTABLE SET OKLAD = OKLAD + 1000 WHERE OKLAD < 1000 Оператор INSERT служит для вставки записей в таблицу INSERT INTO <имя таблицы> (<Список полей>) VALUES (<Список значений>) Пример: INSERT INTO MYTABLE (Name, Surname, Telephone) VALUES (‘Иван’, ‘Иванов’, 2341234) Оператор DELETE служит для удаления записей из таблиц DELETE FROM <имя таблицы> [WHERE <условия выбора>] Пример: DELETE FROM MyTable WHERE Surname = ‘Иванов’ Имеются расширения языка SQL для СУБД InterBase, используемые в хранимых процедурах. Это циклы и операторы ветвления. FOR SELECT ….DO WHILE ….DO IF …THEN…ELSE Примеры: CREATE PROCEDURE SIMPLE RETURNS (ID INTEGER, NAME VARCHAR (80)) AS BEGIN FOR SELECT ID, NAME FROM TABLE1 INTO :ID, :NAME DO BEGIN SUSPEND; /*передача сформированной записи клиенту*/ END END CREATE PROCEDURE QUAD RETURNS (QUADRAT INTEGER) AS DECLARE VARIABLE I INTEGER; BEGIN I = 1; WHILE (I < 100) DО BEGIN QUADRAT = I*I; I = I+1; SUSPEND; END END Входные переменные задаются так: CREATE PROCEDURE Name (I INTEGER, S DATE) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Вложенные SELECT SELECT RDNAME, RDNUMB FROM TREADER where UNIKEY IN (SELECT READER FROM TBOOK_READER where BOOKKEY = 18) Функции COUNT – подсчитывает количество строк, удовлетворяющих условиям запроса SUM – подсчитывает сумму значений указанного выражения по строкам, удовлетворяющим условиям запроса AVG – подсчитывает среднее значение указанного выражения по строкам, удовлетворяющим условиям запроса MAX, MIN – подсчитывают соответственно максимальное и минимальное значения у  казанного выражения по строкам, удовлетворяющим условиям запроса казанного выражения по строкам, удовлетворяющим условиям запросаselect COUNT ( * ) FROM TREADER select COUNT (DISTINCT READER) FROM TBOOK_READER select SUM (PRICE) FROM NAKLS where NAKLS.NUM > 36 Пример: Выборка списка читателей и взятых ими книг SELECT A.RDNUMB, A.RDNAME, B.BOOKNM FROM TREADER A, TBOOK B, TBOOK_READER AB where AB.READER = A.UNIKEY AND AB.BOOKKEY = B.UNIKEY B таблице TBOOK и TREADER ключи имеют одинаковое название UNIKEY. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||