БД_лаб2. Лабораторная работа 2 Создание концептуальной и логической модели. Цель работы
 Скачать 159.5 Kb. Скачать 159.5 Kb.
|

|
Лабораторная работа № 2 Создание концептуальной и логической модели. Цель работы: изучить основы концептуального проектирования и освоить способ реализации проекта в виде логические модели в среде ErWin. Теоретические сведения. Процесс проектирования базы данных принято разделять на три основные фазы: концептуальное проектирование – построение модели на основе информации, полученной при изучении анализируемой области независимо от ее реализации. Основой модели является определение типов важнейших сущностей и существующих между ними связей. логическое проектирование – преобразование концептуального представления в логическую структуру базы данных, включая проектирование отношений; физическое проектирование – создание описания конкретной реализации базы данных (с помощью выбранной СУБД): описание структуры хранения данных и методов доступа. Задачей концептуального проектирования БД является разбиение проекта на группу относительно небольших (и более простых) задач исходя из представлений об этой предметной области различных пользователей. Обычно представление пользователя отражает некоторую функциональную область в деятельности предприятия – например, производство, маркетинг, сбыт, управление кадрами, складской учет. На этом этапе разработки должны быть выполнены следующие задания. определение типов сущностей, определение типов связей, определение атрибутов и связывание их с типами сущностей и связей определение доменов атрибутов, определение атрибутов, являющихся потенциальными и первичными ключами, специализация или генерализация топов сущностей (необязательный этап), создание диаграммы «сущность-связь», обсуждение локальных концептуальных моделей с пользователями. Следующий этап, логическое проектирование, является продолжением концептуального проектирования и представляет собой процесс создания информационной модели работы предприятия на основе отдельных концептуальных моделей данных, отражающей обобщенное представление всех пользователей о предметной области приложения. Более детально рассмотрим процесс логического проектирования. Структурные ограниченияВ предыдущей лабораторной работе были даны понятия идентифицирующих и неидентифицирующих связей между атрибутами и их мощностей. Рассмотрим влияние связей на ключевые атрибуты. Для идентифицирующей связи можно указать обязательность (Nulls). В случае обязательной связи (No Nulls) при генерации схемы БД атрибут внешнего ключа получит признак NOT NULL, несмотря на то, что внешний ключ не войдет в состав первичного ключа дочерней сущности. В случае необязательной связи (Nulls Allowed) внешний ключ может принимать значение NULL. Имя роли (функциональное имя) – это синоним атрибута внешнего ключа, который показывает, какую роль играет атрибут в дочерней сущности.  Рис.2.4. Имя ролей внешних ключей. В сущности Сотрудник внешний ключ Номер отдела имеет функциональное имя «Где работает», которое показывает, какую роль играет этот атрибут в сущности. По умолчанию в списке атрибутов показывается только имя роли. Для отображения полного имени атрибута следует в контекстном меню для диаграммы выбрать пункт Display Options/Entities и затем включить опцию Rolename/Attribute. Примером обязательности присвоения имен ролей являются рекурсивные связи («рыболовный крючок» - fish hook), когда одна и та же сущность является и родительской и дочерней одновременно. При задании рекурсивной связи атрибут должен мигрировать в качестве внешнего ключа в состав неключевых атрибутов той же сущности. Атрибут не может появиться дважды в одной сущности под одним именем, поэтому обязательно должен получить имя роли. Сущность Сотрудник содержит атрибут первичного ключа Табельный номер. Чтобы сослаться на руководителя сотрудника следует создать рекурсивную связь (руководит/подчиняется) и присвоить имя роли («Руководитель»). Рекурсивная связь может быть только неидентифицирующей. В противном случае внешний ключ должен был бы войти в состав первичного ключа и получить при генерации схемы признак NOT NULL. Это сделало бы невозможным построение иерархии – у дерева подчиненности должен быть корень – сотрудник, который никому не подчиняется в рамках данной организации. Такой вид рекурсивной связи называется иерархической рекурсией и задает связь, когда руководитель (экземпляр родительской сущности) может иметь множество подчиненных (экземпляров дочерней сущности), но подчиненный имеет только одного руководителя. Существует также другой вид рекурсии – сетевая рекурсия. Например, когда руководитель имеет множество подчиненных и подчиненный может иметь множество руководителей. Сетевая рекурсия задает паутину отношений между экземплярами родительской и дочерней сущностей. Это случай, когда сущность находится сама с собой в связи многие-ко-многим. Разрешение связи многие-ко-многим будет описана в следующих разделах. Другим примером обязательного применения имен ролей является случай, когда два или более атрибутов одной сущности определены по одной и той же области, т.е. они имеют одинаковую область значений, но разный смысл. Н  апример, сущность Продажа валюты содержит информацию об акте обмена валюты, в котором участвуют две валюты – проданная и купленная. Информация о валютах содержится в сущности Валюта. Следовательно, сущности Продажа валюты и Валюта должны быть связаны дважды и первичный ключ – Номер валюты должен дважды мигрировать в сущность Валюта в качестве внешнего ключа с именами ролей Проданная и Купленная. апример, сущность Продажа валюты содержит информацию об акте обмена валюты, в котором участвуют две валюты – проданная и купленная. Информация о валютах содержится в сущности Валюта. Следовательно, сущности Продажа валюты и Валюта должны быть связаны дважды и первичный ключ – Номер валюты должен дважды мигрировать в сущность Валюта в качестве внешнего ключа с именами ролей Проданная и Купленная.Рис. 2.5. Случай обязательности имен ролей Пример реализации сетевой рекурсии. Структура моделирует родственные отношения между членами семьи любой сложности. Атрибут Тип отношения может принимать значения «отец-сын», «мать-дочь», «дед-внук», «свекровь-невестка», «тесть-зять» и т.д. Поскольку родственные отношения связывают всегда двух людей, от сущности Родственник к сущности Родственные отношения установлены две идентифицирующие связи с именами ролей «Старший» и «Младший». Каждый член семьи может быть в родственных отношениях с любым другим членом семьи, более того, одну и ту же пару родственников могут связывать разные типы родственных отношений. Если атрибут мигрирует в качестве внешнего ключа более чем на один уровень, то на первом уровне отображается полное имя внешнего ключа (имя роли + базовое имя атрибута), на втором и более только имя роли. 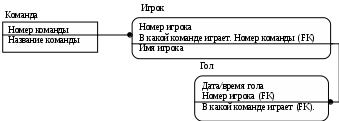 Рис. 2.6. Миграция имен ролей. Атрибут внешнего ключа Номер команды сущности Игрок имеет имя роли «В какой команде играет». На следующем уровне, в сущности Гол, отображается только имя роли соответствующего атрибута внешнего ключа (В какой команде играет). Правила ссылочной целостности (referential integrity, RI) – логические конструкции, которые выражают бизнес-правила использования данных и представляют собой правила вставки, замены и удаления. При генерации схемы БД на основе опций логической модели, задаваемых во вкладке Rolename/RI Actions, будут сгенерированы правила ссылочной целостности, которые должны быть предписаны для каждой связи, и триггеры, обеспечивающие ссылочную целостность. Триггеры представляют собой программы, выполняемые всякий раз при выполнении команд вставки, замены или удаления (INSERT, UPDATE или DELETE). В предыдущем примере Игрок не может существовать без команды (атрибут первичного ключа В какой команде играет. Номер команды не может принимать значение NULL), следовательно, нужно либо запретить удаление команды, пока в ней числится хотя бы один игрок (для удаления команды сначала нужно удалить всех играков), либо сразу удалить вместе с командой всех ее играков. Такие правила удаления называются «ограничение» и «каскад» (Parent RESTRICT и Parent CASCADE). Сущности Игрок и Гол, в свою очередь, тоже связаны идентифицирующей связью и в случае удаления каскадом команды будут удалены все игроки команды и все голы, которые они забивали. С 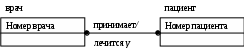 вязь многие-ко-многим возможно только на уровне логической модели данных. Например, врач может принимать много пациентов, пациент может лечиться у нескольких врачей. Такая связь обозначается сплошной линией с двумя точками на концах. вязь многие-ко-многим возможно только на уровне логической модели данных. Например, врач может принимать много пациентов, пациент может лечиться у нескольких врачей. Такая связь обозначается сплошной линией с двумя точками на концах.Рис. 2.7. Связь многие-ко-многим. При переходе к физическому уровню Erwin автоматически преобразует связь многие-ко-многим, добавляя новую таблицу и устанавливая две новые связи один-ко-многим от старых к новой таблице. Новой таблице автоматически присваивается имя «Имя1_Имя2». Н  о лучше разрешать связь многие-ко-многим осмысленно, добавляя в логическую модель таблицу. В предыдущем примере имеет смысл ввести таблицу Визит. о лучше разрешать связь многие-ко-многим осмысленно, добавляя в логическую модель таблицу. В предыдущем примере имеет смысл ввести таблицу Визит.Рис. 2.8. Дополнение модели при разрешении связи многие-ко-многим. Типы сущностей и иерархия наследования. Различают несколько типов зависимых сущностей. Характеристическая – зависимая дочерняя сущность, которая связана только с одной родительской и по смыслу хранит информацию о характеристиках родительской сущности. Например, Сотрудник – Хобби. Ассоциативная – сущность, связанная с несколькими родительскими сущностями. Такая сущность содержит информацию о связях сущностей. Примером является Визит. Категориальная – дочерняя сущность в иерархии наследования. Иерархия наследования (или иерархия категорий) представляет собой особый тип объединения сущностей, которые разделяют общие характеристики. Например, в организации работают служащие, занятые полный рабочий день (постоянные служащие) и совместители. Из их общих свойств можно сформировать обобщенную сущность (родовой предок) Сотрудник, чтобы представить информацию, общую для всех типов служащих. Специфическая для каждого типа информация может быть расположена в категориальных сущностях (потомках) Постоянный сотрудник и Совместитель. Для каждой категории можно указать дискриминатор – атрибут родового предка, который показывает, как отличить одну категориальную сущность от другой (атрибут Тип). И 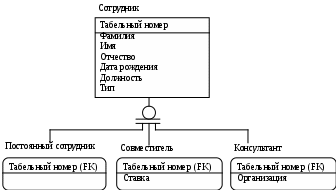 ерархии категорий делятся на два типа – полные и неполные. В полной категории одному экземпляру родового предка (сущность Служащий) обязательно соответствует экземпляр в каком-либо потомке, т.е. в примере служащий обязательно является либо совместителем, либо консультантом, либо постоянным сотрудником. ерархии категорий делятся на два типа – полные и неполные. В полной категории одному экземпляру родового предка (сущность Служащий) обязательно соответствует экземпляр в каком-либо потомке, т.е. в примере служащий обязательно является либо совместителем, либо консультантом, либо постоянным сотрудником.Рис. 2.9. Иерархия наследования. Полная категория. Если категория еще не выстроена полностью и в родовом предке могут существовать экземпляры, которые не имеют соответствующих экземпляров в потомках, то такая категория будет неполной. На рисунке изображена неполная категория. Д 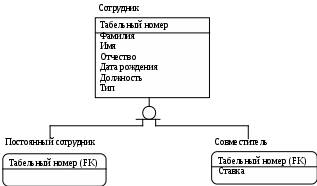 ля редактирования категорий нужно в контекстном меню для категории выбрать пункт Subtype Relationship Editor. ля редактирования категорий нужно в контекстном меню для категории выбрать пункт Subtype Relationship Editor. Рис. 2.10. Иерархия наследования. Неполная категория. Вследствие неправильной интерпретации смысла некоторых связей может быть построена ER-модель, которая не будет являться истинным представлением реального мира. Возникающие при этом проблемы называются ловушками соединения. Ловушка разветвления имеет место в том случае, когда модель отображает связь между типами сущностей, но путь между отдельными сущностями этого типа определен неоднозначно. Ловушка разрыва появляется в том случае, когда в модели предполагается наличие связи между типами сущностей, но не существует пути между отдельными сущностями этих типов. Основных понятий ER-моделирования недостаточно для разрешения таких ситуаций, поэтому появилась расширенная ER-модель(или EER-модель), дополненная новыми концепциями, такими как специализация/генерализация и категоризация. EER-модель Рассмотрим сначала понятия суперкласса и подкласса, а также процесс наследования атрибутов, которые являются основными в EER-моделировании. Суперкласс – это тип сущности, включающий разные подклассы, которые необходимо представить в модели данных. Подкласс является типом сущности, который исполняет отдельную роль, а также является членом суперкласса. Существует две причины введения понятий суперклассов и подклассов в ER-модель. Во-первых, это позволяет избежать повторного описания сходных понятий, а во-вторых, при проектировании в базы данных включается больше семантической информации в форме, более привычной для многих людей. Выбор представления сущностей может производится разными путями, применяя операции специализации/генерализации или используя понятие категории. Специализация представляет собой нисходящий подход к определению множества суперклассов и связанных с ними подклассов. Это процесс увеличения различий между отдельными членами типа сущности за счет выделения их отличительных характеристик. Генерализация представляет собой восходящий подход, который позволяет создать обобщенный суперкласс на основе различных исходных подклассов. Это процесс сведения различий между сущностями к минимуму путем выделения их общих характеристик. Каждая связь «суперкласс/подкласс» в иерархии специализации/генерализации обладает единственным и отличным от других суперклассом. Однако в некоторых ситуациях может потребоваться смоделировать связь «суперкласс/подкласс», включающую сразу несколько разных суперклассов. В этом случае создаваемый подкласс будет называться категорией. Категоризация это моделирование одного подкласса со связью, которая охватывает несколько разных суперклассов. Ключи. Каждый экземпляр сущности должен быть уникален и отличаться от других атрибутов. Первичный ключ(primary key) – это атрибут или группа атрибутов, однозначно идентифицирующая экземпляр сущности. На диаграмме эти атрибуты располагаются в списке атрибутов выше горизонтальной линии. Признак первичного ключа в диалоге Attribute Editor включается флажком Primary Key в закладке General. В одной сущности могут оказаться несколько атрибутов, претендующих на роль первичного ключа. Такие претенденты называются потенциальными ключами(candidate key). Ключи могут быть сложными, т.е. содержащими несколько атрибутов. Для того, чтобы стать первичным, потенциальный ключ должен удовлетворять ряду требований: Уникальность. Два экземпляра не должны иметь одинаковых значений возможного ключа. Компактность. При выборе первичного ключа предпочтение должно отдаваться более простым ключам, т.е. ключам, содержащим меньшее количество атрибутов. Атрибуты ключа не должны содержать нулевых значений. Значение атрибутов ключа не должно меняться в течение всего времени существования экземпляра сущности. Каждая сущность должна иметь по крайней мере один потенциальный ключ. Такой ключ становится первичным. Если сущность имеет более одного возможного ключа, то остальные ключи называются альтернативными. Erwin позволяет выделить атрибуты альтернативных ключей, и по умолчанию в дальнейшем при генерации схемы БД по этим атрибутам будет генерироваться уникальный индекс. При работе ИС часто бывает необходимо обеспечить доступ к нескольким экземплярам сущности, объединенным каким-либо одним признаком. Для повышения производительности в этом случае используются неуникальные индексы. Атрибуты, участвующие в неуникальных индексах, называются инверсионными входами(Inversion Entries). Erwin генерирует неуникальный индекс для каждого Inversion Entry. Создать альтернативные ключи и инверсионные входы можно в закладке Key Group диалога Attribute Editor. На диаграмме атрибуты альтернативных ключей обозначаются как (АКn.m), где n – порядковый номер ключа, m – порядковый номер атрибута в ключе. Инверсионные входы обозначаются как (IEn.m), где n – порядковый номер входа, m – порядковый номер атрибута.  Рис. 2.11. Сущность «Сотрудник» с отображением ключей. Внешние ключи(Foreign Key) создаются автоматически, когда связь соединяет сущности: связь образует ссылку на атрибуты первичного ключа в дочерней сущности и эти атрибуты образуют внешний ключ в дочерней сущности (миграция ключа). Атрибуты внешнего ключа обозначаются символом (FK) после своего имени. Нормализация данных. Нормализация – процесс проверки и реорганизации сущностей и атрибутов с целью удовлетворения требований к реляционной модели данных. Нормализация позволяет быть уверенным, что каждый атрибут определен для своей сущности, значительно сократить объем памяти для хранения информации и устранить аномалии в организации хранения данных. В результате проведения нормализации должна быть создана структура данных, при которой информация о каждом факте хранится только в одном месте. Процесс нормализации сводится к последовательному приведению структуры данных к нормальным формам – формализованным требованиям к организации данных. Известны шесть нормальных форм, но на практике ограничиваются использованием трех из них. Первая нормальная форма (1FN). Сущность находится в первой нормальной форме в том случае, если все атрибуты содержат атомарные значения. 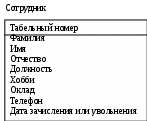 Рис. 2.12. Ненормализованная сущность «Сотрудник» Для приведения сущности к первой нормальной форме следует разделить сложные атрибуты на атомарные. Для этого необходимо: создать новую сущность, перенести в нее все «повторяющиеся» атрибуты, выбрать возможный атрибут для нового PK (или создать новый PK), установить идентифицирующую связь от прежней сущности к новой. 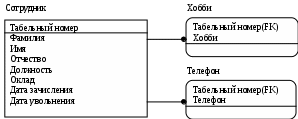 Рис.2.13. Сущность «Сотрудник», приведенная к первой нормальной форме. Вторая нормальная форма (2NF). Сущность находится во второй нормальной форме, если она находится в первой нормальной форме и каждый неключевой атрибут полностью зависит от первичного ключа (не должно быть зависимости от части ключа). Вторая нормальная форма имеет смысл только для сущностей, имеющих сложный первичный ключ.  Рис. 2.14. Сущность «Проект» Атрибуты Фамилия, Имя, Отчество, Должность зависят только от атрибута Табельный номер руководителя. Для приведения сущности ко второй нормальной форме следует выделить атрибуты, которые зависят только от части первичного ключа в новую сущность и установить идентифицирующую связь. 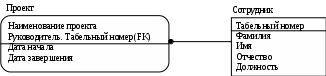 Рис. 2.15. Сущность «Проект», приведенная ко второй нормальной форме. Вторая нормальная форма позволяет избежать аномалий при операциях обновления, вставки и удаления записей. Третья нормальная форма (3NF). Сущность находится в третьей нормальной форме, если она находится во второй нормальной форме и никакой неключевой атрибут не зависит от другого неключевого атрибута (не должно быть взаимозависимости между неключевыми атрибутами). На рис 2.13 в сущности «Сотрудник» неключевой атрибут Оклад зависит от неключевого атрибута Должности. Для приведения сущности к третьей нормальной форме следует создать новую сущность и перенести в нее атрибуты с одной и той же зависимостью от неключевого атрибута и установить связь. 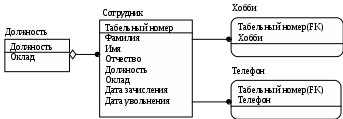 Рис. 2.16. Сущность «Сотрудник», приведенная к третьей нормальной форме. К сожалению, Erwin не содержит полного алгоритма нормализации и не может проводить нормализацию автоматически. В результате нормализации все взаимосвязи данных становятся правильно определенными, исключаются аномалии при операциях с данными, модель данных легче поддерживать. Однако часто нормализация данных не ведет к повышению производительности ИС в целом. Поэтому в целях повышения производительности при переходе на физический уровень приходится сознательно отходить от нормальных форм проводить операцию денормализации) для того, чтобы использовать возможности конкретного сервера или ИС в целом. Домены. Домен можно определить как совокупность значений, из которых берутся значения атрибутов. Каждый атрибут может быть определен только на одном домене, но на каждом домене может быть определено множество атрибутов. В понятие домена входит не только тип данных, но и область значений данных. В Erwin домен может быть определен только один раз, и использоваться как в логической, так и в физической модели. Например, можно определить домен «Возраст» как положительное целое число и определить атрибут Возраст сотрудника как принадлежащий этому домену. Для создания домена в логической модели служит диалог Domain Dictionary Editor. Его можно вызвать из меню Edit / Domain Dictionary по кнопке, расположенной в верхней левой части закладки General диалога Attribute Editor. Можно связать домен с иконкой и снабдить комментарием. Erwin имеет специальный инструмент, который значительно облегчает создание новых атрибутов в модели, используя описание доменов, -Independent Attribute Browser. Этот диалог вызывается с помощью CTRL+B. Лабораторное задание Создайте EER-модель для представления требований к данным вашей задачи: а) выделите типы сущностей; б) выделите типы связей и определите для них показатели кардинальности и степень участия сторон; в) определите потенциальные и первичные ключи сущностей; г) выполните специализацию/генерализацию типов сущностей (там, где это необходимо); д) нарисуйте EER-диаграмму. Укажите все допущения, которые были сделаны при создании этой EER-модели. Варианты заданий
|