РВС. 7 РВС. Лабораторная работа 7 Гистограмма Распределенные вычислительные системы Специальность 10. 03. 01 Информационная безопасность
 Скачать 144.74 Kb. Скачать 144.74 Kb.
|

|
Министерство цифрового развития, связи и массовых коммуникаций Российской Федерации Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение «Московский технический университет связи и информатики»  Кафедра “Математическая кибернетика и информационные технологии” Лабораторная работа №7 «Гистограмма» «Распределенные вычислительные системы» Специальность 10.03.01 – Информационная безопасность Выполнил: студент группы БИБ2003 Абдиев Н. Проверил: Соловьёв А.С. Москва 2021 Цель работы: изучить и реализовать эффективный алгоритм для вычисления гистограммы входного массива чисел из определенного диапозона. Исходный код: #include #define NUM_BINS 4096 #define CUDA_CHECK(ans) \ { gpuAssert((ans), __FILE__, __LINE__); } inline void gpuAssert(cudaError_t code, const char* file, int line, bool abort = true) { if (code != cudaSuccess) { fprintf(stderr, "GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line); if (abort) exit(code); } } __global__ void histogram_kernel(unsigned int* input, unsigned int* bins, unsigned int num_elements, unsigned int num_bins) { unsigned int tid = blockIdx.x * blockDim.x + threadIdx.x; extern __shared__ unsigned int bins_s[]; for (unsigned int binIdx = threadIdx.x; binIdx < num_bins; binIdx += blockDim.x) { bins_s[binIdx] = 0; } __syncthreads(); //Гистограмма for (unsigned int i = tid; i < num_elements; i += blockDim.x * gridDim.x) { atomicAdd(&(bins_s[input[i]]), 1); } __syncthreads(); //Зафиксировать в глобальной памяти for (unsigned int binIdx = threadIdx.x; binIdx < num_bins; binIdx += blockDim.x) { atomicAdd(&(bins[binIdx]), bins_s[binIdx]); } } __global__ void convert_kernel(unsigned int* bins, unsigned int num_bins) { unsigned int tid = blockIdx.x * blockDim.x + threadIdx.x; if (tid < num_bins) { bins[tid] = min(bins[tid], 127); } } void histogram(unsigned int* input, unsigned int* bins, unsigned int num_elements, unsigned int num_bins) { CUDA_CHECK(cudaMemset(bins, 0, num_bins * sizeof(unsigned int))); { dim3 blockDim(512), gridDim(30); histogram_kernel << num_bins * sizeof(unsigned int) >> > ( input, bins, num_elements, num_bins); CUDA_CHECK(cudaGetLastError()); CUDA_CHECK(cudaDeviceSynchronize()); } { dim3 blockDim(512); dim3 gridDim((num_bins + blockDim.x - 1) / blockDim.x); convert_kernel << CUDA_CHECK(cudaGetLastError()); CUDA_CHECK(cudaDeviceSynchronize()); } } int main(int argc, char* argv[]) { wbArg_t args; int inputLength; unsigned int* hostInput; unsigned int* hostBins; unsigned int* deviceInput; unsigned int* deviceBins; args = wbArg_read(argc, argv); wbTime_start(Generic, "Importing data and creating memory on host"); hostInput = (unsigned int*)wbImport(wbArg_getInputFile(args, 0), &inputLength, "Integer"); hostBins = (unsigned int*)malloc(NUM_BINS * sizeof(unsigned int)); wbTime_stop(Generic, "Importing data and creating memory on host"); wbLog(TRACE, "The input length is ", inputLength); wbLog(TRACE, "The number of bins is ", NUM_BINS); wbTime_start(GPU, "Allocating GPU memory."); // Выделяемпамять GPU CUDA_CHECK(cudaMalloc((void**)&deviceInput, inputLength * sizeof(unsigned int))); CUDA_CHECK( cudaMalloc((void**)&deviceBins, NUM_BINS * sizeof(unsigned int))); CUDA_CHECK(cudaDeviceSynchronize()); wbTime_stop(GPU, "Allocating GPU memory."); wbTime_start(GPU, "Copying input memory to the GPU."); // Скопируемпамятьсхостана GPU CUDA_CHECK(cudaMemcpy(deviceInput, hostInput, inputLength * sizeof(unsigned int), cudaMemcpyHostToDevice)); CUDA_CHECK(cudaDeviceSynchronize()); wbTime_stop(GPU, "Copying input memory to the GPU."); // Запускядра // ---------------------------------------------------------- wbLog(TRACE, "Launching kernel"); wbTime_start(Compute, "Performing CUDA computation"); histogram(deviceInput, deviceBins, inputLength, NUM_BINS); wbTime_stop(Compute, "Performing CUDA computation"); wbTime_start(Copy, "Copying output memory to the CPU"); // Скопируемпамятьобратнос GPU нахост CUDA_CHECK(cudaMemcpy(hostBins, deviceBins, NUM_BINS * sizeof(unsigned int), cudaMemcpyDeviceToHost)); CUDA_CHECK(cudaDeviceSynchronize()); wbTime_stop(Copy, "Copying output memory to the CPU"); wbTime_start(GPU, "Freeing GPU Memory"); // Освобождениепамяти GPU CUDA_CHECK(cudaFree(deviceInput)); CUDA_CHECK(cudaFree(deviceBins)); wbTime_stop(GPU, "Freeing GPU Memory"); // Проверка корректности результатов // ----------------------------------------------------- wbSolution(args, hostBins, NUM_BINS); free(hostBins); free(hostInput); return 0; } Тест программы:  Рисунок 1 – Входные данные 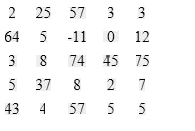 Рисунок 2 – Входные данные 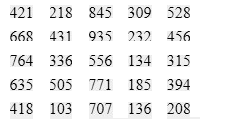 Рисунок 3 – Скриншот результата работы программы Вывод:Успешно научился перемножать матрицы в CUDA. Контрольные вопросы: |