МУ_ЛР_ЛиПОАС. Методические указания по выполнению лабораторных работ по дисциплине (модулю) Лингвистическое и программное обеспечение автоматизированных систем
 Скачать 2.76 Mb. Скачать 2.76 Mb.
|

2.2. Разработка синтаксического анализатораПосле получения списка лексем необходимо ответить на вопрос: в правильном ли порядке они идут? Из грамматики языка очевидно, что, к примеру, последовательность лексем ID – PLUS – NUMBER является верной, а последовательность ID – ID – MINUS – неверной. Программа-распознаватель должна ответить на вопрос, допустима ли предлагаемая последовательность лексем в рамках грамматики того или иного языка. Существуют различные методы построения анализаторов. Один из основных – метод нисходящего разбора, при котором диаграмма Вирта фактически является блок-схемой процедур распознавания. Основная программа будет состоять из оператора чтения первой лексемы, за которым следует оператор активации основной цели грамматического разбора. Отдельные процедуры, соответствующие целям грамматического разбора или графам, получаются по следующим правилам. Правила преобразования графа в программу: 1. Свести систему графов к как можно меньшему числу отдельных графов с помощью соответствующих подстановок. 2. Преобразовать каждый граф в описание процедуры в соответствии с приведенными ниже правилами З-7. 3. Последовательность элементов  S1 S2 Sn … переводится в составной оператор T(S1); T(S2); ...; T(Sn) 4. Выбор элементов 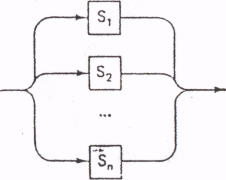 переводится в выбирающий или условный оператор: переводится в выбирающий или условный оператор:switch (ch) { case L1: T(S1); break; case L2: T(S2); break; ………… case Ln: T(Sn); break; default: error; } if (ch == L1) T(S1); else if (ch == L2) T(S2); else …………… if (ch == Ln) T(Sn); else error; где Li означает множество начальных символов нетерминального символа Si. Если Li состоит из одного символа a, то, разумеется, вместо ch in Li нужно писать ch == а. 5. Цикл вида 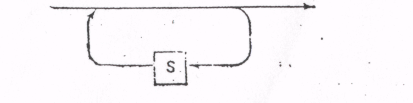 while (ch == L[i]) T(S); переводится в оператор где T(S) есть отображение S в соответствии с правилами З-7, a L есть множество начальных символов нетерминального символа S (см. предыдущее правило). 6 Элемент графа, обозначающий другой граф А 7. Элемент графа, обозначающий терминальный символ, if (ch = x) ReadLex(ch); else error; переводится в: где error - процедура, к которой обращаются при появлении неправильной конструкции; ReadLex(ch) – процедура чтения следующей лексемы в переменную ch. 2.3. Пример построения простого синтаксического анализатораРеализуем синтаксический анализатор в виде следующего класса: public partial class TSyntaxAnalyzer { private string Ferr; //Сообщение об ошибке private ushort FerrPos; //Позиция ошибки во входной строке private Tresult[] Flex; //Входной массив лексем после лексического разбора private Int32 Count; //Номер текущей лексемы public ushort ErrorPos { get { return FerrPos; } } public String Error { get { return Ferr; } } public TSyntaxAnalyzer(Tresult[] Lexems) //Конструктор { Ferr = ""; FerrPos = 0; Flex = Lexems; Count = 0; } Как видно, при создании объекта класса TSyntaxAnalyzer его конструктору на вход подается массив лексем, сформированный ранее лексическим анализатором. В методе GetLex в случае, если лексемы в массиве кончились, всегда возвращается лексема FINISH. private Tresult GetLex() { if (Count <= Flex.Length - 1) { Count++; return Flex[Count - 1]; } else { Tresult FinishRes; FinishRes.lexeme = "FINISH"; FinishRes.name = ""; FinishRes.value = 0; FinishRes.position = 0; return FinishRes; } } Самое сложное – процедура PARSE, отвечающая на вопрос соответствия заданной последовательности лексем грамматике языка. Ее алгоритм программируется в точном соответствии с правилом грамматики: Для удобства введены два константных множества Operation и Item. Алгоритм имеет следующий вид: public void Parse() { string[] Operation = { "PLUS", "MINUS" }, item = { "ID", "NUMBER" }; Tresult Curlex = GetLex(); do { if (Array.IndexOf(item, Curlex.lexeme) != -1) { Curlex = GetLex(); if (Curlex.lexeme == "FINISH") break; do { if (Array.IndexOf(Operation, Curlex.lexeme) != -1) { Curlex = GetLex(); if (Array.IndexOf(item, Curlex.lexeme) == -1) { Ferr = "Синтаксическая ошибка. Ожидается слагаемое"; FerrPos = Curlex.position; break; } } else { Ferr = "Синтаксическая ошибка. Ожидается операция"; FerrPos = Curlex.position; break; } Curlex = GetLex(); } while (Curlex.lexeme != "FINISH"); } else { Ferr = "Синтаксическая ошибка. Неизвестная лексема!"; FerrPos = Curlex.position; break; } } while (Curlex.lexeme != "FINISH"); } Все! Легко убедиться, что данный синтаксический анализатор действительно корректно проверяет введенное выражение. |