BigData_лекция_01_рус. Лекция Базовые понятия системы Big
 Скачать 316.75 Kb. Скачать 316.75 Kb.
|

|
Лекция 1. Базовые понятия системы Big Data Большие данные в информационных технологиях – серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объемов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети. Предметом обработки больших данных является цифровая информация, сформированная множествами действующих в Интернете стационарных и мобильных устройств. Поэтому содержание информации описывает состояние значительно большей части общества, а значит, и результаты обработки затрагивают интересы больших масс людей. В информационных технологиях признаками больших данных служат: - объем данных, который оказывается настолько велик, что не позволяет выполнить хранение и обработку традиционными методами и средствами; - быстрый рост объема генерируемой информации; - разнообразие используемых форматов неструктурированных и моделей для структурированных данных; - одинаковая ценность всех данных для решения задачи, т. е. из всей массы априорно не выделяются несущественные данные, которые можно бы не хранить и не обрабатывать. В сравнении с классическими базами при обработке больших данных допускается избыточность и неконсистентность данных. Например, временная несогласованность данных или несоответствие реплики основным данным источника. Подобная «неточность» данных допустима в силу того, что целью обработки является не вычисление новых данных, а обнаружение статистических зависимостей и трендов развития процессов. В технологии обработки традиционных баз данных создано отдельное направление – бизнес-аналитика (Business Intelligence, Data Mining) – разработано немало «коробочных» продуктов для пакетной обработки данных. Технология применения этих продуктов требует сосредоточенной в одном центре базы и процесса обработки данных и поэтому не позволяет использовать их для хранения и обработки больших данных. Потребность достижения приемлемой скорости обработки больших данных стимулировала появление новых методов, ориентированных на использование массово-параллельных вычислений. Особенность больших данных, заключающаяся не только в их массовости, но и однородности, позволяет выполнять распараллеливание процесса обработки на сотни и тысячи узлов. Для реализации таких процессов необходимы средства отказоустойчивого распределенного хранения огромных объемов данных и организации надежных параллельных вычислений с последующим слиянием их результатов. Представленной задаче наилучшим образом соответствуют данные, накопленные в Интернете. Они исходно размещены на разных узлах в дата-центрах и могут обрабатываться параллельно. При этом используемая технология обработки должна учитывать следующие требования: 1. Данные хранятся на многих серверах, и, чтоб избежать больших объемов передачи данных, их надо обрабатывать в местах хранения. Вместо традиционной передачи данных в узлы обработки необходима передача программ в места хранения данных. Серверы хранения должны быть и серверами обработки данных. 2. Неизбежные отказы серверов хранения и обработки требуют реализации их автоматического восстановления. В целях достижения общей эффективности необходима балансировка и перераспределение нагрузки между узлами обработки. 3. Реализация параллельных вычислений требует программирования и синхронизации параллельных процессов для большого и меняющегося числа параллельных узлов. Обычно Большие данные описываются при помощи следующих характеристик: 1. Объем (Volume) – количество сгенерированных и хранящихся данных. Размер данных определяет значимость и потенциал данных, а также то, могут ли они быть рассмотрены как Большие данные. 2. Разнообразие (Variety) – тип данных. Большие данные могут состоять из текста, изображений, аудио, видео. Большие данные при сопоставлении друг с другом могут дополнять отсутствующие данные. 3. Скорость (Velocity) – скорость. Здесь подразумевается скорость, с которой данные генерируются и обрабатываются. Очень часто Большие данные используются в режиме реального времени. 4. Изменчивость (Variability) – противоречивость наборов данных может препятствовать их обработке и управлению ими. 5. Достоверность (Veracity) – качество данных напрямую влияет на точность проведения анализа данных. Большие данные могут быть классифицированы в соответствии с несколькими главными компонентами (рис. 1). 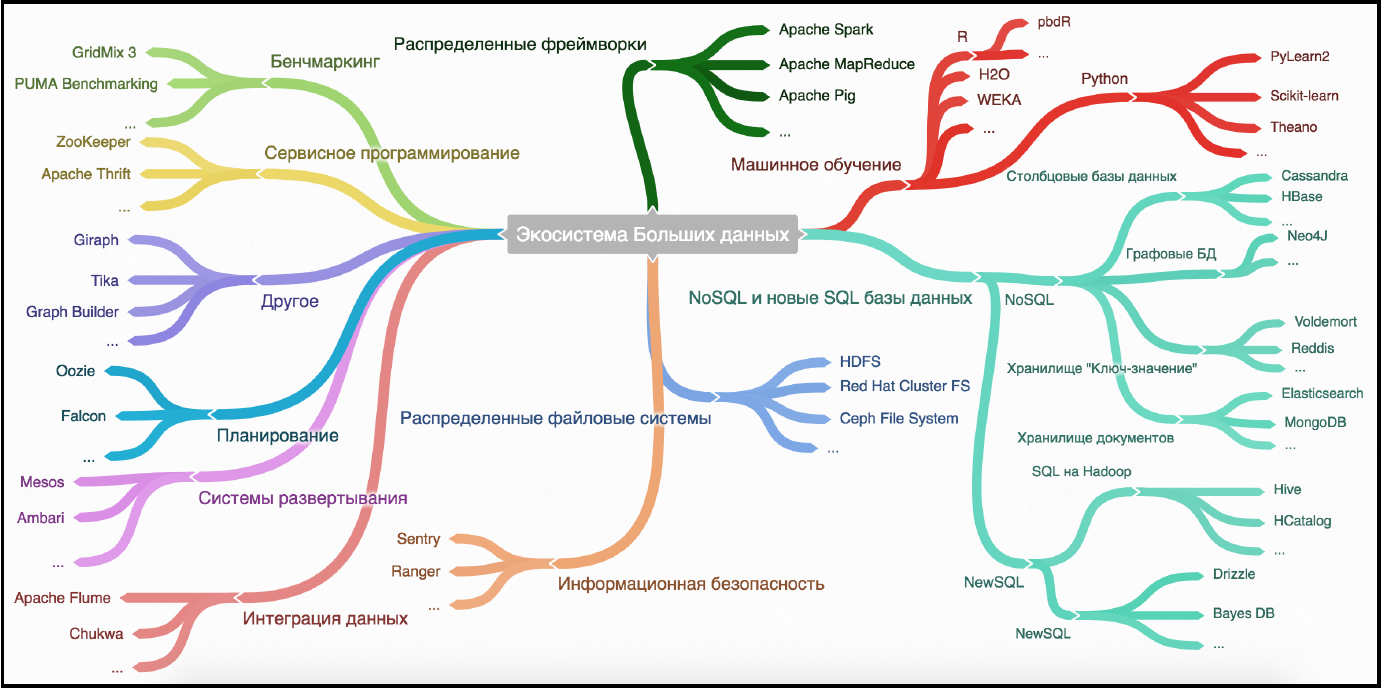 Рисунок 1 – Интеллект-карта экосистемы Больших данных Технологии и тенденции работы с Big Data Изначально в совокупность подходов и технологий включались средства массово-параллельной обработки неопределённо структурированных данных, такие как СУБД NoSQL, алгоритмы MapReduce и средства проекта Hadoop. В дальнейшем к технологиям больших данных стали относить и другие решения, обеспечивающие сходные по характеристикам возможности по обработке сверхбольших массивов данных, а также некоторые аппаратные средства. MapReduce — модель распределённых параллельных вычислений в компьютерных кластерах, представленная компанией Google. Согласно этой модели, приложение разделяется на большое количество одинаковых элементарных заданий, выполняемых на узлах кластера и затем естественным образом сводимых в конечный результат. NoSQL (от англ. Not Only SQL, не только SQL) — общий термин для различных нереляционных баз данных и хранилищ, не обозначает какую-либо одну конкретную технологию или продукт. Обычные реляционные базы данных хорошо подходят для достаточно быстрых и однотипных запросов, а на сложных и гибко построенных запросах, характерных для больших данных, нагрузка превышает разумные пределы и использование СУБД становится неэффективным. Hadoop — свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Считается одной из основополагающих технологий больших данных. R — язык программирования для статистической обработки данных и работы с графикой. Широко используется для анализа данных и фактически стал стандартом для статистических программ. Аппаратные решения. Корпорации Teradata, EMC и др. предлагают аппаратно-программные комплексы, предназначенные для обработки больших данных. Эти комплексы поставляются как готовые к установке телекоммуникационные шкафы, содержащие кластер серверов и управляющее программное обеспечение для массово-параллельной обработки. Сюда также иногда относят аппаратные решения для аналитической обработки в оперативной памяти, в частности, аппаратно-программные комплексы Hana компании SAP и комплекс Exalytics компании Oracle несмотря на то, что такая обработка изначально не является массово-параллельной, а объёмы оперативной памяти одного узла ограничиваются несколькими терабайтами. Облачные технологии Общепринятое определение облачных вычислений, предложенное Национальным институтом стандартов и технологий США – U.S. National Institute of Standards and Technology (NIST Special Publication 800-145), гласит: «Облачные вычисления – это модель, позволяющая легко осуществлять сетевой доступ по требованию к единому пулу настраиваемых вычислительных ресурсов (например, сетей, серверов, систем хранения данных, приложений и услуг), которые быстро выделяются для использования и затем так же быстро высвобождаются. При этом затрачивается минимум усилий на администрирование и взаимодействие с поставщиком услуг.» Высокоэффективные облачные технологии К высокоэффективным облачным технологиям относятся grid-вычисления, utility-вычисления, виртуализация и сервис-ориентированная архитектура. - Grid-вычисления представляют собой разновидность распределенного вычисления, позволяющую предоставлять ресурсы многочисленных разнородных компьютеров, находящихся в сети, для совместной работы по одновременному решению единой задачи. Grid-вычисления позволяют производить параллельные вычисления и наилучшим образом подходят для решения задач с большими объемами работ. - Utility-вычисления представляют собой модель предоставления услуг, в которой поставщик каждой отдельно взятой услуги предоставляет клиентам доступ к вычислительным ресурсам по запросу и ведет учет предоставляемых услуг по факту их потребления. Здесь прослеживается аналогия с предоставлением жилищно-коммунальных услуг, например с обеспечением электроэнергией, где учет ведется на основе фактического потребления. - Виртуализация представляет собой технологию, позволяющую пользователям IT-ресурсов абстрагироваться от их физических характеристик. Она дает возможность просматривать ресурсы и управлять ими в составе пула, а также позволяет пользователям создавать из пула виртуальные ресурсы. Виртуализация дает возможность проявлять более высокий уровень гибкости в предоставлении IT-ресурсов по сравнению с выполнением этой же задачи в невиртуализированной среде. Она помогает оптимизировать использование ресурсов и повысить эффективность их предоставления. - Сервис-ориентированная архитектура – Service Oriented Architecture (SOA) — предоставляет набор служб, способных взаимодействовать друг с другом. Эти службы ведут совместную работу для выполнения определенных действий или просто обмениваются данными друг с другом. Характеристики облачных вычислений Вычислительная инфраструктура, используемая для предоставления облачных услуг, должна обладать определенными возможностями или характеристиками. В соответствии с положениями, выработанными NIST, облачная инфраструктура должна иметь пять основных характерных особенностей. - Самообслуживание по требованию. Потребитель в инициативном порядке может быть автоматически снабжен вычислительными ресурсами, такими как серверное время и сетевое хранилище, по факту потребности, без участия представителей поставщиков услуг. Поставщик облачных услуг публикует перечень услуг, содержащий информацию обо всех облачных услугах, доступных потребителям. Перечень услуг включает информацию о характере услуг, ценах и способах их запросов. Потребители просматривают перечень услуг с помощью пользовательского веб-интерфейса и используют его для запроса услуги. Потребители могут либо воспользоваться теми услугами, которые уже готовы к использованию (ready-to-use), либо изменить некоторые параметры обслуживания, чтобы настроить услуги под свои запросы. - Широкополосный сетевой доступ. Возможности, доступные по сети, обращение к которым осуществляется с использованием стандартных механизмов, способствующих их использованию разнородными, как полными, так и неполными клиентскими платформами (например, мобильными телефонами, планшетными компьютерами, ноутбуками и рабочими станциями). - Создание пула ресурсов. Вычислительные ресурсы поставщика объединяются в пул для обслуживания нескольких потребителей с использованием модели, допускающей наличие множества арендаторов различных физических и виртуальных ресурсов, динамически выделяемых и высвобождаемых в соответствии с потребительскими нуждами. У клиента создается чувство независимости от местонахождения за счет того, что клиент, как правило, не контролирует точное местонахождение предоставляемых ресурсов или даже не знает о нем, но при этом может указать местонахождение на более высоком уровне абстракции (например, страну, штат или дата-центр). В качестве примеров ресурсов могут послужить хранилища данных, средства обработки данных, память и полоса пропускания сети. - Оперативность и гибкость. С целью быстрого масштабирования, соразмерного с внешним и внутренним спросом, ресурсы могут быть гибко предоставлены и высвобождены, причем в ряде случаев в автоматическом режиме. Потребителю доступные для предоставления ресурсы зачастую видятся неограниченными и предоставляемыми в любом объеме и в любое время. При резких колебаниях потребностей в IT-ресурсах потребители могут воспользоваться преимуществами оперативности и гибкости облачной среды. Например, организации в течение определенного периода времени для выполнения определенной задачи может понадобиться двойное количество веб-серверов и серверов приложений. В оставшийся период они с целью экономии средств могут освободиться от неиспользуемых серверных ресурсов. Облако позволяет потребителям увеличивать и сокращать количество ресурсов динамически. - Оплата услуг по факту потребления. Облачные системы автоматически контролируют и оптимизируют использование ресурсов, применяя возможности измерения на уровне абстракции, соответствующем типу услуги (например, по факту хранения, обработки, предоставления полосы пропускания и по времени активности учетных записей пользователей). Использование ресурсов может отслеживаться, контролироваться и заноситься в отчет, обеспечивая прозрачность и поставщику, и потребителю используемой услуги. Преимущества, получаемые от облачных вычислений Облачные вычисления предлагают следующие основные преимущества. - Уменьшение стоимости IT-услуг. Облачные услуги могут приобретаться на основе оплаты фактически потребленных объемов или по цене их абонирования. Тем самым снижаются или исключаются капитальные расходы (CAPEX) потребителей на IT-инфраструктуру. - Адаптивность бизнеса. Облачные вычисления дают возможность быстро выделять и масштабировать вычислительные мощности. Они способны сократить время, требующееся на предоставление и развертывание новых приложений, с месяцев до минут. Это позволяет предприятию намного быстрее реагировать на рыночные перемены и сокращать срок вывода продукции на рынок. - Гибкое масштабирование. Облачные вычисления позволяют потребителям легко наращивать и сокращать вычислительные мощности, расширять и сужать границы их применения в соответствии с потребностями в компьютерных ресурсах. Потребители могут в одностороннем порядке или автоматически масштабировать вычислительные ресурсы без взаимодействия с поставщиками облачных услуг. Присущая облачным вычислениям возможность гибкого предоставления услуг зачастую формирует у потребителей облачных вычислений ощущение возможности неограниченного масштабирования. - Высокая доступность. Облачные вычисления могут гарантировать доступность ресурсов на различных уровнях в зависимости от политики и приоритетов потребителей. Отказоустойчивость развернутых облачных систем гарантируется избыточной инфраструктурой компонентов (серверов, сетевых маршрутов и оборудования для хранения данных наряду с программами кластеризации). Эти технологии могут охватывать несколько дата-центров, находящихся в различных географических районах, что предотвращает недоступность данных из-за сбоев в каком-нибудь из районов. Модели облачного обслуживания В соответствии с положениями NIST предложения облачного обслуживания в основном сводятся к трем моделям: инфраструктура как услуга — Infrastructure-as-a-Service (IaaS), платформа как услуга — Platform-as-a-Service (PaaS) и программное обеспечение как услуга — Software-as-a-Service (SaaS). Литература: Парфенов Ю.П. Постреляционные хранилища данных: учеб. пособие. – Екатеринбург: Изд-во Урал. ун-та, 2016 – 120с. Радченко И.А., Николаев И.Н. Технологии и инфраструктура Big Data. – СПб: Университет ИТМО, 2018. – 52с. Big Data (Большие данные) [Электронный ресурс] // IT-Enterprise. URL: https://www.it.ua/ru/knowledge-base/technology-innovation/big-data-bolshie-dannye (дата обращения: 10.09.2021) От хранения данных к управлению информацией. 2-е изд. – СПб.: Питер, 2016. – 544с. Контрольные вопросы: 1. Что такое Big Data? 2. Требования к технологиям обработки Больших данных. 3. Характеристики Больших данных. 4. Технологии и тенденции работы с Большими данными. 5. Характеристики облачных вычислений. |