CSS Практическая работа 1. Лекция. Кодировки текста и специальные символы
 Скачать 35.15 Kb. Скачать 35.15 Kb.
|

Лекция. Кодировки текста и специальные символыОднобайтныеимногобайтныекодировки Все данные в компьютере: текст, графика, звук, видео – хранятся и обрабатываются в цифровой (двоичной) форме. Минимальной единицей измерения информации является бит – разряд двоичного числа, который может принимать 2 значения: 0 или 1. 8 бит составляют 1 байт – минимальную единицу адресации к хранимой информации. Текст представляет из себя набор символов: букв, цифр, знаков препинания и других. Для работы с текстом компьютер должен представить его в «привычном» для себя виде: нулями и единицами. Для этого задаются таблицы соответствия символа и его числового кода – таблицы кодировки. В 1960-гг. в США была создана кодировка ASCII. Числовой код символа записывался 7-ю битами, таким образом, можно было составлять тексты, используя 27 = 128 различных символов. Кодировка содержит управляющие символы (например, перенос строки, табуляция), латинские символы, цифры, знаки пунктуации и др. Так, пробелу соответствовал код 32, цифре 0 – код 48, заглавной латинской букве A – код 65, а строчной – 97. ASCII в своей 7-битной версии не позволяет использовать символы национальных алфавитов, например, кириллицу: для нее не осталось места в таблице. Так как компьютеры работают с байтом из 8 бит, в ASCII использовались только первые 7 бит, а последний бит всегда был равен 0. Задействовав этот последний бит, можно получить еще дополнительно 128 мест. Таким способом ASCII была дополнена алфавитами для различных языков. Для каждого языка создавались кодировки, первые 128 символов которых повторяли ASCII, а во второй половине таблицы кодировки располагались символы национальных алфавитов. К сожалению, конкуренция между разработчиками операционных систем привела к появлению нескольких несовместимых друг с другом кодировок для кириллицы: КОИ-8 в UNIX, CP866 в MS-DOS, Windows-1251 в Windows, MacCyrillic на компьютерах «Макинтош» фирмы Apple. Чтобы устранить «зоопарк» кодировок, Международной организацией по стандартизации (ISO) была разработана единая кодировка ISO 8859-5, но она так и не прижилась в компьютерной индустрии. Однобайтные кодировки обладают следующими недостатками: Документы, созданные в одной кодировке, отображаются как беспорядочный набор символов в другой Использование однобайтной кодировки ограничивает набор 256-ю символами (на самом деле, еще меньше – первые 32 символа являются служебными). Это делает невозможным работу с иероглифическими языками (китайским, японским), в которых используются тысячи различных знаков, а также использование множества языков в одном документе. Для решения этих проблем был создан стандарт кодирования Unicode (Юникод), который содержит символы практически всех существующих письменных языков и изобретенных человечеством знаков (музыкальных, математических и т.п.). Юникод устраняет проблему выбора правильной кодировки, но текст, сохраненный в этой системе, занимает больший объем байт. Существует несколько представлений Unicode: UTF-16, где на 1 символ приходится 2 байта, и UTF-8 с переменным числом байтов на символ – от 1 до 4. Если на странице используется только латиница и кириллица, то каждый символ для хранения будет занимать 2 байта, т.е. текст такой HTML-страницы в UTF-8 требует в 2 раза больше места на диске, чем текст в кодировке Windows-1251. При нынешних темпах развития систем хранения данных это уже можно не считать серьезным недостатком. На начало 2010 года UTF-8 используется более чем на 50% сайтов, а кодировки ASCII, Windows-1251 и прочие из года в год используются веб-мастерами все реже. КодировкавHTML Кодировка документа HTML задается в текстовом редакторе. Например, Блокнот в ОС Windows по умолчанию сохраняет текстовые файлы в кодировке Windows-1251. Для того чтобы браузер правильно отобразил HTML-страницу, необходимо задать правильную кодировку в специальном теге . http-equiv="Content-Type" content="text/html; charset=windows-1251"> или content="text/html; charset=utf-8"> Если кодировка не будет указана, браузер попытается «угадать» ее, но не всегда это заканчивается успехом. Пользователь может выбрать кодировку самостоятельно в меню браузера (в Internet Explorer и Mozilla Firefox: Вид → Кодировка). При разработке сайта проблем с кодировкой следует избегать, т.к. большинство пользователей сразу же покинет страницу, увидев нечитаемый набор букв на экране. СпециальныесимволывHTML В HTML предусмотрен механизм вставки в документ любых символов Юникод – подстановки или сущности (англ. entities). Подстановки позволяют употреблять символы, отсутствующие на клавиатуре или даже в используемой кодировке (т.е. даже используя кодировку Windows-1251 можно вставить букву греческого алфавита). Подстановки начинаются с символа амперсанда и записываются в виде &#DDDD; где DDDD – код символа в Юникоде в десятеричной системе счисления. Также можно записывать код в шестнадцатеричной системе счисления в форме &#xHHHH; Для некоторых символов заданы специальные названия – мнемоники. Например, знак копирайта © может быть задан кодом © или © или мнемоникой ©. 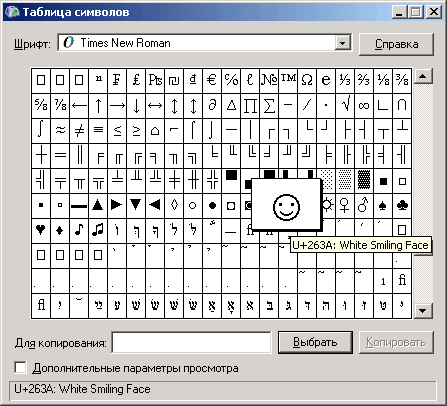 Рисунок2.10.Интерфейспрограммы«Таблицасимволов» Для того чтобы найти код нужного символа в ОС Windows, можно воспользоваться системной утилитой «Таблица символов» (см. рис. 2.10). Открыть программу можно нажав кнопку Пуск → Выполнить → charmap. В программе можно посмотреть, какие символы поддерживают установленные на компьютере шрифты, и узнать шестнадцатеричные коды этих символов. Частоиспользуютсяподстановки: « и » – для кавычек «елочек»; — – для тире; неразрывный пробел (см. список Интернет-ресурсов в конце лекции) < и > – для символов меньше (<) и больше (>), которые используются для задания тегов HTML. Задания:а) Найдите код и вставьте в HTML-документ символы ☼ ♥ ≈ € ☭ б) Составьте формулу объема конуса: Vкон = ⅓·π·r2·h |