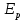Параллельное вычисление произведения двух матриц
 Скачать 159.88 Kb. Скачать 159.88 Kb.
|

|
Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования "Уфимский государственный авиационный технический университет" Кафедра Высокопроизводительных вычислительных технологий и систем Дисциплина: Параллельное программирование Отчет по лабораторной работе № 2 Тема: «Параллельное вычисление произведения двух матриц»
Уфа 2020 Цель: научиться использовать принцип геометрической декомпозиции в параллельных алгоритмах и создавать параллельные программы для систем с распределенной памятью с использованием коллективных функций MPI на примере вычисления произведения двух матриц. Теоретический материал Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу. MPI является наиболее распространённым стандартом интерфейса обмена данными в параллельном программировании, существуют его реализации для большого числа компьютерных платформ. Используется при разработке программ для кластеров и суперкомпьютеров. Основным средством коммуникации между процессами в MPI является передача сообщений друг другу. Базовым механизмом связи между MPI процессами является передача и приём сообщений. Сообщение несёт в себе передаваемые данные и информацию, позволяющую принимающей стороне осуществлять их выборочный приём: отправитель — ранг (номер в группе) отправителя сообщения; получатель — ранг получателя; признак — может использоваться для разделения различных видов сообщений; коммуникатор — код группы процессов. Функция инициализации MP: int MPI_Init(int *argc, char **argv[]); возвращает предопределенные константы MPI_SUCCESS - возвращается в случае успешного выполнения MPI_ERR_ARG- ошибка неправильного задания аргумента MPI_ERR_INTERN- внутренняя ошибка (нехватка памяти) MPI_ERR_UNKNOWN- неизвестная ошибка Функция завершения работы с MPI: int MPI_Finalize(void); Функция определения количества процессов size в коммуникационной группе с коммуникатором comm: int MPI_Comm_size(MPI_Comm comm, int* size); Функция, возвращающая номер rank вызвавшего ее процесса, входящего в коммуникационную группу с коммуникатором comm: int MPI_Comm_rank(MPI_comm comm, int* rank); Блокирующая функция передачи данных: int MPI_Send(void* sbuf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm); Входные параметры: sbuf – адрес в памяти, начиная с которого размещаются передаваемые данные; count – количество передаваемых элементов; datatype – тип передаваемых элементов; dest – номер процесса-получателя сообщения; tag – метка передаваемого сообщения; comm – коммуникатор Блокирующая функция приема данных: int MPI_Recv(void* rbuf, int count, MPI_Datatype datatype, int source, int tag, MPI_comm comm, MPI_Status *status); Входные параметры: count – количество получаемых элементов; datatype – тип получаемых элементов; source – номер процесса-отправителя сообщения; tag – метка принимаемого сообщения; comm – коммуникатор. Выходные параметры: rbuf – адрес в памяти, начиная с которого размещаются принимаемые данные; status – структура, содержащая информацию о принятом сообщении. Структура status имеет три поля. Status.MPI_SOURCE - номер процесса-отправителя; Status.MPI_TAG - метка принимаемого сообщения; Status.MPI_ERROR - код завершения приема сообщения. Тип данных datatype может быть одной из предопределенных констант. MPI_CHAR MPI_UNSIGNED_CHAR MPI_SHORT MPI_UNSIGNED_SHORT MPI_INT MPI_UNSIGNED_INT MPI_LONG MPI_UNSIGNED_LONG MPI_FLOAT MPI_DOUBLE MPI_LONG_DOUBLE MPI_BYTE MPI_PACKED Определение времени выполнения параллельной программы: double MPI_Wtime(); Определение. Отношение времени выполнения параллельной программы на одном процессоре (ядре) 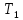 ко времени выполнения параллельной программы на p процессорах ко времени выполнения параллельной программы на p процессорах 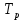 называется ускорением при использовании p процессоров: называется ускорением при использовании p процессоров: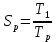 Определение. Отношение ускорения 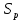 к количеству процессоров p называется эффективностью при использовании p процессоров: к количеству процессоров p называется эффективностью при использовании p процессоров: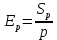 Характеристики процессора: 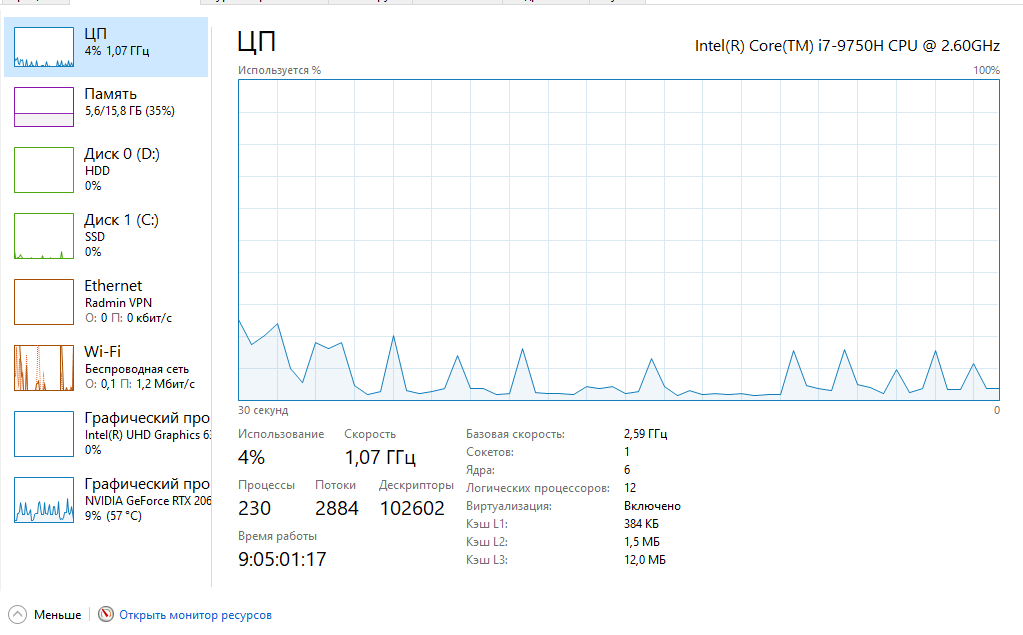 Задание №1 Требуется вычислить произведение матриц A(N*L) и B(L*L) и вычислить квадрат евклидовой нормы результирующей матрицы: 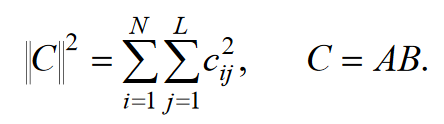 Матричное умножение выражается формулой: 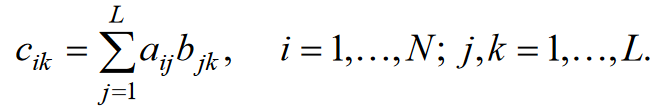 Написать программу с использованием коллективных функций MPI В программе предусмотреть следующее а) размерность L вводится пользователем, размерность N=10L; б) матрицы заполняются случайными элементами вещественного типа; в) замер времени выполнения параллельной программы (вычисления + коммуникации). Запустить программы на кластере при числе процессов p = 1, 2, 4, 8, 16, 32, 64, размерность подобрать так, чтобы время выполнения параллельной программы при p = 1 составляло около 60 и 600 с. Вычислить ускорение и эффективность, построить их графики в зависимости от числа процессов. Составить отчет. Написали программу на языке C++. Расчет осуществляем при числе процессов p = 1, 2, 6, 12 а размерность матрицы подбираем таким образом, чтобы время работы программы при p = 1 составляло порядка 60 и 600 с. Время работы параллельного участка кода занесли в таблицу (Код приведен в приложении 1)
Таблица 1 Время работы параллельной программы от числа процессов Вычислили ускорение и эффективность, полученные значения занесли в таблицу
Таблица 2 Ускорение и эффективность от числа процессов По данным таблицы построили графики зависимостей ускорения и эффективности от числа процессов при различном числе членов ряда. 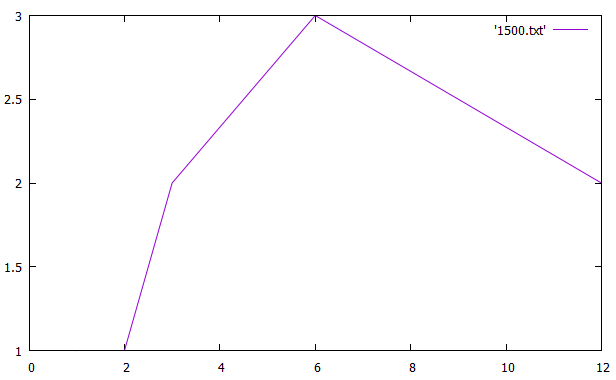 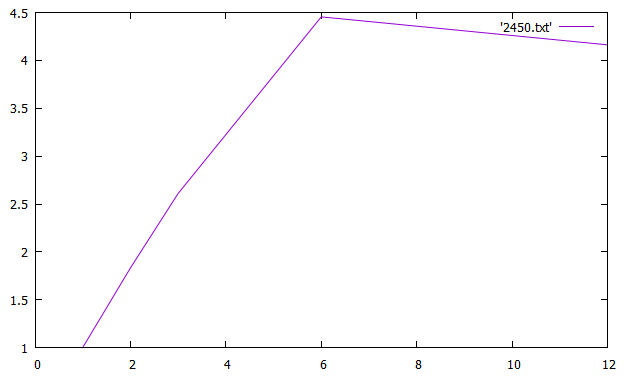 Зависимость ускорения от числа процессов 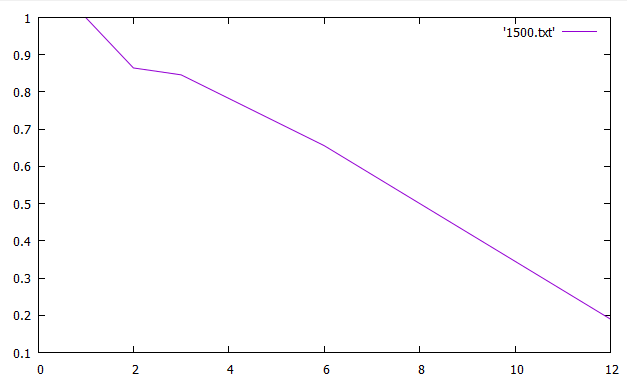 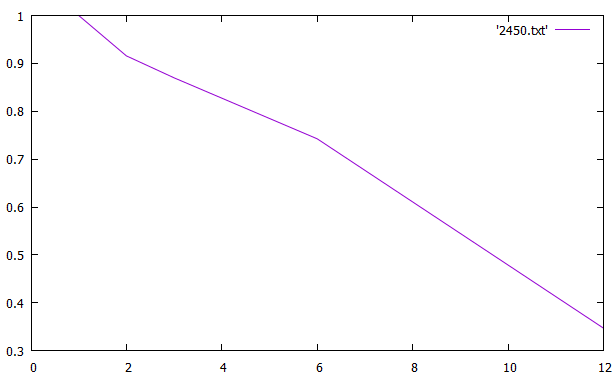 Зависимость эффективности от числа процессов Вывод: Для многопроцессорных вычислительных систем с распределенной памятью на примере задачи параллельного умножения матриц научились программно реализовывать простейшие параллельные вычислительные алгоритмы и проводить анализ их эффективности. На данном процессоре лучше всего использовать 6 процессов Исходный код Приложение 1 #include "mpi.h" #include "math.h" #include #include "stdlib.h" #include void rand_matrix(double* a, const int n, const int m) { srand(1); for (int i = 0; i < n * m; i++) a[i] = -0.5 + (double)rand() / RAND_MAX; } int main(int argc, char* argv[]) { int MyID, NumProc, root = 0; int ierror = MPI_Init(&argc, &argv);//инициализирует библиотеку мпи if (ierror != MPI_SUCCESS) perror("MPI initialization error!"); MPI_Comm_size(MPI_COMM_WORLD, &NumProc);//число процессов MPI_Comm_rank(MPI_COMM_WORLD, &MyID);//№ MPI_Barrier(MPI_COMM_WORLD); int L = atoi(argv[1]);//первый параметр к стр хранит число столбцов/строк матр б int N = 10 * L;//число строк матр а double *A, *B, *C; A = (double*)malloc(N * L * sizeof(double)); B = (double*)malloc(L * L * sizeof(double)); C = (double*)malloc(N * L * sizeof(double)); int* scounts, * displs; scounts = (int*)malloc(NumProc * sizeof(int)); if (MyID == root) //процесс который делает работу { rand_matrix(A, N, L); rand_matrix(B, L, L); int q = N / NumProc; int cnt = N - q * NumProc;//остаток for (int i = 0; i < NumProc; i++) { if (cnt) { scounts[i] = q + 1; //сколько передаем cnt--; } else scounts[i] = q; scounts[i] *= L; //мы делим построчно, а умножаем на Л чтобы пройтись по столбцам и получить количество элементов которые отдадим } displs = (int*)malloc(NumProc * sizeof(int)); displs[0] = 0; for (int i = 1; i < NumProc; i++) { displs[i] = displs[i - 1] + scounts[i - 1];//с какого места начинаем отправку } } MPI_Bcast(scounts, NumProc, MPI_INT, root, MPI_COMM_WORLD); // делимся числом отправлямых элементов со всеми процессами int rcount = scounts[MyID];//число принимаемых эллементов double* c, * d; c = (double*)malloc(rcount * sizeof(double)); d = (double*)malloc(rcount * sizeof(double)); //d MPI_Scatterv(A, scounts, displs, MPI_DOUBLE, c, rcount, MPI_DOUBLE, root, MPI_COMM_WORLD); //раздаем матрицу а( сколько, с какого элемента, куда, сколько принимаем,процесс отправитель) MPI_Bcast(B, L * L, MPI_DOUBLE, root, MPI_COMM_WORLD);// раздаем матрицу б(всем в этой группе) double norm = 0., zz = 0.; double tstart = MPI_Wtime(); for (int i = 0; i < rcount / L; i++) { for (int j = 0; j < L; j++) { for (int k = 0; k < L; k++) zz += c[i * L + k] * B[j + L * k]; d[i * L + j] = zz; norm += zz * zz; zz = 0.; } } double result; MPI_Reduce(&norm, &result, 1, MPI_DOUBLE, MPI_SUM, root, MPI_COMM_WORLD);// собираем норму со всех процессов, пишем сумму этих норм в резалт,количество элементов собираемых с каждого процесса) MPI_Gatherv(d, rcount, MPI_DOUBLE, C, scounts, displs, MPI_DOUBLE, root, MPI_COMM_WORLD); if (MyID == root) { double tfinish = MPI_Wtime() - tstart; printf("norm = %f\ntime = %f\n", result, tfinish); free(displs); free(A); } free(scounts); free(C); free(B); MPI_Finalize(); return 0; } | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
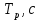
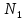 = 1500
= 1500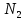 = 2450
= 2450