математические методы. методы математические. Министрество науки и высшего образования рф
 Скачать 78.93 Kb. Скачать 78.93 Kb.
|

|
Министрество науки и высшего образования РФ Федеральное государственное автономное образовательное учреждение высшего образования «Пермский государственный национальный исследовательский университет» Региональный институт непрерывного образования Центр психологического образования Математические методы в психологии Выполнил слушатель ЦПО РИНО ПГНИУ курсов профессиональной переподготовки по Дополнительной профессиональной прогамме «Психология» Федосеева Ирина Преподаватель: Дериш Ф.В. Пермь ,2022 1.Измерение и шкалирование в психологии. Виды шкал по Стивенсу и свойства чисел. Измерение в психологии – научный метод представления числами интересующего психического свойства или параметров психического процесса на основании некоторых процедурных правил. Шкалирование в психологии – это совокупность экспериментальных и математических приемов для измерения особенностей психических процессов и состояний. Под шкалированием психических процессов, свойств, объектов или событий понимается процесс приравнивания к этим процессам, свойствам, объектам или событиям чисел по определенным правилам, а именно таким образом, чтобы в отношениях чисел отображались отношения явлений, подлежащих измерению. Шкала (лат.-лестница) – инструмент для измерения непрерывных свойств; шкала представляет собой числовую систему в которой отношения между разными свойствами объектов выражены свойствами числового ряда. Основываясь на правилах измерения, принято различать несколько типов шкал, с каждым из которых могут быть соотнесены конкретные процедуры шкалирования. При этом каждый тип шкалы может быть охарактеризован соответствующими числами, свойствами. С. Стивенсоном предложена классификация из 4х типов шкал измерения. Шкала наименований- простейшая из шкал измерения. Отражает те отношения, посредством которых обьекты группируются в отдельные непересекающиеся классы. Пример: классификация испытуемых на мужчин и женщин, нумерация игроков отдельных команд и др. Эти переменные не отражают отношений больше-меньше. Порядковая шкала .отображает отношения порядка. Единственно возможныеотношения между обьектами измерения в этой шкале- это больше-меньше, лучше-хуже. Интервальная шкала-помимо оьношений, указанных для шкал наименования и порядка, отображает отношения расстояния (разности) между обьектами. Разности между соседними точками в этой шкале равны. Большинство психологических тестов содержат нормы, которые являются образцом интервальной шкалы. Где ноль- это минимально возможный балл теста.[2стр 12] Непсихологический пример шкалы интервало- шкала градусов Цельсия. Шкала отношений может отображать то, во сколько один показатель больше другого . шакла отношений имеет нулевую точку, которая характеризует полное отсутствие измеряемого качества. С помощью таких шкал могут быть измерены масса, длина, сила, то есть все, что имеет гипотетически абсолютный ноль. Свойствами чисел являются идентичность, порядок, количество. 2.Репрезентативность Представляет собой такое свойство выборки, которое позволяет распространить полученные результаты исследования, проведенного в отношении частных подгрупп, на всю генеральную совокупность. Данное правило успешно распространяется на качественные и количественные исследования при условии их грамотной реализации. 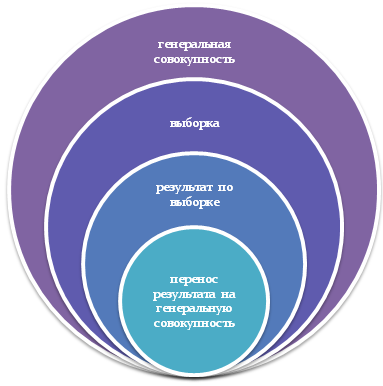 репрезентативность выборки репрезентативность выборкиЕсли распространить полученные результаты исследования невозможно на более широкий круг, то такая выборка будет нерепрезентативной. Фактически репрезентативность выборки демонстрирует связь выборки с генеральной совокупностью. Приведем пример репрезентативной и нерепрезентативной выборки. Допустим, Вы провели социологический опрос населения. Ключевой вопрос исследования – устраивает ли Вас текущий уровень зарплаты? Допустим, в опросе приняло участие 100 человек. В результате Вы получили следующие данные: 18% респондентов негативно относятся к жаре, более 70% — положительно, 12% — затруднились ответить. В данном виде невозможно распространить результаты опроса на всех людей, так как в нем могли принять участие и неработаюшие люди, и иждивенцы и пр. Значит, данная выборка нерепрезентативна.[2стр 18] . Репрезентативная – выборка адекватно отображающая генеральную совокупность в качественном и количественном отношениях. Выборка должна адекватно отображать генеральную совокупность, иначе результаты не совпадут с целями исследования. Репрезентативность зависит от объема, чем больше объем, тем выборка репрезентативней По способу отбора . Случайная – если элементы отбираются случайным образом. Неслучайная выборка: • механический отбор, когда вся совокупность делится на столько частей, сколько единиц планируется в выборке и затем из каждой части отбирается один элемент; • типический отбор – совокупность делится на гомогенные части, и из каждой осуществляется случайная выборка; • серийный отбор – совокупность делят на большое число разновеликих серий, затем делают выборку одной какой-либо серии; • комбинированный отбор – сочетаются рассматриваемые виды отбора, на разных этапах. По схеме испытаний – выборки могут быть независимые и зависимые. По объему выборки делят на малые и большие. Малые выборки используются при статистическом контроле известных свойств уже изученных совокупностей. Большие выборки используются для установки неизвестных свойств и параметров совокупности 3.Понятие статистических гипотез и их виды Статистическая гипотеза- это предположение относительно неизвестного параметра генеральной совокупности, которая формулируется для проверки надежности связи и котрую можно проверить по изаестным выборочным статистикам- результаты исследования. Выделяют основную (нулевую) и альтернативную ститистические гипотезы. Основная содержит утверждение об отсутствии связи в генеральной совокупности и доступа проверке методами статистического вывода Альтернативная гипотеза- принимается при отклонении нулевой и содержит утвержение о наличии связи. При этом нулевая и альтернативная гипотезы представляют собой, в терминах теории вероятности, полную группу несовместимых событий, если верна одна из них, то другая является ложной, и наоборот,отклонение одной из них неизбежно влечет принятие другой. 4.Уровень значимости. Ошибки первого и второго рода. Уровень значимости- основной результат проверки статистической гипотезы. Это вероятность получения данного результата выборочного исследования при условии, что на самом деле , для генеральной совокупности верна нулевая статистическая гипотеза-то есть, связи нет. Иначе говоря, это вероятность того, что обнаруженная связь носит случайный характер, а не является свойствами совокупности. Именно статистическая значимость, p- уровень значимости является количественной оценкой надежности связи: чем меньше эта вероятность, тем надежней связь.В отношении научной гипотезы уровень статистической значимости - это количественный показатель степени недоверия к выводу о наличии связи, вычисленный по результатам выборочной, эмпирической проверки этой гипотезы. Чем меньше значение р-уровня, тем выше статистическая значимость результата исследования, подтверждающего научную гипотезу. Уровень значимости при прочих равных условиях выше (значение р-уровня меньше) если: • величина связи (различия) больше • изменчивость признака (признаков) меньше • объем выборки (выборок) больше [1 стр 99] Основанием для принятия исследователем решения о том, какая гипотеза верна, является р-уровень - вероятность того, что верна все-таки нулевая гипотеза. Но принимая решение, исследователь всегда допускает вероятность его ошибочности: ведь исследование проведено на выборке, а вывод делается относительно генеральной совокупности. Ошибка первого рода-ошибка сосотящая в том, что мы отклонили нулевую гипотезу, в то время, как она верна. Ошибка второго рода-мы приняли нулевую гипотезу, в то время, как она верна.[3] 5.Понятие статистического критерия и его виды. Статистический критерий- это инструмент определения уровня статистической значимости (p). Проверки статистических гипотез, в качестве основы для применения статистических критериев, используют теоретическое распределение, для условия, когда верна нулевая гипотеза. Критерий так же подразумевает формулу, позволяющую соотнести эмпирическое значение выборочной статистики с этим теоретическим распределением. Применяя эту формулу, исследователь вычисляет эмпирическое значение критерия, которое позволяет определить р-уровень - значения вероятности того, что нулевая статистическая гипотеза верна.[1 стр100] Уровень значимости- это вероятность ошибиться, признав полученные результаты достоверными -вероятность истинности h0 Чем меньше p, тем более вероятно, что связь( различие) существует Типы статистических критериев: .• Параметрические - основаны на конкретном распределении генеральной совокупности (как правило, нормальном) или используют параметры этой совокупности (среднее, дисперсии и тд). Например, Корреляционный анализ Пирсона, Т-критерий Стьюдента. Применяются для анализа нормально распределенных количественных признаков. • Непараметрический - оперируют с частотами, рангами и тд, не учитывающие форму распределения выборочных данных и поэтому имеющие более широкую область применения. Например, Корреляционный анализ Спирмена, критерий Манна-Уитни. Применяются в остальных случаях: для анализа количественных признаков независимо от вида их распределения, для анализа качественных признаков. Основные описательные статитики и их применение в психологических иссследованиях. Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или в эксперименте. Процедуры здесь сводятся к группировке данных по их значениям, построению распределения их частот, выявлению центральных тенденций распределения (например, средней арифметической) и, наконец, к оценке разброса данных по отношению к найденной центральной тенденции. К первичным описательным статистикам обычно относят числовые характеристики распределения измеренного на выборке признака. Каждая такая характеристика отражает в одном числовом значении свойство распределения множества результатов измерения: с точки зрения их расположения на числовой оси либо с точки зрения их изменчивости. Мера центральной тенденции - это число, характеризующее выборку по уровню выраженности измеренного признака.Существует три способа определения «Центральной тенденции», каждому из которых соответствует своя мера: мода, медиана и выборочное среднее. Мода - это такое значение из множества измерений, которое встречается наиболее часто. Моде или модальному интервалу признака, соответствуют наибольший подъем (вершина) графика распределения частот. [1 стр 40] Медиана - это такое значение признака, которое делит упорядоченное (ранжированное) множество данных пополам так, что одна половина всех значений оказывается меньше медианы, а другая - больше. Среднее (или среднее арифметическое) - определяется как сумма всех значений измеренного признака, деленная на количество суммированных значений. [1 стр 41]Среднее значение какого-либо показателя характеризует группу в целом и позволяет сравнивать ее с другими группами. Например, проведена диагностика уровня эмпатии в группе мужчин и женщин. Как узнать, влияет ли пол на способность к эмпатии. Один из способов – найти средний уровень этого показателя в группах мужчин и женщин. Например, в группе женщин средний уровень эмпатии равен 23,5 баллов, а в группе мужчин – 17,7 баллов. Как видно, в среднем у женщин эмпатия выше, чем у мужчин.[2 стр 53] Среднее – это не единственный статистический показатель, который отражает выраженность переменной в группе. Аналогичную функцию выполняют мода и медиана. Меры центральной тенденции чаще всего используют для сравнения групп по уровню выраженности признака. Помимо мер центральной тенденции в психологии широко используются меры положения, которые называются квантилями распределения. Квантиль - это точка на числовой оси измеренного признака, которая делит всю совокупность упорядоченных измерений на две группы с известным соотношением их численности.Меры изменчивости применяются в психологии для сеченного выражения величины межиндивидуальной вариации признака. Наиболее простой и очевидной мерой изменчивости является размах, указывающий на диапазон изменчивости значений, это разность максимального и минимального значений. Дисперсия - мера изменчивости для метрических данных, пропорциональна сумме квадратов отклонений измеренных значений от их арифметического среднего. Стандартное отклонение - положительное значение квадратного корня из дисперсии. На практике чаще используется именно стандартное отклонение, а не дисперсия. [1 стр 44] Понятие , свойства нормального распределения. Применение в психологических исследованиях.Нормальное распределение- это распределение значений переменной величины в тех случаях, когда она варьирует случайным образом и не подвержена влиянию какого-либо состематического фактора.Нормальный закон распределения играет важнейшую роль в применении численных методов в психологии. Он лежит в основе измерений, разработки тестовых шкал, методов проверки гипотез.Закономерность нормального закона распределения проявляется в том, что чаще всего встречаются средние значени соответствующих показателей и чем больше отклонение от этой средней величины, тем реже встречаемость этих отклонений. [1 стр 49] Нормальный закон распределения случайных величин, который иногда называют законом Гаусса или законом ошибок, занимает особое положение в теории вероятностей, так как 95 % изученных случайных величин подчиняются этому закону. Природа этих случайных величин такова, что их значение в проводимом эксперименте связано с проявлением огромного числа взаимно независимых случайных факторов, действие каждого из которых составляет малую долю их совокупного действия.Свойства нормального распределения: • единицей измерения единичного нормального распределения является стандартное отклонение • кривая приближается к оcи Z по краям асимптотически - никогда не касаясь ее • кривая симметрична относительно М=0. ее асимметрия и эксцесс равны нулю • кривая имеет характерный изгиб: точка перегиба лежит точно на расстоянии в одну a от М • площадь между кривой и осью Z равна 1 [1 стр 52] Три важных аспекта применения нормального распределения: • разработка тестовых шкал • проверка нормальности выборочного распределения для принятия решения о том, в какой шкале измерен признак - в метрической или порядковой. • статистическая проверка гипотез, в частности - при определении риска принятия неверного решения. [1 стр 54] Полностью определяется средним значением и стандартным отклонением Мода, медиана и среднее значение совпадают Среднее значение характеризует положение кривой распределения и место ее максимума Стандартное отклонение характеризует форму кривой Зная среднее и стандартное отклонения , ориентировочно можно указать интервал практически всех значений изучаемой величины.[2стр 83] Каждому психологическому (или шире — биологическому) свойству соответствует свое распределение в генеральной совокупности. Чаще всего оно является нормальным и характеризуется своими параметрами: средним (М) и стандартным отклонением (о). Только эти два значения отличают друг от друга бесконечное множество нормальных кривых, одинаковой формы, заданной уравнением. Среднее задает положение кривой на числовой оси и выступает как некоторая исходная, нормативная величина измерения. Стандартное отклонение задает ширину этой кривой, зависит от единиц измерения и выступает как масштаб измерения критерии различий и условия их применения Эти критерии позволяют оценить степень статистической достоверности различий между разнообразными показателями, измеренными согласно плану проведения психологического исследования. Важно учитывать, что уровень достоверности различий включается в план проведения эксперимента. Другими словами, исследователь при постановке экспериментальной задачи априори выбирает уровень достоверности различий (как правило, от 5% и выше в зависимости от особенностей решаемой задачи), который будет считаться приемлемым.[3стр98] Сравнение двух выборок по признаку, измеренному в метрической шкале обычно предлагает сравнение средних значений с использованием параметрического критерия t-Стьюдента. сделает различать три ситуации по соотношению выборок между собой: случай независимых и зависимых выборок и дополнительно - случай сравнения одного среднего значения с заданной величиной (критерий t-Стьюдента для одной выборки) К параметрическим методам относится и сравнение дисперсий двух выборок по критерию F-Фишера. Иногда этот метод приводит к ценным содержательны вводам, а в случае сравнения средних для независимых выборок сравнение дисперсий является обязательной процедурой. При сравнении средних или дисперсий двух выборок проверяется ненаправленная статистическая гипотеза о равенстве средних (дисперсий) в генеральной совокупности. Соответсвенно, при ее отклонении допустимо принятие двухсторонней альтернативы о конкретном направлении различий в соответствии с соотношением выборочных средних (дисперсий) для принятия статистического решения в таких случаях применяются двухсторонние критерии и , соответсвенно, критические значения для проверки направленных альтернатив. [1 стр 162] Непараметрические методы сравнения выборок (критерий U-Манна-Уитни, критерий серий, критерий Т-Вилкоксона, критерий знаков, критерий Н Краксала-Уолесса, критерий X2-Фридмана) являются аналогами параметрических, н заметно проще в вычислительном отношении и применяются в случаях, когда не выполняются основные предположения, лежащие в основе параметрических методов. [1 стр 172] Условия, когда применение непараметрический методов оправдано: • есть основания считать, что распределение значений признака в генеральной совокупности не соответствует нормальному закону • есть сомнения в нормальности распределения признака в генеральной совокупности, но выборка слишком мала, чтобы по выборочному распределению судить о распределении в генеральной совокупности • не выполняется требование гомогенность дисперсии при сравнении средних значений для независимых выборок. [1 стр 173] Понятие , виды, этапы и условия применения дисперсионного анализа. ANOVА - это метод сравнения нескольких (более двух) выборок по признаку, измеренному в метрической шкале. Кроме того метод допускает сравнение выборок более чем по одному основанию - когда деление на выборки производится по нескольким номинативным переменным, каждая из которых имеет две и более градаций. [1 стр 185] Был разработан Р.Фишером. В зависимости от типа экспериментального пана выделяют четыре основных • однофакторный - используется при изучении влияния одного фактора на зависимую переменную. При этом проверяется одна гипотеза о влиянии фактора на зависимую переменную. • многофакторный - используется при изучении влияния двух и более независимых переменных (факторов) на зависимую переменную, позволяет проверять гипотезы не только о влиянии каждого фактора в отдельности, но и взаимодействии факторов. Проверяют три гипотезы: о влиянии одного фактора, о влиянии другого фактора, и взаимодействии факторов. • с повторными изменениями - применяется, когда по крайней мере один из факторов изменяется по внутригрупповому плану, то есть различным градациям этого фактора соответсвует одна и та же выборка объектов. Проверяют три гипотезы: о влиянии внутри группового фактора, о влиянии межгруппового фактора, о взаимодействии внутри группового и межгруппового факторов. • многомерный - применяется, когда зависимая переменная является многомерной, иначе говоря, представляет собой несколько измерений изучаемого явления [1 стр196] Условия применения дисперсионного анализа: Задачей исследования является определение силы влияния одного (до 3) факторов на результат или определение силы совместного влияния различных факторов (пол и возраст, физическая активность и питание и т.д.). Изучаемые факторы должны быть независимые (несвязанные) между собой. Например, нельзя изучать совместное влияние стажа работы и возраста, роста и веса детей и т.д. на заболеваемость населения. Подбор групп для исследования проводится рандомизированно (случайный отбор). Организация дисперсионного комплекса с выполнением принципа случайности отбора вариантов называется рандомизацией (перев. с англ. — random), т.е. выбранные наугад. Можно применять как количественные, так и качественные (атрибутивные) признаки. При проведении однофакторного дисперсионного анализа рекомендуется (необходимое условие применения): Нормальность распределения анализируемых групп или соответствие выборочных групп генеральным совокупностям с нормальным распределением. Независимость (не связанность) распределения наблюдений в группах. Наличие частоты (повторность) наблюдений.[2стр 79] Классический дисперсионный анализ проводится по следующим этапам: Построение дисперсионного комплекса. Вычисление средних квадратов отклонений. Вычисление дисперсии. Сравнение факторной и остаточной дисперсий. Примером применения может быть исследование различия в продуктивности воспроизведения одного и того же материала трех групп испытуемых по 5 человек, различающихся условиями предъявления этого материала для запоминания. Понятие, виды, ограничения и условия корелляционного анализа Корелляционный алаиз позволяет оценить степень (силу) и напрвленность(+,-) линейной связи между двумя переменными, измеренными в ранговой или интервальной шкале. Результатом анализа является коэффициент корелляции ( r) , диапазон которого состоит от 1 до -1. Коэффициент корреляции - это мера прямой или обратной пропорциональности между двумя переменными. Он чувствителен к связи только в том случае, если эта связь является монотонной - не меняет направления по мере увеличения значений одной из переменных. Основные показатели: сила, направление и надежность (достоверность) связи. Сила связи определяется по абсолютной величине корреляции (меняется от 0 до1). направление связи определяется по знаку корреляции: положительный -связь прямая, отрицательный - связь обратная. Надежность связи определяется р-уровнем статистической значимости (чем меньше р-уровень, тем выше статистическая значимость, достоверность связи) Условия применения коэффициентов корреляции: • переменные измерены в количественной (ранговой, метрической) шкале на одной и той же выборке объектов • связь между переменными является монотонной [1 стр 147] Виды коэффициентов корреляции: • корреляция метрических переменных • частная корреляция • сравнение корреляций для независимых выборок • сравнение корреляций для зависимых выборок • корреляция ранговых переменных • анализ корреляционных матриц Ограничения : Нелинейность связи. Наличие нелинейных отношений между двумя переменными, способнов значительной степени снизить значение коэффициента корелляции. Дисперсионные выбросы, асимметричность распределения. Наибольшее значение эти параметры оказывают на коэффициент корелляции Пирсона. Даже одно экстремально большое или маленькое значение способно изменить знак коэффициента корелляции на противоположный Влияние третьей переменной. Иногда корелляция между переменными может быть ложной и обьясняться влиянием дополнительных факторов[2 стр 114] Источники. Наследов А.Д. Математические методы психологического исследования. Уч. пособие, СПб:Речь-2004, стр95,98,99 Титкова Л.С. Математические методы в психологии. Уч. Пособие. Дальневосточный гос. Университет. Тихоокеанский институт дистанционного образования и технологий., 2006, стр. 9, 38, 72-73 Презентация преподавателя Дериша Ф.В. |