Односв/двухсв бин дерево
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
для выполнения лабораторных работ
по дисциплине “Алгоритмы и структуры данных”
по теме “Динамические структуры данных”
оглавление
1. Динамические структуры данных 3
1.2.Операции с указателями 4
1.3. Работа с памятью при использовании динамических структур 5
1.4. Односвязные списки 5
1.5. Двусвязные списки. 13
1.6. Бинарные деревья. 14
1. Динамические структуры данных
Значения переменных в ходе выполнения программы могут меняться, но объем памяти, выделенный под хранение этих переменных, остается неизменным.
В С++ имеются средства, позволяющие отводить и освобождать память для размещения информации непосредственно по ходу выполнения программы. Для этого прибегают к построению динамических структур данных.
Большинство задач, рассмотренных ранее, требовали работы со статическими переменными, - переменными, которые создаются в момент определения (описания) и уничтожаются автоматически при выходе программы из области их действия. Статические переменные и структуры данных характеризуются фиксированным размером выделенной для них памяти. Например, если описан массив int a[100] под него будет выдела sizeof(int)*100 байт, хотя в самой программе может реально использоваться лишь несколько первых элементов массива. Существуют задачи, которые исключают использование структур данных фиксированного размера и требуют введения динамических структур данных, способных увеличиваться в размерах в процессе работы программы. Если до начала работы с данными невозможно определить, сколько памяти потребуется для их хранения, то память должна выделять по мере необходимости отельными блоками, связанными друг с другом указателями. Динамическая структура может занимать несмежные участки оперативной памяти.
Динамические структуры широко применяют и для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки, поскольку упорядочивание динамических структур не требует перестановки элементов, а сводится к изменению указателей на эти элементы. Например, если в процессе выполнения программы требуется многократно упорядочивать большой массив данных, имеет смысл организовать его в виде динамической структуры.
Для реализации элементов динамической структуры данных в С++ используют тип данных, называемый структура (struct). (В многих языках программирования такой тип данных называют записью).
Структура - это поименованная совокупность поименованных элементов, имеющих в общем случае разный тип, и расположенных в памяти компьютера последовательно. Каждая структура включает в себя один или несколько объектов, называемых элементами структуры. Элементы структуры также называют полями структуры.
Динамические структуры данных – это структуры данных, память под которые выделяется и освобождается по мере необходимости.
1.2.Операции с указателями
1. int *P;
Указатель находится в неопределенном состоянии, после его описания.
P
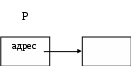
= new int;
Процедура new – отводит место в оперативной памяти под хранение
п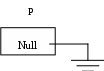
еременной целого типа, и этот адрес вносится в указатель P.
P=Null;
Указатель на пустой адрес (никуда).
d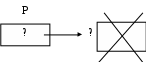
elete P;
Процедура delete освобождает память, занимаемую динамической переменной и она (память) становится доступна для других динамических переменных.
1.3. Работа с памятью при использовании динамических структур
При работе с данными динамической структуры в разделе описаний указывается не сама переменная какого-либо типа, а указатель (ссылка) на нее.
В результате указатель будет обычной переменной, а переменная, на которую он указывает – динамической.
В программах, в которых необходимо использовать динамические структуры данных, работа с памятью происходит стандартным образом. Выделение динамической памяти производится с помощью операции new или с помощью библиотечной функции malloc (calloc). Освобождение динамической памяти осуществляется операцией delete или функцией free.
1.4. Односвязные списки
Динамические переменные можно объединять в связанные динамические структуры.
Для организации связей между элементами динамической структуры, каждый элемент должен содержать информационную часть и указатель.
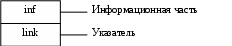
Каждая динамическая структура характеризуется, во-первых, взаимосвязью элементов, и, во-вторых, набором типовых операций над этой структурой. В случае динамической структуры важно решить следующие вопросы:
каким образом может расти и сокращаться данная структура;
каким образом можно включить в структуру новый и удалить существующий элемент;
как можно обратиться к конкретному элементу структуры для выполнения над ним определенной операции.
Из динамических структур в программах чаще всего используют линейные списки, стеки или очереди, а также бинарные деревья.
Самый простой способ связать множество элементов – сделать так, чтобы каждый элемент ссылался на следующей. Такую динамическую структуру называют однонаправленным (односвязанным) линейным списком. Если каждый элемент структуры содержит ссылку как на следующий, так и не предыдущий, то говорят о двунаправленном (двусвязанном) линейном списке.
Например, объявим динамическую структуру данных с именем Student с полями Name, Year и Next, выделим память под указатель на структуру, присвоим значения элементам структуры и освободим память.
struct Student {char Name[20]; //ФИО
int Year; //дата рождения
Student *Next }; //указатель на следующий элемент
Student *P; //объявляется указатель P
P = new Student; //выделяется память = new Student; //выделяется память
P->Name = "Иванов";
P->Value = 1978; //присваиваются значения
P->Next = NULL;
delete P; // освобождение памяти
P->Name – обращение к полям структуры.
Тип указателя на элемент динамической структуры имеет тип структуры.
Рассмотренная динамическая структура называется односвязным списком.
Односвязные списки можно формировать в виде:
очереди: (новый элемент добавляется в конец очереди; а удаляется элемент из начала очереди);
стека: (добавлять и удалять элемент можно только с одного конца списка, который называется вершиной стека).
При работе с очередью применяют указатели на начало (begp) и на конец (endp) очереди.
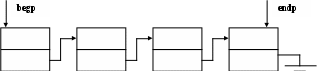
2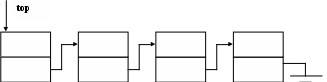 . При создании динамической структуры в виде стека – используют указатель на начало стека – top. . При создании динамической структуры в виде стека – используют указатель на начало стека – top.
Основные операции над односвязными списками:
переход от элемента к элементу;
добавление нового элемента к списку;
исключение элемента из списка;
сортировка элементов.
Ниже в методических указаниях приведены примеры программ, в которых реализованы основные операции над односвязными списками.
Задача: составить программу, формирующую односвязный список в виде стека о товарах некоторого склада и распечатывает созданный список товаров.
Где: top – указатель на начало списка;
p – указатель на текущий элемент.
Ввод прекращается, если вместо количества товаров ввести 0.
s truct stud {char name[10]; truct stud {char name[10];
int kol; Описаниеструктуры
stud *next;
};
#include
#include
using namespace std;
// Рекурсивная функция печати элементов односвязного спмска
void output( struct stud *p)
{if (p==NULL) { cout<<"\n END____ \n";
return; // выход из функции при достижении конца списка
}
cout<<"\n "<
name<<” ”p->kol;
output(p->next);
}
int main()
{ // Объявляются указатели на структур,
// top - указатель на начало списка
// p - указатель на текущий элемент
stud *top,*p;
top = NULL;
do
{ p = new stud; // выделяется память под новый элемент списка
cout<<"\n Ведите наименование "; cin>>p->name;
cout<<"\n Введите количество "; cin>>p->kol;
if (p->kol != 0) {p->next=top; top=p;}
}
while(p->kol!=0);
cout<<"\n____ Стек____ \n";
//Обращение к рекурсивной функции печати элементов стека
output(top);
/ *do *do
{cout<<"\n "<
name;
cout<<"\n "<kol; // Печать элементов стека через цикл
p=p->next;
}
while (p!= NULL);*/
getch(); }
Задача: ввод и создание односвязного списка в виде стека, элементы которого отсортированы по возрастанию. Сортировка элементов выполняется непосредственно при создании списка, т.е. для каждого элемента находится свое место в списке.
Где - top, p, t, n – указатели на вершину, предыдущий, текущий и новый элемент
списка соответственно.
s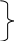 truct stud {char name[10]; truct stud {char name[10];
int kol; Описание структуры
stud *next;
};
#include
#include
#include
using namespace std;
// Рекурсивная функция печати элементов стека
void output( struct stud *p)
{ if (p==NULL) {cout<<"\n END+++++ \n"; return;}
cout<<"\n "<
name<<" "<
kol;
output(p->next);
}
int main()
{
// Описываются указатели (вершина, предыдущий, текущий, новый)
stud *top,*p,*t,*n;
char name[10]; int kol;
top = NULL;
do
{ cout<<"\n Введите наименование "; cin>>name;
cout<<"\n Введите количество "; cin>>kol;
if ( kol !=0 )
{ // Выделение памяти под новый элемент
n = new stud;
strcpy(n->name,name);
n->kol=kol;
n->next=NULL;
t=top; p=NULL;
// Поиск места для нового элемента
if (t!=NULL)
while ( kol > t->kol && t!=NULL)
{ p=t; t=t->next;
if (t==NULL)break;
}
if (p==NULL)
//Вставка элемента в начало списка
{n->next=top; top=n;}
else
// Вставка элемента в конец списка
{ if (t==NULL) {p->next=n; n->next=NULL;}
else
// Вставка элемента в середину списка
{n->next=p->next; p->next=n;}
}
}
} while( kol != 0);
cout<<"\n Stek \n";
output(top); // Печать списка
getch();
}
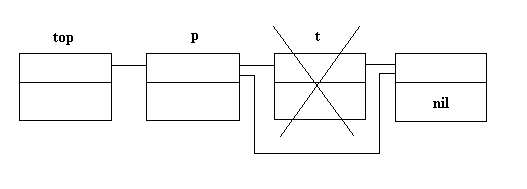
Задача: удаление элемента из односвязного списка.
name – элемент, который необходимо удалить;
top, t, p – указатели на вершину, текущей и предыдущий элемент соответственно;
f – флаг,
f=1 - признак того, что элемент найден.
struct stud {char name[10];
int kol;
stud *next;};
#include
#include
#include
using namespace std;
// Рекурсивная функция печати элементов стека
void output( struct stud *p)
{ if (p==NULL) {cout<<"\n END+++++ \n"; return;}
cout<<"\n "<
name<<" "<
kol;
output(p->next);
}
int main()
{
// Описываются указатели (вершина, предыдущий, текущий, новый)
stud *top,*p,*t,*n;
char name[10]; int kol;
top = NULL;
do
{ cout<<"\n vv name "; cin>>name;
cout<<"\n vv kol "; cin>>kol;
if ( kol !=0 )
{ // Выделение памяти под новый элемент
n = new stud;
strcpy(n->name,name);
n->kol=kol; n->next=NULL;
t=top; p=NULL;
// Поиск места для нового элемента
if (t!=NULL)
while ( kol > t->kol && t!=NULL)
{ p=t; t=t->next;
if (t==NULL)break;
}
if (p==NULL)
//Вставка элемента в начало списка
{n->next=top; top=n;}
else
// Вставка элемента в конец списка
{ if (t==NULL) {p->next=n; n->next=NULL;}
else
// Вставка элемента в середину списка
{n->next=p->next; p->next=n;}
}
}
} while( kol != 0);
cout<<"\n Стек \n";
output(top);
t=top; p=NULL; int f=0;
// ввести наименование товара, который необходимо удалить
cout<<"\n Введите наименование товара \n"; cin>>name;
while ( f==0 && t!=NULL)
{
if ( strcmp(t->name, name)==0)
{
if (p==NULL)
top=t->next; //Удаление первого элемента списка
else p->next=t->next; //Удаление среднего или последнего элемента //delete t;
f=1; // Элемент найден
}
else {p=t; t=t->next;} // Переход к след. элементу
}
if (f==0) cout<<"\n Элемет не найден ! \n";
else {cout<<"\n Stek \n"; output(top);}
getch();
}
1.5. Двусвязные списки.
Двусвязными называются списки, в которых каждый элемент списка имеет указатель не только на последующий, но и на предыдущий элемент списка.
Описание двусвязных списков:
Основные операции над двусвязными списками:
- переход от элемента к элементу;
- сортировка элементов;
- подключение элемента к списку;
- исключение элемента из списка.
Описание двусвязного списка;
struct stud {char name[10];
int kol;
stud *l,*r;
};
Где: l – указатель на предыдущиц элемент списка;
r - указаиель на последующий элемент списка/
Для реализации основных операций над двусвязными списками, можно использовать изложенные выше примеры программ работы с односвязными списками.
.
1.6. Бинарные деревья.
Бинарное дерево - это структура в которой:
есть только один узел, в который не входит ни одного ребра (этот узел называется вершиной);
в каждый узел, кроме вершины, входит только одно ребро;
из каждого узла исходит не более 2-х ребер.
Бинарные деревья позволяют осуществить быстрый поиск данных
Пусть дана последовательность:
100, 20, 120, 130, 50, 15, 30, 35, 25, 55, 60, 110.
При построении бинарного дерева используется следующее правило:
о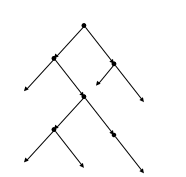
т каждого узла влево-вниз - ставится меньший, а вправо-вниз - больший узел.
Описание бинарного дерева:
s truct stud {char name[10]; информационные поля truct stud {char name[10]; информационные поля
int kol;
stud *l,*r;
};
Где; l - указатель на узел, стоящий влево-вниз;
r - указатель на узел, стоящий вправо-вниз.
Задача: создание бинарного дерева, отсортированного по полю “kol” (количество).
Где: top, n – вершина дерева и новый узлы дерева соответственно.
В данной задаче использованы следующие рекурсивные функции:
insert – вставка нового элемента в дерево;
outrec – обход бинарного дерева и печать.
struct stud {char name[10];
int kol;
stud *l,*r;
};
#include
#include
#include
using namespace std;
// Рекурсивная функция - вставка узла в дерево
struct stud *insert( struct stud *n,struct stud *top )
{
if (top==NULL){ top=n; n->r=NULL; n->l=NULL;}
else
if ( n->kol < top->kol ) top->l=insert(n,top->l);
else top->r=insert(n,top->r);
return (top); // возвращает указатель на вершину дерева
}
// Рекурсивная функция - обход дерева и печать узлов
void output(struct stud *top)
{
if (top->l!=NULL) output(top->l);
cout<<"\n "<name<<" "<kol<<"\n";
if (top->r!=NULL) output(top->r);
}
int main()
{
stud *top,*n; // описание указателей(вершина, новый)
char name[10]; int kol;
top = NULL;
do
{ cout<<"\n Name "; cin>>name;
cout<<"\n Kol "; cin>>kol;
if ( kol !=0 )
{ n = new stud; // выделение памяти под новый узел
strcpy(n->name,name);
n->kol=kol;
top=insert(n,top); //вставка нового узла в дерево
}
} while (kol!=0);
cout<<"\n ++++++++++++++++++++++++\n";
cout<<"\n Вершина - "<kol<<"\n";
cout<<"\n Дерево\n";
output(top); //обход дерева и печать узлов
getch();
}
https://prog-cpp.ru/data-tree/
Составитель:
ст. преподаватель _______________ Д.М.Ахмедханлы
|
 Скачать 0.57 Mb.
Скачать 0.57 Mb.