Способы описания языка. Сам работа -. Отчет по самостоятельной работе " Основы теории компиляторов Язык. Грамматика. Способы описания языка. "
 Скачать 82.23 Kb. Скачать 82.23 Kb.
|

|
МИНИСТЕРСТВО ПО РАЗВИТИЮ ИНФОРМАТИЗАЦИИ И КОММУНИКАЦИЙ РЕСПУБЛИКИ УЗБЕКИСТАН ТАШКЕНТСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ ИМЕНИ МУХАММАДА АЛЬ-ХОРАЗМИЙ Кафедра информационно-компьютерных технологий и программирования Отчет по самостоятельной работе: “Основы теории компиляторов Язык. Грамматика. Способы описания языка.” Вариант №-15 Выполнил студент группы:11-20 ПОИТ Олимжонов Хуршидбек Олимжонович Проверил преподаватель: Доцент, Кудратов Султан Гуламович Ташкент – 2021 Цель работы. Дать основную теорию по данной теме и показать примером. Задание. Описать основы теории компиляторов, язык, грамматика, и способы описания языка. Основная часть. Теория компиляторов возникла еще в 70-х годах прошлого столетия. Тогда программисты прониклись идеей создать единый язык программирования для всего на свете и единый компилятор. Но мир меняется, и требования к языкам программирования тоже меняются. Программы решают очень разносторонние задачи, и представить, что все можно написать одним языком программирования, очень сложно. Ведь сфера деятельности у программирования разная: одно дело писать скрипт для управления полетом баллистической ракеты, а другое — скрипт для начисления зарплаты 10-ти сотрудникам. Задачи разные, подходы разные, языки программирования разные, соответственно, и компиляторы будут разные. А в последнее время вообще стало модным, чтобы у каждой крупной компании был собственный язык программирования и, соответственно, собственный компилятор. А помимо крупных фирм типа: Google, Microsoft, Oracle, есть еще масса более мелких разработчиков, которые тоже создают собственные языки и собственные компиляторы. Поэтому универсальный язык и универсальный компилятор пока остаются только в теории. Но теория создания новых компиляторов гласит, что, несмотря на компилируемый язык программирования, компиляторы используют одинаковые принципы, технологии и инструментарий в своей работе. Поэтому разработка собственного компилятора — это не что-то необычное, уже существуют наработанные структуры и способы создания компиляторов, также в сети множество блогов, статей и книг по разработке компиляторов. Компиляторы пишутся как на автокоде, так и на языках высокого уровня. Кроме того, существуют и специальные языки конструирования компиляторов – компиляторы компиляторов. Компилятор компиляторов (КК) – система, позволяющая генерировать компиляторы; на входе системы – множество грамматик, а на выходе, в идеальном случае, – программа. Иногда под КК понимают язык программирования, в котором исходная программа – это описание компилятора некоторого языка, а объектная программа – сам компилятор для этого языка. Исходная программа КК – это просто формализм, служащий для описания компиляторов, содержащий, явно или неявно, описание лексического и синтаксического анализаторов, генератора кодов и других частей создаваемого компилятора. Обычно в КК используется реализация схемы т.н. синтаксически управляемого перевода. Кроме того, некоторые из них представляют собой специальные языки высокого уровня, на которых удобно описывать алгоритмы, используемые при создании компиляторов. Это – достаточно общая схем. Реальный компилятор чаще всего представляет собой целый программный комплекс. Исходная программа – текст программы на языке высокого уровня, который должен быть переведен в машинный код. Информационные таблицы – самостоятельные структуры, заполняющиеся в ходе лексического анализа и дополняющиеся во время работы. Лексический анализатор (или сканер), имеющий на выходе поток лексем, нужен для того, чтобы убрать все лишнее (комментарии, разделители), выделить лексемы, т.е. лексические единицы, из которых строится машинный язык, и преобразовать их к внутренним или промежуточным формам представления. На этом этапе идет активная работа с таблицами, в которые заносится информация о распознанных лексемах, их типах, значениях и т.д. Результатом является поток лексем, эквивалентный исходному тексту. Синтаксический анализатор необходим для того, чтобы выяснить, удовлетворяют ли предложения, из которых состоит исходная программа, правилам грамматики этого языка. Наряду с проверкой синтаксиса параллельно происходит генерация внутренней формы представления программы. ОСНОВНЫЕ ЧАСТИ КОМПИЛЯТОРА Итак, можно выделить следующие этапы компиляции: 1) Лексический анализ. Замена лексем их внутренним представлением (например, замена операторов, разделителей и идентификаторов числами). 2) Синтаксический анализ. Иногда на этом этапе также вводятся дополнительные разделители и заменяются существующие для облегчения обработки. 3) Генерация промежуточного кода (трансляция). На этом этапе осуществляется контроль типа и вида всех идентификаторов и других операндов. При этом обычно преобразование исходной программы в промежуточную (например, польскую) форму записи осуществляется одновременно с синтаксическим анализом. 4) Оптимизация кода. 5) Распределение памяти для переменных в готовой программе. 6) Генерация объектного кода и компоновка программных сегментов. На всех этих этапах происходит работа с различного рода таблицами. В частности, для каждого блока (если таковые существуют в языке) идентификаторы, описанные внутри, запоминаются вместе со своими атрибутами. Очевидна зависимость структуры компилятора от структуры ЭВМ, точнее, от имеющейся производительности системы. Например, при малой памяти увеличивается количество проходов компиляции (т.н. многопроходные компиляторы), а при наличии памяти большого объема можно все этапы компиляции произвести за один проход (и тогда мы имеем дело с однопроходным компилятором). Тем не менее, независимо от вычислительных ресурсов, всю вышеперечисленную работу приходится так или иначе делать. Далее мы рассмотрим вкратце некоторые из этих составных частей процесса компиляции. Лексический анализ (сканер) На входе сканера – цепочка символов некоторого алфавита (именно так выглядит для сканера наша исходная программа). При этом некоторые комбинации символов рассматриваются сканером как единые объекты. Например: – Один или более пробелов заменяются одним пробелом; – Ключевые слова (вроде BEGIN, END, INTEGER и др.); – Цепочка символов, представляющая константу; – Цепочка символов, представляющая идентификатор (имя); Таким образом, лексический анализатор (ЛА) группирует определенные терминальные символы (т.е. входные символы) в единые синтаксические объекты – лексемы. В простейшем случае лексема – это пара вида. Задача выделения лексем из входного потока зачастую оказывается весьма нетривиальной и зависящей от структуры конкретного языка. Как будет интерпретироваться такая входная последовательность "567АВ"? Это может быть одна лексема (идентификатор), а может – и пара лексем – константа "567" и имя "АВ". Во втором случае либо между лексемами необходимо указание разделителя (например, пробела), либо надо заранее знать, что будет следовать дальше. Существует два основных типа лексических анализаторов – прямые (ПЛА) и непрямые (НЛА). Прямой ЛА определяет лексему, расположенную непосредственно справа от текущего указателя, и сдвигает указатель вправо от части текста, образующей лексему (ПЛА определяет тип лексемы, которая образована символами справа от указателя). Непрямой ЛА определяет, образуют ли знаки, расположенные непосредственно справа от указателя, лексему этого типа. Если да, то указатель передвигается вправо от части текста, образующей лексему. Иными словами, для него заранее задается тип лексемы, и он распознает символы справа от указателя и проверяет, удовлетворяют ли они заданному типу. У ПЛА более сложная структура – он должен выполнять больше операций, нежели НЛА. Тем не менее в большинстве современных языков программирования используется синтаксис прямых лексических анализаторов (это может быть видно по внешнему виду фраз языка). Фортран – это классический пример языка, использующего непрямой лексический анализатор. Все дело в том, что в этом языке игнорируются пробелы. Рассмотрим, например, конструкцию DO5I=1,10 … Для разбора этого предложения необходим непрямой лексический анализатор, который и определит, что означает цепочка "DO5I" – идентификатор "DO5I", или же ключевое слово "DO", за которым следует метка 5, а далее – имя переменной "I". Впрочем, аналогичные неприятности ожидают и разработчиков компиляторов языков типа C или C++, в которых существуют строковые комментарии "/*…*/" и "//…". При проведении лексического анализа, встретив символ "/", изначально неясно, является ли он оператором или началом строкового комментария. И вообще, много символьные лексемы – штука малоприятная для анализа. Итак, на выходе сканера – внутреннее представление имен, разделителей и т.п. Например: Вход сканера: AVR := B + CDE; // Комментарии Выход сканера: 38, -8, 65, -2, 184 (Если мы условимся обозначать оператор присваивания ":=" числом с кодом – 8, операцию сложения – числом –2, а имена переменных числами 38, 65 и 184). Кроме того, сканер занимается формированием различного рода таблиц. И прежде всего – таблицы имен, в которую он будет заносить распознанные имена – идентификаторы, константы, метки и т.п. Синтаксический и семантический анализ Синтаксический анализ – это процесс, в котором исследуется цепочка лексем и устанавливается, удовлетворяет ли она структурным условиям, явно сформулированным в определении синтаксиса языка. Это – самая сложная часть компилятора. Синтаксический анализатор расчленяет исходную программу на составные части, формирует ее внутреннее представление, заносит информацию в таблицу символов и другие таблицы. При этом производится полный синтаксический и, по возможности, семантический контроль программы. Фактически, это – синтаксически управляемая программа. При этом обычно стремятся отделить синтаксис от семантики насколько это возможно – когда синтаксический анализатор распознает конструкцию исходного языка, он вызывает семантическую процедуру, которая контролирует эту конструкцию, заносит информацию куда надо, проверяет на дублирование описания переменных, проверяет соответствие типов и т.п. Предложения исходной программы обычно записываются в инфиксной форме. Однако эта привычная форма, в которой оператор записывается между операндами, является совершенно не пригодной для автоматического вычисления. Дело в том, что необходимо постоянно помнить о приоритетах операторов, "забегая" при анализе выражения "вперед". К тому же очень усложняют жизнь применяемые скобки, определяющие очередность вычислений. Альтернативой инфиксной форме является польская форма записи (в честь польского математика Лукасевича): постфиксная и префиксная. Обычно под польской формой понимают именно постфиксную форму записи. Кроме того, используются и такие внутренние формы представления исходной программы, как дерево (синтаксическое) и тетрады. Дерево. Пусть имеется входная цепочка i= (a + b) * c. Тогда дерево будет выглядеть так:    = * = *  + + i i У каждого элемента дерева может быть только один “предок”. Дерево “читается” снизу вверх и слева направо. Дерево – это прежде всего удобная математическая абстракция. На практике дерево можно реализовать в виде списковой структуры. Польская форма записи. Существуют три вида записи выражений: инфиксная форма, в которой оператор расположен между операндами (например, " а + b"); постфиксная форма, в которой оператор расположен после операндов (то же выражение выглядит как "а b + "); префиксная форма, в которой оператор расположен перед операндами ("+ а b"). Постфиксная и префиксная формы образуют т.н. польскую форму записи. Польская форма удобна прежде всего тем, что в ней отсутствуют скобки. На практике наиболее часто используется постфиксная форма. Поэтому под польской обычно понимают именно постфиксную форму записи. В этой форме записи выражение I = (a + b) * c выглядит так: " Iab+c*=". Это выражение удобно расписывается по дереву: с нижней строки записываются “a” и “b”, далее “+” и “с”, выше – “i” и “*” и в вершине дерева “=”. Язык программирования – это система обозначений и понятий для описания структур данных и алгоритмов. Алфавит языка – набор символов, которые разрешено использовать. Синтаксис – система правил, по которым записываются конструкции языка. Семантика – набор правил, на основе которых следует истолковывать эти конструкции. Не случайно используются термины «система правил» и «набор правил», некоторое различие здесь имеется. Идеального способа описания языка программирования пока не найдено. Одна из причин – неоднозначность конструкций естественных языков, которые используются при этом. Кроме того, трудности описания языков программирования связаны с интересами субъектов: авторы языка стремятся изложить свои идеи строго, лаконично и красиво, разработчиков транслятора интересует совсем другое в описании языка – как быстрее и эффективнее анализировать исходный текст, а программистам хочется программировать, а не тратить время на изучение документации. Различают неформальное и формальное описание языков программирования. В учебниках, как правило, изложение неформальное: можно писать так, а можно немного по – другому. Вот примеры, mach mit, mach wie, mach besser☺. Формальное описание языка требует больших усилий. Обычно все начинается с описания синтаксиса. Для этого используются некоторый вспомогательный язык – метаязык. Средства описания языков программирования.Как уже указывалось, язык программирования должен иметь алфавит, синтаксис и семантику. Правила, определяющие структуру текста, составляют синтаксис (грамматику). Правила, позволяющие извлекать из текста смысл, называются семантикой языка. Для описания синтаксиса языка используется так называемый метаязык (язык для описания языка). В качестве метаязыка используют либо металингвистические формулы Бэкуса—Наура, либо синтаксические диаграммы. Джон Бэкус разработал специальную систему определений для языков программирования. Например, определяя элемент «цифра», он указывал: <цифра>:: =0|1|2|3|4|5|6|7|8|9. Этот способ записи назвали нормальной формой Бэкуса, или БНФ. Датский астроном П. Наур внес некоторые уточнения, и форму стали называть формой Бэкуса—Наура, но сокращенное название БНФ осталось. БНФ-нотация – это мета синтаксический язык, описывающий синтаксис языков программирования, однако не всё можно описать с помощью БНФ. Существуют контекстно-зависимые условия, для описания которых необходимы зависимые свойства. Синтаксис языков программирования устанавливается над множеством основных символов, из которых строятся синтаксические правильные последовательности символов подмножества слов, допустимых для записи конструкций языка программирования. Семантика смысла этих конструкций целиком зависит от синтаксического языка. Для записи конструкции языка с помощью БНФ используют определенные мета символы и понятия регулярного выражения. ::= Метасимволы по определению есть | или [R]-x регулярное выражение RQ Конкатенация регулярного выражения {R} регулярное выражение или значение пусто {R}+ регулярное выражение хотя бы один раз {R}* регулярное выражение повторенное многократно {} множество пусто <действительное число>::=0 | [ [ {-}<простая цифра>{цифра}*] {{<цифра>}<простая цифра>}] Где<цифра>::+0| <Простая цифра>::=1|2|3|5|6|7|8|9. Синтаксичские диаграммы разработаны Н.Виртом, используется два грамматических символа: 1)Записываются терминальные символы 2)Не терминальные символы, для которых нужно создать синтаксически диаграммы Эти графически символы соединяются стрелками. Определяемая конструкция записываемая на входной стрелкой и синтаксическая правильной конструкция получается если пройти от входной стрелки к выходной по одному из путей. В БНФ каждое понятие определяется с помощью одной металингвистической формулы, в левой части которой указываются определяемые понятия, а в правой — описываются все допустимые структуры языка, соответствующие этому понятию. Левая и правая части формулы связываются знаком::=, который читается «по определению есть». При перечислении дополнительных вариантов структур в правой части используется знак |, имеющий смысл «или». Все определяемые понятия языка программирования заключаются в угловые скобки < >, а неопределяемые исходные понятия языка называются лексемами. Лексемы могут использоваться в правой части формулы. Например, определить понятие <целое число>, если алфавит языка программирования включает арабские цифры и знаки арифметических операций. Сначала определим понятие <цифра> (см. ранее). Затем введем понятие <целое без знака>, описав его следующей формулой: <целое без знака>::= <цифра> | <целое без знака> <цифра> Это равносильно определению «любая последовательность цифр». Формула рекурсивна, так как <целое без знака> уже встречается в правой части, т. е. имеется ссылка на само себя. Теперь выведем формулу: <целое число>::= <целое без знака> | -<целое без знака> | I + <целое без знаках Полученная цепочка из трех формул определяет понятие <целое число> через лексемы языка 0, 1, 9, +, С помощью металингвистических формул могут быть описаны все понятия языка программирования. Синтаксическая правильность текста проверяется в процессе его синтаксического анализа на основе металингвистических формул. Способ описания синтаксиса на основе диаграмм основан на тех же принципах. На рис. 3.9 приводится изображение понятия «цифра» в виде диаграммы. 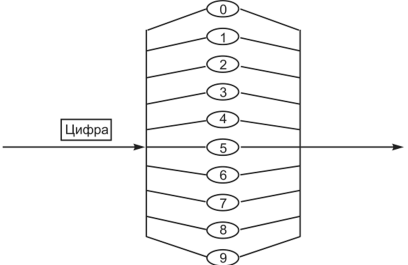 Рис. 3.9. Синтаксическая диаграмма понятия «цифра» Синтаксические диаграммы графически изображают допустимую структуру определяемого понятия. Следование элементов структуры задается стрелками, вариантность указывается как распараллеливание направлений следования. Лексемы изображают в виде кружка или овала, а определяемое понятие — в виде прямоугольника. Диаграмма имеет одну входную и одну выходную стрелки. Язык и грамматика Формальный язык является объединением нескольких множеств: множества исходных символов, называемых литерами (алфавит), множества правил, которые позволяют строить из букв алфавита новые слова (правила порождения слов или идентификаторов), множества предопределённых идентификаторов или словаря ключевых слов (прочие идентификаторы называются именами), множества правил, которые позволяют собирать из имён и ключевых слов выражения, на основе которых строятся простые и сложные предложения (правила порождения операторов или предложений). Множество правил порождения слов, выражений и предложений называют грамматикой формального языка или формальной грамматикой. У формального языка много общего с естественным языком, предложения которого также строятся в соответствии с грамматическими правилами. Однако грамматика естественного языка, подобно наукам о природе с известной степенью достоверности описывает и обобщает результаты наблюдений за естественным языком как за явлением окружающего мира. Характерные для грамматики естественных языков исключения из правил свидетельствуют о том, что зафиксированная в грамматике языка система правил не может в точности описать все закономерности развития языка. Формальные языки проще естественных языков. Они создаются одновременно с системой правил построения слов и предложений. Исключения из правил в формальном языке могут свидетельствовать лишь о противоречивости и некорректности системы грамматических правил. Однако и здесь не всё так просто. В языке программирования C++ существуют так называемые дополнительные специальные правила соотнесения (соотнесения имени и его области действия - скоро мы встретимся с этими правилами). Так вот эти правила (а, может быть, соглашения?) вполне можно рассматривать как аналоги исключений, поскольку они директивно (по соглашению) отдают предпочтение одной из возможных альтернатив. Грамматические правила можно записывать различными способами. Грамматика естественного языка традиционно описывается в виде грамматических правил на естественном языке. Грамматика формального языка также может быть описана в виде множества правил на естественном языке. Но обычно для этого используют специальные средства записи: формулы и схемы. В качестве примера рассмотрим простой формальный язык. Алфавит этого языка состоит из 17 букв: А Б Е З И Й К Н О П Р С Т У Ч Ш Ы и одного знака пунктуации - '.' (точки). Рассмотрим систему правил, составляющих грамматику языка. Правила словообразования (мы не будем вдаваться в их подробное описание) позволяют сформировать из букв языка 5 различных идентификаторов (имён и ключевых слов): КУБ ШАР ПРОЗРАЧНЫЙ СИНИЙ УКРАШАЕТ и ни одним идентификатором больше. Идентификаторы КУБ и ШАР считаются именами, прочие идентификаторы считаются ключевыми словами. По весьма отдалённой аналогии с естественным языком, ключевые слова будут играть роли членов предложения и частей речи. Определение сказуемого (это член предложения): ключевое слово УКРАШАЕТ будем считать сказуемым. Определение прилагательного (это часть речи): ключевые слова ПРОЗРАЧНЫЙ и СИНИЙ будем считать прилагательными. Имена играют роль существительных. По аналогии с естественным языком, где предложения строятся из членов предложений, предложения-операторы языка состоят из членов предложений-выражений. Часть выражений считается подлежащими, часть - дополнениями. Определение подлежащего: выражения-подлежащие состоят из ключевого слова-прилагательного и имени. Определение дополнения: выражения-дополнения состоят из ключевого слова-прилагательного и имени (одного из двух). Определение оператора (это последнее правило грамматики): предложение состоит из тройки выражений, самым первым из которых является подлежащее, затем сказуемое и дополнение. Предложение заканчивается точкой. Только что нами была определена грамматика формального языка. Она была описана привычным способом, с помощью нескольких предложений русского языка. Рассмотрим ещё один способ записи этой грамматики - с помощью формул. Запишем сначала в виде формулы определение оператора: Оператор ::= подлежащее сказуемое дополнение . (1) В этой формуле символ::= следует читать как "является" или "заменить". Затем определим в виде формул подлежащее и дополнение: Подлежащее ::= прилагательное существительное (2) Дополнение ::= прилагательное существительное (3) Следующая формула отражает тот факт, что сказуемым является ключевое слово УКРАШАЕТ. Сказуемое ::= УКРАШАЕТ (4) Следующее правило определяет прилагательное: Прилагательное ::= ПРОЗРАЧНЫЙ | СИНИЙ (5) Здесь вертикальная черта между двумя ключевыми словами означает, альтернативу (прилагательным в выражении может быть либо ключевое слово ПРОЗРАЧНЫЙ, либо ключевое слово СИНИЙ). Существует еще, по крайней мере, один способ описания альтернативы. Воспользуемся им при определении существительного. Это правило задаёт множество имён: Существительное ::= ШАР (6) ::= КУБ Правила построения предложений в нашем языке оказались записаны с помощью шести коротких формул. Слова, стоящие справа и слева от знака "заменить" принято называть символами формальной грамматики, а сами формулы грамматическими правилами. Заметим, что символы в формулах грамматики не являются словами в обычном смысле этого слова. Символ в формуле является лишь своеобразным иероглифом, по внешнему виду напоминающим слово. При изменении внешнего вида символов суть формул грамматики нисколько бы не изменилась. Мы всего лишь используем возможность кодирования дополнительной информации с помощью внешнего вида символа. В надежде, что это поможет лучше понять происходящее. Символы, которые встречаются только в левой части правил, называются начальными нетерминальными символами или начальными нетерминалами. Символы, которые встречаются как в левой, так и в правой части грамматических правил называются нетерминальными символами. Символы, которые встречаются только в правой части правил, называются терминальными символами. Воспользуемся этой грамматикой и построим несколько предложений. Алгоритм порождения операторов-предложений и отдельных выражений с помощью правил формальной грамматики очень прост: Выбрать начальный нетерминал (оператор) или отдельный нетерминальный символ, найти правило, содержащее этот символ в левой части и заменить его на символ или на последовательность символов из правой части правила. Процесс замены продолжать до тех пор, пока в предложении будут встречаться нетерминальные символы. Выбор нетерминального символа обеспечивает порождение выражения, выбор начального нетерминала обеспечивает вывод оператора: Оператор (1) Подлежащее сказуемое дополнение. (2) Прилагательное существительное сказуемое дополнение. (3) Прилагательное существительное сказуемое прилагательное существительное. (4) Прилагательное существительное УКРАШАЕТ прилагательное существительное. (5) ПРОЗРАЧНЫЙ существительное УКРАШАЕТ СИНИЙ существительное. (6) ПРОЗРАЧНЫЙ ШАР УКРАШАЕТ СИНИЙ КУБ. Больше терминальных символов нет. По правилам формальной грамматики мы построили первое предложение языка. СИНИЙ КУБ УКРАШАЕТ ПРОЗРАЧНЫЙ КУБ. Это ещё одно предложение нашего языка. Формальная грамматика может использоваться не только для порождения предложений, но и для проверки, является ли какая-либо последовательность символов выражением языка. Для этого среди символов исследуемой последовательности надо сначала отыскать терминальные символы и применяя правила формальной грамматики, справа налево заменять терминальные символы нетерминальными, а затем "сворачивать" последовательности нетерминальных символов до тех пор, пока не будет получен начальный нетерминал, или окажется единственный нетерминальный символ. Так последовательность символов СИНИЙ КУБ ВЕНЧАЕТ ПРОЗРАЧНЫЙ КУБ. не является оператором языка, поскольку символ ВЕНЧАЕТ не встречается среди нетерминальных символов. В свою очередь, пара терминальных символов СИНИЙ ШАР является выражением нашего языка и может быть как подлежащим, так и дополнением, поскольку может быть преобразована как в нетерминальный символ подлежащее, так и в нетерминальный символ дополнение. Вывод. Рассмотренный нами способ записи правил грамматики языка называется формой Бэкуса-Наура (сокращенно БНФ). Зачем они и что, собственно, с ними делать? Не бояться их. Смотреть на них. Читать их. Символы формальной грамматики складываются в основном из букв родного алфавита. Формулы кратки и информативны. Правила, для изложения которых обычно требуется несколько фраз естественного языка, часто описываются одной формой Бэкуса-Наура. После небольшой тренировки чтение этих форм становится лёгким и приятным занятием. Впервые БНФ были использованы при описании языка программирования Алгол более 30 лет назад и до сих пор БНФ применяются для описания грамматики при разработке новых языков программирования. Это очень эффективное и мощное средство. Без лишних слов, просто, лаконично, наглядно. Мы часто будем использовать эти формы. При этом нетерминальные символы в БНФ будут выделяться подчёркиванием. Подобно предложениям естественного языка, которые обычно служат основой связного повествования (сказки, романа, научного исследования), предложения формального языка также могут быть использованы для описания всевозможных явлений и процессов. Множества операторов языка программирования служат для создания программ - основного жанра произведений, для которых и используются эти языки. Программы пишут для различных программируемых устройств. К их числу относятся и электронно-вычислительные машины, которые в настоящее время являются наиболее универсальными вычислительными устройствами и основными потребителями программ. |