Ревью разд. 6 (Generics. Collections). Перед ревью, проверьте себя по контрольным вопросам
 Скачать 1.15 Mb. Скачать 1.15 Mb.
|

|
Перед ревью, проверьте себя по контрольным вопросам: 1) Что такое дженерики? Какую проблему они решают. 2) Wildcard 3) Принцип PECS 4) Параметризация статических методов. 5) Что такое коллекция. Иерархия коллекций. 6) Внутреннее устройство коллекций. Что такое generic и для чего они нужны? Дженерики (или обобщения) - это параметризованные типы. Параметризованные типы позволяют объявлять классы, интерфейсы и методы, где тип данных, которыми они оперируют, указан в виде параметра. Например, используя дженерики, можно создать единственный класс, который будет автоматически работать с разными типами данных. Что такое wildcard? Wildcard — (сильная карта или символом подстановки) это дженерик, обозначается вопросительным знаком в угловых скобках , означает, что тип может быть чем угодно. Где используется wildcard? Wldcard позволяет подставить любой тип вместо символа Что такое принцип PECS? Producer Extends Consumer Super - Поставщик расширяет, потребитель ограничивает. Это означает, что типы используемые в wildcard можно ограничивать сверху и снизу по иерархии. Также называется Bounded Wildcards. Принцип PECS более подробно? Для ограничения используется и . - означает что можно использовать всех наследников от типа Т и сам тип Т включительно. - означает что можно использовать только предков типа Т и сам тип Т включительно. Принцип PECS еще? - означает что можно использовать Integer, Long, Double и все что наследуется от Number. Допустим есть класс Car и его наследник Car1 и наследник от Car1 класс Car2. - означает что можно использовать сам класс Car1 и класс Car. Т.е. можно использовать только предков. Upper Bounded Wildcards, Lower Bounded Wildcards? Аналогично PECS. Upper Bounded Wildcards - extends T. Lower Bounded Wildcards - super T. Что такое raw type? Raw type (сырые типы) это generic-типы без указания типа-параметра. Например: List listRawType = new ArrayList(); В один лист можно добавить объекты разного типа, например, Integer и String. Какие проблемы могут быть при использовании raw type? Raw type использовать настоятельно не рекомендуется. Он нужен для обратной совместимости. До появления generic в Java 5. При использовании возможна проблема heap pollution (перев. «загрязнение кучи») - ошибка когда переменная параметризованного типа хранит в себе объект, параметризованный другим типом. В чем отличие ArrayList и ArrayList ? ArrayList - без указания типа использует raw type. ArrayList Это лист без конкретного параметра, в него нельзя ничего добавить кроме null. Но его можно использовать например в параметре метода и принимать различные типы листа. Что такое Type Erasure (стирание типов)? Информация о типе параметра дженерика во время компиляции заменяется на Object. При необходимости добавляется явное приведение типов. Что такое коллекции в Java? Коллекции в Java это классы, основная цель которых - хранить набор других элементов. Коллекции — это наборы однородных элементов. Преимущества использования коллекций? 1. Сокращение усилий по разработке благодаря использованию базовых классов коллекций, а не реализации собственных классов коллекций. 2. Качество и безопасность кода улучшается за счет использования хорошо протестированных базовых классов коллекций. 3. Возможность повторного использования и обратная совместимость с прошлыми версиями Java. 4. Поддержка многопоточного доступа. 5. Возможность динамического увлечения размера в отличии от массивов. С чем работают коллекции а с чем массивы? Коллекции работают с объектами и могут хранить любые ссылочные типы данных. Массивы могут работать с примитивами. Какова иерархия коллекций? На вершине иерархии в Java Collections Framework располагаются 2 интерфейса: Collection и Map. Эти интерфейсы разделяют все коллекции, входящие во фреймворк на две части по типу хранения данных: простые последовательные наборы элементов и наборы пар «ключ — значение» (словари). 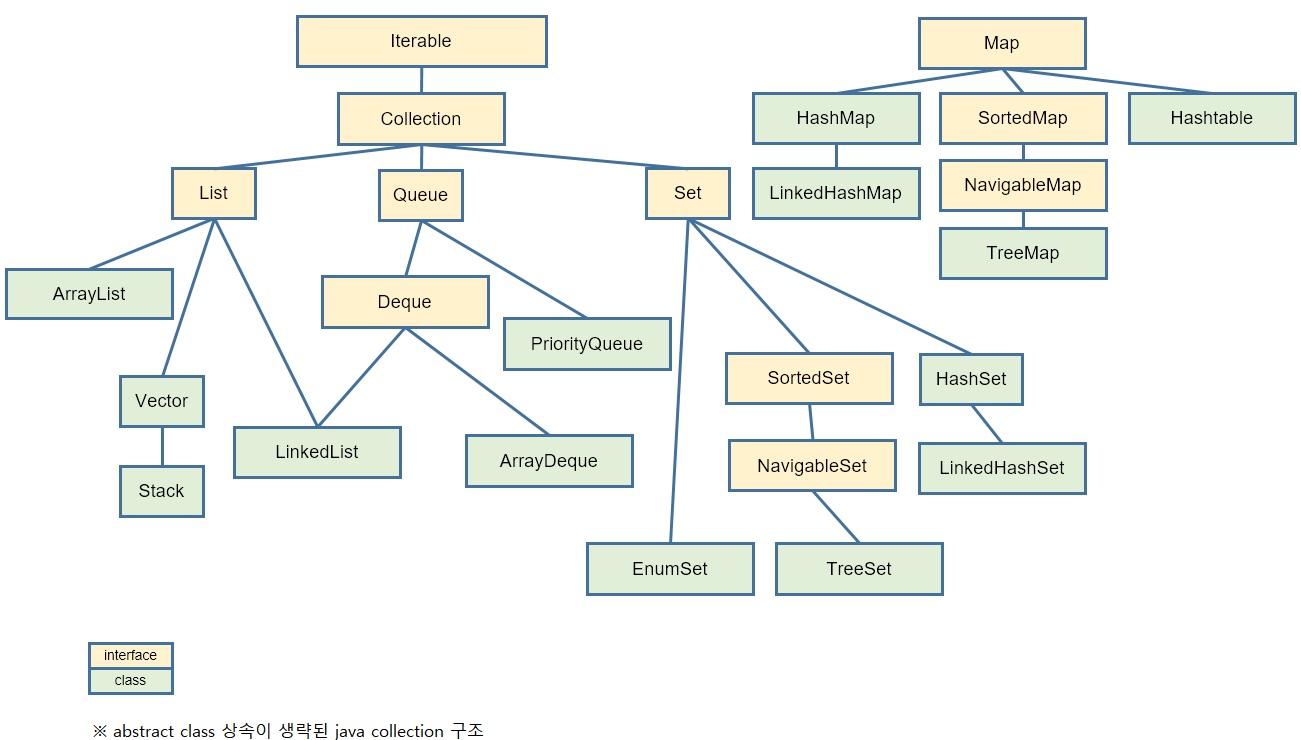  Основные коллекции интерфейса Collection? Set, List, Queue Основные коллекции интерфейса Map? HashMap, LinkedHashMap, TreeMap, Hashtable(устаревший) Что вы знаете о коллекциях типа List? List — это упорядоченный список. Объекты хранятся в порядке их добавления в список. Доступ к элементам списка осуществляется по индексу. Что вы знаете о коллекциях типа Set? Set — неупорядоченное множество уникальных (неповторяющихся) объектов. В коллекции этого типа разрешено наличие только одной ссылки типа null. Что вы знаете о коллекциях типа Queue? Кью - Очередь. Этот список, который используется для реализации концепции FIFO (first in, first out) — «первым пришёл — первым ушёл». В Queue элементы обычно добавляются в конец. Что вы знаете о коллекциях типа Deque? Дэк - двунаправленая очередь. Расширяет интерфейс Queue. Обычно используется для реализации концепции LIFO (last in - first out) - "последний пришёл первый вышел" или как Stack. Но может выступать роли обычной очереди. Можно добавлять элементы как в начало, так и в конец очереди. Интерфейс Deque позиционируется как современная альтернатива классу Stack. Что вы знаете о коллекциях типа Stack? Стек - это подкласс Vector, который реализует стандартный стек LIFO. Рекомендуется использовать Deque в место Stack. Почему Map не наследуется от Collection? Map не наследуется от Collection, потому что это разные структуры данных. Что вы знаете о коллекциях типа HashMap? HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек. Как устроен HashMap? 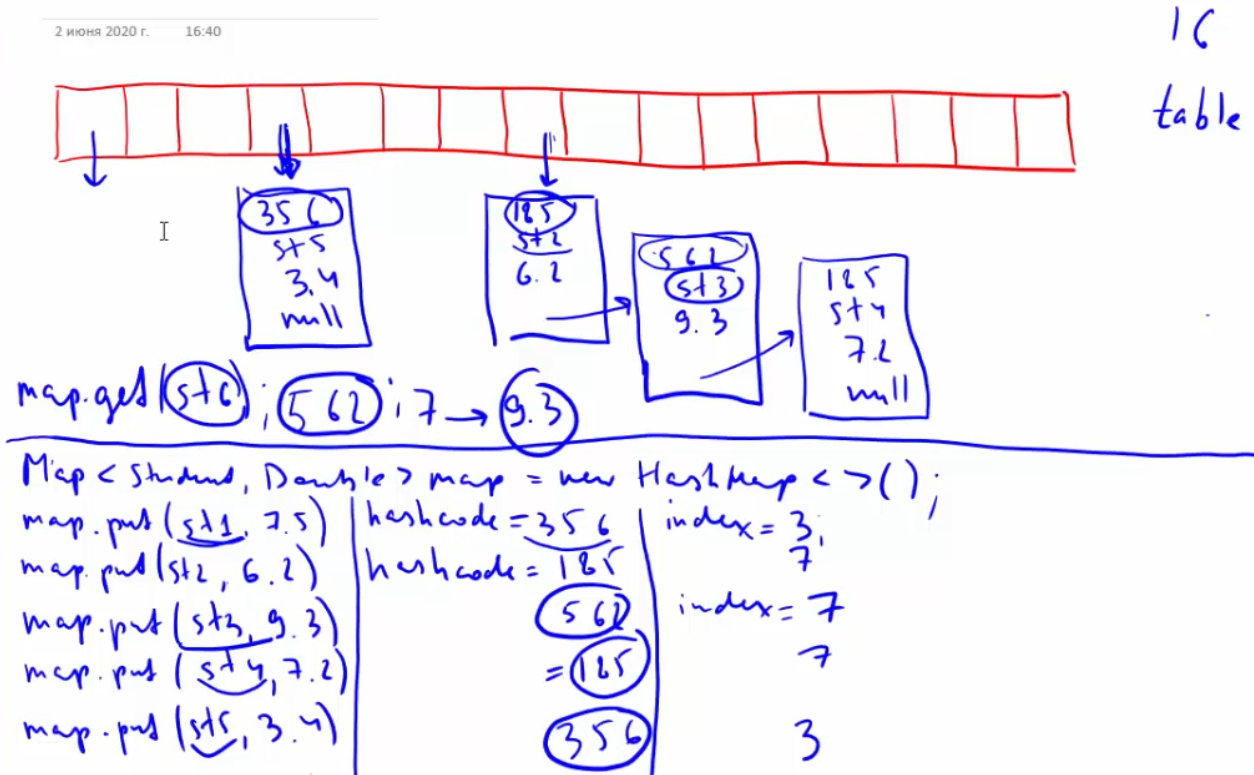  В классе HashMap есть внутренний класс Node (нода по-русски, еще называют узел), который часто называют Entry (т.к. он имплементирует одноименный интерфейс) – это то, что представляет для нас пару ключ-значение. Этот объект также содержит поля hash, в который записывается вычисленный хэшкод ключа, и поле next, в который может помещаться ссылка на соседнюю ноду, помещаемую в один бакет. 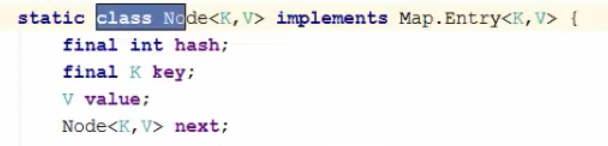 Пример, когда мы создаем hashmap из объектов Student и Double. Map После создания HashMap создается массив размером 16. Этот массив называется table. Каждый элемент массива может содержать несколько пар ключ-значение, которые будем добавлять. Поэтому, чтобы один элемент массива мог содержать несколько пар, эти пары объединяются в LinkedList, т.е. каждый элемент массива будет содержать LinkedList. Элементы данного массива называются basket (бакет, перев. «корзина»), в корзинах содержатся элементы HashMap. Добавим 1й элемент map.put(st1, 6.5): Идет проверка, ключ равен null или нет, если null, этот элемент помещается сразу на нулевой индекс. В нашем случае это не null, поэтому находится хэшкод для ключа, например hashcode = 356 Несложным алгоритмом в хэшмэпе находится, на какой индекс будет помещен данный элемент. Например index = 3. Если хэшкоды совпадают, то и индексы совпадут На 3ю позицию добавляется LinkedList c первым объектом Node с полями - hash = 356 - key = st1 - value = 7.5 - next = пока null (ссылки на следуюший элемент в бакете с индексом 3 пока нет) Добавим 2й элемент map.put(st1, 6.2): Вычисляется хэшкод для ключа, например hashcode = 185; index = 7; На 3ю позицию добавляется LinkedList c первым объектом Node с полями - hash = 185 - key = st2 - value = 7.5 - next = пока null (ссылки на следуюший элемент в бакете с индексом 7 пока нет) Добавим 3й элемент map.put(st3, 9.3): Вычисляется хэшкод для ключа, например hashcode = 562; Допустим, что index = 7 (как у 2го элемента). Происходит проверка, одинаковые или нет хэшкоды у объектов – разные, значит эти ключи не одинаковые, следовательно equals не равны и объекты не равны (equals не проверяется в данном случае); На 3й индекс в конец уже имеющегося LinkedList добавляется второй объект (нода) в бакете с полями - hash = 562 - key = st3 - value = 9.3 И в next 1й ноды в бакете помещается ссылка на 2ю ноду Добавим 4й элемент map.put(st4, 7.2): Хэшкод =185 как у 2го элемента – произошла коллизия. => index = 7 Происходит проверка всех нод бакета на позиции 7. У ключей проверяются хэшкоды, если хэшкоды одинаковы – проверяется equals. Если по equals ключи одинаковы – происходит перезапись значения в ноде, если нет – проверяется следующая нода в LinkedList. Если равных по hashcode и equals не найдено, нода записывается в конец LinkedList и предпоследняя нода в LinkedList начинает ссылаться на последнюю, а добавленная ссылается на null Вычисляется хэш ключа. Если ключ null, хэш считается равным 0. Чтобы достичь лучшего распределения, результат вызова hashCode() «перемешивается»: его старшие биты XOR-ятся на младшие. Значения внутри хэш-таблицы хранятся в специальных структурах данных - нодах, в массиве. Из хэша высчитывается номер бакета - индекс для значения в этом массиве. Полученный хэш обрезается по текущей длине массива. Длина - всегда степень двойки, так что для скорости используется битовая операция & В бакете ищется нода. В ячейке массива лежит не просто одна нода, а связка всех нод, которые туда попали. Исполнение проходит по этой связке (цепочке или дереву), и ищет ноду с таким же ключом. Ключ сравнивается с имеющимися сначала на == (ссылке), затем на equals. Если нода найдена - её значение просто заменяется новым. Работа метода на этом завершается. Если ноды с таким же ключом в бакете пока нет - добавляемая пара ключ-значение запаковывается в новый объект типа Node, и прикрепляется к структуре существующих нод бакета. Ноды составляют структуру за счет того, что в ноде хранится ссылка на следующий элемент (для дерева - следующие элементы). Кроме самой пары и ссылок, чтобы потом не считать заново, записывается и хэш ключа. В случае, когда структурой была цепочка а не дерево, и длина цепочки превысила 7 элементов - происходит процедура treeification - превращение списка в самобалансирующееся дерево. В случае коллизии это ускоряет доступ к элементам на чтение с O(n) до O(log(n)). У comparable-ключей для балансировки используется их естественный порядок. Другие ключи балансируются по порядку имен их классов и значениям identityHashCode-ов. Для маленьких хэш-таблиц (< 64 бакетов) «одеревенение» заменяется увеличением (см. п.8). Если новая нода попала в пустую ячейку, заняла новый бакет - увеличивается счетчик структурных модификаций. Изменение этого счетчика сообщит всем итераторам контейнера, что при следующем обращении они должны выбросить ConcurrentModificationException. Когда количество занятых бакетов массива превысило пороговое (capacity * load factor), внутренний массив увеличивается вдвое, а для всего содержимого выполняется рехэш - все имеющиеся ноды перераспределяются по бакетам по тем же правилам, но уже с учетом нового размера. Чем отличается метод Put и Get для HashMap? Put вставляет новый элемент в ноду или перезаписывает имеющийся. Метод Get позволяет получить имеющуюся пару, тем же образом что и запись, только без добавления. Как решается коллизия HashMap? При совпадении хеш кода, объект сравнивается на равенство ссылок а затем по equals. Если Совпадение найдено то значение у ключа перезаписывается. Если не найдено, то создается новая нода и прикрепляется к структуре существующих нод бакета. Чем отличается Map от HashMap? Map это интерфейс, HashMap это реализация этого интерфейса. Условия перестроения в красно-черное дерево (одеревенение) HashMap? Как только длина связного списка переходит превышает 7 элементов происходит процедура treeification - превращение списка в самобалансирующееся дерево. Для маленьких хэш-таблиц (< 64 бакетов) «одеревенение» заменяется увеличением. В чем отличие Map от Set? Map состоит из пар «ключ-значение». Ключи уникальны, а значения могут повторяться. Порядок элементов не гарантирован. Может иметь 1 null ключ и несколько null значений. Set состоит из ключей. Которые должны быть уникальны. В HashSet элементы не упорядочены и хранятся в удобном для HashSet порядке (можно сказать случайном). Может хранить 1 null значение. Что вы знаете о коллекциях типа HashSet? Хеш сет представляет собой таблицу хеш кодов, которая генерируется при добавлении элемента. Элементами хеш сета могут быть только уникальные значения ключа, и одно null значение. Как работает HashSet? HashSet основан на HashMap, и так же представляет собой массив. HashSet использует хеш таблицы. В начале вычисляется хеш код объекта. На основании хеша и размера массива вычисляется индекс массива. По этому индексу кладется объект. Если происходит коллизия ( эта ячейка не пустая), то в эту же ячейку ложится новый объект и используется односвязный список между ними. Что в HashSet используется вместо значений HashMap? new Object. Почему в HashSet используется new Object а не null для value значений? Если не использовать null значение, до при создании и удалении элементов, не будет видно выполнилось действие или нет, т.к. до и после ссылка будет равна null. Что вы знаете о коллекциях типа TreeSet? TreeSet — коллекция, которая хранит свои элементы вв отсортированном и возрастающем порядке. TreeSet инкапсулирует в себе TreeMap, который в свою очередь использует сбалансированное бинарное красно-черное дерево для хранения элементов. TreeSet хорош тем, что для операций add, remove и contains потребуется гарантированное время log(n). Что вы знаете о коллекциях типа TreeMap? Имплементирует интерфейсы NavigableMap и SortedMap, TreeMap получает дополнительный функционал, которого нет в HashMap, но с меньшей производительностью. В TreeMap элементы хранятся в естественном(по возрастанию) порядке или согласно компаратору. В основе лежит Красно-чёрное дерево (Red-Black Tree). Возможность работы с null-ключом если он разрешен компаратором. Что такое красно-черное дерево? Структура для хранения данных. Если в кратце, то у любого дерева есть корень. Если нужное значение меньше или равно чем корень, то поиск идет в левой части, если больше то в правой. Что вы знаете о коллекциях типа LinkedHashSet? LinkedHashSet наследуется от HashSet. Храненит элементы в порядке добавления. Имеет двухсвязный список между элементами. Что вы знаете о коллекциях типа LinkedHashMap? LinkedHashMapнаследуется от HashMap. Храненит элементы в порядке добавления. Имеет двухсвязный список между элементами. На что указывают крайние ссылки в двухсвязном списке? на null Что такое двухсвязный и односвязный список? двухсвязный список - когда элемент имеют ссылку на предыдущий и следующий. односвязный список - когда элемент имеют ссылку на следующий. Основные реализации List? ArrayList Список LinkedList Список Vector Вектор Stack Стек Основные реализации Set? HashSet TreeSet LinkedHashSet Основные реализации Map? HashMap TreeMap LinkedHashMap Hashtable Что вы знаете о коллекциях типа LinkedList? LinkedList - реализует интерфейс List. Является двунаправленным списком, где каждый элемент структуры содержит указатели на предыдущий и следующий элементы. Итератор поддерживает обход в обе стороны. Реализует методы получения, удаления и вставки в начало, середину и конец списка. Позволяет добавлять любые элементы в том числе и null. Хранит Элементы в порядке добавления. Какие реализации SortedSet вы знаете и в чем их особенность? TreeSet - реаализации SortedSet. Реализации этого интерфейса, следит за уникальностью хранимых объектов и поддерживают их в порядке возрастания. Отношение порядка между объектами может быть определено, помощью метода compareTo интерфейса Comparable В чем отличия/сходства List и Set? Оба унаследованы от Collection, а значит имеют одинаковый набор и сигнатуры методов. List хранит объекты в порядке вставки, элемент можно получить по индексу. Set не может хранить одинаковых элементов, доступ по ключу. Что разного/общего у классов ArrayList и LinkedList? ArrayList реализован внутри в виде обычного массива, доступ по индексу и вставка в конец происходит очень быстро. Для вставки в середину или начало приходится сначала сдвигать на один все элементы после него, а уже затем в освободившееся место вставлять новый элемент. LinkedList реализован в виде двухсвязного списка. Каждый элемент знает предыдущий и следующий за ним. Вставка осуществляется быстро за счет простого изменения ссылок на соседние элементы. А обход по всем элементам занимает много времени. Когда лучше использовать ArrayList, а когда LinkedList? Часто указывается что там где нужно добавлять и удалять много элементов из середины нужно использовать LinkedList. А там где нужен доступ по индексу и добавление в конец - ArrayList. Но по факту лучше стараться почти всегда использовать ArrayList. Т.к в большинстве случаев LinkedList проигрывает по потребляемой памяти и по скорости выполнения операций ArrayList. LinkedList предпочтительно применять, когда происходит активная работа (вставка/удаление) с серединой списка или в случаях, когда необходимо гарантированное время добавления элемента в список. Что будет, если в Map положить два значения с одинаковым ключом? Последнее значение перезапишет предыдущее. Что такое HashtTable, чем она отличается от HashMap? HashtTable- deprecated. Не рекомендована к использованию. Основные отличия HashtTable - синхронизирована и медленнее работает и не позволяет иметь null ключей и значений. Порядок следования в коллекциях? HashMap/HashSet - "случайный" порядок(удобный для Map/Set) хранения элементов. ТгееМар/ТгееSet - хранит эл-ты в порядке возрастания элементов. LinkedHashMap/LinkedHashSet - хранит эл-ты в порядке добавления элементов. Дайте определение понятию "итератор"? Iterator Итератор — объект, позволяющий перебирать элементы коллекции. Методы Iterator? next(); boolean hasNext(); void remove(); Какую функциональность представляет класс Collections? Collections.sort() - cсортировка Collections.shuffle() - Перемешивает коллекцию в случайном порядке. Collections.reverse() - Переворачивает коллекцию в обратном порядке. Collections.binarySearch() - Поиск в коллекции по ключу с использованием бинарного поиска. Collections.copy() - Копирует коллекцию источник src в dest. Collections.frequency() - Возвращает число вхождений объекта в коллекции. Collections.synchronizedCollection() - Возвращает синхронизированную (потокобезопасную) коллекцию. Какие коллекции синхронизированы? Для этого используется пакет Concurrent. @Deprecated HashTable, Vector. Как получить синхронизированную коллекцию из не синхронизированной? Collections.synchronizedList(list); Collections.synchronizedSet(set); Collections.synchronizedMap(map); Все они принимают коллекцию в качестве параметра, и возвращают потокобезопасную коллекцию с теми же элементами внутри. Как получить коллекцию только для чтения? Используйте следующие методы: Collections.unmodifiableList(list); Collections.unmodifiableSet(set); Collections.unmodifiableMap(map); Все они принимают коллекцию в качестве параметра, и возвращают коллекцию только для чтения с теми же элементами внутри. В чем разница между Iterator и Enumeration? Enumeration в два раза быстрее Iterator и использует меньше памяти. Iterator потокобезопасен, т.к. не позволяет другим потокам модифицировать коллекцию при переборе. Enumeration можно использовать только для read-only коллекций. Так же у него отсутствует метод remove(); Разница между Iterator и Iterable? Iterable - это простое представление серии элементов, которые могут быть итерированы поверх. У него нет никакого состояния итерации такого как "текущий элемент". Вместо этого у него есть один метод, который производит Iterator. Iterator - это объект с состоянием итерации. Он позволяет проверить, есть ли у него больше элементов с помощью hasNext() и переместиться на следующий элемент (если есть) с помощью next(). И метод Remove. Зачем в итераторе метод remove? Для удаления элемента из коллекции при обходе; Перед этим необходимо вызвать метод next(). Для того что бы перейти на элемент который нужно удалить. В чем разница между Iterator и ListIterator? Iterator может использоваться для перебора любых коллеций Set, List и Map. В отличие от него, ListIterator может быть использован только для перебора элементов коллекции List. Iterator позволяет перебирать элементы только в одном направлении, при помощи метода next(). И удалять методом remove() Тогда как ListIterator позволяет перебирать список в обоих направлениях, при помощи методов next() и previous(), модифицировать список, добавляя/удаляя элементы с помощью методов add() и remove(). Какие есть способы перебора всех элементов List? Iterator, listIterator, enumerator, for, forEach,While В чём различие между fail-fast и fail-safe итераторами? Fail-fast итератор генерирует исключение ConcurrentModificationException, если коллекция меняется во время итерации, а fail-safe - нет. Что делать, чтобы не возникло исключение ConcurrentModificationException? Можно подобрать другой итератор, работающий по принципу fail-safe. К примеру, если вы используете List, то можете взять ListIterator. Если же вам нужна устаревшая коллекция — то используйте перечислители. В том случае, когда вышеизложенное вам не подходит, у вас есть три варианта: 1. При использовании JDK 1.5 или выше, вам подойдут классы ConcurrentHashMap и CopyOnWriteArrayList. Это самый лучший вариант 2. Вы можете преобразовать список в массив и перебирать массив 3. Вы можете блокировать изменения списка на время перебора с помощью блока synchronized. Обратите внимание, что последние два варианта негативно скажутся на производительности. Как реализован цикл foreach? Реализован на основе Iterator. Почему в классе iterator нет метода для получения следующего элемента без передвижения курсора? Итератор похож на указатель своими основными операциями: он указывает на отдельный элемент коллекции объектов (предоставляет доступ к элементу) и содержит функции для перехода к другому элементу списка (следующему или предыдущему). Контейнер, который реализует поддержку итераторов, должен предоставлять первый элемент списка, а также возможность проверить, перебраны ли все элементы контейнера (является ли итератор конечным). Таким образом без курсора просто нельзя будет реализовать безошибочное передвижение по коллекции. В чем разница между интерфейсами Comparable и Comparator? Коротко: Comparable используется для естественной сортировки(по возрастанию). Comparator для сортировки по разным шаблонам. Подробно: Классы-обертки как Integer, Double и String реализуют интерфейс Comparable. По этому метод sort ,без параметров может сортировать эти объекты. Интерфейс Comparable может быть реализован именно элементами коллекции или ключами Map. Так же интерфейсом Comparable может пользоваться любой класс который его реализует и переопределяет. Если у вас нет доступа к классу можно реализовать интерфейс Comparator. Comparator реализуется отдельным объектом (это удобно, так как можно заготовить несколько реализаций для разных правил сортировок, не меняя при этом код элементов коллекции/ключей Map). Почему коллекции не наследуют интерфейсы Cloneable и Serializable? Клонирование и сериализация являются очень узкоспецифичными операциями, и реализовывать их нужно только когда это необходимо. Так же каждая операция клонирования потребляет очень много памяти, и неопытные программисты могут расходовать ее сами не понимая последствий. Что можно параметризовать? Параметризовать можно классы, конструкторы, методы, интерфейсы, поля. Параметризация статических переменных и методов? Нельзя создавать обобщенные статические переменные и методы. Можно объявлять статические методы со своими параметрами(отличающимися от параметров класса) Ограничения присущие обобщениям? 1. Нельзя создавать экземпляр по параметру типа. Ни обычный объект, ни массив. Тип экземпляра класса должен быть известен заранее. 2. Нельзя создать массив специфических для типа обобщенных ссылок 3. Нельзя создавать обобщенные статические переменные и методы. Почему в статические методы не передается тип класса? Если статический метод будет привязан к параметрам класса, то может возникнуть такая ситуация, когда экземпляра класса еще не было создан. Так же и со статическими полями класса. Как параметризовать статический метод? статический метод параметризуется так же как и обычный - перед типом возвращаемого значения указывается параметр в угловых скобках Что такое даймонд оператор? Это треугольные скобки <>. Даймонд оператор Уменьшает количество кода при использовании дженериков. При создании объекта слева пишется его тип, а с права уже не нужно повторять этот тип, оператор можно оставить пустым.(возможно не для анонимного метода, но это не точно) Почему последняя строчка не скомпилируется? List ArrayList
Потому что дженерики инварианты. Т.е. нельзя приводить конкретный тип к общему. List ArrayList
Что такое ковариантность и контравариантность? Формально, ковариантность/контравариантность типов - это сохранение/обращение порядка наследования для производных типов. Проще говоря, когда у ковариантных сущностей типами-параметрами являются родитель и наследник, они сами становятся как бы родителем и наследником. Контравариантные наоборот, становятся наследником и родителем. Что такое инвариантность? Инвариантность - это отсутствие свойств ковариантности и контрвариантности. Дженерики без вайлдкардов инвариантны: List |