Отчёт кр. Контрольная работа 1 Вариант 1 по Основы сбора и обработки больших данных
 Скачать 455.5 Kb. Скачать 455.5 Kb.
|

|
ФЕДЕРАЛЬНОЕ АГЕНТСТВО СВЯЗИ Федеральное государственное бюджетное образовательное учреждение высшего образования ПОВОЛЖСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ И ИНФОРМАТИКИ Заочный факультет РЕГИСТРАЦИОННЫЙ № Контрольная работа № ___1___ Вариант __1___ по «Основы сбора и обработки больших данных» Студент Ермаков Михаил Васильевич Факультет ____ЗО_____ курс ___3_____ шифр гр.05И Работа выслана « »_октябрь 2022г. Оценка _______________ Дата ___________20___г. Подпись преподавателя ___________________ Часть 1 Цель работы: получить базовые навыки моделирования данных в разрезе выполнения моделей. Устанавливаем библиотеки: numpy, statsmodels, sklearn. С помощью команды pip install… Запускаем IDLE, и создаем новый файл, вводим код: import statsmodels.api as sm import numpy as np predictors = np.random.random(1000).reshape(500, 2) target = predictors.dot(np.array([0.4, 0.6])) + np.random.random(500) lmRegModel = sm.OLS(target, predictors) result = lmRegModel.fit() print(result.summary()) 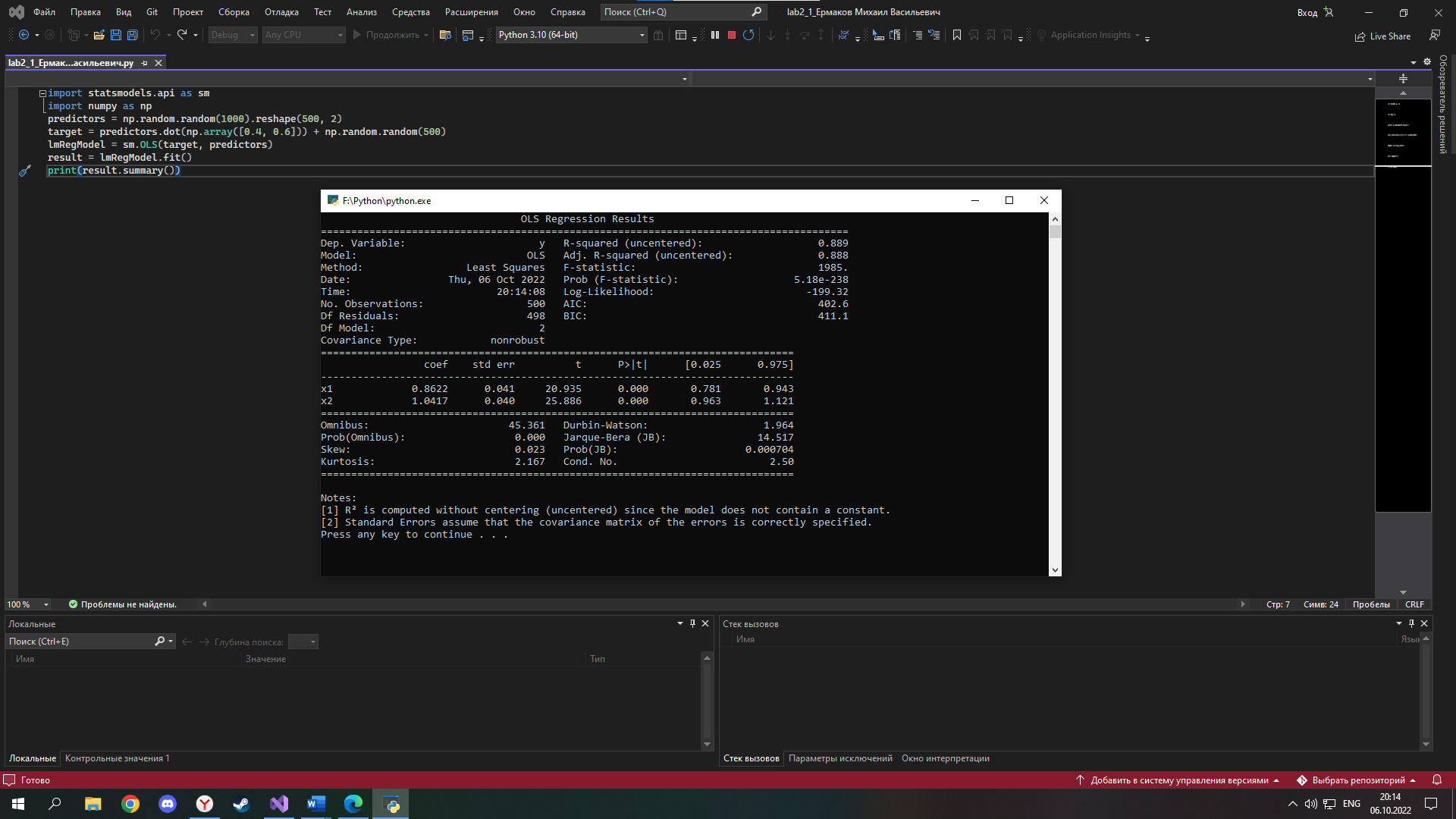 Необходимо добавить пояснение к выводу матрицы import statsmodels.api as sm import numpy as np print('Regression results') predictors = np.random.random(1000).reshape(500, 2) target = predictors.dot(np.array([0.4, 0.6])) + np.random.random(500) lmRegModel = sm.OLS(target, predictors) result = lmRegModel.fit() print(result.summary()) 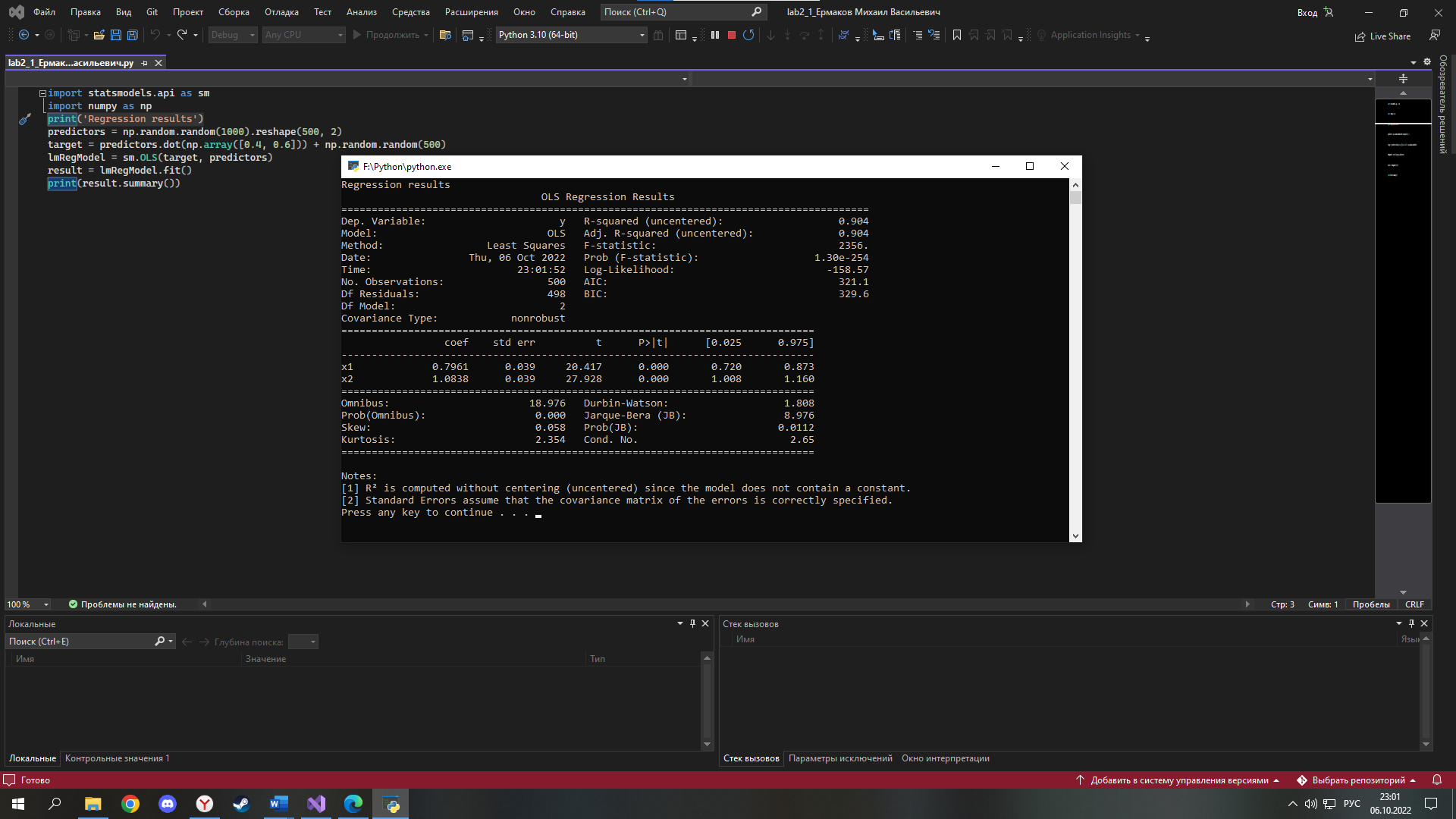 Выполните по 10 итераций для переменных "predictors" и "target", изменяя условия их формирования. Входные данные (условия формирования) и измерения (результаты) занести в таблицу (Excel). В таблицы использовать только метрики, рассмотренные на лекции. Минимальное значение метрики равно: [0.74813690 1.04371307] Среднее:[ 0.83293122 1.06944231] Максимальное: [0.91284322 1.05731586] Строим график Вывод: Влияние изменения predictors: При уменьшении значения (особенно менее 30) резко растёт коэффициент детерминации, приближаясь и становясь равным 1,а при увеличении значения коэффициент детерминации стремится к одной и той же константе (для target определяемого как [0.4, 0.6] это значение около 0,89) Влияние изменения target: При увеличении разницы между значениями массива растёт разница между Coef X1 и Coef X2, что отражает то, как части выборки влияют на изменение итоговых значений функции Y. Из этого следует вывод, что чем меньше изменение любой из частей тем большее влияние она оказывает на итоговый результат. Причём это действительно даже если увеличить сумму частей массива более 1, правда это вызывает значительное увеличение коэффициента детерминации и резко снижает доверие к результатам Часть 2 1. Создаем новый файл и называем его: lab2_2_Ермаков Михаил Васильевич 2. Вводим код: import numpy as np from sklearn import neighbors from sklearn.metrics import confusion_matrix predictors = np.random.random(1000).reshape(500,2) target = np.around(predictors.dot(np.array([0.4, 0.6])) + np.random.random(500)) clf = neighbors.KNeighborsClassifier(n_neighbors = 10) knn = clf.fit(predictors, target) print(knn.score(predictors, target)) prediction = knn.predict(predictors) print(confusion_matrix(target, prediction)) 3. Результат выполнения кода 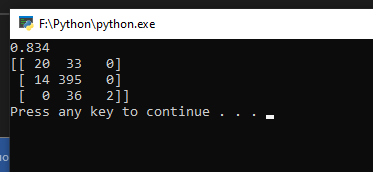 4. Необходимо, чтобы впереди матрицы выходил текст, добавляем его с помощью команды: print print ('model compliance metrics and nonconformity matrices') Результат ниже: 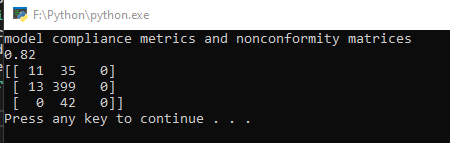 5. Производим 10 итераций результат в файле result 6. В результате выполнения лабораторной работы были рассмотрены принципы моделирования данных двумя методами линейной регрессии и методом голосования. Так же мною проиллюстрированы результаты работы с предсказанием случайных чисел. Оба метода показали, что достаточно эффективны в выполнении данной задачи, но у каждого есть свои особенности применения Качество обоих методов сильно зависит от параметра target, т.е. от изменения первоначальной выборки. А при росте числа элементов качество модели линейной регрессии увеличивается, в то время как у метода голосования качество модели практически неизменно. Из этого следует вывод, что на маленьких наборах данных более эффективен окажется метод голосования. |