Лекции по дисциплине ИТ_2020. Лекции по дисциплине "Информационные технологии"
 Скачать 287.29 Kb. Скачать 287.29 Kb.
|

Лекция 5. Информационные технологии широкого пользованияСамыми распространенными компьютерными технологиями являются редактирование текстовых данных, обработка графических и табличных данных. Табличные процессорыДокументы табличного вида составляют большую часть документооборота предприятия любого типа. Поэтому табличные ИТ особо важны при создании и эксплуатации ИС. Комплекс программных средств, реализующих создание, регистрацию, хранение, редактирование, обработку электронных таблиц и выдачу их на печать, принято называть табличным процессором. Электронная таблица представляет собой двухмерный массив строк и столбцов, размещенный в памяти компьютера. Широкое распространение получили такие табличные процессоры, как SuperCalc, VisiCalc, Lotus 1-2- 3, Quattro Pro. Для Windows был создан процессор Excel, технология работы с которым аналогична работе с любым приложением Windows интерфейса WIMP. Табличный процессор позволяет решать большинство финансовых задач. Системы управления базами данных Основные понятия БДЦель любой информационной системы - обработка данных об объектах реального мира. В широком смысле слова база данных - совокупность сведений о конкретных объектах реального мира в какой- либо предметной области. Создавая базу данных, пользователь стремиться упорядочить информацию по различным признакам и быстро извлекать выборку с произвольным сочетанием признаков. Сделать это возможно, только если данные структурированы. Структурирование - это введение соглашений о способах представления данных. В современной технологии баз данных предполагается, что создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляется централизовано с помощью специального программного инструментария - системы управления базами данных Базаданных(БД)-поименованная совокупность структурированных данных, относящихся к определенной предметной области. Система управления базами данных (СУБД) - это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации. Понятие базы данных тесно связано с такими понятиями структурных элементов, как поле и запись. Поле-элементарная единица логической организации данных, которая соответствует неделимой единицы информации - реквизиту.Для описания поля используются следующие характеристики: имя; тип; длина; точность. Запись-совокупность логически связанных полей. Экземплярзаписи-отдельная реализация записи, содержащая конкретные значения ее полей. Виды моделей БДЯдром любой базы данных является модель данных. Модельданных- совокупность структур данных и операций их обработки. СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или не некотором их подмножестве. Иерархическая модель данных.К основным понятиям иерархической структуры относятся: уровень, элемент, связь. Узелэто совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне (см. рис. 5). 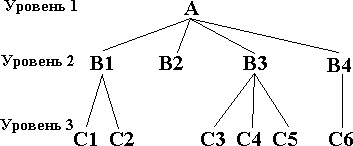 Рис. 5. Иерархическая модель данных К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, для записи С4 путь проходит через записи А и В3. 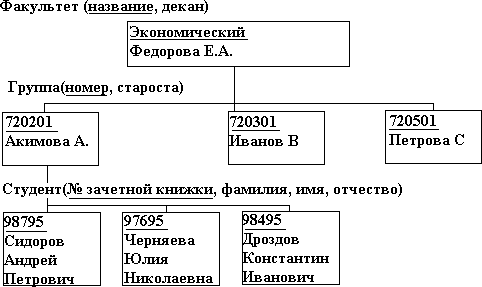 Пример иерархической структуры. Каждый студент учится в определенной (только одной) группе, которая относится к определенному (только одному) факультету (см. рис. 6). Пример иерархической структуры. Каждый студент учится в определенной (только одной) группе, которая относится к определенному (только одному) факультету (см. рис. 6).Рис. 6. Пример иерархической организации данных Сетевая модель данныхВ сетевой структуре каждый элемент может быть связан с любым другим элементом (см. рис 7). 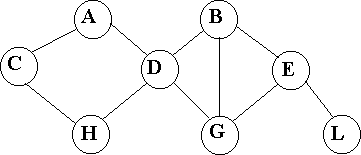 Рис. 7. Сетевая модель данных Пример сетевой структуры. База данных, содержащая сведения о студентах, участвующих в научно- исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС (см. рис. 8). 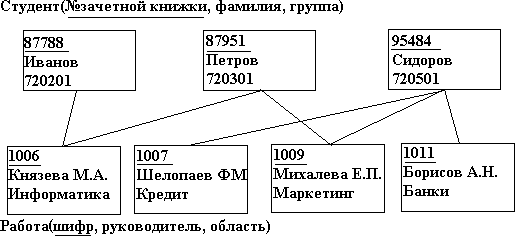 Рис. 8. Пример сетевой организации данных Реляционная модель данныхЭти модели характеризуются простотой структуры данных, удобным для пользователя представлением и возможностью использования формального аппарата алгебры отношений. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица (отношение) представляет собой двумерный массив и обладает следующими свойствами: каждый элемент таблицы - один элемент данных; все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину; каждый столбец имеет уникальное имя; одинаковые строки в таблице отсутствуют; порядок следования строк и столбцов может быть произвольным. Пример. Реляционной таблицей можно представить информацию о студентах, обучающихся в вузе.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составнойключ. Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ- ключ второй таблицы. Одни и те же данные могут группироваться в таблицы различными способами. Группировка атрибутов в таблицах должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки. Нормализацияотношений-формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных. Выделяют пять нормальных форм отношений. Эти формы предназначены для уменьшения избыточности информации от первой до пятой нормальных форм. Поэтому каждая последующая нормальная форма должна удовлетворять требованиям предыдущей формы и некоторым дополнительным условиям. При практическом проектировании баз данных четвертая и пятая формы, как правило, не используются. Процедуру нормализации рассмотрим на примере проектирования многотабличной БД Продажи, содержащей следующую информацию: Сведения о покупателях. Дату заказа и количество заказанного товара. Дату выполнения заказа и количество проданного товара. Характеристику проданного товара (наименование, стоимость, марка). Таблица 2. Структура таблицы Продажи
Таблицу Продажи можно рассматривать как однотабличную БД. Основная проблема заключается в том, что в ней содержится значительное количество повторяющейся информации. Такая структура данных является причиной следующих проблем, возникающих при работе с БД: Приходится тратить значительное время на ввод повторяющихся данных. Например, для всех заказов, сделанных одним покупателем, придется каждый раз вводить одни и те же данные о покупателе. При изменении адреса или телефона покупателя необходимо корректировать все записи, содержащие сведения о заказах этого покупателя. Наличие повторяющейся информации приведет к неоправданному увеличению размера БД. В результате снизится скорость выполнения запросов. Кроме того, повторяющиеся данные нерационально используют дисковое пространство компьютера. Любые нештатные ситуации потребуют значительного времени для получения требуемой информации. Первая нормальная форма.Таблица, структура которой приведена в табл.2, является ненормализованной. Таблица в 1НФ должна удовлетворять следующим требованиям: Таблица не должна иметь повторяющихся записей. В таблице должны отсутствовать повторяющиеся группы полей. Строки должны быть не упорядочены. Столбцы должны быть не упорядочены. Для удовлетворения условия 1 значение хотя бы одного поля таблицы для каждой строки таблицы должно быть уникально, т.е. быть ключом. Таблица Продажи не содержит такого ключа, что допускает наличие в таблице повторяющихся записей. Для выполнения условия 1 создадим новое поле Код Клиента. В таблицах большинства СУБД записи упорядочены, поэтому требование 3 не может быть удовлетворено. Так как каждый покупатель может сделать несколько заказов, в каждом из которых в свою очередь может заказать несколько товаров, то для выполнения требования 2, необходимо разбить таблицу на три таблицы: сведения о клиентах; номер и дату заказ клиента, данные о менеджере, обслуживающем заказ; код, наименование, количество заказанного товара.  Поэтому разобьем таблицу Продажи на три отдельные таблицы (Клиенты'>Клиенты, Заказы и Заказано) и определим КодКлиентав качество совпадающего поля для связывания таблицы Клиенты с таблицей Заказы и КодЗаказа– для связывания таблиц Заказы и Заказано. Отметим, что отношение между связываемыми таблицами «один-ко-многим». Поэтому разобьем таблицу Продажи на три отдельные таблицы (Клиенты'>Клиенты, Заказы и Заказано) и определим КодКлиентав качество совпадающего поля для связывания таблицы Клиенты с таблицей Заказы и КодЗаказа– для связывания таблиц Заказы и Заказано. Отметим, что отношение между связываемыми таблицами «один-ко-многим».Таблица Клиенты содержит данные о клиентах. Определим ключевое поле КодКлиента. Аналогично для таблицы Заказы – ключевое поле Код Заказа. Таким образом, для таблиц Клиенты и Заказы решена проблема повторяющихся групп. Таблица Заказано содержит сведения о товарах, включенных в заданный заказ. Для исключения повторяющихся записей можно воспользоваться одним из способов: Добавить в таблицу новое уникальное ключевое поле Счетчик, что позволит однозначно идентифицировать каждую запись. Это не лучший способ, т.к. в дальнейшем при построении схемы данных не позволит установить связь между таблицами. В качестве ключа использовать составной ключ, состоящий из 2 полей Код Заказа и Код Товара(наименование обычно не используется, чтобы не отличались товары Нож, нож, Ножи, т.е. по- разному написанные). После разделения повторяющихся строк и определения ключей в каждой таблице можно считать, что таблицы Клиенты, Заказы и Заказано находятся в первой нормальной форме. Вторая нормальная форма.О таблице говорят, что она находится во второй нормальной форме, если: Она удовлетворяет условиям первой нормальной формы. Любое неключевое поле однозначно идентифицируется полным набором ключевых полей. Из приведенного определения видно, что понятие 2НФ применимо только к таблицам, имеющим составной ключ. В нашем примере такой таблицей является Заказано, в которой составной ключ образуют поля Код Заказа и Код Товара. Данная таблица не является таблицей во 2НФ, т.к. поля Наименование, Единица измерения однозначно определяются только одним из ключевых полей – КодТовара. Для приведения таблицы ко 2НФ выделим из таблицы Заказано таблицу Товары, которая будет содержать информацию о товарах. Для связывания таблиц Заказано и Товары используется поле КодТовара 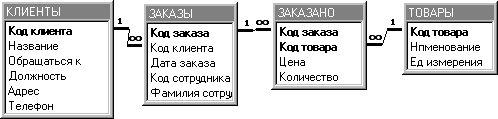 Третья нормальная формаО таблице говорят, что она находится во второй нормальной форме, если: Она удовлетворяет условиям второй нормальной формы. Ни одно из неключевых полей не идентифицируется с помощью другого неключевого поля. Сведение таблицы к 3НФ предполагает выделение в отдельную таблицу полей, которые не зависят от ключа. В таблице Заказы поле Фамилия Сотрудника содержит имена менеджеров, которые однозначно определяются значением поля Код Сотрудника и не зависит от Кода Заказа. Следовательно, т.к. неключевое поле (Фамилия сотрудника) однозначно определяется другим неключевым полем (КодСотрудника), таблица Заказы не является таблицей в 3НФ. Для приведения этой таблицы к 3НФ создадим новую таблицу Сотрудники 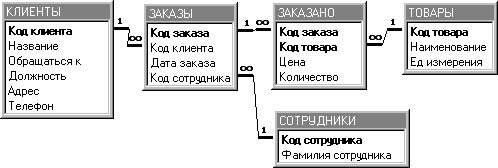 Обзор СУБДВ настоящее время наибольшее распространение получили следующие СУБД, реализующие реляционную модель данных: dBASE IV (Borland International) Microsoft FoxPro for DOS Microsoft FoxPro for Windows Microsoft Access Paradox for DOS (Borland) Paradox for Windows В табл. 3 показаны места (условные), которые занимают рассматриваемые программные средства относительно друг друга. Например, 1 означает, что в указанной позиции данная программа обладает лучшими характеристиками, 5 - худшими, нет - указанной характеристикой данная программа не обладает. Таблица 3. - Характеристики СУБД
Кроме перечисленных СУБД применяются также Clarion, Clipper, RBase, DataEase, SuperBase и другие. Технология работы в СУБДПосле построения информационно-логической модели предметной области, не ориентированной на конкретную СУБД, приступают к физической реализации базы данных средствами СУБД. Каждая конкретная СУБД имеет свои особенность, которые необходимо учитывать. Однако можно представить обобщенную технологию работы пользователя в СУБД, реализующей реляционную модель данных (см. рис. 9). Рис. 9. Обобщенная технология работы пользователя в СУБД 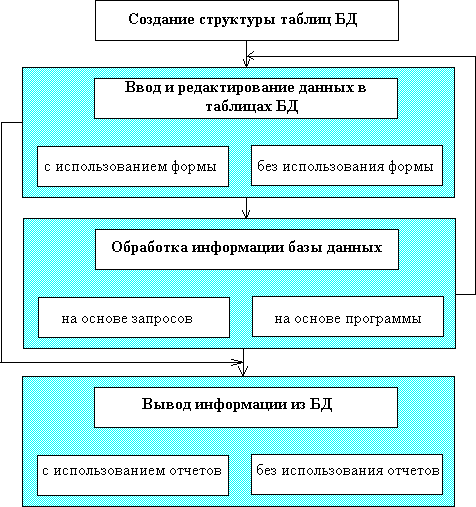 |