Базаров О. Б. КР_БД. Olap технологии по учебной дисциплине
 Скачать 293.5 Kb. Скачать 293.5 Kb.
|

Кафедра информатики, математики и естественнонаучных дисциплин КУРСОВАЯ РАБОТА на тему OLAP технологии по учебной дисциплине: Базы данных Выполнил: Базаров Олжас Быкытжанович Фамилия И.О. Направление подготовки: прикладная информатика Форма обучения: заочная____________ Работа защищена с оценкой: ____________________________ ____________________________ Подпись Фамилия И.О. “____”________________20___ г. Омск, 2017 Оглавление Введение3 1 Хранилища данных и OLAP5 1.1 Что такое Хранилище данных5 1.2. Многомерные хранилища данных10 1.3 Компоненты OLAP-систем14 2 OLAP18 2.1 Технология OLAP18 2.2 Сравнение технологий OLAP, OLTP и РБД21 2.3 Применение OLAP технологий при извлечении данных24 Заключение25 Список использованных источников27 Приложения29 Введение Объемы данных в современном мире растут огромными темпами, поэтому оценить и проанализировать их должным образом без специального ИТ-инструментария, сегодня практически невозможно. Одним из основных компонентов решений Business Intelligence является OLAP (On-Line Analytical Processing), оперативный анализ данных, представляющий собой комплекс ИТ-решений, направленных на интерактивный анализ больших объемов информации. Отличительным признаком OLAP-систем является представление данных в виде многомерных кубов. Вся информация бизнес-процесса систематизируется, разбивается на категории, которые в свою очередь преобразовываются в оси (измерения) многомерных кубов. Подобный подход позволяет предоставлять все данные в виде визуальных, интуитивно понятных двух- или трехмерных срезов таких кубов. Пользователь может самостоятельно выбирать срезы по тем или иным категориям, что позволяет совмещать, сравнивать и анализировать информацию по всевозможным направлениям, представленным в виде измерений сформированного куба. При этом каждое измерение может быть в свою очередь разбито на подизмерения в зависимости от рода информации. Кубы, «наполненные» данными, предоставляют практически полную «свободу для творчества». Их можно «вращать» по своему усмотрению и «резать» во всех интересующих направлениях, «отсекая» всю лишнюю на данный момент информацию, быстро собирая воедино все нужные цифры и показатели. История создания OLAP-систем восходит к 1962 году, когда Кен Айверсон опубликовал книгу «Язык программирования». Айверсон разработал первый язык, который давал возможность многомерного программирования. Уже в 1970году вышел первый программный продукт Express, позволяющий проводить многомерный анализ данных. Express до сих пор является одним из лидеров рынка OLAP, входя в состав Oracle9i Database. В 1992 году появился Essbase, который стал первым серьезным продуктом, занявшим прочные позиции на ИТ-рынке, а спустя год Эдгар Кодд ввел в обращение термин OLAP. Первоначально OLAP использовался как профессиональное словечко, обозначающее принципиальное отличие от OLTP (On-Line Transaction Processing, Оперативная обработка транзакций). Буква T была заменена на A, что подчеркивало аналитические возможности OLAP в отличие от транзакционных характеристик технологии реляционных баз данных. Сегодня термин OLAP используется родовое понятие для различных технологий, включая системы поддержки принятия решений, Business Intelligence и управленческие информационные системы. В данной курсовой работе мы рассмотрим технологию OLAP, ее достоинства и недостатки, а также сравним ее с другими технологиями для анализа данных. 1 Хранилища данных и OLAP 1.1 Что такое Хранилище данных Хранилище данных (Data Warehouse) представляет собой центральное место, в которое направляются все сведения из разнообразных подразделений предприятия, и где они в дальнейшем будут храниться и накапливаться. Однако эта информация, не может поступать в такой центр необработанной, поскольку ее форма и структура могут не соответствовать конфигурационным параметрам хранилища данных. В таком случае требуется предварительное преобразование и первичная систематизация информации. Это осуществляется в транзакционной базе данных. Перед тем, как информация будет использоваться в разнообразных целях, необходимо ее проанализировать и преобразовать в необходимый вид. А это потребует определенного времени и усилий, от качества организации которых зависит эффективность наполнения базы и результативность последующего использования информации. В хранилище происходит интеграция данных, что предполагает необходимость подготовительных и адаптационных мероприятий: - определяются различия и совместимость форматов информации, поступающей из разных, а иногда одних и тех же источников; - осуществляется контроль за правильностью и корректностью заполнения всех блоков таблиц; - планирование всех внутренних связей между отдельными элементами базы данных; - разделение информации по степени ее полезности, приоритетности и важности для дальнейшего применения, что предопределяет корректировку внутренней конфигурации базы [5]. Управленческие решения принимаются на основе большого объема информации, которая поступает из разных источников и отражает разнообразные стороны описываемых объектов и процессов. Усложнение информации, необходимость ее своевременного поступления и обработки приводят к возникновению проблем управленческого характера. Информация может иметь вид, непригодный для использования, она может быть необъективной или неадаптированной под решение конкретной проблемы. В результате увеличиваются непроизводительные затраты времени, связанные с дополнительной обработкой и систематизацией данных, а также поиском требуемых сведений среди множества таблиц и отчетов. Со временем оборот информации по предприятию возрастает настолько, что ни сама система, ни ее пользователи не справляются с ее обработкой. Возникают ошибки принятия решений, что ведет к дополнительным экономическим потерям. Формирование хранилища данных представляет собой сложный процесс, который включает следующие этапы: 1) разработка планов проведения работ и конкретизация временных параметров исполнения; 2) определение цели систематизации данных и приведения их в единообразный вид; 3) группировка существующей информации с целью исключения накопления излишних данных, которые повторяют друг друга. Здесь выделяют: - внешние обязательные отчеты, которые циркулируют в отношениях со сторонними организациями, в том числе органами государственного управления и контроля. Такие отчеты могут быть ежедневными ежемесячными, ежеквартальными и т.д., что требует четкой временной периодизации процесса обмена данными; - внутренние целевые документы, которые подразделяются исходя из источника поступления – структурных подразделений предприятия; 4) комплексный анализ информации всех видов [9]. Размеры предприятия и объемы его деятельности постоянно изменяются. В условиях роста оборотов, числа клиентов и проданной продукции возникает необходимость постоянной адаптации баз данных к такому росту бизнеса. В то же время ее расширение не может проводиться бесконтрольно. Требуется последовательная модернизация хранилища данных. Такое изменение предполагает опытную загрузку дополнительной информации с последующим тестированием уровня работоспособности хранилища. Если система справится с потоком данных, а эффективность проводимых расчетов и экспериментов с применением загруженных данных будет высока, то можно будет утверждать о готовности хранилища к дальнейшей эксплуатации. Тестирование должно проводиться своевременно с целью оперативного выявления возможных сбоев и проблем системы до того момента, как данные будут использоваться в текущей деятельности всего предприятия. Если перед разработчиками ставится задача упростить процессы накопления и обмена информации, то первоначальным этапом становится планирование витрины данных по отдельным подразделениям. Цель такого моделирования хранилища сводится к проектированию упрощенного варианта базы с меньшим потоком информации и ограниченным объемом важных операций. Уровень подразделения предприятия является наиболее оптимальным выбором при тестировании. В результате информационная система делится на отдельные объекты. Взяв один отдельный элемент, проектировщики получают возможность конкретизировать технологию проектных мероприятий [14]. Проектирование базы данных может осуществляться на основе комплексного изучения особенностей действующей системы, оценки внутренних информационных связей в хранилище. Только после получения общего описания работающей системы можно начинать формировать новую базу. Оптимальным вариантом является создание пилотного проекта хранилища в целом по предприятию, без выбора экспериментального полигона для испытаний. Здесь акцент ставится именно на структурные взаимосвязи внутри организационной структуры управления предприятием. Более того, модификация пилотного подразделения и других структурных элементов информационной системы должны быть учтены в полном объеме. Дополнительно оценивается влияние таких изменений на эффективность системы в целом. Все действия как по подразделению, так и по всей системе должны строго документироваться. В данном подходе есть важное преимущество – сама система взаимосвязей не упрощается. Наоборот, последовательно изучаются информационные связи отдельного подразделения, а затем оценивается их состояние с учетом отношений между подразделениями. Эффективность решения по формированию хранилища и отдельных его витрин значительно повышается. Хранилище данных работает настолько результативно, насколько позволяет качество собранной в нем информации. Такие данные должны быть: - полными; - достоверными и объективными; - соответствовать требованиям оптимальной систематизации; - находиться под постоянным контролем в процессе формирования базы данных и ее развития. В случае не выполнения указанных требований хранилище будет эксплуатироваться некорректно, а решения, которые будут приниматься на основе этих сведений, приведут к значительным экономическим потерям. Следовательно, перед началом работ по проектированию Data Warehouse необходимо проверить качество данных. Делать это надо на уровне источников, т.е. сначала информация приводится в необходимый формат, а затем направляется в хранилище. Однако часто это требование не учитывается, а поэтому в процессе проектирования возникает необходимость обрабатывать не сочетающиеся друг с другом данные. После того, как данные приведены к единому формату, необходимо спланировать систему защиты и безопасности информации. Поскольку доступ к хранилищу должен быть обеспечен большому числу пользователей, то важно решить две задачи проектирования: - оптимально распределить доступ к хранилищу и исключить конфликт обращений; - предотвратить возможные сбои системы и отказ в работе отдельных ее элементов. Популярным способом регулирования доступа к данным и осуществления контроля за ним является назначение индивидуальным пользователям или их группам определенного статуса с различными полномочиями и объемом разрешенных функций. Необходимо установить запрет для большинства пользователей на изменение базы данных, ограничить доступ к заданным категориям данных, конкретизировать лиц, которые будут допущены к конфиденциальным сведениям [6]. Data Warehouse должно содержать исключительно актуальные сведения. Поэтому в нем надо предусмотреть возможность выведения части устаревших сведений в архивный раздел. Оценка такой актуальности проводится статистическим методом посредством отслеживания числа запросов, осуществленных к заданному сектору информации за конкретный период времени. Часто берется период пиковой загрузки, чтобы оценить устойчивость системы повышенной частоте обращений. Цель хранилища не только в накоплении данных, но и обеспечении достоверной аналитической работы с этими данными. Информация различается по степени ценности для предприятия, часто не может быть опубликована в открытом доступе. Поэтому следует создать многоуровневую систему хранения с учетом различий в статусе пользователей и уровней конфиденциальности данных. Эффективность работы хранилища зависит от уровня квалификации разработчика, его опыта и правильности формулирования технического задания. Перед проектировщиком должны быть поставлены конкретные задачи, учтены потребности в информации со стороны отдельных подразделений. Налаженность взаимосвязей разработчиков и сотрудников предприятия позволит правильно оценить необходимую конфигурацию базы данных и создать высокопроизводительное хранилище. 1.2. Многомерные хранилища данных Работа с информацией, которая поступает в любую базу данных и в последующем подлежит систематизации, связана с всесторонней обработкой данных. В результате информация приобретает вид, позволяющий проводить аналитические расчеты. Но для этого необходимо сформировать на основе выборки ряд показателей, сведенных к набору числовых атрибутивов (Таблица 1). Таблица 1 – Таблица данных
Существует несколько методов решения данной задачи. Они имеют свои преимущества и недостатки. Но наиболее часто применимым является табличный метод. В таблице выделяется комплекс атрибутивов и соответствующие им массивы числовых данных. Могут выделяться следующие атрибутивы - «Страна», «Год» и «Товар», с которыми соотносятся показатели продаж. Назначение таблицы в данном случае состоит в обеспечении наилучшей визуализации данных для последующего определения связей между атрибутивами и числовыми данными. Благодаря оценке взаимосвязей и сопоставлению их, можно сформировать трехмерные массивы в следующих измерениях: страны, годы и товары. Этот трехмерный характер представления позволяет выделить сегменты, которые обладают наибольшим значением числового параметра, т.е. максимальным показателем объема продаж. Более того, можно произвести ранжирование сегментов по степени обладания заданными параметрами, а также выделить те, в которых нет данных по исследуемым показателям. Например, отсутствие данных по объемам продаж в Аргентине в 1988 г. выделено серым цветом [17]. При анализе сформированных массивов обращает на себя внимание массив OLAP. Он носит название куба, хотя с математической точки зрения данный массив может не соответствовать этой характеристике. Здесь имеет место равенство в числе элементов по каждому из измерений. В то же время ограничения в показателях для кубов OLAP отсутствуют, поэтому реальная их конфигурация может варьироваться от двухмерных вариантов до многомерных. Определяющим фактором выступают целевые ориентиры и задачи, которые поставлены перед аналитиком. Параметры измерений в кубах задаются соответствующими метками или членами куба (members) – измерению «Страна» соответствуют метки «Бразилия», «Аргентина», «Венесуэла». При этом, как уже было отмечено, отдельные фрагменты куба могут не иметь числовых показателей – Аргентина в 1988 г. Такая ячейка пустует. Исключение пустой ячейки из куба недопустимо, ведь в этом случае сами данные и их восприятие будут искажены. Поэтому пустая ячейка сохраняет статус элемента куба и получает соответствующую отметку, означающую отсутствие информации. А для решения данной задачи в конфигурацию закладываются соответствующие резервы памяти и вакуумный принцип хранения многомерных данных. Для лучшего понимания конфигурационных особенностей многомерных массивов данных и моделей необходимо представить основные их составляющие: 1. Показатель – числовое выражение заданной величины, например размер прибыли, число потребителей, объем продаж. Эти числовые выражения подлежат анализу, а сам куб OLAP дает возможность работы по нескольким показателям. 2. Измерение – строгая иерархическая структура объектов. Эти объекты могут быть одинаковыми или отличаться друг от друга. Благодаря измерению, числовые показатели приобретают информационное значение. Визуализация структуры объектов достигается за счет формирования куба с признаками многомерности [12]. 3. Объекты, по которым строится измерение или образуются соответствующие члены. Представление объектов в интегрированном виде обеспечивается за счет создания точек или блоков на осях этого куба. По временному параметру выделяют Дни, Месяцы, Кварталы или Годы. Внутри каждого измерения откладываются временные точки, например 8 мая 2002 г., 2-ой квартал 2002 г., май 2002 г. или 2002 г. Наличие отдельных членов в измерении позволяет строить аналитическую работу с последующим вычленением пространственно-временных связей. Но и сами объекты в измерениях часто различаются, что требует глубокого их структурирования и выделения уровней, в которых будут компоноваться объекты с одинаковым иерархическим значением. 4. Ячейки (cell) – они соотносятся с отдельными значениями показателей. Ячейки находятся внутри куба и представляют заданные числовые показатели. Благодаря измерениям, существует возможность идентифицировать любые показатели, которые наполняют ту или иную ячейку. Кроме того, члены измерений могут комбинироваться друг с другом, а, значит, задавать многомерные координаты при поиске нужных значений (Рис 4). В то же время, если при структурировании какой-либо комбинации участвуют все члены измерения, то ссылка будет вести на несколько ячеек. Для однозначности выполнения поставленной задачи требуется указание как членов измерения, так и самого показателя. Иногда реалистичность измерения нарушается. Это связано с фактическим отсутствием заданного атрибутива и невозможности существования искомого показателя. Например, если предприятие не работало в 2001 г. на рынке Московской области, то соответствующий показатель «Объем продаж» будет отсутствовать, а ячейка окажется пустой [15]. При помощи построения иерархических связей обеспечивается систематизация данных, что в последующем позволяет проводить их детальный анализ и сопоставление. В связи с этим целесообразно выделить следующие типы иерархий: 1. Иерархии сбалансированного типа (balanced), имеющие четкую структуру, которая задает необходимое число уровней. На каждом таком уровне есть некоторое число соответствующих именно ему объектов. Если банковское учреждение выдает несколько кредитов по целевому назначению, а внутри каждого типа кредита есть несколько кредитных программ, то будет сформирована трехмерная иерархия: банк, кредит, кредитная программа. Кроме того, в рамках такой иерархии формируются связи между объектами, имеющими различную степень детализации. Это приводит к упорядочению уровней, каждый из которых приобретает конфигурацию простого измерения. Более высокая степень разреженности куба в такой ситуации будет связана с появлением связей между измерениями с элементами обоюдной зависимости [10]. 2. Иерархии несбалансированного типа (unbalanced). Структура и число уровней в них может меняться. На каждой «ветви» иерархии находятся как однотипные объекты одного уровня, так и однотипные объекты разных уровней. В иерархической связи «начальник – подчиненный» все объекты будут относиться к одному типу «Сотрудник». 3) Неровные иерархии (balanced), в которых число уровней определяется по постоянной структуре, но в отличие от сбалансированной иерархии, некоторые ветки «дерева» не содержат объекты, относящиеся к конкретному уровню. Иерархии такого типа содержат члены или логические «родители», находящиеся на вышестоящем уровне. В качестве типичного примера географической иерархии можно привести уровни, - «Города», «Страны», «Штаты». При этом в наборе их данных будут присутствовать страны без штатов или регионов между уровнями «Города» и «Страны» [2]. Агрегаты – это агрегированные по определенным условиям значения исходных показателей. Под агрегацией обычно понимается любая процедура формирования меньшего количества показателей на основе множества исходных значений. Под терминами агрегация и агрегирование понимается процесс суммирования данных. Заблаговременное формирование, а также сохранение агрегатов для уменьшения времени отклика на запрос пользователя, является важнейшим свойством системы поддержки оперативного анализа. 1.3 Компоненты OLAP-систем OLAP-системы относятся к многокомпонентному типу с четким иерархическим построением. Внутри системы выделяют: - источник информации; - сервер OLAP; - программу-клиент. Из источника информации все данные поступают на сервер OLAP для их систематизации и обработки. Здесь разрозненные данные структурируются и приобретают вид, которые соответствуют требованиям запроса. В результате появляется возможность корректного ответа на него. Запрос пользователя формируется посредством программы-клиента. Эта программа наделена возможностями интерфейса сервера OLAP. Таким образом, возможность анализа информации обеспечивается за счет корректного поступления данных с сервера OLAP. Поскольку управленческие решения принимаются на основе сложной и разнообразной информации, то все продукты OLAP должны ориентироваться на работу с данными, которые поступают из различных источников [20]. Благодаря наличию такой прикладной составляющей системы, как сервер, создается возможность не только накапливать и хранить информацию, но и ее обрабатывать, проводить аналитические действия. Сложность работы системы связана и с тем, что она обладает и входом, и выходом. Это проявляется в наличии пользовательских запросов, существовании доступа к данным лицами, имеющими различный статус. Поэтому архитектура сервера может быть различной и определяться несколькими основными концепциями. Все продукты OLAP используют базы данных двух видов: - многомерные (ММБД); - реляционные (РБД) Многомерный сервер MOLAP задействован при хранении информации в базах многомерно типа [18]. Применением ММБД обеспечивается не только эффективное и корректное хранение информации, но и оперативное реагирование на запросы пользователей после их доступа к системе. Агрегирование данных производится после того, как они будут загружены в базу из источника. Обработка и обобщение этой информации значительно ускоряет доступ к отдельным блокам данных. Чем быстрее производится доступ к информации и требуемые расчеты, тем выше качество и скорость ответа системы на запрос. При этом интеллектуальный характер работы базы позволяет системе запоминать конфигурацию запроса и использовать результаты обработки для других подсчетов. Реляционный сервер ROLAP базируется на моделях реляционного типа, вследствие чего для передачи данных в базу используются классические схемы «звезда» или «снежинка». Это непосредственно влияет на оперативность доступа и скорость получения ответа на запрос. Комплекс оптимизированных запросов SQL формирует при этом производительную многомерную модель. При проектировании базы данных необходимо сделать выбор соответствующей модели. Реляционный тип обладает отработанной технологией оптимизации с использование различных способов ее осуществления. Важным преимуществом ROLAP является возможность работы с большими массивами данных. Но при этом конфигурация пользовательских запросов чрезмерно усложнена, что связано с применением концепции SQL. Только при помощи этого типа организации запросов можно обеспечить корректный доступ к крупной базе данных. Эффективная работа с базой данных возможна лишь в случае оптимизации клиента, который позволяет отображать все данные заданной базы. Мощность сервера должна сочетаться с параметрами клиента, его многофункциональностью и простотой в эксплуатации. Это предопределяет требование к дополнительным усилиям по повышению производительности самого клиента [7]. Доступ к OLAP-данным обеспечивается инструментом запросов или генератором отчетов. Чем легче доступ и проще интерфейс, тем удобней будет использование данного инструмента. Классическое перемещение объектов в отчет при помощи перетаскивания мышью не только исключает непроизводительные затраты времени, но и уменьшают вероятность ошибки или некорректной работы. Следует разделять функциональные возможности традиционного генератора отчетов и OLAP-генераторов. Если первые ориентированы на ускорение формирования формализованных отчетов, то вторые обеспечивают их актуализацию. Приложения, в отличие от предыдущих элементов, обладают большими функциональными характеристиками и более высокой производительностью по сравнению с генератором отчетов. Внедрение современных хранилищ данных и использование средств Data Mining - необходимый элемент безопасности и конкурентоспособности компаний, поскольку обеспечивают не только накопление информации и ее обработку, но и комплексный анализ при сохранении заданного уровня конфиденциальности. Все данные при этом проходят проверку на подлинность и систематизируются. Между инструментами OLAP и Data Mining есть определенные различия. Применение OLAP-систем позволяет аналитикам осуществить анализ данных наиболее оперативным и комплексным способом. При этом обеспечивается работа инструмента для визуализации срезов данных. Инструмент Data Mining ориентирован на поиск и отображение неявных тенденций, вследствие чего анализ производится самой системой, поскольку аналитик не имеет реальной возможности адекватно оценить большие массивы информации и выявить скрытые связи и зависимости. 2 OLAP 2.1 Технология OLAP Программные средства OLAP представляют собой очень эффективные элементы быстрого анализа объемной информации, содержащейся в специальном хранилище. Главной особенностью этой программы можно назвать тот факт, что она ориентируется не на профессиональных пользователей в сфере информационных технологий, а на обыкновенных руководителей, директоров, менеджеров кредитного отдела и других специалистов прикладных сфер на предприятии. Эта программа предназначена для общения специалистов не с компьютером, а с проблемами конкретной организации. Структура OLAP представлена в форме куба, который сам по себе не пригоден для какого-либо анализа. У такого куба очень много граней, количество которых может достигать девятнадцати и более сторон. Исходя из этой особенности, следует сразу отметить, что при изучении информации многомерного куба сначала придется извлечь ее в простую двумерную таблицу. Такая операция носит название «разрезание куба» и имеет весьма образное представление. Другими словами, специалист как бы «разрезает» кубические измерения по конкретным меткам. Таким способом он получает двумерный кубический срез и далее работает с ним. Это можно сравнить с подсчетом годовых колец на срубленной древесине [16]. При создании «разреза» два измерения остаются цельными по количеству табличных измерений. Но бывает и так, что лишь одно измерение остается «не разрезанным». Это может быть в том случае, когда куб содержит несколько типовых значений числа, и они откладываются по одному конкретному табличному измерению. При детальном и внимательном рассмотрении первой таблицы сразу заметно, что данные в ячейках не являются первичными, поскольку они получены за счет суммирования более мелких частей и чисел. Например, во многих случаях время делится на части (год на кварталы, месяцы, недели и дни). В качестве примера также можно привести структуру государственного строения, в которой оно формируется из отдельных регионов, городов и населенных пунктов. Помимо этого в каждом городе можно выделить районы и конкретные точки. Если взять структурное деление в сфере розничной торговли, то можно выделить товары, объединенные в группы. В самом понятии системы OLAP такие многоуровневые построения называются четкой иерархией. Все средства системы призваны обеспечивать возможность для пользователя в любой момент перейти на конкретный уровень иерархии. Для одних и тех же частей может быть задействовано сразу несколько иерархий, например, - "день-неделя-квартал", либо "день-декада-месяц". Вся исходная информация всегда берется из нижних иерархических уровней, а далее складывается в единое целое для получения более обобщенных и завершенных уровней. Чтобы ускорить процесс перехода, числовые обозначения суммируются для различных уровней, а потом сохраняются в секторах куба [8]. Исходя из выше сказанного, можно выделить серьезный момент, - система OLAP очень эффективна и высокопроизводительна. Можно себе представить, что конкретно будет происходить в момент, когда специалист захочет получить конкретную информацию, если средства OLAP в компании отсутствуют. Сначала он должен собственными силами или с помощью программистов сформировать четкий SQL-запрос. После этого он получит всю интересующую информацию в виде отчета, а далее самостоятельно будет заносить их в электронную таблицу. Именно в этот момент начнутся самые серьезные трудности, поскольку специалист должен заниматься не SQL-программированием и ожиданием результатов, а выдавать определенный результат по времени. Конечно это негативно скажется на его профессиональной деятельности и значительно затянет время работы. Кроме того, одна единственная отчетная таблица точно не спасет гиганта мысли и процедуру придется провести несколько раз. Это произойдет по той причине, что грамотные специалисты не задают вопросы по мелочам, они сразу работают со всей информацией. Поскольку техника постоянно совершенствуется, серверу реляционной СУБД, к которому обращаются специалисты, необходимо постоянно ускорять свою работу. Этот орган должен быстро и надежно предоставлять необходимую информацию и блокировать все посторонние запросы. [1] Концепция OLAP специально была разработана для решения подобных проблем. Все кубы системы представляют собой своеобразные мета-отчеты. При разрезе мета-отчетов или кубов по конкретным измерениям специалист получает интересующую информацию в виде простых двумерных отчетов. Однако, это не совсем простые отчеты в привычном понимании. Они имеют вид упорядоченной структуры с определенными функциями. Плюсы кубов системы OLAP очевидны, поскольку показатели запрашиваются из реляционной СУБД лишь один раз при формировании куба. В основном специалисты не работают с информацией, которая меняется очень часто. Поэтому уже сформировавшийся куб можно считать актуальным на протяжение долгого времени. За счет такой особенности исключены все возможные перебои с работой сервера реляционной базы данных. Он просто не получает множество запросов и не выдает миллионы строк с ответами. Вследствие этого скорость доступа и работы с информацией возрастает вместе с производительностью системы. Таким образом, в кубе идет подсчет промежуточных иерархий и формируется одна сумма агрегированных уровней на момент формирования куба. Если с самого начала его построения данные будут содержать информацию за один день по одному конкретному направлению (количеству товара, выручке), то в системе OLAP постепенно со временем будет происходить подсчет этих сумм по неделям, месяцам, годам или другим измерениям [19]. Конечно, за повышение эффективности работы таким способом придется платить. Иногда можно наблюдать такую картину, при которой структура данных системы OLAP «взрывается», т.е. переполняется и занимается в сотни раз больше места, чем имеющиеся исходные данные. Для того, чтобы избежать подобного явления, нужно точно знать, как работает этот механизм. Таким образом удастся формализовать знания и выделить четкие критерии OLAP без перевода на простой человеческий язык. Все эти 12 критериев были сформулированы еще в 1993 году Е. Коддом, который считается создателем концепции реляционных СУБД и самой OLAP. Со временем эти критерии были переработаны в тест FASMI, помогающий определить требования к продуктам OLAP. Сама же аббревиатура FASMI создана от обозначения каждого пункта тестирования: • Analysis (Анализ). В приложении OLAP пользователь может провести числовой и статистический анализ; • Fast (Быстрый). С помощью системы обеспечивается минимальный срок получения аналитической информации (не более 5 секунд); • Multidimensional (Многомерность). Все данные представляются в виде многомерной модели; • Shared (Разделяемый доступ). Многофункциональное приложение OLAP дает возможность работать сразу с несколькими видами данных одновременно; • Information (Информация). С помощью OLAP пользователь способен получить требуемые данные из любого электронного хранилища куба [13]. Всю работу с системами OLAP можно формировать на основании двух схем, которые описаны ниже. 2.2 Сравнение технологий OLAP, OLTP и РБД Параллельное применение учетной системы OLAP или прямая настройка аналитических функций на OLTP-базе, может быть осложнена следующими факторами: 1) запросы к информационной базе в OLAP бывают сложными и требуют много времени. Непосредственно прямой доступ к системе сильно уменьшает общую производительность оперативной системы ПК. 2) Часто в учетных системах информация может быть «загрязнена», несогласованна или неполноценна. 3) Различные учетные системы могут быть неоднородными по разновидности используемых концептуальных возможностей или синтаксических соглашений (кодирования, единиц измерений, наименований), поэтому их интеграция будет затруднительной. 4) Отсутствие общей модели данных размера компании. За счет проектирования баз системы учета могут использоваться разные информационные модели (иерархическая, «фирменная», реляционная, объектно-ориентированная, и прочие). 5) При обновлении OLTP- базы данные за учетный период утрачиваются. Таким образом, происходит остановка анализа временных тенденций. А это обстоятельство является значимым моментом для многих сфер бизнеса [11]. 6) В оперативных системах отсутствуют методики четкого представления информации для разных групп пользователей в нужной форме. 7) База OLTP не сохраняет информацию в денормализованном виде, а это нужно для аналитической обработки. Изменение такой информации в процессе выполнения запросов оказывается сложнейшей задачей. Кроме выше перечисленных концептуальных различий можно отметить и технологические проблемы. Их необходимо преодолевать для эффективного использования аналитических возможностей в отдельных учетных системах. К числу таких проблем относятся следующие трудности: • отличие аппаратных платформ (сетей, компьютеров и периферии); • использование разного ПО (операционных систем, СУБД, протоколов, языков программирования); • геораспределение баз с информацией внутри организации и за ее пределами. Часто средства OLAP используются в виде набора удобных многопользовательских приложений с поддержкой. Они помогают обеспечить оперативный доступ к разнообразным элементам базы вне зависимости от объема и сложности информации. Это достигается благодаря использованию сервера OLAP, который и представляет собой многопользовательский инструмент для действий с многомерной структурой данных. С помощью системы конструкция сервиса и структура данных оптимизируется должным образом. Благодаря этому можно спокойно проводить не регламентированные запросы и гибкие вычисления с последующим преобразованием информации. Посредством работы с сервером OLAP можно организовать физическое сохранение многомерных обработанных данных. Это дает возможность быстро формулировать ответы на запросы пользователей. Кроме того, предполагается преобразование информации из реляционных баз в режиме реального времени в многомерные структуры. Стоит рассмотреть подробнее процесс ведения совместной работы многомерных и реляционных средств. Продукты OLAP активно внедряются в действующую корпоративную структуру посредством интегрирования с реляционными системами. Сами администраторы информационных баз активно загружают данные в многомерный кэш, или же настраивают его для получения доступа непосредственно к SQL информации. Архитектура системы параллельно использует реляционные и многомерные системы. Сама информация хранится в структуре OLAP или на сервере в виде КЭШа для информации. Можно использовать комбинацию двух подходов и снизить масштаб данных, перемещаемых в многомерную схему из реляционной и обратно. Довольно часто в реляционной системе хранится детализированная информация. Система OLAP дает возможности для пользователя осуществлять переходы от своих данных к другим более подробным данным. Реляционная и многомерная модели математически похожи, поэтому они легко отображаются в другой архитектуре. Например, переменные OLAP берутся из столбцов реляционной базы. Все измерения в многомерном кубе связаны с ключами и идентичны строкам реляционной базы. Пользователю системы видно, какие типы вычислительных функций сейчас доступны и насколько быстро происходят вычисления. Он также может видеть основные задачи технического персонала. Обе модели открывают аналитические возможности для пользователя. Но несмотря на это поддержка, описание и применение сложного кода в многомерных моделях означает то, что потребуется много времени для анализа по сравнению с реляционной моделью. 2.3 Применение OLAP технологий при извлечении данных Общим принципом работы любой системы OLAP можно назвать простоту и скорость. Работа с кубом информации сводится к его разворотам и группировкам. Пользователь может менять число измерений и группировок, но принцип подсчетов будет идентичным. Однако, при подсчетах могут возникнуть некоторые проблемы. При подробном представлении информации специалист может хорошо проанализировать данные. Тем не менее, сам куб OLAP со временем будет лишь увеличиваться в объемах за счет бесконечно поступающей информации. Именно поэтому для получения результата пользователь должен видеть на своем экране не весь информационный куб, а только его необходимую грань или часть. Для этого необходимо выбрать правильные измерения, которые интересны для конкретного случая или расчетов. К примеру, если аналитику все равно, куда был продан товар, то он в первую очередь должен убрать измерение «город». Дальше можно отсечь другие ненужные критерии из общей номенклатуры [3]. Заключение OLAP позволяет анализировать данные, накопленные в системе, «с разных сторон и точек зрения», «в разной итоговой форме, с пользовательскими расчетами и агрегированием». Можно строить максимально гибкие и сложные пользовательские OLAP-отчёты с действительно произвольным набором аргументов и расчетов для удовлетворения потребностей в бизнес-ориентированной отчетности. И в заключение следует отметить, что аналитические возможности технологий OLAP повышают пользу данных, хранящихся в корпоративном хранилище информации, позволяя компании более эффективно взаимодействовать со своими клиентами. Можно выделить две основные причины, почему электронные таблицы продолжают использоваться и почему применение альтернативных технологий в финансовых отделах не получило широкого распространения. Во-первых, в финансовых отделах отсутствует понимание существующих альтернативных подходов к решению проблем. В IT-подразделениях также не достает осознания сложностей, с которыми сталкиваются финансовые специалисты. Другими словами, один отдел не понимает проблему, другой – ее решение. Во-вторых, присутствуют сложности с обоснованием необходимости расходов. Покупка и внедрение новых технологий требуют финансирования, однако отдача от них ощущается не сразу и не поддается простомуколичественному определению. В большинстве случаев для обоснования предстоящих затрат, требуется представить доказательства, что проект окупится в течение первого года. Поэтому, несмотря на очевидные достоинства OLAP – точность данных, легкость анализа и использования, а также возможность своевременного получения информации – представление подобного обоснования является крайне непростой задачей. Сегодня большинство мировых компаний перешли к использованию OLAP как базовой технологии для предоставления информации лицам, принимающим решениям. Поэтому принципиальный вопрос, которым необходимо задаться, не состоит в том, следует ли продолжать применять электронные таблицы в качестве основной платформы для подготовки отчетности. Компании должны спросить себя, готовы ли они терять конкурентные преимущества, используя неточную, неактуальную и неполную информацию, прежде чем они созреют и рассмотрят альтернативные технологии. Технология OLAP призвана повысить эффективность информационно-аналитической и управленческой деятельности руководящего персонала. Используя эти средства, можно быстрее и более обоснованно принимать оперативные и стратегические решения. Открытые при помощи OLAP закономерности реализуются затем в экономические модели, позволяющие заглянуть в будущее. Таким образом, благодаря технологиям многомерного анализа данных информация, накопленная в программной системе, перестает быть «вещью в себе» и максимально способствует повышению эффективности бизнеса. Список использованных источников Книги, статьи, материалы конференций и семинаров Баженова И.Ю., Основы проектирования приложений баз данных [Текст] / И.Ю. Баженова – М.: Интернет-Университет Информационных Технологий (ИНТУИТ), 2016. – 325 с. Бен-Ган И., Microsoft SQL Server 2012. Высокопроизводительный код T-SQL. Оконные функции [Текст] / И. Бен-Ган – М.: Русская редакция, 2013. – 256 с. Бен-Ган И., Microsoft SQL Server 2012. Основы T-SQL [Текст] / И. Бен-Ган – М.: Эксмо, 2015. – 400 с. Бондарь А.Г., Microsoft SQL Server 2012 [Текст] / А.Г. Бондарь – М.: БХВ-Петербург, 2013 г. – 608 с. Мартишин С.А., Базы данных. Практическое применение СУБД SQL и NoSOL-типа для применения проектирования информационных систем. Учебное пособие. Гриф МО РФ [Текст] / С.А. Мартишин, В.Л. Симонов, М.В. Храпченко - М.: Инфра-М, Форум, 2016 г. – 368 с. Марц Н., Большие данные. Принципы и практика построения масштабируемых систем обработки данных в реальном времени [Текст] / Н. Марц, Дж. Уоррен - М.: Вильямс, 2016. – 368 с. Новиков Б.В., Настройка приложений баз данных. Гриф УМО МО РФ [Текст] / Б.В. Новиков – М.: БХВ-Петербург, 2012. – 240 с. Редмонд Э., Семь баз данных за семь недель. Введение в современные базы данных и идеологию NoSQL [Текст] / Э. Редмонд, Д. Р. Уилсон, Ж. Картер - М.: ДМК Пресс, 2013 г. – 384 с. Риза С., Spark для профессионалов. Современные паттерны обработки больших данных [Текст] / С. Риза, У. Лезерсон, Ш. Оуэн, Дж. Уиллс - М.: Питер, 2016 г. – 272 с. Садаладж П., NoSQL: новая методология разработки нереляционных баз данных [Текст] / П. Садаладж, М. Фаулер - М.: Диалектика / Вильямс, 2013 г. – 192 с. Семакин И.Г., Основы программирования и баз данных. Учебник для студентов среднего профессионального образования [Текст] / И.Г. Семакин - М.: Академия (Academia), 2014 г. – 224 с. Смирнов С.А., Практикум по работе с базами данных [Текст] / С.А. Смирнов – М.: Гелиос АРВ, 2012. – 160 с. Такахаши М., Занимательное программирование. Базы данных [Текст] / М. Такахаши - М.: ДМК Пресс, 2014 г. – 240 с. Тарасов С., СУБД для программиста. Базы данных изнутри. Справочное пособие [Текст] / С. Тарасов – М.: Солон-Пресс, 2015 г. – 320 с. Тарасов С., СУБД для программиста. Базы данных изнутри. Справочное пособие [Текст] / С. Тарасов - М.: Солон-Пресс, 2015 г. – 320 с. Туманов В.Е., Проектирование хранилищ данных для систем бизнес-аналитики. Учебное пособие [Текст] / В.Е. Туманов - М.: Интернет-Университет Информационных Технологий, 2013 г. – 615 с. Уидом Д., Реляционные базы данных. Руководство [Текст] / Д. Уидом, Д.Д. Ульман - М.: Лори, 2014 г. – 374 с. Федорова Г.Н., Основы проектирования баз данных [Текст] / Г.Н. Федорова - М.: Академия (Academia), 2014 г. – 224 с. Фуфаев Э.В., Базы данных. Учебное пособие для студентов учреждений среднего профессионального образования [Текст] / Э.В. Фуфаев, Д.Э. Фуфаев - М.: Академия, 2013 г. – 320 с. Фуфаев Э.В., Разработка и эксплуатация удаленных баз данных. Учебник для студентов учреждений среднего профессионального образования [Текст] / Э.В. Фуфаев, Д.Э. Фуфаев - М.: Академия, 2014 г. – 256 с. Приложение АКлиент/серверная архитектура MOLAP 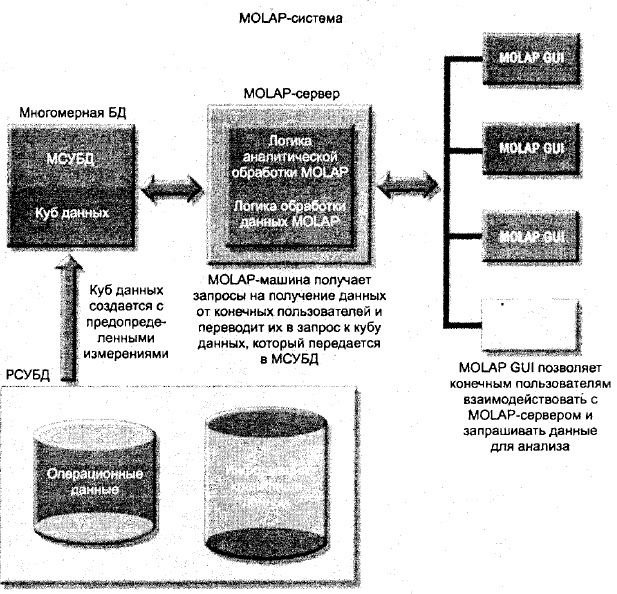 Рисунок А.1 - Клиент/серверная архитектура MOLAP |