Отчет по Прикладном анализе 1. Лабораторна робота 1 з аналізу даних Зорін Володимир 32 варіант 32
 Скачать 136.36 Kb. Скачать 136.36 Kb.
|

|
Лабораторна робота №1 З аналізу даних Зорін Володимир 32 варіант
Розглядається задача Residential Building про прогнозування фактичних витрат на будівництво в Тегерані. Опис наведено за адресою https://archive.ics.uci.edu/ml/datasets/Residential+Building+Data+Set . Цільові дані (Actual construction costs) – Фактичні витрати на будівництво. Набір даних невеликий за розміром, 372 випадків. У кожному випадку набору даних є 105 атрибутів. Вони є: 8 фінансових та фізичних змінних 19 економічних помножених на 5 раз з запізнюванням. 2 вихідних змінних Розглядяємо вхідні змінні: V11 – Кількість виданих дозволів на будівництво. V13 – Індекс оптових цін (WPI) c будівельних матеріалів за базовий рік. Та вихідна змінна Actual construction costs – фактичні витрати на будівництво. Розбити дані на навчальну та тестову вибірки та перевірити їх репрезентативність.
Експериментальні дані розіб’ємо на навчальну та тестову вибірки. В навчальну включимо непарні рядки даних, а в тестову – парні. Для перевірки репрезентативності вибірок розрахуємо математичне сподівання (mean) та дисперсію (std) даних за кожною змінною. Результати перевірки вказують на приблизно однакові значення цих показників для навчальної та тестової вибірок, тому вважаємо їх репрезентативними. Візуально підтверджує цей висновок рисунок:  Рисунок 1. Розподіл даних навчальної та тестової вибірок Зобразити експериментальні дані у формі однофакторних залежностей. Однофакторні залежності вказують на сильну тенденцію збільшення витрат на будінвництво зі збільшенням кількості дозволів на будівництво, та тендецію збільшення витрат зі збільшенням індексу оптових цін на матеріали. 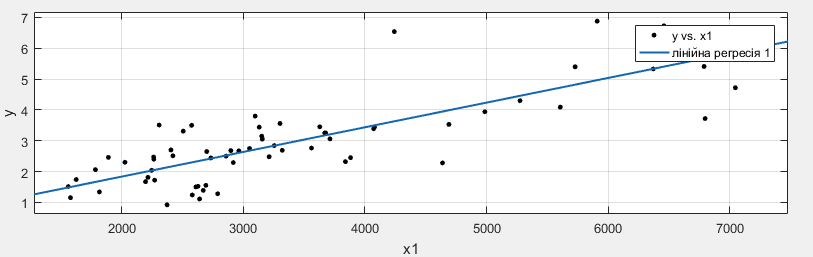 Рисунок 2. Залежність між х1 та у.  Рисунок 3. Залежність між х2 та у. Рисунок 3. Залежність між х2 та у.Знайдемо коефіцієнти лінійної регресії за допомогою такої програми: loadmydata; ResidentialBuildingDataSet = [V11,V13,V105]; data = ResidentialBuildingDataSet; vars = [1, 2, 3, 4]; x1 = data(:,vars(1)); x2 = data(:,vars(2)); y = data(:,vars(3)); %Формування навчальної та тестової вибірок: tr_set = data(1:2:end, vars); test_set = data(2:2:end, vars); %математичне сподівання mn_tr = mean(tr_set); mn_test = mean(test_set); %дисперсія despers_tr = std(tr_set); despers_test = std(test_set); % графік розподіл вибірки subplot(2,1,1) scatter(tr_set(:,1),tr_set(:,2),'b','o'); hold on scatter(test_set(:,1),test_set(:,2),'r','o'); l = legend('Навчальна вибірка','Тестова вибірка'); title(l,'Розподіл даних'); %Однофакторні залежності cftool(x1,y); cftool(x2,y); %Довжина вибірки: M_tr=length(tr_set); M_test=length(test_set); disp('Лінійний регресійний аналіз:') %model_1 y = a0 + a1x1 + a2x2 X_tr=[ones(M_tr,1) tr_set(:,1) tr_set(:,2)]; X_test=[ones(M_test,1) test_set(:,1) test_set(:,2)]; Y_tr=tr_set(:,3); Y_test=test_set(:,3); A=X_tr\Y_tr; %Розрахунок нев'язки на навчальній вибірці: pred_tr=X_tr*A; RMSE_tr=norm(Y_tr-pred_tr)/sqrt(M_tr); %Розрахунок нев'язки на тестовій вибірці: pred_test=X_test*A; RMSE_test=norm(Y_test-pred_test)/sqrt(M_test); %Побудова графіків: subplot(2,3,1) plot(Y_tr, pred_tr, 'ko', 'markersize', 5) hold on plot([0 10],[0 10], 'r-', 'linewidth', 1) xlabel('Експеримент') ylabel('Теорія') RMSE_str=num2str(RMSE_tr, 4); title(['Лінійна регресія, RMSE_t_r=', RMSE_str]) subplot(2,3,2) plot(Y_test, pred_test, 'ko', 'markersize', 5) hold on plot([0 10],[0 10], 'r-', 'linewidth', 1) xlabel('Експеримент') ylabel('Теорія') RMSE_str=num2str(RMSE_test, 4); title(['Лінійна регресія, RMSE_t_e_s_t=', RMSE_str]);  Рисунок 4. Модель 1 Аналогічно знайдемо інші регресійні моделі та запишемо результати у таблицю.
З таблиці, що наведено вище, бачимо що досліджувані моделі мають від 3 до 6 коефіцієнтів. Найкраща точність спостерігається для 3 моделі, що має 6 коефіцієнтів. Порівнюючи теоретичні результати з експериментальними даними бачимо, що для моделі 1 нев’язка майже рівномірно розподілена та теоритичні дані узгоджуються з експерементальними, наведено на рис.6. Найгірша точність для 1 моделі, яка має також 3 коефіцієнтів. Порівнюючи теоретичні результати з експериментальними даними бачимо, що для моделі 4 характерне невелике заниження витрат, наведено на рис.5. Рисунок.5 Найгірша модель 1.  Рисунок.6 Найкращамодель 3. Додаємо у постановку задачі ще одну вхідну зміну V12 (Індекс будівельних послуг (BSI) b за попередньо обраний базовий рік) . Вносимо зміну в модель 3 та обчислюємо цю модель.
 Рис.7 Модель 6. Отримана модель майже не відрізняється від попередньої моделі, при цьому трохи складніша від неї, має 7 коефіцієнтів та 3 змінних. Нев’язка розподілена так само і на попередній моделі. Теоретичні дані збігаються зі експериментальними. Тому модель можна вважати інтерпретабельну. Порівняння з іншими моделями. В таблиці розроблена модель порівнюється з конкурентними. Власна модель переважає за точність іншу модель. На рахунок складності, наша модель більш складна ніж інша, можливо тому і вдалося досягти кращої точності як у конкурентів.
|
 +0,007
+0,007
 0,0001
0,0001
 + 0,000094
+ 0,000094


