Конспекты лекций. Конспект лекций. Микропроцессорные устройства систем управления
 Скачать 0.73 Mb. Скачать 0.73 Mb.
|

5.3. Многопроцессорные системы с локальной памятью и многомашинные системыСуществуют два различных способа построения крупномасштабных систем с распределенной памятью. Простейший способ заключается в том, чтобы исключить аппаратные механизмы, обеспечивающие когерентность кэш-памяти, и сосредоточить внимание на создании масштабируемой системы памяти. Несколько компаний разработали такого типа машины. Наиболее известным примером такой системы является компьютер T3D компании Cray Research. В этих машинах память распределяется между узлами (процессорными элементами) и все узлы соединяются между собой посредством того или иного типа сети. Доступ к памяти может быть локальным или удаленным. Специальные контроллеры, размещаемые в узлах сети, могут на основе анализа адреса обращения принять решение о том, находятся ли требуемые данные в локальной памяти данного узла, или размещаются в памяти удаленного узла. В последнем случае контроллеру удаленной памяти посылается сообщение для обращения к требуемым данным. Чтобы обойти проблемы когерентности, разделяемые (общие) данные не кэшируются. Конечно, с помощью программного обеспечения можно реализовать некоторую схему кэширования разделяемых данных путем их копирования из общего адресного пространства в локальную память конкретного узла. В этом случае когерентностью памяти также будет управлять программное обеспечение. Преимуществом такого подхода является практически минимальная необходимая поддержка со стороны аппаратуры, хотя наличие, например, таких возможностей как блочное (групповое) копирование данных было бы весьма полезным. Недостатком такой организации является то, что механизмы программной поддержки когерентности подобного рода кэш-памяти компилятором весьма ограничены. Существующая в настоящее время методика в основном подходит для программ с хорошо структурированным параллелизмом на уровне программного цикла. Машины с архитектурой, подобной Cray T3D, называют процессорами (машинами) с массовым параллелизмом (MPP Massively Parallel Processor). К машинам с массовым параллелизмом предъявляются взаимно исключающие требования. Чем больше объем устройства, тем большее число процессоров можно расположить в нем, тем длиннее каналы передачи управления и данных, а значит и меньше тактовая частота. Происшедшее возрастание нормы массивности для больших машин до 512 и даже 64К процессоров обусловлено не ростом размеров машины, а повышением степени интеграции схем, позволившей за последние годы резко повысить плотность размещения элементов в устройствах. Топология сети обмена между процессорами в такого рода системах может быть различной. На рис.5.5 приведены характеристики сети обмена для некоторых коммерческих MPP. Для построения крупномасштабных систем альтернативой рассмотренному в предыдущем разделе протоколу наблюдения может служить протокол на основе справочника, который отслеживает состояние кэшей. Такой подход предполагает, что логически единый справочник хранит состояние каждого блока памяти, который может кэшироваться. В справочнике обычно содержится информация о том, в каких кэшах имеются копии данного блока, модифицировался ли данный блок и т.д. В существующих реализациях этого направления справочник размещается рядом с памятью. Имеются также протоколы, в которых часть информации размещается в кэш-памяти. Положительной стороной хранения всей информации в едином справочнике является простота протокола, связанная с тем, что вся необходимая информация сосредоточена в одном месте. Недостатком такого рода справочников является его размер, который пропорционален общему объему памяти, а не размеру кэш-памяти. Это не составляет проблемы для машин, состоящих, например, из нескольких сотен процессоров, поскольку связанные с реализацией такого справочника накладные расходы можно преодолеть. Но для машин большего размера необходима методика, позволяющая эффективно масштабировать структуру справочника. 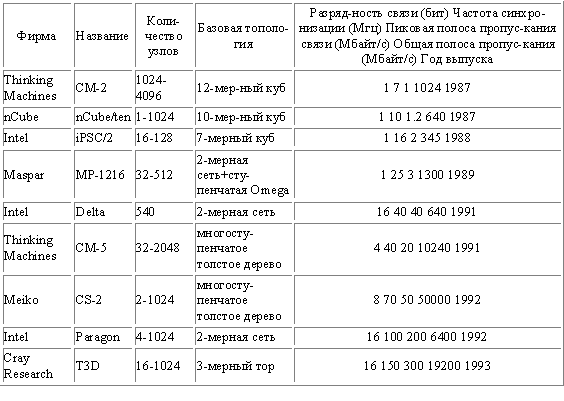 Рис.5.5. Характеристики межсоединений некоторых коммерческих MPP В частности, чтобы предотвратить появление узкого горла в системе, связанного с единым справочником, можно распределить части этого справочника вместе с устройствами распределенной локальной памяти. Таким образом можно добиться того, что обращения к разным справочникам (частям единого справочника) могут выполняться параллельно, точно также как обращения к локальной памяти в распределенной памяти могут выполняться параллельно, существенно увеличивая общую полосу пропускания памяти. В распределенном справочнике сохраняется главное свойство подобных схем, заключающееся в том, что состояние любого разделяемого блока данных всегда находится во вполне определенном известном месте. На рис.6 показан общий вид подобного рода машины с распределенной памятью. Вопросы детальной реализации протоколов когерентности памяти для таких машин выходят за рамки настоящего обзора. 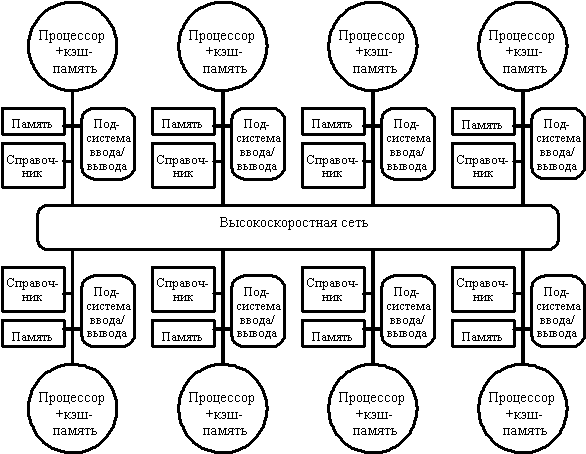 Рис. 5.6. Архитектура системы с распределенной внешней памятью и распределенным по узлам справочником 5.4. ТранспьютерыТранспьютер (transputer = transfer (передатчик) + computer (вычислитель)) является элементом построения многопроцессорных систем, выполненном на одном кристалле СБИС (рис. 5.7, а). Он включает средства для выполнения вычислений (центральный процессор, АЛУ для операций с плавающей запятой, внутрикристальную память объемом 2...4 кбайта) и 4 канала для связи с другими транспьютерами и внешними устройствами. Встроенный интерфейс позволяет подключать внешнюю память объемом до 4 Гбайт. 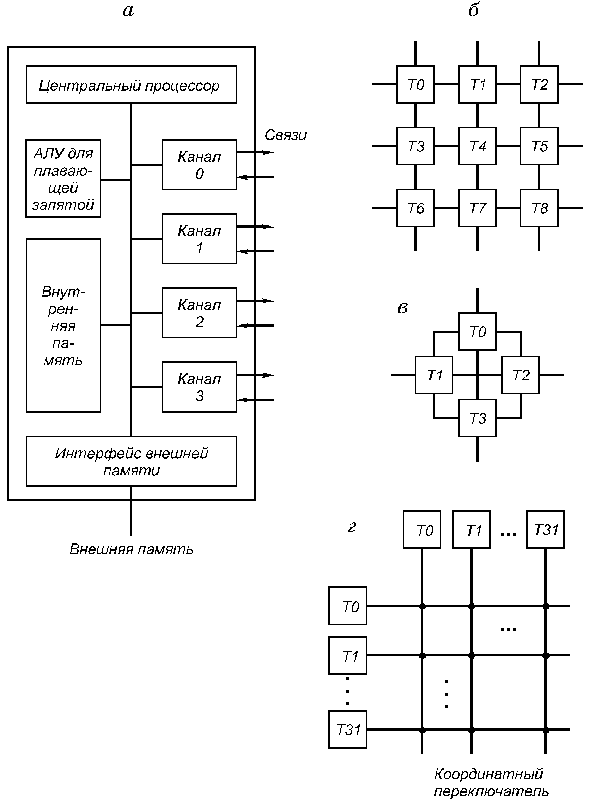 Рис. 5.7.Структура транспьютера и систем на его основе Для образования транспьютерных систем требуемого размера каналы различных транспьютеров могут соединяться непосредственно (рис. 5.7, б, в) или через коммутаторы типа координатный переключатель на 32 входа и выхода, который обеспечивает одновременно 16 пар связей (рис. 5.7, г). Такие переключатели могут настраиваться программно или вручную и входят в комплект транспьютерных СБИС. Размер транспьютерных систем не ограничен, а структура системы может быть сетевой, иерархической или смешанной. Организация транспьютеров основана на языке Оккам (Occam), разработанном под руководством Хоара (C.A.R.Hoar) в 1984 году. Основой языка являются: средства описания параллелизма выполняемых процессов; средства описания межпроцессорного обмена данными; средства описания размещения процессов по единицам оборудования. Состав оборудования транспьютера представлен на рис. 5.7. Рассмотрим особенности его структуры. Каждый канал транспьютера физически состоит из двух одноразрядных каналов, один для работы в прямом, другой - для работы в обратном направлении, обозначаемые как link.in и link.out. Один канал транспьютера соответствует двум каналам языка Оккам. Поскольку каждый канал транспьютера имеет автономное управление, то все каналы могут работать независимо друг от друга и от процессоров транспьютера. АЛУ транспьютера, а значит, и система команд строятся по стековому принципу. На рис. 5.8 представлена регистровая структура центрального процессора. 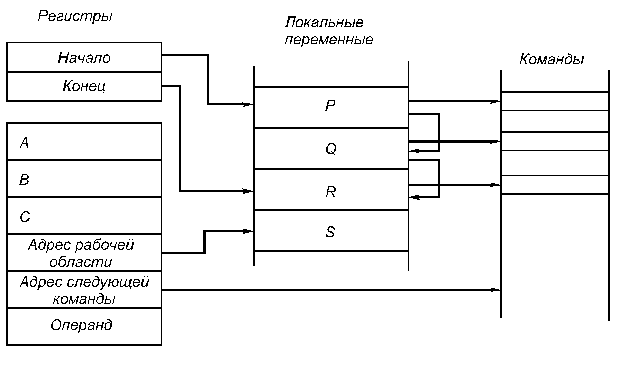 Рис. 5.8. регистровая структура центрального процессора транспьютера В ЦП используются 6 регистров по 32 разряда каждый: указатель рабочей области для локальных переменных программы; указатель следующей команды; регистр операндов, в котором формируются операнды и команды; A, B и C - регистры, образующие вычислительный стек. В вычислительном стеке выполняются не только арифметические и логические операции, но и команды планирования параллельных процессов и коммуникаций, в него записываются параметры при вызове процедур и др. Наличие вычислительного стека устраняет необходимость задания в командах явного указания регистра. Например, команда ADD складывает значения из регистров A и B, помещает результат в A и копирует C в B. Поэтому большинство команд транспьютера (70-80%) являются однобайтовыми. В транспьютере, кроме вычислительного стека ЦП для целочисленной арифметики, имеется стек для работы над данными с плавающей запятой с регистрами AF, BF, CF. Список команд транспьютера включает 110 команд. Они делятся на две группы: с прямой адресацией (один байт) и с косвенной адресацией (два или более байтов). Транспьютер может одновременно обрабатывать любое число параллельных процессов. Он имеет специальный планировщик, который производит распределение времени между ними. В любой момент времени параллельные процессы делятся на два класса: активные процессы (выполняются или готовы к выполнению) и неактивные процессы (ожидают ввода-вывода или определенного времени). Активные процессы, ожидающие выполнения, помещаются в планировочный список. Планировочный список является связным списком рабочих областей этих активных процессов в памяти и задается значениями двух регистров, один из которых указывает на первый процесс в списке, а другой - на последний. Состояние процесса, готового к выполнению, сохраняется в его рабочей области. Состояние определяется двумя словами - текущим значением указателя инструкций и указателем на рабочую область следующего процесса в планировочном списке. В ситуации, изображенной на рис. 5.8, имеется четыре активных процесса, причем процесс S выполняется, а процессы P, Q и R ожидают выполнения в планировочном списке. Команда транспьютера start process создает новый активный процесс, добавляя его в конец планировочного списка. Перед выполнением этой команды в A-регистр вычислительного стека должен быть загружен указатель инструкций этого процесса, а в B-регистр - указатель его рабочей области. Команда start process позволяет новому параллельному процессу выполняться вместе с другими процессами, которые транспьютер обрабатывает в данное время. Команда end process завершает текущий процесс, убирая его из планировочного списка. В Оккаме конструкция PAR - параллеьного запуска процессов может закончиться только тогда, когда завершатся все ее компоненты параллельного процесса. Каждая команда start process увеличивает их число, а end process уменьшает. В транспьютере предусмотрен специальный механизм учета числа незавершившихся компонент данной параллельной конструкции (необходимо учитывать как активные, так и неактивные процессы). При обработке параллельных процессов на самом деле присутствует не один, а два планировочных списка - список высокого приоритета и список низкого приоритета. Процессы с низким приоритетом могут выполняться только тогда, когда список высокого приоритета пуст, что должно быть его нормальным состоянием. Процессы с высоким приоритетом обычно вводятся для обеспечения отклика системы на них в реальном времени. Коммуникации между параллельными процессами осуществляются через каналы. Для организации этого объема используются команды транспьютера "input message" и "output message". Эти команды используют адрес канала, чтобы установить, является он внутренним (в том же транспьютере) или внешним. Внутренний канал реализуется одним словом памяти, а обмен осуществляется путем пересылок между рабочими областями этих процессов в памяти транспьютера. Несмотря на принципиальные различия в реализации внутренних и внешних каналов команды обмена одинаковы и различаются только адресами. Это позволяет осуществить компиляцию процедур безотносительно к способу реализации каналов, а следовательно, и к конфигурации вычислительной системы. Рассмотрим пересылку данных по внешнему каналу. Команда пересылки направляет автономному канальному интерфейсу задание на передачу данных и приостанавливает выполнение процесса. После окончания передачи данных канальный интерфейс помещает этот процесс в планировочный список. Во время обмена по внешнему каналу оба обменивающихся процесса становятся неактивными. Это позволяет транспьютеру продолжать обработку других процессов во время пересылки через более медленные внешние каналы. Каждый канальный интерфейс использует три своих регистра, в которые загружаются указатель на рабочую область процесса, адрес пересылаемых данных и количество пересылаемых байтов. В следующем примере процессы P и Q, которые выполняются на различных транспьютерах, обмениваются данными по внешнему каналу C, реализованному в виде линии связи, соединяющей эти два транспьютера (рис. 5.9). Пусть P передает данные, а Q принимает (рис. 5.9, а). Когда процесс P выполняет команду output message, регистры канального интерфейса транспьютера, на котором выполняется P, инициализируются, а процесс P прерывается и становится неактивным. Аналогичные действия происходят в другом транспьютере при выполнении процессом Q команды input message (рис. 5.9, б). Когда оба канальных интерфейса инициализированы, происходит копирование данных по межтранспьютерной линии связи. После этого процессы P и Q становятся активными и возвращаются в свои планировочные списки (рис. 5.9, в). Для пересылки данных используется простой протокол, не зависящий от разрядности транспьютера, что позволяет соединять транспьютеры разных типов. 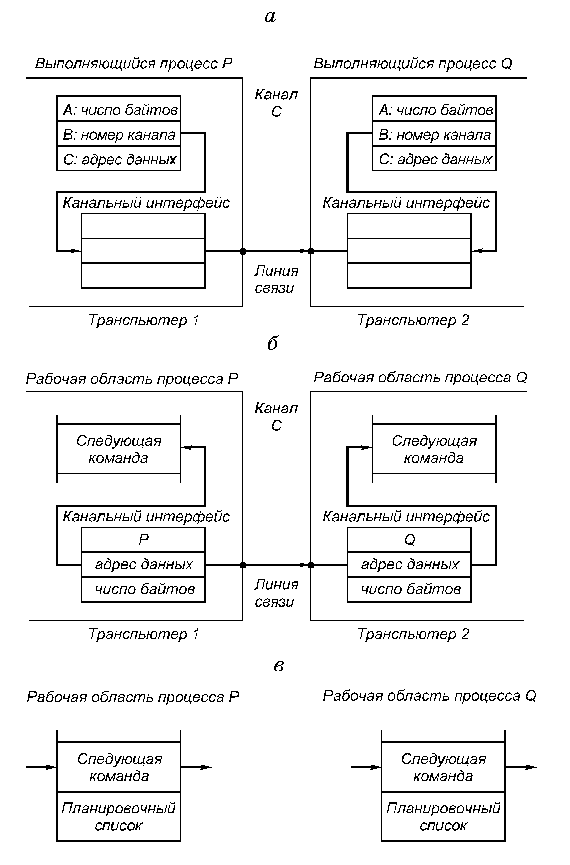 Рис. 5.9. Пересылка данных по внешнему каналу Сообщения передаются в виде отдельных пакетов, каждый из которых содержит один байт данных, поэтому наличие буфера в один байт в принимающем транспьютере является достаточным для исключения потерь при пересылках. После отправления пакета данных транспьютер ожидает получения пакета подтверждения от принимающего транспьютера. Пакет подтверждения показывает, что процесс-получатель готов принять этот байт и что канал принимающего транспьютера может начать прием следующего байта. Форматы пакетов данных и пакетов подтверждения показаны на рис. 5.10. 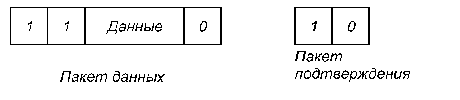 Рис. 5.10. Форматы пакетов данных и пакетов подтверждения Протокол передачи пакета данных позволяет отсылать пакет подтверждения, как только транспьютер идентифицировал начало пакета данных. Подтверждение может быть получено передающим транспьютером еще до завершения передачи всего пакета данных, и поэтому пересылка данных может быть непрерывной, то есть без пауз между пакетами. В последних модификациях транспьютеров для упрощения программирования и увеличения пропускной способности физиче-ских каналов связи используется процессор виртуальных каналов VCP (Virtual Chanal Processor). VCP позволяет использовать на этапе программирования неограниченное число виртуальных каналов. |