М. В. Соколовская должность, уч степень, звание подпись, дата инициалы, фамилия реферат стандарты кодирования файлов по дисциплине информатика
 Скачать 1.16 Mb. Скачать 1.16 Mb.
|

|
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ федеральное государственное автономное образовательное учреждение высшего образования «САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ» КАФЕДРА ПРИКЛАДНОЙ МАТЕМАТИКИ ОЦЕНКА РЕФЕРАТА РУКОВОДИТЕЛЬ
РЕФЕРАТ ВЫПОЛНИЛ
Санкт-Петербург 2022 Содержание Введение 3 Файл 4 Немного истории 6 До изобретения глобальных таблиц кодировки 6 ASCII 8 8 Юникод 9 Графические файлы 11 JPEG 14 PNG 15 Звуковые файлы 16 MP3 18 Заключение 21 Список литературы 23 Введение Известен факт, что двадцать первый век, то есть, нынешний век, называют веком информации. Связано это с тем, что передача информации как таковой стала как никогда быстрой, удобной и простой в понимании для стандартного пользователя. Это возможно благодаря развитой области компьютеров и компьютерных процессов, которые располагают необходимыми для поставленных задач мощностями. В компьютере большое число информационных процессов происходит с использованием кодирования данных. Под кодированием информации понимают процесс преобразования символов, записанных на разных естественных языках (русский язык, арабский язык, английский язык, французский язык, польский язык, итальянский язык, японский язык, китайский язык, и так далее) в цифровое обозначение. Это означает, что при кодировании текста каждому символу присваивается определённое значение в виде нулей и единиц, то есть, байта.  Каждый пользователь компьютера ежедневно сталкивается с большим количеством информации, находящейся в персональном компьютере. Информация это записана и хранится в разных областях в зависимости от своего характера. То есть, компьютерный файл — область с определённой информацией, которая хранится в памяти компьютера. Все файлы четко структурированы в зависимости от своих свойств и расширений. Вся структура называется файловой системой, управление которой осуществляет операционная система компьютера за счет выполнения команд, введённых пользователем (команды также находятся в структуре визуального интерфейса какой-либо программы, поэтому то же нажатие кнопки «отправить» можно заменить командой в терминале, уже написанной за счёт набора символов на клавиатуре). Таким образом, выбранная тема реферата актуальна на сегодняшний день и представляет собой довольно важный аспект современной повседневной жизни человека в эпоху цифровой информации, которую нужно каким-либо образом структурировать, описать, сохранить, индексировать, и которой в конце концов можно пользоваться. Такую функцию и помогает выполнять кодирование файлов, в которых лежит та или иная информация.  Файл Файлы есть в любой компьютерной системе, на любом компьютере, ноутбуке, телефоне или планшете. Благодаря им, мы можем легко взаимодействовать с этими устройствами. Музыка, видео, документы и другой контент всегда доступен нам буквально в пару нажатий и все это, благодаря файлам. Итак, файл — это компьютерный ресурс, который можно изобразить в виде контейнера, предназначенный для хранения выполняемого кода. Все данные в компьютерных системах представляют собой код, этот код и записывается в файлы. Все документы, музыка, видео, игры и другой контент на вашем компьютерном устройстве хранятся в них. Они значительно упрощают взаимодействие человека с компьютерными системами, ведь это удобно, когда данные хранятся в одном контейнере и их можно просто открыть.  Организацией хранения файлов на накопителе информации (SSD, жёсткий диск, флэш-накопитель и так далее) занимается файловая система. Как раз она и позволяет создавать директории. Разделяются файлы на типы по своему назначению и привязке к программному обеспечению. Тип файла пишется в названии после точки, так чтобы операционная система и программное обеспечение могло правильно определить его и вообще открыть. Немного истории Само слово «File» изначально происходит от латинского — «Filum», что переводится, как — нить. Еще в 15 веке словом «Filer» называли размещение документов в последовательном порядке, сшивая их. А самим словом «File» назывались провод или нить на которые были нанизаны документы. Тогда и начали говорить, что — документы находятся в файле. Поэтому, когда появились первые накопители информации и, вообще, возможность записывать данные в электронном виде, такие хранилища первым делом и назвали — File. Впервые это произошло в 1 950 году в рекламе на Radio Corporation of America (RCA), рекламировали они новую вакуумную лампу с памятью, которую сами разработали. Вот эту память так и назвали. Хранилища так называли вплоть до появления концепции файловых систем в 1961, когда на хранилища или накопители информации стало возможным записывать сразу множество файлов. Именно с того времени термин обрел свое нынешнее значение. До изобретения глобальных таблиц кодировки В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.  С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8. Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых. Свои кодировки необходимы и для других стран с уникальным набором символов. Это приводило к путанице и сложностям в обмене информацией. Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым. При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256). ASCII 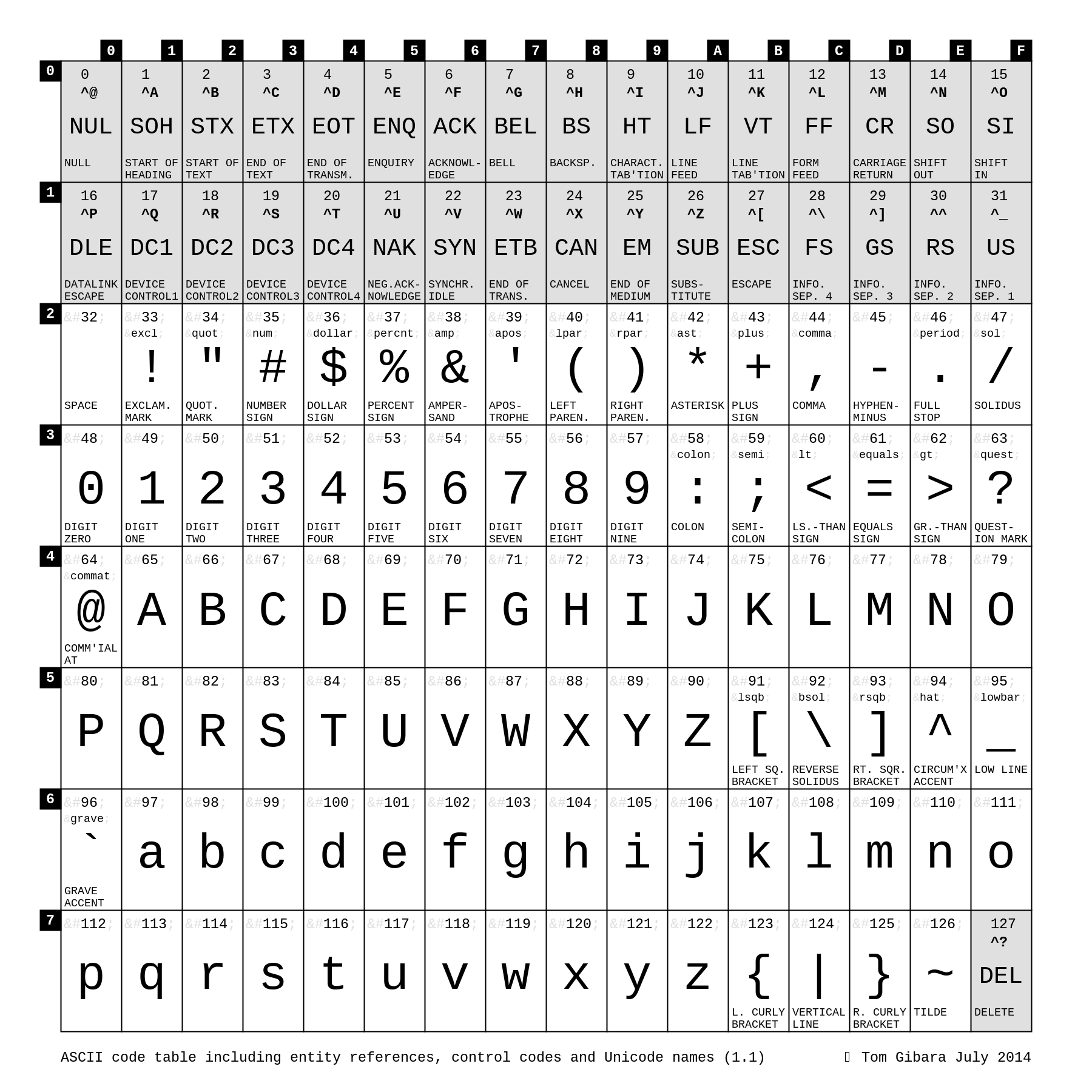 Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией). Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов. Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась. Юникод Юникод – это глобальный стандарт кодировки символов, который используется для привязки кода ко всем существующим письменным знакам и символам, содержащимся во всех языках, используемых для письменного общении во всем мире. Юникод является непревзойденным эталоном кодирования и стандартом для поддержки всех языков мира, за исключением ряда уникальных китайских символов. Юникод необходим всем, кто собирается использовать Java, XML, LDAP, JavaScript и другие языки программирования.  Без кодировки символов нет и Юникода. Кодировка символов – это привязка определенного числа (кода) к заданному символу. Юникод – это общепринятая во всем мире система кодировки символов. Например, английской букве "B" соответствует число 6, a=12, s=15 и т. д. Как своего рода система, Юникод определяет коды для более 128 000 символов. Кроме того, он имеет различные форматы кодировки, которые называются Форматом преобразования Юникода (Unicode Transformation Format - UTF). Это такие форматы как: UTF-8. Это наиболее компактный формат для кодирования различных символов. Для кодирования используется от 1 до 4 байт. Все зависит от конкретного символа. Так для кодирования символов латиницы используется всего один байт или 8 бит. Для кодирования символов других алфавитов используются дополнительные серии битов. Этот формат очень популярен в Интернете и в системах электронной почты. UTF-16. Этот формат для кодирования символов использует 2 байта или 16 битов. Это позволяет представить огромное количество символов, так как для кодирования каждого символа используется полностью 2 байта во всем диапазоне. UTF-32. В этом формате для кодирования символов используется 4 байта или 32 бита. Данный формат появился как расширение технологии кодирования 16 битного формата для решения некоторых его ограничений. Наиболее интересной особенностью этого формата является то, что ему не нужно для представления увеличенных символов использовать пары 32 битных чисел. Он вполне способен представить любой символ Юникода как сплошное 32 битное число. Американский стандартный код для обмена информацией (ASCII) был первым популярным методом кодирования, но он имел ограничения по символам, используя только 128 кодовых определений. Он хорошо подходил для символов латинского алфавита, но с другими алфавитами возникали проблемы. В результате разработчики из других стран начали создавать свои методы кодирования, подходящие для их собственных языков. Результатом стали дебри методов кодирования с весьма ограниченной связью за пределами своих изначальных регионов. Таким образом, в качестве компромисса между разработчиками всего мира появился Юникод. Кодовая точка - это значение, которое приписывается символу в схеме кодирования символов Юникод. Кодовые точки разбиты на 17 различных секций, называемых плоскостями, которые содержат до 65 с половиной тысяч кодовых точек. Эти плоскости нумируются числовыми значениями от 0 до 16. При этом в плоскости с номером 0, содержатся часто повторяющиеся коды. На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях. Графические файлы Пространство непрерывно, а это значит, что в любой его области содержится бесконечное множество точек. Чтобы абсолютно точно сохранить изображение, необходимо запомнить информацию о каждой его точке. Иначе говоря, компьютерное представление некоторого изображения должно содержать информацию о бесконечном количестве точек, для сохранения которой потребовалось бы бесконечно много памяти. Но память любого компьютера конечна. Чтобы компьютер мог хранить и обрабатывать изображения, необходимо ограничиться выделением конечного количества объектов пространства (областей или точек), информация о которых будет сохранена. Информация обо всех остальных точках пространства будет утрачена.  Пространственная дискретизация — способ выделения конечного числа пространственных элементов, информация о которых будет сохранена в памяти компьютера. Цвет и яркость — характеристики, присущие каждому элементу (точке, области) изображения. Их можно измерять, т. е. выражать в числах. И цвет, и яркость — непрерывные величины, результаты измерения которых следует выражать вещественными числами. Но вам известно, что вещественные числа не могут быть представлены в компьютере точно. Квантование — процедура преобразования непрерывного диапазона всех возможных входных значений измеряемой величины в дискретный набор выходных значений. При квантовании диапазон возможных значений измеряемой величины разбивается на несколько поддиапазонов. При измерении определяется поддиапазон, в который попадает значение, и в компьютере сохраняется только номер поддиапазона. Дискретизация и квантование всегда приводят к потере некоторой доли информации. В зависимости от способа формирования графических изображений выделяют векторный и растровый методы кодирования графических изображений. Векторное изображение строится из отдельных базовых объектов — графических примитивов: отрезков, многоугольников, кривых, овалов. Способ создания векторных изображений напоминает аппликацию. Графические примитивы характеризуются цветом и толщиной контура, цветом и способом заливки внутренней области, размером и так далее При сохранении векторного изображения в память компьютера заносится информация о составляющих его графических примитивах. Например, для построения окружности необходимо сохранить такие исходные данные, как координаты её центра, значение радиуса, цвет и толщину контура, цвет заполнения. При этом и большая, и маленькая окружности будут описаны одним и тем же набором данных, то есть реальные размеры объекта не оказывают никакого влияния на размер сохраняемых о нём данных. Фактически векторное представление — это описание, в соответствии с которым происходит построение требуемого изображения. Такого рода описания представляются в компьютере как обычная текстовая информация. Растровое графическое изображение состоит из отдельных маленьких элементов — пикселей (pixel — аббревиатура от английского picture element — элемент изображения). Оно похоже на мозаику, изготовленную из одинаковых по размеру объектов (разноцветных камешков, кусочков стекла, эмали и др.). Растр — организованная специальным образом совокупность пикселей, представляющая изображение. Координаты, форма и размер пикселей задаются при определении растра. Изменяемым атрибутом пикселей является цвет. В прямоугольном растре пиксели составляют прямоугольную матрицу, её основными параметрами являются количество столбцов и строк, составленных из пикселей. Главное преимущество прямоугольных растров заключается в том, что положение каждого пикселя на изображении (или на экране) не надо задавать — его легко вычислить, зная размеры растровой матрицы, плотность размещения пикселей, которую обычно указывают в количестве точек на дюйм, и правила перечисления пикселей (например, слева направо и сверху вниз: сначала слева направо нумеруются все пиксели в верхней строке, затем нумерация продолжается на следующей строке, лежащей ниже, и т. д.). JPEG Легко принять, как само собой разумеющееся, возможность отправить фотографию другу, и не волноваться по поводу того, какое устройство, браузер или операционную систему он использует — однако так было не всегда. К началу 1980-х компьютеры умели хранить и показывать цифровые изображения, однако по поводу наилучшего способа для этого существовало множество конкурирующих идей. Нельзя было просто отправить изображение с одного компьютера на другой и надеяться, что всё заработает. 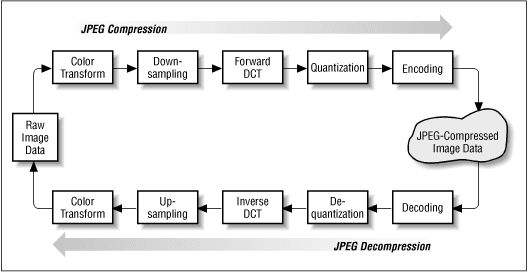 Для решения данной проблемы в 1986 году был собран комитет экспертов под названием "Объединённая группа экспертов по фотографии" (Joint Photographic Experts Group, JPEG), основанный в рамках совместной работы Международной организации по стандартизации (ISO) и Международной электротехнической комиссии (IEC) – двух международных организаций по стандартизации, штаб-квартира которых расположена в Женеве (Швейцария). Группа людей под названием JPEG создала стандарт сжатия цифровых изображений JPEG в 1992 году. Любой человек, использовавший интернет, вероятно, встречался с изображениями в кодировке JPEG. Это самый распространённый способ кодирования, отправки и хранения изображений. От веб-страниц до электронной почты и социальных сетей, JPEG используется миллиарды раз в день — практически каждый раз, когда кто-либо смотрит на изображение онлайн или отправляет его. Без данного формата интернет был бы менее ярким, более медленным, и, вероятно, в нём было бы меньше фотографий котиков, капибар и утят. PNG Файл PNG - растровое изображение, сохраненное в формате Portable Network Graphic. В каждом PNG-рисунке содержится палитра - набор используемых цветов. Для уменьшения размера файла применяется сжатие без потерь качества по алгоритму Deflate. Используется преимущественно в Интернете в качестве изображений для веб-страниц.  Формат был разработан для замены GIF, который, помимо своих недостатков, до 2004 имел ограничения для использования в свободном программном обеспечении. Новый формат PNG решил эти проблемы. В частности, в нем реализована поддержка 8-битного альфа-канала и поддержка глубины цвета до 48 бит. В то время как в GIF-формате возможна только полная прозрачность и цветовая палитра ограничена всего 256 цветами (8 бит). Однако, в отличие от предшественника, этот формат не поддерживает анимацию. С этой целью был создан другой формат MNG. В файлах PNG также невозможно использование палитры CMYK, потому как этот формат не предназначен для профессиональной работы с графикой. Звуковые файлы Как известно, цифровой сигнал — это набор значений уровня сигнала, записанный через заданные промежутки времени. Процесс преобразования непрерывного аналогового сигнала в цифровой сигнал называется дискретизацией (по времени и по уровню). Есть две основные характеристики цифрового сигнала — частота дискретизации и глубина дискретизации по уровню. 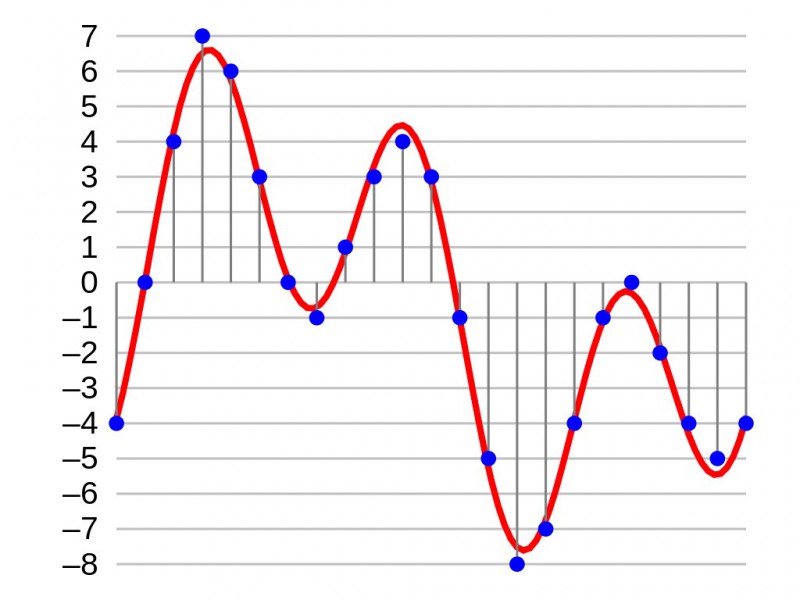 Частота дискретизации указывает на то, с какими интервалами по времени идут данные об уровне сигнала. Существует теорема Котельникова (в западной литературе её упоминают как теорему Найквиста — Шеннона, хотя встречается и название Котельникова — Шеннона), которая утверждает: для возможности точного восстановления аналогового сигнала из дискретного требуется, чтобы частота дискретизации была минимум в два раза выше, чем максимальная частота в аналоговом сигнале. Если брать примерный диапазон воспринимаемых человеком частот звука 20 Гц — 20 кГц, то оптимальная частота дискретизации (частота Найквиста) должна быть в районе 40 кГц. У стандартных аудио-CD она составляет 44.1 кГц. Глубина дискретизации по уровню описывает разрядность числа, которым описывается уровень сигнала. Эта характеристика накладывает ограничение на точность записи уровня сигнала и на его минимальное значение. Стоит специально отметить, что данная характеристика не имеет отношения к громкости — она отражает точность записи сигнала. Стандартная глубина дискретизации на audio-CD — 16 бит. При этом, если не использовать специальную студийную аппаратуру, разницу в звучании большинство перестаёт замечать уже в районе 10-12 бит. Однако большая глубина дискретизации позволяет избежать появления шумов при дальнейшей обработке звука. В цифровом звуке можно выделить три основных источника шумов: Джиттер — Это случайные отклонения сигнала, как правило, возникающие из-за нестабильности частоты задающего генератора или различной скорости распространения разных частотных составляющих одного сигнала. Данная проблема возникает на стадии оцифровки. Шум дробления — Он напрямую связан с глубиной дискретизации. Так как при оцифровке сигнала его реальные значения округляются с определённой точностью, возникают слабые шумы, связанные с её потерей. Эти шумы могут появляться не только на стадии оцифровки, но и в процессе цифровой обработки (например, если сначала уровень сигнала сильно понижается, а затем — снова повышается). Алиасинг — При оцифровке возможна ситуация, при которой в цифровом сигнале могут появиться частотные составляющие, которых не было в оригинальном сигнале. Данная ошибка получила название Aliasing. Этот эффект напрямую связан с частотой дискретизации, а точнее — с частотой Найквиста. MP3 MP3 опирается на два типа компрессии, только один из которых использует психоакустический анализ. Психоакустическая компрессия идеальна для уменьшения сложных по характеру звуков с большим количеством составляющих, т.к. они предоставляют широкие возможности маскировки. Более простые звуки не выигрывают по степени сжатия от психоакустики, но очень легко сжимаются с использованием более традиционных методов компрессии. Совмещение обоих подходов требует двух-проходного процесса квантования и кодирования по Хаффману, взаимодействие которых обеспечивает впечатляющую гибкость сжатия. Вместе с квантованием и масштабированием MP3 кодировщик также использует кодирование по Хаффману – с тем чтобы преобразовать информацию о масштабнокоэффициентных полосах в более короткие двоичные строки. Кодирование Хаффмана (названное так в честь кандидата наук Массачусетского института технологий, разработавшего этот метод в 1952-м году) представляет из себя что-то вроде дедуктивной игры «двадцать вопросов» в двоичном коде. Начиная с верха дерева, содержащего все возможные ответы, компьютер считывает информацию, спускаясь вниз по ветвям, каждой из которых присвоено значение 0 или 1. Ответы содержатся в конце ветви, так что, как только компьютер считывает верный ответ, он прекращает движение по ветви.  Наиболее вероятные ответы расположены близко к вершине (как на примере ниже, который иллюстрирует кодирование наиболее часто встречающихся букв английского языка). Ключевым моментом является именно то, что алгоритм прекращает перемещение по ветви, как только находит ответ. Наиболее часто встречающиеся ответы могут быть записаны в виде очень коротких значений (если код начинается с 1 вместо 0, записывается буква «Е» и немедленно выполняется переход к следующей последовательности). Эти коды могут быть изображены в виде дерева, но для компьютерной программы они – обычная таблица, и как только компьютер находит совпадение, он переходит к следующему символу. MP3 использует несколько таблиц Хаффмана для квантованных значений и может выбирать разные таблицы для представления различных масштабнокоэффициентных полос. Меньшие (менее точные) значения располагаются вверху таблиц. Используя таблицы Хаффмана, кодер регулирует качество для получения на выходе заданного битрейта. Если в конце этапа квантования он обнаруживает, что блок кодированных битов длиннее, чем позволяет битрейт гранулы, кодер возвращается к регулировке коэффициента масштабирования и уменьшает его (таким образом получая на выходе меньше битов, в т.ч. после сжатия по Хаффману). С другой стороны, если кодер не достигает установленного битрейта, он опять же возвращается и увеличивает уровень отдельных частот, тем самым повышая точность квантования. Вот всё, что необходимо для кодирования гранулы. Каждая гранула состоит из двух частей необходимых для восстановления аудио: масштабные коэффициенты для каждой полосы и длинная последовательность битов Хаффмана. Но, как говорилось ранее, MP3 базируется на фреймах, каждый из которых включает две гранулы. После завершения двух гранул, кодер объединяет их в один фрейм для передачи. MP3 файлы имеют довольно простую структуру, с большим количеством аудио данных и ID3 метаданными , записанными в начале файла. Кроме того, фрейм также содержит в своем заголовке большое количество вспомогательной информации. Например, здесь содержится код синхронизации, которым начинается каждый фрейм, именно поэтому декодеры могут проигрывать частично поврежденные файлы. После синхрокода в фрейме находится информация о битрейте, что позволяет некоторым фреймам использовать больший битрейт, если они содержат больше информации (VBR кодирование). Ну и, наконец, в заголовке фрейма располагается информация о количестве каналов (стерео или моно), частоте дискретизации (семплирования), а также пометка о защите материала авторскими правами. Заключение Каждый год количество информации увеличивается, поэтому человечеству придётся придумывать более новые, более усовершенствованные, изящные и хитриые алгоритмы записи всеобъемлющей информации на компьютер. Файлы могут быть сколь угодно большими, но при этом не обладать сколь угодно полезной информацией, которую можно извлечь оттуда. Так массивные файлы с музыкой не слишком практичны в повседневной жизни, так как музыкальных треков много, а телефон всего один, на котором могут либо кончится память, либо пакет гигабайт в месяц, чтобы прогрузить такой большой объём цифровой информации. Для такого рода задач (упрощение и повышение эффективности памяти) и создаются всё новые и новые стандарты хранения и обработки информации, которые зовутся стандартными кодировками или стандартами кодирования файлов.  Таким образом стандартизация файлов помогает человечеству каждый день при поиске необходимой справки, и обычному пользователю не нужно выбирать из десятков тот самый формат, который ему может подойти в конкретной ситуации, ведь гораздо проще пользоваться объединённым стандартом для широкого пользования. Список литературы Де Кастро Виктор Просто криптография. Изд. Страта, 2014 г., - 208 с. https://webnub.ru/dlya-novichkov/kompyuternaya-gramotnost/chto-takoe-fajly-v-kompyutere/ (файлы в компьютере) https://guides.hexlet.io/encoding/ (основные способы кодировки текстовых файлов) Информационная безопасность: основы правовой и технической защиты информации: учебное пособие / В. А. Мазуров, А. В. Головин, В. В. Поляков.- Барнаул: Изд-во Алт. ун-та, 2005. — 196 с. https://msiter.ru/articles/chto-takoe-kodirovanie-simvolov-v-yunikode-utf-ascii (про UTF) https://guides.hexlet.io/encoding/ (ASCII и Unicode) https://murnik.ru/kodirovanie-graficheskoj-informacii (виды графической информации и её представления) https://habr.com/ru/blog/kak-rabotaet-zvuk-na-komputere/ (подробное описание оцифровки звука) http://rain.ifmo.ru/cat/theory/data-compression/jpeg-2006 (стандарт формата JPEG) |