Лекция 2. Лекция Основные принципы построения концептуальной, логической, и физической модели данных. Основные принципы структуризации и нормализации базы данных
 Скачать 377.61 Kb. Скачать 377.61 Kb.
|

|
Лекция 2. Основные принципы построения концептуальной, логической, и физической модели данных. Основные принципы структуризации и нормализации базы данных. Задачи проектирования баз данных Процесс проектирования баз данных длительный, он требует обсуждений с заказчиком, со специалистами в предметной области. При разработке серьезных корпоративных информационных систем проект базы данных является тем фундаментом, на котором строится вся система в целом. Проектирование баз данных состоит в построении комплекса взаимосвязанных моделей данных. При создании базы данных для информационной системы наиболее важными являются задачи, связанные с разработкой правильной логической структуры данных, обеспечивающей выполнение всего требуемого набора функций информационной системы. Плохо продуманная база данных оказывается, как правило, неэффективной и даже бесполезной. Разработка базы данных — достаточно сложная задача. Зачастую к ней предъявляется много противоречивых требований. Создание правильной логической структуры предусматривает комплексный анализ всех факторов, влияющих на формирование и обработку данных. Задача проектировщика состоит в учете всех этих факторов с целью разработки наиболее оптимальной базы данных. Основные задачи проектирования баз данных можно сформулировать следующим образом: обеспечение хранения в БД всей необходимой информации; обеспечение возможности получения данных по всем необходимым запросам; сокращение избыточности и дублирования данных; обеспечение целостности базы данных. В том, как решаются эти задачи, мы и будем разбираться. Процесс проектирования БД представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. В общем случае можно выделить следующие этапы проектирования: 1) системный анализ и словесное описание информационных объектов предметной области; 2) проектирование концептуальной (инфологической) модели предметной области — частично формализованное описание объектов предметной области в терминах некоторой семантической модели; 3) даталогическое или логическое проектирование БД, т.е. описание БД в терминах принятой логической модели данных; 4) физическое проектирование БД, т.е. выбор эффективного размещения БД на внешних носителях для обеспечения наиболее эффективной работы приложения. На каждом из этих этапов разрабатывается та или иная модель данных. Если мы учтем, что между вторым и третьим этапами необходимо принять решение, с использованием какой стандартной СУБД будет реализовываться наш проект, то условно процесс проектирования БД можно представить последовательностью выполнения соответствующих этапов (рис. 8.1). 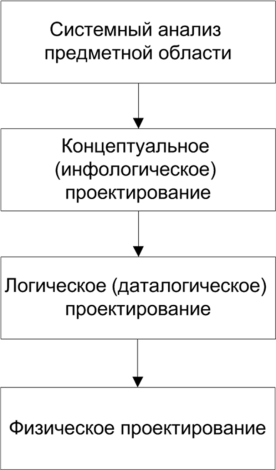 Рис. 8.1. Этапы проектирования БД Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, т.е. информационной модели наиболее высокого уровня абстракции. Такая модель создается без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является образом как реальности, так и проектируемой базы данных для этой реальности. Конкретный вид и содержание концептуальной модели базы данных определяются выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграм- мам. Чаще всего концептуальная модель базы данных включает в себя: • описание информационных объектов, или понятий предметной области и связей между ними; • описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними. Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например реляционной. Для реляционной модели данных логическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи. Преобразование концептуальной модели в логическую, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован. На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД. Физическое проектирование — создание схемы базы данных для конкретной системы управления базами данных. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, на под держиваемые типы данных и т.п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т.д. В области проектирования и разработки баз данных используются различные средства моделирования предметной области и БД, причем даже в рамках одной конкретной системы необходим целый комплекс моделей разного назначения. Далее рассмотрим каждый из этих этапов более подробно. Концептуальное моделированиеКонцептуальная модель — это определенное множество понятий и связей между ними, являющихся смысловой структурой рассматриваемой предметной области. Эта модель является начальным прототипом будущей базы данных, но строится без привязки к конкретной СУБД. Процесс разработки концептуальной модели предметной области является творческим и довольно трудно поддается формализации. Для построения концептуальной модели необходимо хорошее знание предметной области, ее семантики, понимание логических взаимосвязей ее информации. В 70—80-е годы в литературе концептуальное проектирование баз данных обозначалось терминами «инфологическое проектирование» и «инфологическая модель». На рис. 8.2 дается схема построения концептуальной модели от исходной информации до результата. В 1976 г. Питером Ченом была предложена так называемая модель «сущность-связь» {«entity-relationship»). Она включает сущности и взаимосвязи, отражающие основные бизнес-правила предметной области. В настоящее время для модели «сущность-связь» общепринятым стало сокращенное название — ER-модель. В дальнейшем многими авторами были разработаны свои варианты подобных моделей. Но все варианты моделей «сущность-связь» исходят из одной идеи — графическое изображение нагляднее текстового описания. В настоящее время ER-модель стала фактически стандартом для семантической структуризации предметной области — стандартом при концептуальном моделировании баз данных. В качестве стандартной графической нотации, с помощью которой можно визуализировать ER-модель, была предложена диаграмма сущность-связь (ER-диаграмма). ER-диаграмма изображается с помощью трех конструктивных элементов: сущность, атрибут и связь. Сущность — это класс однотипных объектов, информация о которых имеет существенное значение для рассматриваемой предметной области. Сущность представляет собой множество экземпляров реальных или абстрактных объектов (людей, событий, состояний, предметов и т.п.). Экземпляр сущности — это конкретный представитель данной сущности. Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности. Например, представителем сущности «Сотрудник» может быть «Сотрудник Иванов И.И.». Существует несколько систем нотаций (условных обозначений, языков) для описания объектно-связного представления предметной области. Нотация Баркера является наиболее распространенной. На диаграмме в нотации Баркера сущность изображается прямоугольником, иногда с закругленными углами (рис. 8.3, а). Каждая сущность обладает одним или несколькими атрибутами. Атрибут сущности — это именованная характеристика, являющаяся некоторым свойством сущности. Атрибут предназначен для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности (рис. 8.3, б). 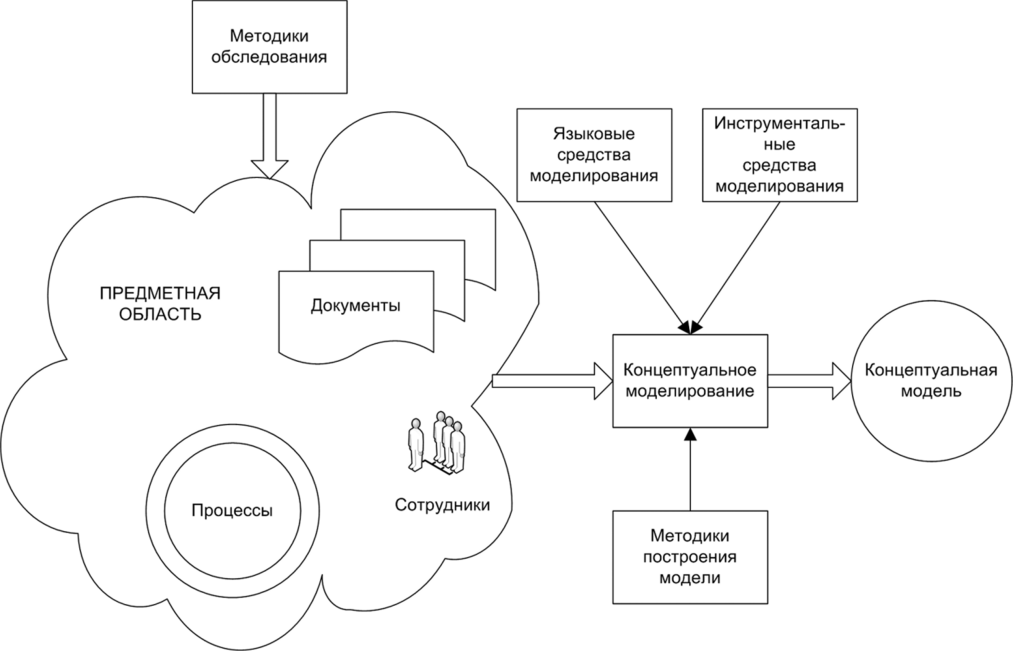 Рис. 8.2. Схема построения концептуальной модели Экземпляр атрибута — определенная характеристика конкретного экземпляра сущности, значение атрибута (например, «цвет» — это атрибут, а «зеленый» — экземпляр атрибута). Первичный ключ сущности — это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из состава ключа приведет к нарушению его уникальности. Первичный ключ предназначен для уникальной идентификации каждого экземпляра сущности, т.е. представляет собой совокупность признаков, позволяющих идентифицировать объект. Ключевые атрибуты помещают в начало списка и помечают символом «#» (рис. 8.3, в). Связь — это отношение одной сущности к другой или к самой себе. Каждая сущность может обладать любым количеством связей с другими сущностями модели. Различают три типа связей (рис. 8.4): 1*1 — «один-к-одному»; 1*п — «один-ко-многим»; n*m — «многие-ко-многим». 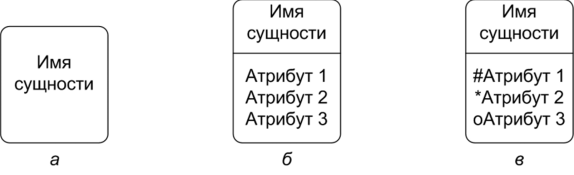 Рис. 8.3. Обозначения сущности в нотации Баркера: а — без атрибутов; б— с указанием атрибутов; в — с уточнением атрибутов и их типов (# — ключевой, * — обязательный, о — необязательный) 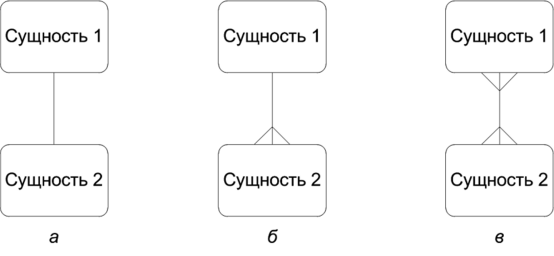 Рис. 8.4. Обозначение разных типов связи в нотации Баркера: а — «один-к-одному»; б — «один-ко-многим»; в — «многие-ко-многим» Связь типа «один-к-одному» означает, что один экземпляр первой сущности связан только с одним экземпляром второй сущности. Такая связь, скорее всего, свидетельствует о том, что была неверно разделена одна сущность на две (хотя иногда к такому типу связи прибегают в случае, если есть необходимость «засекретить» часть данных). Связь типа «один-ко-многим» означает, что каждый экземпляр первой сущности связан с несколькими экземплярами второй сущности. Связь типа «многие-ко-многим» означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и наоборот. Такой тип связи является временным, допустимым на ранних этапах разработки модели. В дальнейшем такую связь необходимо заменить двумя связями типа «один-ко-многим» путем выделения промежуточной сущности. Некоторые ограничения целостности задаются на ER-диаграмме, другие описываются на естественном языке В качестве примера рассмотрим небольшую базу данных, отражающую процесс поставки и продажи некоторого товара постоянным клиентам. База данных проектируется для автоматизированной информационной системы «Склад оптовой торговли». Исходя из анализа предметной области, можно выделить следующие сущности — Товар, Поставщик и Покупатель. Сразу возникает очевидная связь между сущностями — «покупатели могут приобретать много товаров», «товары могут приобретаться многими покупателями» Отношение между ними относится к типу «многие-ко-мно- гим» (рис. 8.5).  Рис. 8.5. Первый вариант ER-диаграммы Однако реляционная модель данных требует заменить отношение «многие-ко-многим» на несколько отношений «один-ко-многим». Для разрешения этого отношения добавим еще один тип сущностей, отображающий процесс продажи/покупки товаров — введем ассоциированные сущности «Приходная накладная» и «Расходная накладная» (рис. 8.6). Установим связи между объектами. Один покупатель может неоднократно покупать товары, поэтому между объектами «Покупатель» и «Расходная накладная» имеется связь «один-ко-многим». Каждое наименование товара может неоднократно участвовать в сделках, в результате между объектами «Товар» и «Расходная накладная» имеется связь «один-ко-многим». Аналогично строятся связи между сущностями «Приходная накладная» и «Товар». 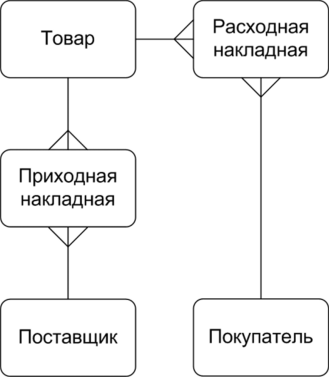 Рис. 8.6. Промежуточный вариант ER-диаграммы Проанализируем атрибуты сущностей. Каждый поставщик и покупатель являются юридическими лицами и имеют наименование, адрес, банковские реквизиты. Каждый товар имеет наименование, цену, характеризуется единицей измерения. Каждая накладная имеет уникальный номер, дату выписи, список товаров с количествами и ценами, а также общую сумму накладной. Покупатели покупают товары, получая при этом расходные накладные, в которые внесены данные о количестве и цене приобретенного товара. Каждый покупатель может получить несколько накладных. Каждая накладная должна выписываться на одного покупателя и должна содержать не менее одного товара (не может быть «пустой» накладной). Каждый товар, в свою очередь, может быть продан нескольким покупателям по нескольким накладным. Аналогичную цепь рассуждений можно выстроить для определения связей между сущностями «Товар» и «Поставщик». Покупатель может быть одновременно и поставщиком, поэтому эти два объекта объединены в одну сущность «Контрагент». Важной задачей в создании базы данных является выявление первичных ключей. Для таблицы «Товар» название товара не может служить первичным ключом, так как товары разных типов могут иметь одинаковые названия, поэтому введем первичный ключ «Код», под которым можно понимать, например, артикул товара. Точно так же «Наименование» не может служить первичным ключом в таблице «Контрагенты». Введем первичный ключ «Код» для поставщиков и покупателей, под которым можно понимать номер паспорта, идентификационный номер налогоплательщика или любой другой атрибут, однозначно определяющий каждого контрагента. Для таблиц «Расходная накладная»/«Приходная накладная» первичным ключом является поле «Номер», так как номер однозначно определяет каждую накладную. Теперь можно все это внести в диаграмму После уточнения диаграмма будет выглядеть следующим образом (рис. 8.7). 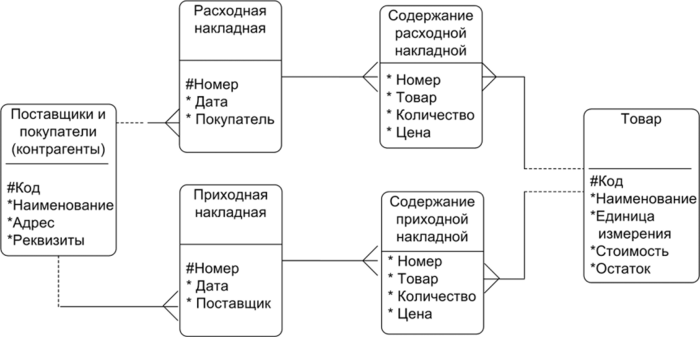 Рис. 8.7. Окончательный вариант ER-диаграммы Данная диаграмма должна быть проверена с точки зрения возможности получения всех выходных данных, показанных на диаграмме потоков данных разрабатываемой системы. В качестве самостоятельного объекта в ER-модели следует изображать сущности, для которых фиксируются какие-либо их свойства, либо участвующие более чем в одной связи. При возникновении сомнений лучше принять решение о создании самостоятельного объекта, так как это в дальнейшем потребует меньших изменений в модели. Следует помнить, что количественные характеристики всегда являются свойствами какого-либо объекта, и никогда — самостоятельными объектами. Например, год рождения не может рассматриваться как самостоятельный объект. Построение концептуальной модели может выполняться как «вручную», так и с использованием автоматизированных средств проектирования — CASE-средств. Логическое проектирование и физическая модель БДПри проектировании логической структуры БД осуществляются преобразование исходной концептуальной модели в модель данных, поддерживаемую конкретной СУБД, и проверка адекватности полученной логической модели отображаемой предметной области. Для любой предметной области существует множество вариантов проектных решений ее отображения в логической модели. Методика проектирования должна обеспечивать выбор наиболее подходящего проектного решения. Этап создания логической модели называется логическим проектированием. При переходе от концептуальной (инфологической) модели к логической (даталогической) следует иметь в виду, что концептуальная модель должна включать в себя всю информацию о предметной области, необходимую для проектирования базы данных. Преобразование концептуальной модели в логическую, осуществляется по формальным правилам. Логическая модель базы данных строится в терминах информационных единиц, допустимых в той конкретной СУБД, в среде которой мы проектируем базу данных. Описание логической структуры базы данных на языке СУБД называется схемой данных. Спроектировать логическую структуру базы данных означает определить все информационные единицы и связи между ними, задать их имена; если для информационных единиц возможно использование разных типов, то определить их тип. Следует также задать некоторые количественные характеристики, например длину поля. Любая система управления данными оперирует с допустимыми для нее логическими единицами данных. Кроме того, многие СУБД накладывают количественные и иные ограничения на структуру базы данных. Поэтому, прежде чем приступить к построению логической модели, необходимо детально изучить особенности СУБД, возможности и целесообразности ее использования, ознакомиться с существующими методиками проектирования, а также проанализировать имеющиеся средства автоматизации проектирования. Хотя логическое проектирование является проектированием логической структуры базы данных, на него оказывают влияние возможности физической организации данных, предоставляемые конкретной СУБД. Следовательно, при проектировании логической структуры необходимо знание особенностей физической организации данных. В базе данных отражается определенная предметная область. Поэтому процесс проектирования БД предусматривает предварительную классификацию объектов предметной области, систематизированное представление информации об объектах и связях между ними. На проектные решения оказывают влияние особенности требуемой обработки данных. Значит, соответствующая информация должна быть определенным образом представлена и проанализирована на начальных этапах проектирования БД. В концептуальной модели должна быть отображена вся информация, циркулирующая в информационной системе. Но это вовсе не означает, что вся она должна храниться в базе данных и все сущности, зафиксированные в концептуальной модели, должны в явном виде отражаться в логической модели. Прежде чем строить логическую модель, необходимо решить, какая информация будет храниться в базе данных. Например, в концептуальной модели должны быть отражены вычисляемые показатели, но вовсе не обязательно, что они должны храниться в базе данных. В связи с этим одним из первых шагов проектирования является определение состава БД, т.е. перечня тех показателей, которые целесообразно хранить в базе данных. Кроме того, не все виды связей, существующие в предметной области, могут быть непосредственно отображены в конкретной логической модели. Так, многие СУБД не поддерживают непосредственно отношение «многие-ко-многим» между элементами. В этом случае в логическую модель вводится дополнительный вспомогательный элемент, отображающий эту связь (таким образом, отношение «многие-ко-многим» как бы разбивается на два отношения «один-ко- многим» между этим вновь введенным элементом и исходными элементами). Пример этого был приведен ранее. Для привязки логической модели к среде хранения используется модель данных физического уровня, для краткости часто называемая физической моделью. Эта модель определяет способы физической организации данных в среде хранения. Модель физического уровня строится с учетом возможностей, предоставляемых СУБД. Описание физической структуры базы данных называется схемой хранения. Соответствующий этап проектирования БД называется физическим проектированием. СУБД обладают разными возможностями по физической организации данных. В связи с этим различаются для конкретных систем сложность и трудоемкость физического проектирования и набор выполняемых шагов. Физическая модель данных описывает данные средствами конкретной СУБД. На этапе физического проектирования учитывается специфика конкретной модели данных и специфика конкретной СУБД. Отношения, разработанные на стадии формирования логической модели данных, преобразуются в таблицы, атрибуты становятся столбцами таблиц, для ключевых атрибутов создаются уникальные индексы, домены преображаются в типы данных, принятые в используемой СУБД. Ограничения, имеющиеся в логической модели данных, реализуются различными средствами СУБД, например при помощи индексов, ограничений целостности, триггеров, хранимых процедур. При этом решения, принятые на уровне логического моделирования, определяют некоторые границы, в пределах которых можно развивать физическую модель данных. Точно также в пределах этих границ можно принимать различные решения. Например, отношения, содержащиеся в логической модели данных, должны быть преобразованы в таблицы, но для каждой таблицы можно дополнительно объявить различные индексы, повышающие скорость обращения к данным. Многое тут зависит от конкретной СУБД. Физическое проектирование БД предполагает также выбор эффективного размещения БД на внешних носителях для обеспечения наиболее эффективной работы приложения. На этапе физического моделирования производятся оценка требований к вычислительным ресурсам, необходимым для функционирования системы, выбор типа и конфигурации ЭВМ, типа и версии операционной системы. Выбор зависит от таких показателей, как: примерный объем данных в БД; динамика роста объема данных; характер запросов к данным (извлечение и обновление отдельных записей, обработка групп записей, обработка отдельных отношений или соединение отношений); интенсивность запросов к данным по типам запросов; требования к времени отклика системы по типам запросов. Выбор СУБД и инструментальных программных средств является одним из важнейших моментов в разработке проекта базы данных, так как он принципиальным образом влияет на весь процесс проектирования БД и реализации информационной системы. Теоретически при осуществлении этого выбора нужно принимать во внимание десятки факторов. Но на практике разработчики руководствуются лишь собственной интуицией и несколькими наиболее важными критериями, к которым, в частности, относятся: тип модели данных, которую поддерживает данная СУБД, адекватность модели данных структуре рассматриваемой ПО; характеристики производительности СУБД; запас функциональных возможностей для дальнейшего развития информационной системы; степень оснащенности СУБД инструментарием для персонала администрирования данными; удобство и надежность СУБД в эксплуатации; стоимость СУБД и дополнительного программного обеспечения. Нормализация таблиц баз данныхС теорией нормализации связана классическая технология проектирования реляционных баз данных. Нормализация представляет собой процесс реорганизации данных путем ликвидации избыточности данных и иных противоречий с целью приведения таблиц к виду, позволяющему осуществлять непротиворечивое и корректное редактирование данных. Цель нормализации сводится к получению оптимальной структуры базы данных с минимальной логической избыточностью. Метод нормализации основан на теории реляционных моделей данных. Исходной точкой является представление предметной области в виде одного или нескольких отношений, и на каждом шаге проектирования производится некоторый набор таблиц, обладающих «улучшенными» свойствами. Процесс проектирования представляет собой процесс нормализации схем отношений. Иными словами, осуществляется декомпозиция отношения, находящегося в предыдущей нормальной форме, в два или более отношения, удовлетворяющих требованиям следующей нормальной формы. В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм: первая нормальная форма (1нф, 1 Normal Form, INF); вторая нормальная форма (2нф, 2NF); третья нормальная форма (Знф, 3NF); нормальная форма Бойса-Кодда (BCNF); четвертая нормальная форма (4нф, 4NF); пятая нормальная форма, или нормальная форма проекции-соединения (5нф, 5NF, или PJ/NF). Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений. Обычно на практике применение находят только первые три нормальные формы, которые и будут рассмотрены далее. Процесс проектирования базы данных с использованием метода нормальных форм является пошаговым. Проектирование начинается с определения всех объектов, информация о которых должна содержаться в базе данных, определения атрибутов этих объектов. Атрибуты всех объектов сводятся в одну таблицу, которая является исходной. Эта таблица приводится к первой нормальной форме в соответствии с ее требованиями. Затем эта таблица декомпозируется на две или несколько таблиц, те, в свою очередь, тоже могут быть преобразованы в другие таблицы. Так последовательно создается совокупность взаимосвязанных таблиц, отвечающих требованиям нормальных форм. На практике обычно используют первые три нормальные формы. Для примера разработаем базу данных для хранения сведений о студентах: ФИО, год рождения, группа, классный руководитель, шифр и наименование специальности. Приведенная таблица имеет довольно простую структуру, на практике таблица содержала бы гораздо больше данных. Но для демонстрации процедуры нормализации этих данных вполне достаточно. Тип и размер полей в данном случае большой роли не играют, поэтому ограничимся только их названиями. Созданную таблицу будем рассматривать как однотабличную базу данных. Для того чтобы таблица соответствовала требованиям первой нормальной формы, должно выполняться следующее условие — поля таблицы должны содержать неделимую (атомарную) информацию. Приведем исходную таблицу к первой нормальной форме. Тогда в таблице «Студенты» будет 6 столбцов: ФИО, Год рождения, Шифр, Специальность, Группа, Классный руководитель (рис. 8.8). 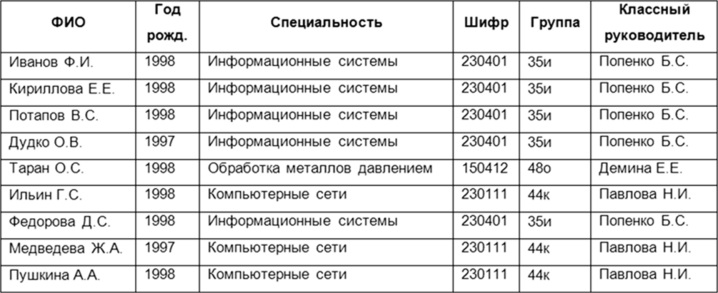 Рис. 8.8. Таблица, соответствующая 1-й нормальной форме Ко второй нормальной форме предъявляются следующие требования: таблица должна удовлетворять требованиям первой нормальной формы; любое неключевое поле должно однозначно идентифицироваться ключевыми полями. Другими словами, таблица находится во второй нормальной форме в том и только в том случае, если эта таблица соответствует первой нормальной форме и каждый неключевой атрибут полностью зависит от первичного ключа. Записи таблицы, приведенной к первой нормальной форме не являются уникальными. Таблица на рис. 8.8 соответствует 1нф, но ввиду отсутствия первичного ключа не соответствует 2нф. Чтобы обеспечить уникальность записей, введем в таблицу ключевое поле — номер студенческого билета. При этом значение ключа будет однозначно идентифицировать каждую запись в таблице (рис. 8.9). Записи этой таблицы имеют значительное избыточное дублирование данных, так как классный руководитель указывается для каждой группы, а наименование специальности — для каждого шифра специальности. Избавиться от дублирования можно, разбив таблицу. При этом таблицы будут соответствовать Знф. 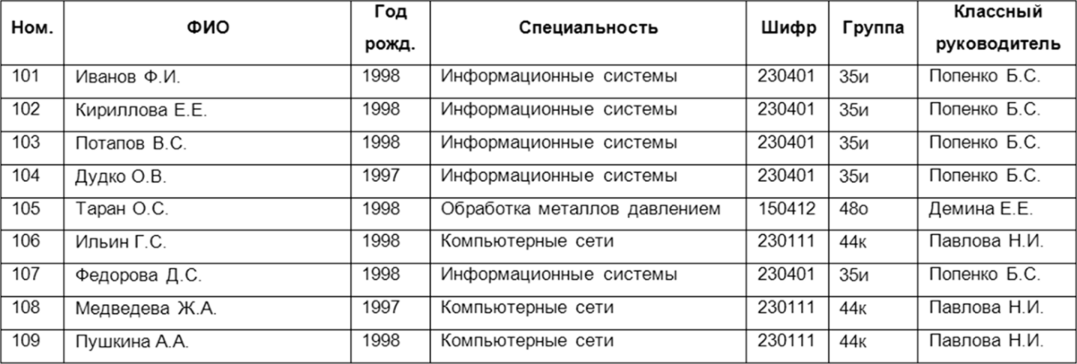 Рис. 8.9. Таблица, соответствующая второй нормальной форме 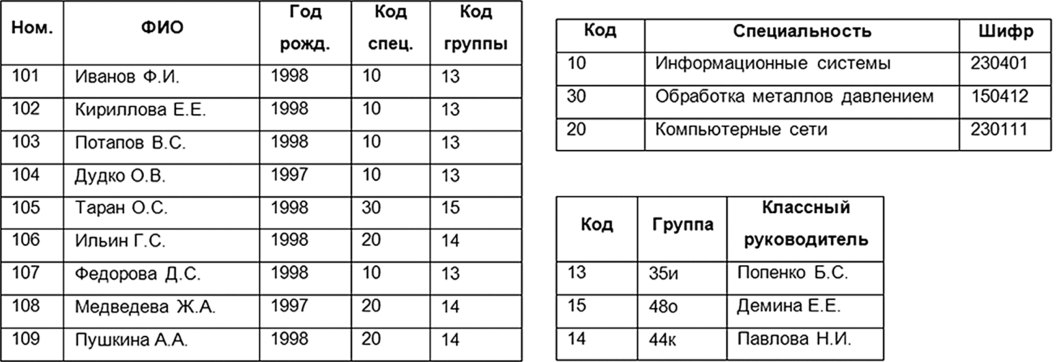 Рис. 8.10. Таблицы в третьей нормальной форме Требования третьей нормальной формы следующие: таблица должна удовлетворять требованиям второй нормальной формы; неключевые поля не зависят друг от друга. На рис. 8.9 таблица не соответствует Знф, потому что значение поля «Классный руководитель» зависит от номера группы, а наименование специальности зависит от шифра, и наоборот. Для того чтобы привести таблицу в соответствие третьей нормальной форме, следует разбить ее на несколько таблиц. Информацию о специальностях и о группах нужно вынести в отдельные таблицы, в каждой из которых определить свой первичный ключ. После приведения к третьей нормальной форме база данных будет иметь структуру, показанную на рис. 8.10. В таблице «Студенты» теперь вместо полной информации о специальности и группе хранится только код специальности и код группы соответственно. Следование требованиям нормальных форм не всегда является обязательным. С ростом числа таблиц усложняется структура базы данных и увеличивается время обработки данных. В ряде случаев для упрощения структуры можно позволить частичное дублирование данных, при этом не допуская нарушения их целостности и соблюдая непротиворечивость. |