Отечественные поисковые системы
 Скачать 0.62 Mb. Скачать 0.62 Mb.
|

|
Задание 1. Составьте схему «Зарубежные и отечественные поисковые машины». Отечественные поисковые системы.ЯндексЯндекс — это крупнейший российский портал, предлагающий пользователям ключевые интернет-сервисы. По данным исследовательских компаний Gallup Media, ФОМ и Комкон, он является самым большим ресурсом в Рунете по объему аудитории. Среди служб Яндекса — поиск в Интернете и каталог сайтов, платежная система и последние новости, карты и энциклопедии, электронная почта и система фильтрации спама (Спамооборона), бесплатный хостинг (Народ) и каталог товарных предложений магазинов (Маркет), а также многое другое. Отличительная особенность Яндекса — возможность точной настройки поискового запроса. Это реализовано за счёт гибкого языка запросов. Яндекс не требует от вас знания специальных команд для поиска. Достаточно набрать вопрос — так же, как бы вы его задали библиотекарю или всезнайке-эрудиту. Например, звезда мирового футбола или контекстная реклама на Яндексе. РамблерПоисковая систем Рамблер уже давно превратилась в мега-портал и имеет очень большой набор сервисов. По данным SpyLog на Рамблер приходится около 20-25% поисковых запросов в Рунете. При поиске Рамблер учитывает морфологию русского языка. Данная поисковая машина, как и многие другие, имеет расширенный поиск, что дает возможность задавать дополнительные параметры поиска. Так же имеется язык поисковых запросов. Регистр поисковых запросов учитывается лишь в некоторых случаях. Для поиска цитат можно использовать двойные кавычки. По каждому слову запроса поиск ведется с учетом правил словоизменения соответствующего языка. Рамблер понимает и различает слова русского и английского языков - по умолчанию, поиск ведется по всем формам слова. Имеются специальные операторы которые позволяют искать страницы, на которых размещены счетчики Top100, TopShop, TopList, SpyLog, а также HotLog. В помощи Рамблера вы сможете найти подробное описание языка запросов и расширенного поиска. АпортПоисковая система Апорт является одной из популярных поисковых машин российского Интернета. Апорт позволяет пользователям осуществлять полнотекстовый поиск документов c учетом морфологии русского языка в запросах. Поисковая система построена на основании новейших достижений в области информационного поиска и использует уникальные алгоритмы сортировки найденных результатов. Техническая база и программное обеспечение Апорта постоянно совершенствуются, что ведет к наращиванию объема поисковой базы и обеспечению высокой частоты индексации русскоязычных ресурсов Интернета. Разнообразные специализированные поиски дают пользователям дополнительные возможности находить различную информацию в Сети. В поисковую машину интегрирован один из крупнейших в Рунете каталогов интернет-ресурсов "Апорт.Каталог". Зарубежные поисковые системыGoogle (от Googol – число со ста нулями после единицы) – одна из самых популярных во всем мире поисковых машин. Google обеспечивает поиск по гипертекстовым документам, находящихся в любых языковых зонах - английской, русской, украинской, немецкой и др. Поисковая система Google имеет собственные поддомены для большинства стран, например, для России. Google ищет не только гипертекстовые файлы (html), но и файлы в формате PDF, DOC, PostScript, Corel WordPerfect и др. MSNMSN search поддерживается Microsoft и размещается по адресу http:/ /search.msn.com. Эта поисковая система не имеет собственного паука (поискового робота) или каталога, она использует данные из Inktomi, LookSmart, Direct Hit. MSN особенно важна т.к. именно эта поисковая система по умолчанию используется, когда пользователи Internet Explorer(а) вводят в адресную строку поисковый запрос. MSN также является информационным узлом, и по данным MediaMetrix, является одним из наиболее посещаемых сайтов. Задание 2. Составьте таблицу «Зарубежные и отечественные поисковые каталоги».
Задание 3. Составьте алгоритм работы в поисковых системах: Google, Яndex, Рэмблер В России основной поисковой системой является «Яндекс», далее – Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса». Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов. Модуль индексирования Модуль индексирования состоит из трех вспомогательных программ (роботов):Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ. Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате: URL страницы дата, когда страница была скачана http-заголовок ответа сервера тело страницы (html-код) Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача - определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе. Indexer (робот- индексатор) – программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д. Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов. База данных База данных, или индекс поисковой системы - это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов. Поисковый сервер Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска. Поисковый сервер работает следующим образом: Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска). Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы. В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»). Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются. Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов. Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов. По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке. 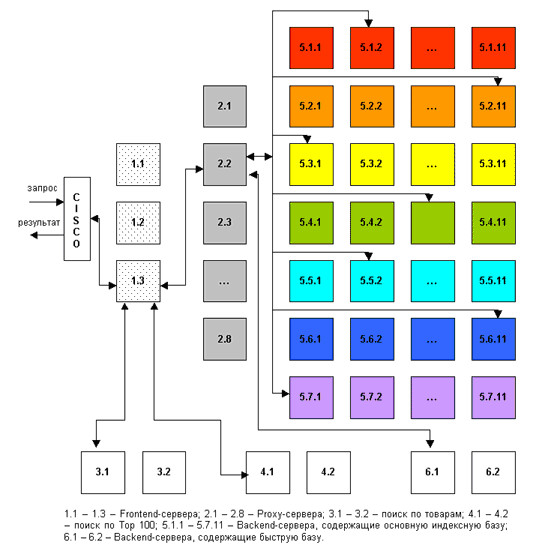 Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня - frontend (1.1 - 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.1 - 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 - 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 - 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, - backends (5.1.х - 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с "быстрой базой" (6.1 - 6.2). На текущий момент в поиск включено 77 backend'ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend'ах первой группы (5.1.1 - 5.1.11 на рис), оранжевый сектор - на backend'ах второй группы (5.2.1 - 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend'ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу. После того, как запрос обработан на backend'ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин "быстрой базы". Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend'ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим – с 6.1, четвертым - с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend. Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю. При написании мастер-класса были использованы материалы и данные ООО «Рамблер Интернет Холдинг», RuSeo.info Задание 4. Составьте алгоритм работы с каталогами Yahoo, Апорт Yahoo Yahoo считается одной из ведущих поисковых систем. Поисковые запросы в Yahoo составляют около 28% от всего поискового трафика. Портал Yahoo продолжает предлагать своим пользователям неограниченные возможности благодаря постоянно совершенствующемуся алгоритму. Yahoo неоднократно и кардинально меняла принципы своей работы. Задача Yahoo – предоставление релевантных результатов своим пользователям в тех областях, где компьютерные алгоритмы «не оправдывают ожиданий» (речь идет о персонализированных результатах и мнениях). Компания Yahoo ввела «социальный поиск», которому дали название My Web 2.0. Новый вид поисковой системы – социальная поисковая система, которая дополняет Интернет-поиск, позволяя пользователям получать ответы на интересующие вопросы не только в Интернет-ресурсах, но и непосредственно от знакомых и друзей.Технология, которой руководствуется «социальный поиск», называется My Rank. My Rank обладает всеми преимуществами алгоритмического поиска и совмещает в себе многие достоинства, руководствуясь всего одной идеей: субъективное мнение по тем или иным вопросам. Технология My Rank позволяет получать ответы на интересующие вопросы не только от поисковиков, но и от определённых людей, оценивать эти мнения с целью нахождения оптимальных ответов, которые, по Вашему мнению, являются наиболее релевантными. Тем более, речь идет о людях, которые Вам знакомы, которые разделяют Ваши интересы, работают, возможно, в Вашей структуре и потенциально искали ответы на те же вопросы, что и Вы. Совмещая возможности алгоритмического поиска с возможностью «войти в знакомое сообщество», технология My Rank способствует нахождению более релевантных ответов. Все это становится реальностью благодаря предоставляемой возможности избирать, сохранять и делиться информацией с другими людьми, точно так же, как и получать информацию, с которой готовы поделиться другие люди.Социальный поиск привнес нечто новое в Интернет. Теперь поисковые результаты находятся в некоторой зависимости от мнения определенных людей. Концептуальный поиск от Yahoo На протяжении длительного периода времени Yahoo стремится стать уникальной концептуальной поисковой системой. Какая теория лежит за понятием «концептуальная модель поисковой системы»? Компания Yahoo придерживается следующего мнения: все, что люди выражают сложной терминологией, можно заключить в простые понятия. Например, «Гавайи» и «Нью-Йорк» - абсолютно разные запросы, как по длине, так и по количеству слов, но в человеческом восприятии они совмещают в себе одно понятие. И, наоборот, человек воспринимает запрос «правоохранительные органы Нью-Йорка» как запрос, содержащий 2 разных понятия: «Нью-Йорк» и «правоохранительные органы». Люди рассуждают о логической связи между понятиями. Например, понятия «правоохранительные органы» и «полиция» можно отнести к смежным областям. Пользователь, который вводит в поисковую строку одно из понятий, может заинтересоваться сайтами, которые относятся к смежному понятию, даже, если оно не содержит слов запроса. До сих пор остается непонятным, какую технологию использует Yahoo, совершенствуя концептуальный поиск. Есть основания подозревать, что Yahoo предложит концептуальный поиск в виде отдельной поисковой системы, с использованием «социального поиска». Тем не менее, стремление предложить пользователям точную информацию в соответствии с их индивидуальными потребностями, выглядит, по меньшей мере, утопично. Yahoo уделяет первостепенное значение плотности ключевых слов. По некоторым оценкам, плотность ключевых слов в < title > составляет около 10% от требований алгоритма рассматриваемой поисковой системы. На первый взгляд, кажется, что алгоритм Yahoo представляет собой полную противоположность приоритетам, которым уделяет внимание Google. Но на самом деле это не так. Некоторые ассоциируют нынешний алгоритм Yahoo с алгоритмом Google двухлетней давности. С момента появления алгоритма Inktomi, поисковая система Yahoo стала уделять большее внимание обратным ссылкам, и все же это не является основополагающим компонентом работы алгоритма Yahoo, в отличие от алгоритма Google. Оптимизируя под Yahoo, важно помнить, что алгоритм этой поисковой системы заинтересован в таких факторах, как контент, использование ключевых слов на странице, плотность ключевых слов на странице, жирный текст. Учитываются такие внешние факторы, как ссылочный текст, входящие ссылки и т.д. Yahoo предпочитает видеть ключевые слова в самих URL сайта или страниц, но отдает предпочтение жирному тексту, тексту, заключенному в < h1>. Апорт-КаталогАпорт-Каталог во многом схож с каталогом Яндекса, но, пожалуй, в несколько меньшей степени оказывает влияние на результаты поиска. Действие каталожного листинга также происходит по схеме ссылочного ранжирования, однако помимо названия и описания, учитывается и список ключевых слов, задающийся при регистрации, но не отображаемый в каталоге. Ресурсы могут заноситься одновременно в несколько категорий каталога, при условии соответствия их содержанию. Ещё одной особенностью можно назвать тот факт, что в результатах поиска Апорта для главных страниц сайтов, присутствующих в каталоге, всегда выводится название и описание ресурса именно из каталога. Регистрационные данные для каталога подаются одновременно с регистрацией в поисковой системе (http://catalog.aport.ru/rus/reg/add.ple). При включении ресурса в каталог на указанный при регистрации почтовый адрес высылается уведомление. Задание 5. Составьте словарь терминов по изученной теме.     |