Лабораторная работа №1 Методы неинформированного (слепого) поиска
Цель: практическое закрепление понимания общих идей поиска в пространстве состояний и стратегий слепого поиска.
Содержание
1. Освоение теоретических основ слепого поиска (лекции, книга Рассел С, Норвиг П. Искусственный интеллект: современный подход, 2-е изд., М. «Вильямс», 2006, стр. 110–152). Стратегии, критерии, алгоритмы. Разбор алгоритмов различных стратегий поиска на конкретном примере в пошаговом режиме.
2. Рассмотрение принципов формализации задачи поиска и алгоритмов поиска для различных стратегий слепого поиска на конкретном примере. Программная реализация стратегий слепого поиска для конкретной задачи.
3. Теоретическая и экспериментальная оценка временной и емкостной сложности.
Основные сведения
Рассмотрим поиск в пространстве состояний на примере головоломки Ханойская башня в простейшем варианте –3x3 (3 стержня, 3 диска).
Формализация задачи поиска в пространстве состояний (возможны другие варианты представления состояний):
Диски обозначим буквами: Б (большой), С (средний), М (малый).
Состояние мира описывается состоянием трех стержней.
Состояние каждого стержня будем записывать в виде списка следующей структуры:
- 1-й элемент - номер стержня;
- остальные элементы – обозначения дисков на данном стержне в порядке снизу-вверх;
Тогда исходное состояние будет представлено следующим образом:
{(1, Б, С, М), (2), (3) }
Целевое состояние: {(1), (2), (3, Б, С, М)}
Правило перехода состояний (функция последователей): С любого стержня (списка), на котором имеется хотя бы один диск, можно снять (удалить) верхний диск (находящийся в конце списка) и поместить его наверх (в конец списка) любого из двух других списков. Ограничение – диск с большим диаметром не может помещаться выше диска меньшего диаметра.
Тогда у исходного состояния существует два последователя:
{(1, Б, С, М), (2), (3)} {(1, Б, С), (2, М), (3)}
{(1, Б, С), (2), (3, М)}
Состояние {(1, Б, С), (2, М), (3)} имеет следующих последователей:
{(1, Б, С), (2, М), (3)} {(1, Б), (2, М, С), (3)} (запрещенное!)
{(1, Б), (2, М), (3, С)}
{(1, Б, С, М), (2), (3)} (повторное!)
{(1, Б, С), (2), (3, М)}
. . . и т.д.
Далее надо рассмотреть решение задачи до конца с использованием различных стратегий.
Построить дерево поиска для стратегий «сначала в ширину», «сначала в глубину» . . .
Поиск (сначала) в ширину.
Сначала раскрывается вершина – корень в дереве поиска. Затем все вершины – непосредственные потомки корня и т.д. Вершины глубины d раскрываются раньше, чем вершины глубины (d+1). Пока есть хотя бы одна вершина глубины d – нельзя раскрывать вершину на глубине d+1.
Поиск в ширину может быть реализован алгоритмом General-Search, в котором функция построения очереди помещает вновь сгенерированные вершины в конец очереди.
function Breadth-First-Search(Problem) returns solution or failure
return General-Search(Problem, En-queue-At-End)
Cтратегия помещает вновь сгенерированные вершины в конец очереди.
Поиск в ширину:
– гарантирует нахождение решения, если оно существует (полная);
– первым всегда находит решение минимальной глубины.
Однако решение минимальной глубины не всегда имеет минимальную стоимость.
Недостаток поиска в ширину – большая сложность.
П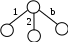 усть пространство поиска, в котором каждое состояние может быть раскрыто в b новых состояний. Тогда корень дерева генерирует b потомков, далее b2, затем b3 и так далее. усть пространство поиска, в котором каждое состояние может быть раскрыто в b новых состояний. Тогда корень дерева генерирует b потомков, далее b2, затем b3 и так далее.
Следовательно, если решение лежит на глубине d, для нахождения решения потребуется раскрыть 1 + b + b2 + b3 + … + bd вершин.
Порядок временной сложности поиска – O(bd).
Поиск (сначала) в глубину.
Поиск сначала в глубину всегда раскрывает одну из вершин на самом глубоком уровне дерева. Останавливается, когда поиск достигает цели или заходит в тупик (ни одна вершина не может быть раскрыта). В последнем случае выполняется возврат назад и раскрываются вершины на более верхних уровнях.
function Depth-First-Search(problem) returns solution or failure
General-Search(problem, En-queue-At-Front)
Поиск в глубину эффективнее, когда задача имеет много решений, так как в этом случае высока вероятность найти решение, исследовав малую часть пространства поиска.
Недостаток поиска в глубину – способность углубляться в неверном направлении. Многие задачи имеют очень глубокие или даже бесконечные деревья поиска, в этом случае поиск в глубину никогда не может восстановиться после неудачного выбранного вблизи корня направления. Поиск в глубину обычно реализуется с помощью рекурсивной функции.
Сложность метода поиска в глубину.
Для пространства состояний с коэффициентом ветвления b максимальной глубины m пространства состояний поиск в глубину требует хранение b*m вершин, поскольку нужно хранить только один путь из корня в вершину, лист и множество оставшихся ждущих раскрытия потомков.
Поиск по критерию стоимости.
Поиск в ширину всегда находит целевое состояние минимальной глубины в дереве поиска, однако ему не всегда соответствует решение минимальной стоимости.
Поиск по критерию стоимости – модифицированная стратегия поиска в ширину, при которой всегда раскрывается вершина с минимальной стоимостью пути. Пусть
g(n) – функция стоимости пути в вершину n.
Поиск в ширину является частным случаем поиска по критерию стоимости, когда стоимость равна глубине.
g(n) = depth(n).
П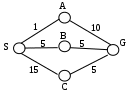 ример: Рассмотрим пути поиска в графе (рис.) ример: Рассмотрим пути поиска в графе (рис.)
Найти путь минимальной стоимости из S в G.

  
C
B
A
g(n)=15
g(n)=5
g(n)=1
g(G) = 1+10=11
Попали в целевое состояние G через A, стоимость пути = 11. Смотрим, есть ли нераскрытые вершины, у которых путь меньше полученного значения.
Находим путь BG.
g(n) = 5+5=10 – более хорошее решение.
Поиск по критерию стоимости находит оптимальное решение, т. е. путь минимальной стоимости, если стоимость пути не может уменьшаться в процессе движения вдоль пути.
g(successor(n)) >=g(n)
Ограниченный по глубине поиск.
Ограниченный по глубине поиск, чтобы избежать недостатков поиска в глубину, накладывает ограничения на максимальную глубину пути.
Поиск не оптимален. Если выбрано очень малое ограничение глубины, данная стратегия даже неполна.
Временная и емкостная сложность аналогична поиску в глубину. Временная сложность O(bL), где L – ограничение глубины.
Емкостная сложность – O(b*L).
Итеративно углубляющийся поиск.
В ограниченном по глубине поиске не всегда удается хорошо задать ограничения. В рассмотренном выше примере ограничение глубины выбиралось исходя их размерности пространства поиска. Вместе с тем может быть известна, например, максимальная длина пути для произвольной пары состояний в пространстве состояний – диаметр пространства состояний. Очевидно, что диаметр пространства является наилучшим ограничением глубины в поиске с ограничениями по глубине. Однако для большинства задач он также не известен. Итеративно углубляющийся поиск – стратегия, которая обходит выбор лучшего ограничения глубины, пробуя все возможные ограничения.
function Iterative-Deepening-Search(problem) returns solution or failure
for depth 0 to ∞ do
if Depth-Limited-Search(problem, depth)
successed then return solution
end
return failure
Двунаправленный поиск
Предполагает встречное движение от исходного состояния и целевого состояния.
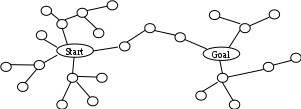
Пусть b – коэффициент ветвления. Пусть также решение находится на глубине d, тогда для нахождения решения потребуется: О(2*bd/2)=O(bd/2)
Если b=10, а d=6, тогда поиск в ширину требует 1111111 шагов. Двунаправленный поиск с каждой стороны пройдет на глубину 3, и при этом будет сгенерировано 2222 вершин.
Для реализации двунаправленного поиска необходимо:
Иметь функцию, определяющую предшественников для каждого состояния.
Способ эффективной проверки – не находится ли новая вершина в дереве другой половины поиска.
Выбрать вид поиска в каждой половине двунаправленного поиска, (лучше – поиск в ширину).
Повторить понятия временной и емкостной сложности и пояснить их оценку для данной задачи.
Основными мерами сложности алгоритма являются время, необходимое для его реализации, и объем требуемой памяти. При этом каждому классу задач можно сопоставить число, характеризующее объем входных данных, которое принято называть размером входа. Очевидно, что сложность алгоритма является функцией размера входа.
Временной сложностью алгоритма называется время, затрачиваемое на вычисление результата, выраженное как функция размера входа.
Емкостная сложность - общая емкость памяти, использованной в процессе реализации алгоритма, как функция размера входа.
Сложность алгоритма может быть различной и при фиксированном размере входа, но различных входных данных. Поэтому различают сложность в худшем и в среднем случае. Сложность в худшем случае - это максимальная при данном размере входа сложность. Средняя сложность - средняя по всем входам данного размера сложность.
Временная сложность в худшем случае - это функция T(n), равная максимальной (по всем входам размера n) из сумм времен, затраченных на каждую сработавшую команду (оператор).
Емкостная сложность в худшем случае - это функция S(n), равная максимальной (по всем входам размера n) из сумм емкостей всех ячеек (элементов) памяти к которым было обращение.
Для точного теоретического определения временной и емкостной сложности требуется знать времена выполнения каждой команды (оператора) и объем памяти, используемый каждой переменной. Так как эти значения зависят от конкретной вычислительной машины, в теории сложности алгоритмов принято оценивать порядок сложности.
Говорят, что функция f(n) имеет сложность порядка g(n), если существуют такие положительные константы c и n0, что для всех n n0 , f(n) c g(n). Этот факт записывается так: f(n) есть O(g(n)). Обычно рассматриваются положительные функции натуральных чисел. Например, функция f(n) = 10n3 есть O(n3), т.к. существуют c=10 и n0 = 1, для которых 10n3 10n3 . Неверно, что 10n3 есть O(n2), так как для любого сколь угодно большого наперед заданного значения константы c найдется такое значение n0 аргумента, что f(n) c g(n) для всех n n0.
При оценке порядка временной сложности определяется зависимость числа шагов в алгоритме от размера входа. Шагом считается такой фрагмент алгоритма, время реализации которого не зависит от размера входа, а число реализаций этого фрагмента зависит от размера входа. Например, шагом является тело цикла, независимо от числа содержащихся в нем операторов, если оно не содержит вложенных циклов, а параметр цикла связан с размером входа.
При определении порядка емкостной сложности, в качестве единицы необходимо выбрать некоторый элементарный в данном классе алгоритмов объект. При этом точный объем памяти (в байтах), занимаемой одним литералом, зависит от выбранных типов и структур данных и не влияет на порядок сложности.
При теоретическом анализе порядка сложности алгоритмов принято оценивать сложность в худшем случае. Теоретическая оценка средней сложности, как правило, весьма затруднительна, т.к. предполагает учет всевозможных комбинаций входных данных и вероятностей их появления. Она может быть получена (в некотором приближении) экспериментальным путем с помощью программно реализованного алгоритма.
При оценке сложностей можно использоваться различные критерии.
Равномерный весовой критерий предполагает, что каждая команда (оператор) затрачивает одну единицу времени и каждая переменная в алгоритме занимает одну ячейку памяти, независимо от принимаемых ей значений.
Алгоритм может иметь существенно различные временные и емкостные сложности в зависимости от используемого весового критерия.
Пример. Определить временную и емкостную сложность алгоритма сортировки массива методом «пузырька» при равномерном весовом критерии.
Решение. В соответствии с данным методом для всех элементов массива, начиная со второго, последовательно выполняется «всплывание», при котором текущий элемент, если он меньше предыдущего, меняется с ним местами. Обозначим i - текущий номер элемента при просмотре массива в глубину, j - номер текущего элемента при "всплывании" (процедура elem_up), A(j) - j-ый элемент массива, n - число элементов в массиве.
program Sort;
procedure elem_up (i: integer); {процедура «всплывание» элемента}
begin
j := i
while (j > 1) and (A(j) < A(j-1)) do
begin
X:= A(j); {перестановка соседних элементов}
A(j):=A(j-1);
A(j-1):=X;
j := j-1;
end
end;
begin {основной цикл программы}
for i := 2 to n do elem_up(i);
end.
Временная сложность при равномерном весовом критерии. Очевидно, что размером входа для данного алгоритма следует считать число n элементов в массиве, а шагом алгоритма - тело цикла в процедуре «всплывание». В теле основной программы имеем (n-1) проходов по циклу. В процедуре elem_up ("всплывание" элемента) - в худшем случае выполняется i проходов по циклу. Тогда, общее число шагов в алгоритме равно:
n
i = (n+2)(n-1)/2 = (n2+n-2)/2 .
i=2
Таким образом, временная сложность алгоритма при равномерном весовом критерии есть O(n2).
Емкостная сложность при равномерном весовом критерии очевидно определяется размером n массива, поэтому есть O(n).
Задание
Рассматривается задача «Головоломка 8-ка».
Задана доска с 8 пронумерованными фишками и с одним пустым участком.
Фишка, смежная с пустым участком, может быть передвинута на этот участок. Требуется достичь указанного целевого состояния.
Начальное состояние:
Целевое состояние:
Необходимо:
– предложить выбрать формализацию состояний (имея в виду дальнейшее программирование) и
– начать в ручном режиме построение дерева для различных стратегий (построить 30 вершин)…
Обсудить возможные представления состояний в программе, функции последователей, особенности экспериментального определения временной и емкостной сложности в программе.
Состояния. Описание состояния определяет местонахождение каждой из этих 8 фишек и пустого участка на одном из 9 квадратов.
Начальное состояние задано (см. вариант задания).
Функция последователей. Эта функция формирует допустимые состояния, которые являются результатом попыток осуществления указанных четырех действий теоретически возможных ходов (Left, Right, Up или Down).
Проверка цели. Она позволяет определить, соответствует ли данное состояние целевой конфигурации, которая задана (см. вариант задания).
Стоимость пути. Каждый этап имеет стоимость 1, поэтому стоимость пути равна количеству этапов пути.
Рассматриваются методы поиска, в которых используется явно заданное дерево поиска, создаваемое с помощью начального состояния и функции последователей, которые совместно задают пространство состояний.
Существует множество способов представления узлов. Предполагается, что узел – это «пятерка»:
State. Состояние в пространстве состояний, которому соответствует данный узел;
Parent-Node. Указатель на родительский узел;
Action. Действие, которое было применено к родительскому узлу для формирования данного узла;
Path-Cost. Стоимость пути от начального состояния до данного узла g(n);
Depth. Количество этапов пути от начального состояния (глубина).
Необходимо различать узлы и состояния. Два разных узла могут включать одно и то же состояние, если оно формируется с помощью двух различных путей поиска.
Предлагается коллекцию узлов дерева реализовывать в виде очереди.
Общий алгоритм поиска в дереве представлен в книге Рассел С, Норвиг П. Искусственный интеллект: современный подход, 2-е изд., М. «Вильямс», 2006. – 1408 с. на страницах 125–126.
Порядок выполнения
1. Доработка алгоритмов. Выбор структур данных. Разработка и отладка программы в соответствии с полученным вариантом задания.
2. Проведение эксперимента.
3. Подготовка отчета
Реализовать (на любом императивном языке программирования) алгоритмы слепого поиска для стратегий, начального и целевого состояния, заданных в соответствии с вариантом (см. табл.).
При программной реализации возможно выполнение задания бригадами 3-4 человека. Номер бригады равен номеру варианта.
Варианты индивидуальных заданий для задачи «Головоломка 8-ка»
Вариант №
|
Начальное состояние
|
Целевое состояние
|
Стратегии поиска
|
|
1
|
а
|
А
|
в глубину, в ширину
|
|
2
|
б
|
Б
|
в глубину, с ограничением глубины
|
|
3
|
в
|
В
|
в глубину, с итеративным углублением
|
|
4
|
г
|
Г
|
в глубину, двунаправленный,
|
|
5
|
д
|
Б
|
в глубину, по критерию стоимости
|
|
6
|
е
|
В
| в ширину, с ограничением глубины |
|
7
|
ж
|
Г
| в ширину, двунаправленный, |
|
8
|
з
|
А
| в ширину, с итеративным углублением |
|
9
|
а
|
Г
|
в ширину, по критерию стоимости
|
|
10
|
б
|
В
|
с ограничением глубины, по критерию стоимости
|
|
11
|
в
|
А
| |
|
12
|
г
|
Б
|
с ограничением глубины, двунаправленный
|
|
13
|
д
|
А
|
с итеративным углублением, по критерию стоимости
|
|
14
|
е
|
Б
|
с итеративным углублением, двунаправленный
|
|
15
|
ж
|
В
|
по критерию стоимости, двунаправленный
|
|
16
|
з
|
Г
|
с ограничением глубины, в ширину
|
|
Описание стратегий поиска – в книге Рассел С, Норвиг П. Искусственный интеллект: современный подход, 2-е изд., М. «Вильямс», 2006. – 1408 с.:
Название стратегии поиска
|
Номера страниц
|
В ширину
|
128–129
|
В глубину
|
130–131
|
По критерию стоимости
|
129–130
|
С ограничением глубины
|
131–132
|
С итеративным углублением
|
133–135
|
Двунаправленный
|
135–136
|
Начальные состояния:
|
а)
|
б)
|
в)
|
г)
|
д)
|
е)
|
ж)
|
з)
|
|
|
|
|
Целевые состояния:
|
А)
|
Б)
|
В)
|
Г)
|
Состояния. Описание состояния определяет местонахождение каждой из этих 8 фишек и пустого участка на одном из 9 квадратов.
Начальное состояние задано.
Функция последователей. Эта функция формирует допустимые состояния, которые являются результатом попыток осуществления указанных четырех действий теоретически возможных ходов (Left, Right, Up или Down).
В программе должна быть реализована функция определения повторного состояния.
Функция достижения целевого состояния. Она позволяет определить, соответствует ли данное состояние целевой конфигурации, которая задана.
Программа должна поддерживать пошаговый режим (очередной шаг выполняться по нажатию клавиши) и выводить на каждом шаге:
– вновь добавленные после раскрытия вершины,
– выявленные повторные вершины,
– текущее состояние «каймы» (вершин, ожидающих раскрытия);
– текущую вершину, выбираемую для раскрытия на данном шаге;
– факт достижения целевого состояния.
Содержание отчета
1) постановка задачи;
2) описание выбранных структур данных (классов), представление функции определения последователей;
3) описание алгоритма;
4) исходный код;
5) результат работы, включая экспериментальные оценки временной (количества шагов) и емкостной (единиц памяти) сложности для своего варианта.
|
 Скачать 170 Kb.
Скачать 170 Kb.