Отчет по практике. Отчёт по практике. Отчет по учебной практике "Парсер контента" Студент группы оаб 09. 03. 03 31э Кузнецов Станислав Анатольевич
 Скачать 0.71 Mb. Скачать 0.71 Mb.
|

|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ ФГБОУ ВО «Удмуртский государственный университет» Институт математики, информационных технологий и физики Кафедра теоретических основ информатики Сроки прохождения практики: с 01.06.2019 г. по 14.06.2019 г. (в соответствии с календарным учебным графиком) ОТЧЕТ ПО УЧЕБНОЙ ПРАКТИКЕ "Парсер контента" Студент группы ОАБ 09.03.03 31э__________Кузнецов Станислав Анатольевич Руководитель практики от университета __________________________ Логов Алексей Генритович Дата сдачи Дата защиты Оценка __________________ Ижевск 2020 Оглавление ОглавлениеВведение 3 Постановка задач 4 Описание метода решения 5 Заключение 7 Список источников 8 Приложения 9 ВведениеСовременный сайт на просторах сети Интернет — это, прежде всего, источник уникальной и полезной информации. Люди в сети ищут нужную им информацию, будь то погода, новости, товары или услуги. Для поиска по Всемирной паутине используют, специально сделанные для этого, поисковики. Каждому сайту необходим свой поисковик, который помогает найти, нужную для пользователя, информацию. Парсер позволяет собирать и анализировать информацию с интересующего нас сайта. Другими словами, мы можем добыть все необходимые нам данные — тексты, изображения, номера телефонов и другую информацию которая есть сайтах. Постановка задачДля достижения результата определены следующие задачи: 1. Изучить тематический материал; 2. Проанализировать методы извлечения информации со сторонних веб-сайтов; 3. Разработать парсер; Описание метода решения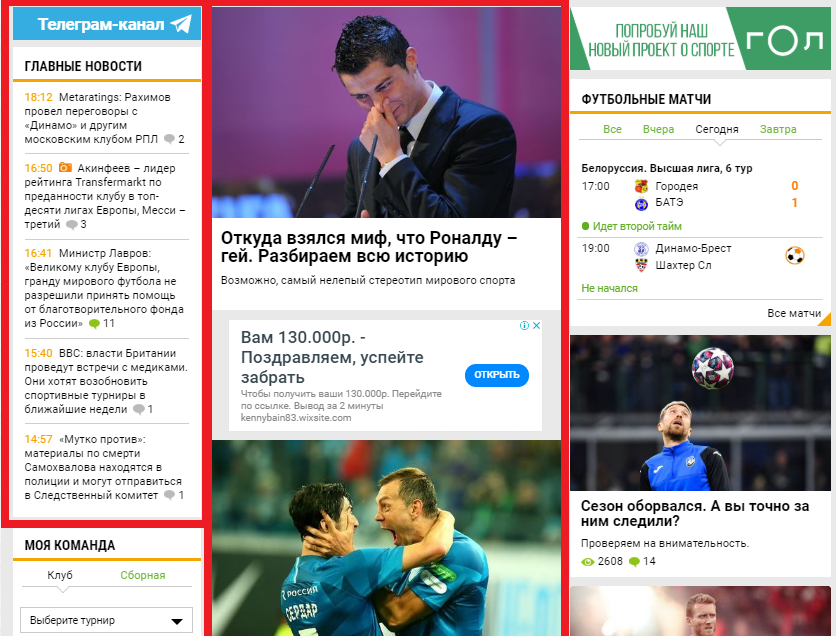 В качестве примера возьмем новости футбола с сайта bombardir.ru. Цель - спарсить главные новости и статьи из центральной блока (Рис. 1). В качестве примера возьмем новости футбола с сайта bombardir.ru. Цель - спарсить главные новости и статьи из центральной блока (Рис. 1).Рис. 1 Работа парсера основана на библиотеке phpQuery. Url сайта помещаем в переменную $site. С помощью file_get_contents считываем весь контент с сайта. Создаем объект phpQuery и вызываем метод newDocument. В качестве входящего параметра мы передаем контент, который находится в переменной $file. В инспекторе кода на сайте выясняем, что блок с новостями находится в контейнере с классом .soc-news. Каждая новость находится в блоке .soc-text a. Из этой ссылки мы вытащим заголовок новости и ссылку на новость. В переменную $newsItems заносим элементы новостей. Воздаем пустой массив $news, в который запишем нужные нам данные. В цикле на каждый элемент создаем объект $newsItem. Затем вытаскиваем заголовок и ссылку в $title и $link и проверяем наличие строки домена в ссылке. И в конце полученные данные помещаются в массив $news. Со статьями из центрального блока делаем то же самое. Результат работы парсера: 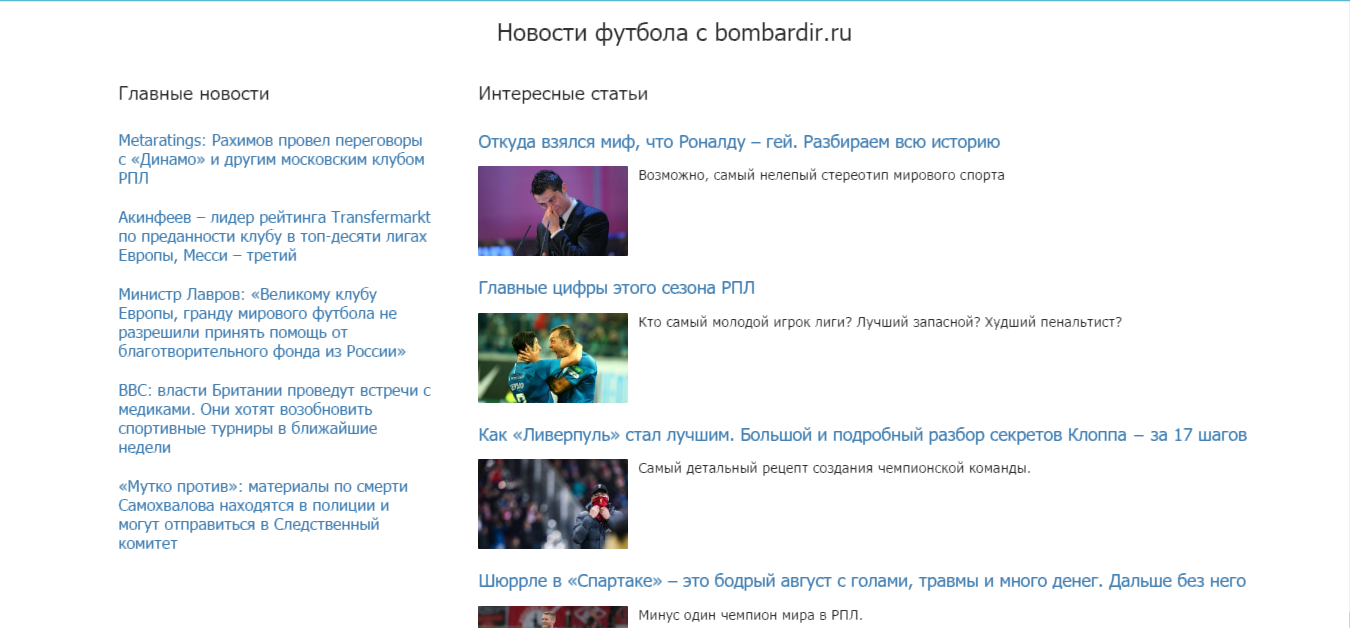 Рис. 2 ЗаключениеБлагодаря этой работе я приобрел навыки разработки простейшего парсера. Познакомился с библиотекой phpQuery, которая значительно упрощает труд разработчика. И в целом обновил свои знания языка PHP. Список источниковПортал по PHP MySQL и другим веб-технологиям [Электронный ресурс] / http://www.php.su/ Руководство по PHP [Электронный ресурс] / https://www.php.net/manual/ru/index.php Приложения Рис. 3  Рис. 4 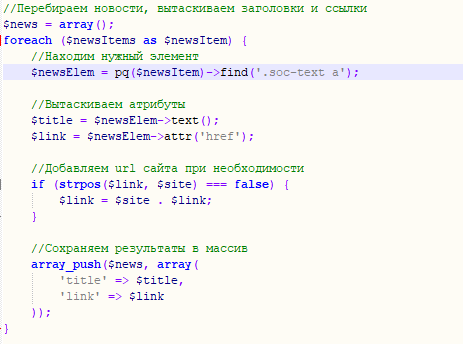 Рис. 5 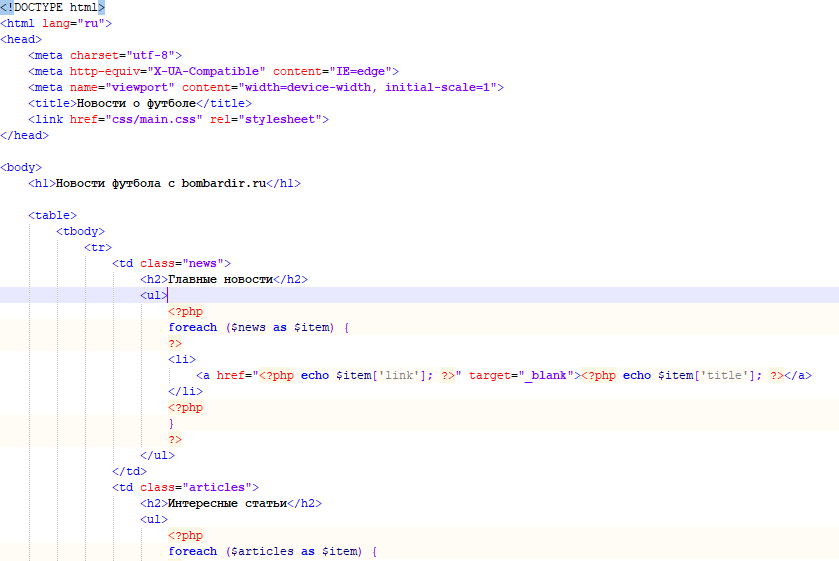 Рис. 6 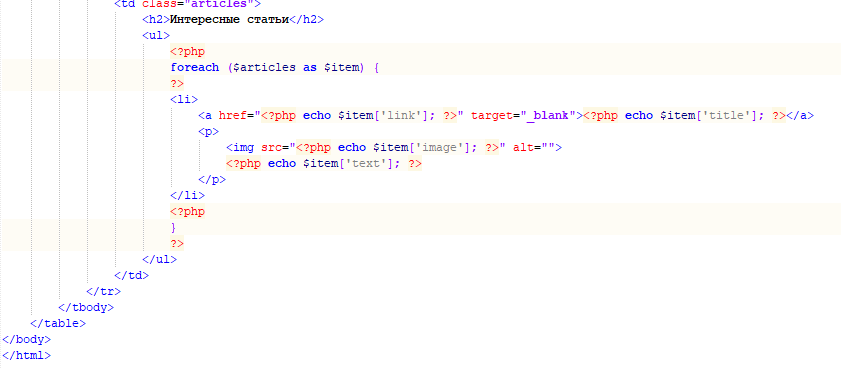 Рис. 7 Рис. 7 |